




 广告
广告





















































算力限制场景下的目标检测实战浅谈
2019-01-21 23:39:47·

这里需要说明计算量Flops(浮点运算次数)或者是MAC(加乘数)与实际运行时间之间的关系:
首先,由于网络结构具有不同计算访存比的特点,导致硬件算力和网络flops之间无法形成线性对比关系。这里可参考:Momenta王晋玮:让深度学习更高效运行的两个视角。比如,在轻量级网络中很常见的depthwise 卷积中,单位取到的数据所支撑的计算量小于普通卷积,也就是计算访存比小,因此对芯片的缓存访存需求更大。
同时,在目标检测问题中,除了骨干神经网络花费的时间,检测头和nms 也花费了一些时间。例如nms 的数量是不固定的,这部分的时间开销和计算量更加无法准确计算。
因此,如果在测试中直接使用时间对模型进行速度衡量,则必须到设备进行实测,这里还涉及到设备端的如ARM/NOEN、定点算浮点、量化等优化,是非常复杂的,所以一般情况下,我们都会使用Flops对计算能力进行估算。
因此,截止目前,我们可以将问题归约为,通过曲线的辅助,找到最优模型和参数,并在有效范围内取最大值。
最关键的问题来了,这条曲线该怎么找到呢?这条曲线其实是没法求的,我们会在后边进行调参举例来进行一定的说明,接下来我们再花些时间在我们的边际效用递减曲线上面。
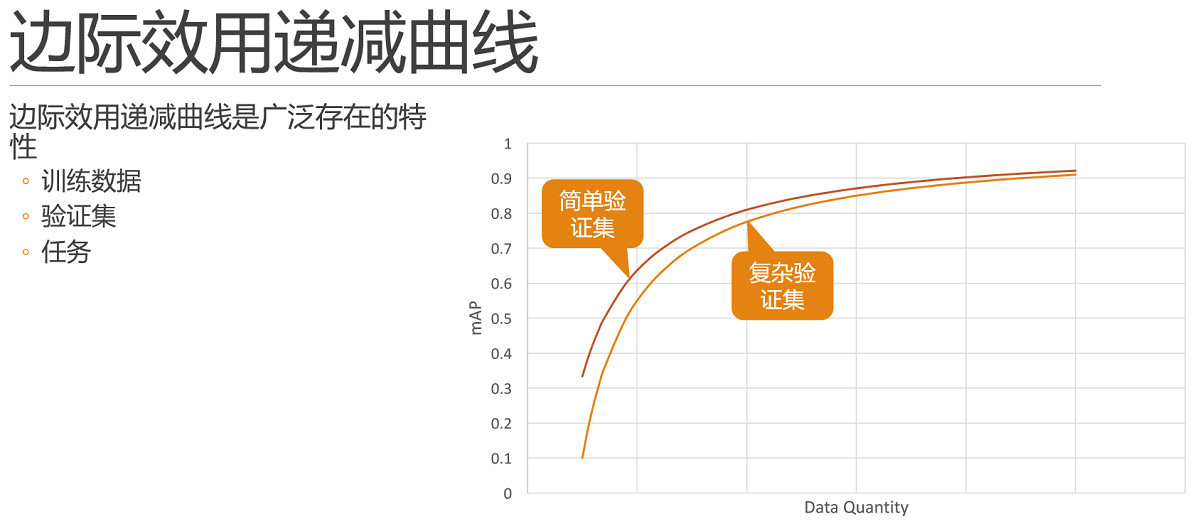
首先,该曲线是广泛存在的。
除去算力,当横轴是数据量的时候,往往情况下也是可以体现出来类似的边际效用特点的,也就是说当我们在数据不足够充分的时候,每次增加单位数量的同分布数据时,相同模型相同参数,所能提高的精度也是符合边际效用递减曲线的。
所以,如果在测试中,你发现增减数据对结果的影响非常大,那么极有可能你的问题当前处在数据量不够的阶段,需要想办法增加数据。这也就是前面所说的这条曲线可以帮助我们明确问题所在的区间。
此外,验证集和评价标准也不是一成不变的,在其他因素不变的情况下,相同方法在简单验证集下,结果的数值上显然是要优于复杂验证集的。
关于训练集和验证集的问题我们后边会再展开讲解,我们这里看一下不同任务的情况下,边际效用递减曲线之间的对比关系是怎样的?

