




 广告
广告





















































算力限制场景下的目标检测实战浅谈
2019-01-21 23:39:47·

为什么要先做这件事呢,除了作为参考系方便进行比较之外,最大的目的是可以最大限度的保证方法本身、你用的框架等等没有问题,如果这时不搞清楚,未来长期在坑里待着,显然完成不了任务了。同时这样会很容易帮你发现论文中的细节部分,论文搞得多的同学都知道,论文不可以没有创新性,所以很有可能一篇论文中号称的自己最核心的算法点在实测中不是对性能提升最优的点,相反,可能论文中会有些很实用但是看起来不是很有创新性的东西,而你不真的去跑一下,是不知道的。
另外,如果一篇论文已经是一两年前的,这一两年之中有些其他论文会提出一些有趣的小trick 和小参数或者小调整,这些东西有的时候也可以在复现经典论文和方法的时候一起揉进去,例如何凯明提出的fan-in,fan-out参数初始化方法,就可以应用到其前面就发表的论文或者项目中去。
总之,这是一个磨刀不误砍柴工的工作,也是一个积累基础经验的过程。
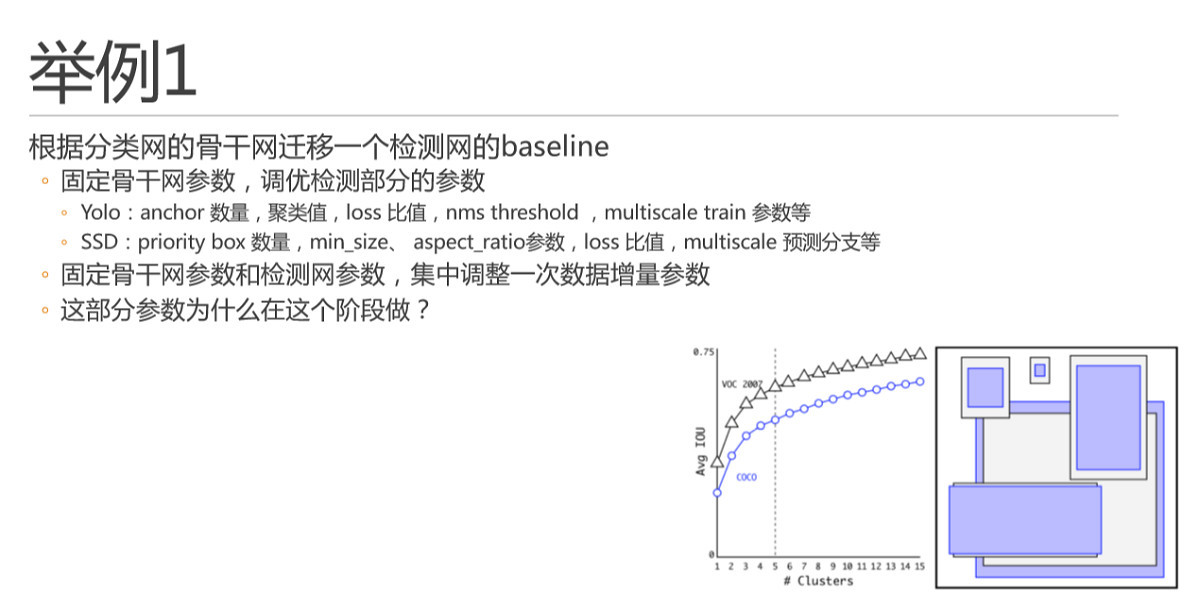
由于不少论文是分类网的论文,或者是不同检测头做的检测模型,比如faster-rcnn 两阶段方法,我们需要换成自己使用的检测头,比如Yolo。这时我就需要再做一个baseline,并获得自有训练数据集下的检测结果。
首先,我会先固定骨干网参数,直接检测部分的参数进行调优。例如Yolo 和SSD 中如图所示的这些参数,简单说原则还是迭代尝试,每次只调整其中一个。
这里多说一嘴,不管是yolo 还是ssd ,他们的anchor 或者priority box 机制,其数量也是符合边际效用递减曲线的,如yolo v2 论文中的这幅图。大家看,这曲线无处不在是吧。所以当其数量适当增加的时候对精度提升是很有用的,但是在算力有限场景下也不能加太多,因为总的proposal 会太多,nms 也会变的很多。
另外,这里anchor聚类出来的具体长宽,只要大体符合数据分布,就可以了,不用很精确,每次增加了同分布数据的时候也不用重复做聚类,因为回归器会自动完成回归过程的,不要离的太远就好。这里不展开了。
调整完检测参数之后,还要再集中调整一次数据增量参数。数据增量也是非常重要的,其实同理,数据增量也是符合边际效用递减曲线的,做太多了也就没啥用了,该增加数据还是增加数据吧。
这里里其实是可以提出这样一个问题的,就是这部分参数为什么在这个阶段做?为什么不在先裁剪出来一个10M 的骨干网再加检测头。这里我个人更加倾向于在后续调优过程中的测试过程更加end2end,因为你的目的就是目标检测嘛。同时,需要注意的是这时的参数并不是最优参数,只是一个起始baseline,未来骨干网确定之后还会再来迭代。



编辑推荐




最新资讯
-
推荐性国家标准《乘/商用车电子机械制动卡
2025-04-30 11:13
-
载荷分解
2025-04-30 10:46
-
布雷博在上海开设亚洲首个灵感实验室
2025-04-30 10:25
-
组分性能对锂离子电池卷芯挤压力学响应的影
2025-04-30 09:00
-
美国发布自动驾驶新框架,放宽报告要求+扩
2025-04-30 08:59
