




 广告
广告





















































算力限制场景下的目标检测实战浅谈
2019-01-21 23:39:47·

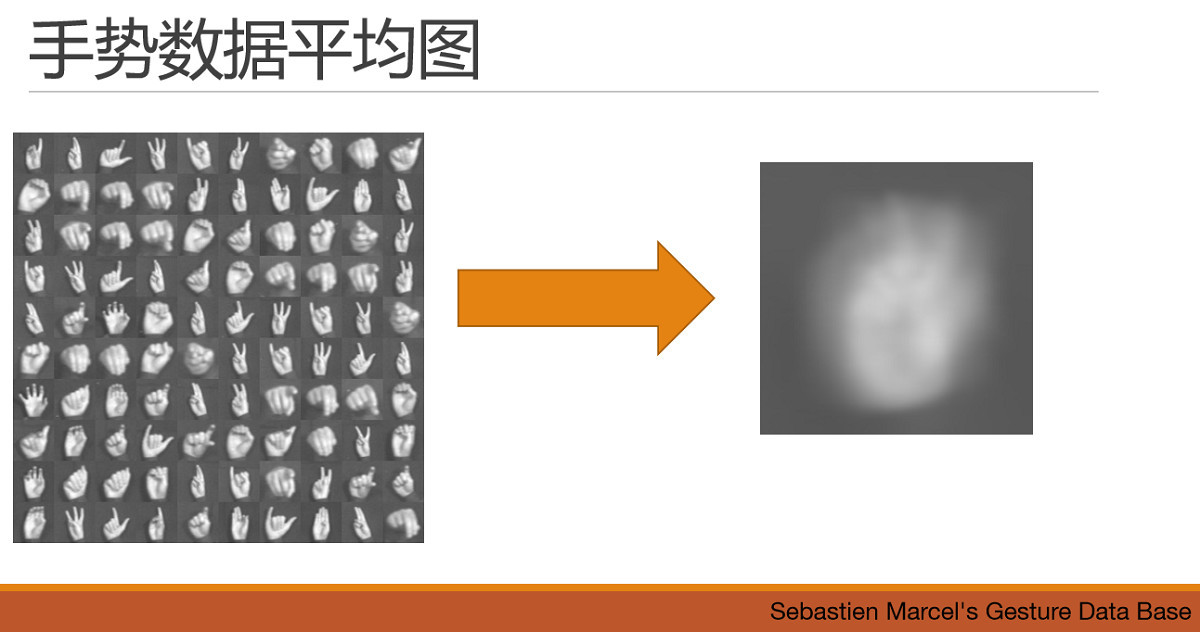
继续看例子,手势,貌似隐隐约约能看出来一个胜利V的手势,但是,这个数据集显然是需要能够识别出这些手势的基本含义。直观看起来,需要的基础特征的形状也是很多的。
特征空间的复杂程度

现在又要祭出这张经典的特征可视化图了,简单的说,就是浅层特征基本就是直线和点,之后的每一层都是再对上一层特征进行概率意义上的组合。
回到特征空间复杂程度的问题上面来,我们再举一个极端的例子,mnist 手写数据集中所需要的特征,直观感觉上就是些直线折线和圈圈,而imagenet 是几乎要应对整个自然图像中所能涉及到的方方面面的情况,需要的特征和特征的组合关系几乎是无法想象的。而在实践中,大家都知道可以让两者跑的好的神经网络,容量相差甚远。
好,我们直观上现在知道了,对于一个特定问题,其实一定程度上可以说它所需要的特征量一般是确定的。当然我们没法准确的得到具体的值,神经网络要基本上能匹配上这个量,才能尽可能的做到精准。当你减少网络参数时,势必会削减网络对某些情况的判断能力,进而减少精度。
这里不得不提一下二八定律,即在正常概率的世界中,我们一般可能需要20%的精力去处理80%的情况,反之需要80%的精力去处理剩下20%的疑难杂症。通过经验我们认为,神经网络大概也是用80%的特征组合关系去处理了那20%的疑难杂症情况,所以如果抛弃部分甚至全部疑难杂症,可能20%的特征组合关系就够用了。也是为什么边际效用递减曲线画出来是一条向左上方凸出的曲线的原因吧。
实战中的实验设计
好了,虚的讲完了。结果遗憾的是,前面所讲的虚的东西,全部都是不能通过数学公式进行推导的。
这咋整?
秀了半天虚的,其实也没什么特别高明的方法,就是试。但是怎么设计实验,也就是说怎么试,每次试什么,试完之后改什么,还是很有文章可以做的。也就是这里所说的通过实验设计逐步获得最优值。这也是本次报告要分享的核心点。
其实,最近研究界大热的automl 或者是network architecture search 的方法,就是以替代掉人类的这部分调参过程为目标的。
但是本次报告我还是寄希望于完全通过手工方法来还原调优过程,通过还原这个调优过程,给大家展示调优过程中的一些小的trick 和机理。这件事虽说未来有可能要失业,但是在automl和nas仍存在学术研究阶段的情况下还是很重要的,也可能会帮助我们去认识和研究automl吧。