通过实践,我们了解到,相同算法下,任务的难度决定了曲线的走向。
那么,在前文提到的车辆和手势两个任务,我们能否把任务和曲线进行如图的对比关系呢?
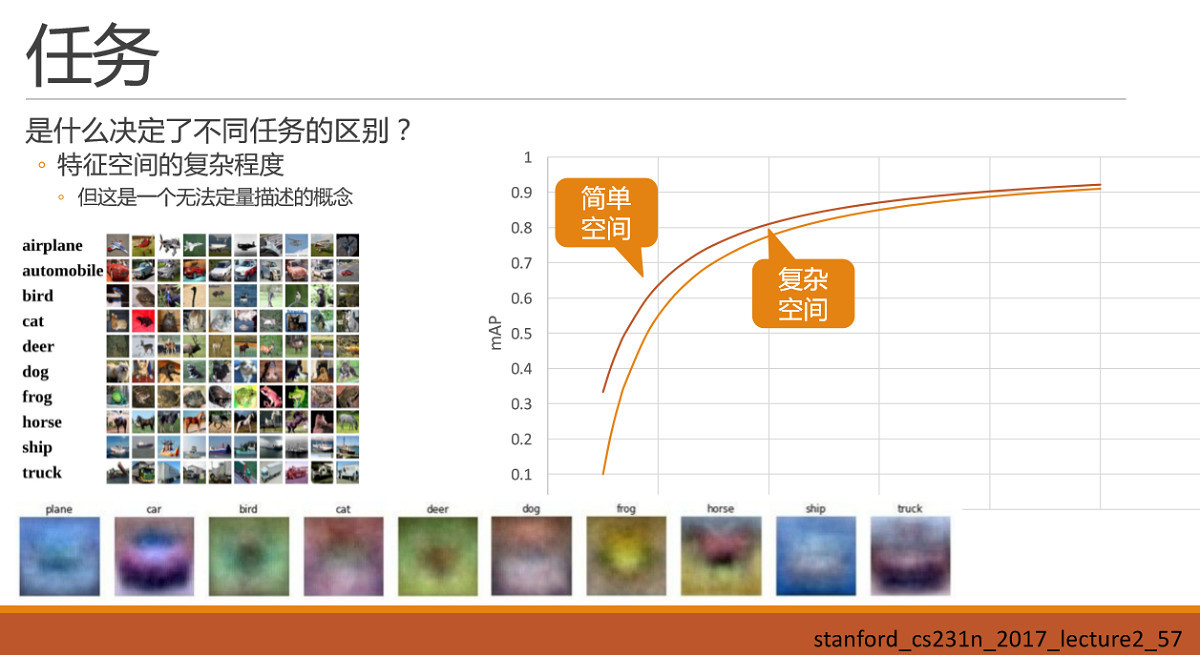
先把车辆和手势放一边,先看:是什么决定了不同任务的区别呢?直接抛出一个小的直观的感觉:即特征空间的复杂程度,决定了任务的区别。暂时我还只能称之为感觉,而不是结论,这里还真不敢下结论。虽然是感觉,但是建立这样一种感觉,可能对我们后续调参会有一些帮助。
那么什么是特征空间的复杂程度呢?这暂时还是一个无法定量描述,甚至无法准确定义的概念。我们可以就看一下什么样的空间复杂,什么样的空间简单:
我们都知道深度学习最核心的能力就是对数据特征的描述以及泛化,那么我们再来看一下数据特征具体长什么样子加深再这个理解。在Stanford cs231n课程中曾经提到cifar10 的数据集中,如果对每一类图的采样并进行平均化的话,可以得到如图的平均图,我们直观的去观察这个平均图,会发现最容易辨认的是第二类car。
那么车辆检测就是简单空间吗?我们继续看下一个例子。

这里是在100张城市数据集车辆尾部数据中采样并得到一张平均图。可以发现一整辆车的轮廓已经出来了。再继续深入去定性分析的话,因为车辆首先是刚体数据,其次线条简单清晰,不同车型的部件基本相同,如后窗、尾灯、牌照、车轮还有车轮下方的阴影区域。这里面图是随机挑选的,感觉白车有点多哈,可能是因为白车不容易脏,买的人本来就多吧?
这里需要注意的是任务需求,这个需求到底是检出来车屁股即可,还是说必须分辨出来是颜色车型等具体信息,甚至需要车辆牌照信息。因为当任务需求发生变化时,神经网络需要去描述的特征的量也会随之发生变化。

再看一下货车的。和轿车的大体相同。

好,我们再看一下人脸数据集的平均图,和车辆差不多,人脸的平均图也差不多出来了一个人,有鼻有嘴,就是看不清。但因为数据中西方人男性居多,所以我们还能大概看出来是个西方男人的感觉。同理,如果任务需要区分人脸的情绪,也就是眼角、嘴型的细微变化,这个新的需求对神经网络所需要描述的特征量的要求也就变得非常大了,也就不简单了。



编辑推荐




最新资讯
-
2025智驾“封神榜”测评|小鹏MONA M03智车
2025-04-29 18:24
-
风噪测试在电动汽车时代的关键作用
2025-04-29 11:34
-
汉航车辆性能测试系列之操纵稳定性测试--汉
2025-04-29 11:09
-
新能源汽车热管理系统验证体系PITMS正式发
2025-04-29 11:09
-
试验载荷谱采集
2025-04-29 11:07