先再放个虚的框架,然后一一展开说一下。

先说数据集,数据集有可能是一个被忽略的因素。为什么这么说呢,因为我们对学术界论文的依赖度还是非常高的,而做论文的思路呢,一般都会使用公开数据集和通用评价标准,因为不使用这些你怎么跟同行进行比较呢?同理做比赛也有这样的问题,虽然比赛已经比较贴近实际任务了,但是也必须有一个公平的评价标准,不然排名靠前靠后凭什么呢?
但是在做实际任务的时候,数据集就必须需要适应问题本身的需求,首先是验证集。大家都知道,其实机器学习就好比训练小学生去应付期末考试。验证集就是期末考试,日常小朋友练习的题目不管怎样也得和期末考试差不多,不然一定懵逼。验证集做简单了,数据分布上可能没有覆盖到实际情况中的大部分情况,也有可能做难了,对于一些不会出现的情况上花费了太多精力。还有一种情况就是验证集和训练集的重复关系,小心验证集达标的时候其实有可能只是过拟合了训练集。所以这时候没人给做验证集,只能靠自己。
训练集数据,根据前文所讲的数据与mAP的边际效用关系,这里肯定是能尽量搞定足够多的数据才是王道。数据量不够的情况下可能还需要使用一些迁移学习的方法来弥补,这里因为时间关系就不展开了。本文的最后还会对imagenet 等数据集对轻量级模型下的迁移学习进行一些补充。
评价标准的重要性在这里也就显现出来了,一般情况下我们会用通用的目标检测评价标准(mAP)来描述我们的目标检测方法。必须承认,mAP 确实是综合的描述了一个模型的基本和平均能力,但是它不能同时兼顾漏检率和误捡率。由于mAP 是一个随着confidence 下降来同时加入tp和fp绘制曲线并计算总面积的,因此fp 也就是误捡的sample 并不会很明显的体现出来,针对比较关注误捡率的问题,最好还是不要用mAP。

好,我们开始跑了。
一般的,我会花一些时间来建立baseline,这个下一页详解。
然后开始迭代,核心思路是使用对照实验(control experiment),只改变一个变量,固定其他所有变量。
既然每次都只能调整一个参数与变量,那就最好沿着最有可能提高性能的方向调整,那么哪个是最大的变量呢?这需要熟悉神经网络的原理和研究现状,等下我们具体举例来说明一下。
这时我们前面讲的辅助线可能就能用上了,几次实验之后,你心目中大概可以形成一个或者多个边际效用递减曲线了,就可以估算一下某个变量在上面所处的位置。嗯,上升趋势比较明显的变量值得着重考虑。
所有维度都尝试之后再重头逐一尝试,因为毕竟每次只调整一个参数没有考虑到参数和参数之间的相互作用关系。
什么时候停止呢?调参小能手一般是没有止境的,yeah。不过一般也就是验证集达标,但是前面也提到了,手头这个验证集符合实际情况吗?要去实际情况跑一跑你的模型了。
举例

刚刚是原则性的套路,现在我们来举一个例子。
要求如图所示,根据我们前面对任务特征空间的描述,这个问题应该有可能能在这个量级下完成吧,我们来试试。

首先我需要一个baseline,虽然我现在要用的是10M 的网络,10M 的论文可能不多,但是我这时还是会先去复现mobilenet-v1,mobilenet-v2,shufflenet-v1/v2,以及各种坊间反馈还比较优秀的所有轻量级网络结构。



编辑推荐




最新资讯
-
组分性能对锂离子电池卷芯挤压力学响应的影
2025-04-30 09:00
-
美国发布自动驾驶新框架,放宽报告要求+扩
2025-04-30 08:59
-
中国汽研联合清华大学牵头编制的《乘用车避
2025-04-30 08:53
-
2025年汽车标准化工作要点
2025-04-30 08:51
-
关于Audio Precision音频分析仪产品价格稳
2025-04-30 08:51
