




 广告
广告





















































利用鲁棒控制实现深度强化学习驾驶策略的迁移
2019-04-09 11:30:04· 来源:ControlPlusAI

从运动规划和控制的角度来看,尽管传统的基于模型的算法已经可以帮助我们完成在相对简单可控的环境下的驾驶任务,如何在复杂场景(例如涉及多车进行复杂交互的场
从运动规划和控制的角度来看,尽管传统的基于模型的算法已经可以帮助我们完成在相对简单可控的环境下的驾驶任务,如何在复杂场景(例如涉及多车进行复杂交互的场景)下安全高效的通行仍然是亟待解决的问题。
自动驾驶无疑是当下最热门的话题之一,无论是工业界还是学术界都在不断探索实现自动驾驶的方法。从运动规划和控制的角度来看,尽管传统的基于模型的算法已经可以帮助我们完成在相对简单可控的环境下的驾驶任务,如何在复杂场景(例如涉及多车进行复杂交互的场景)下安全高效的通行仍然是亟待解决的问题。我们认为利用深度强化学习(Deep Reinforcement Learning),尤其是无模型(model-free)的强化学习算法,来学习复杂场景下的驾驶策略是一个值得探索的方向。通过在训练阶段的大量探索,强化学习算法可以在训练环境中采集不同情况下的数据,从而针对各种情况对策略进行优化,最终获得在训练环境中相对理想的策略。利用这样的方式,我们可以避免对复杂场景的建模,得到可以在线上快速运算的规划及控制策略。
然而,强化学习存在许多现实问题,其中最重要的问题之一就是强化学习缺乏足够的鲁棒性(Robustness)。一旦环境发生变化,出现训练环境没有出现的情况,原本在训练环境中表现优异的策略模型往往无法正确应对。而自动驾驶车辆需要在各种复杂交通状况下行驶,我们无法保证在训练中囊括所有的场景。另一方面,出于安全以及训练效率方面的考虑,驾驶策略往往需要在仿真环境中训练,这更加剧了训练环境和实际工作场景间的差距,使得强化学习生成的驾驶策略无法在实际的自动驾驶车辆上部署。为了解决鲁棒性问题,许多研究者开始使用迁移学习的方法(Transfer Learning),使得在训练好的策略模型可以在新的环境中直接使用(zero-shot),或是经过快速的微调后可以在新的场景下达到理想效果(one-shot/few shot)。
在本文中,我们所关注的问题是驾驶策略对车辆动力学模型变化的鲁棒性,比如模型参数(如质量,转动惯性,轮胎模型参数等等)的变化以及外界的扰动如道路倾角和侧向风导致加载在车辆上的侧向力。我们希望可以将训练好的驾驶策略直接应用在相对于训练环境的车辆有一定变化的车辆上面,比如仿真环境中的不同车辆或是真实车辆,并达到和在训练环境中时相同的效果。为了达到这个目标,我们提出了基于鲁棒控制的驾驶策略迁移框架(RL-RC)。我们在仿真的训练环境(source domain)中训练初始的强化学习策略,随后将训练的强化学习策略应用在目标环境(target domain)中。
我们假设二者的区别仅在于控制车辆的动力学模型有一定程度的差异,并且我们可以获取训练环境中车辆的动力学模型。在迁移的过程中,我们假设相同的行驶轨迹在训练环境和目标环境中有着相同的可行性(Feasibility)和最优性(Optimality),这在二者中控制车辆虽然不同但类似的情况下是合理的假设。因此,我们可以直接利用在目标环境中检测的信息,在训练环境中建立相同的场景,并利用驾驶策略向前仿真一段时间,从而得到在训练环境中未来一段时间内车辆行驶的轨迹。在目标环境中的车辆上,我们利用已知的车辆动力学模型信息,设计鲁棒控制器来控制车辆追踪生成的参考轨迹。
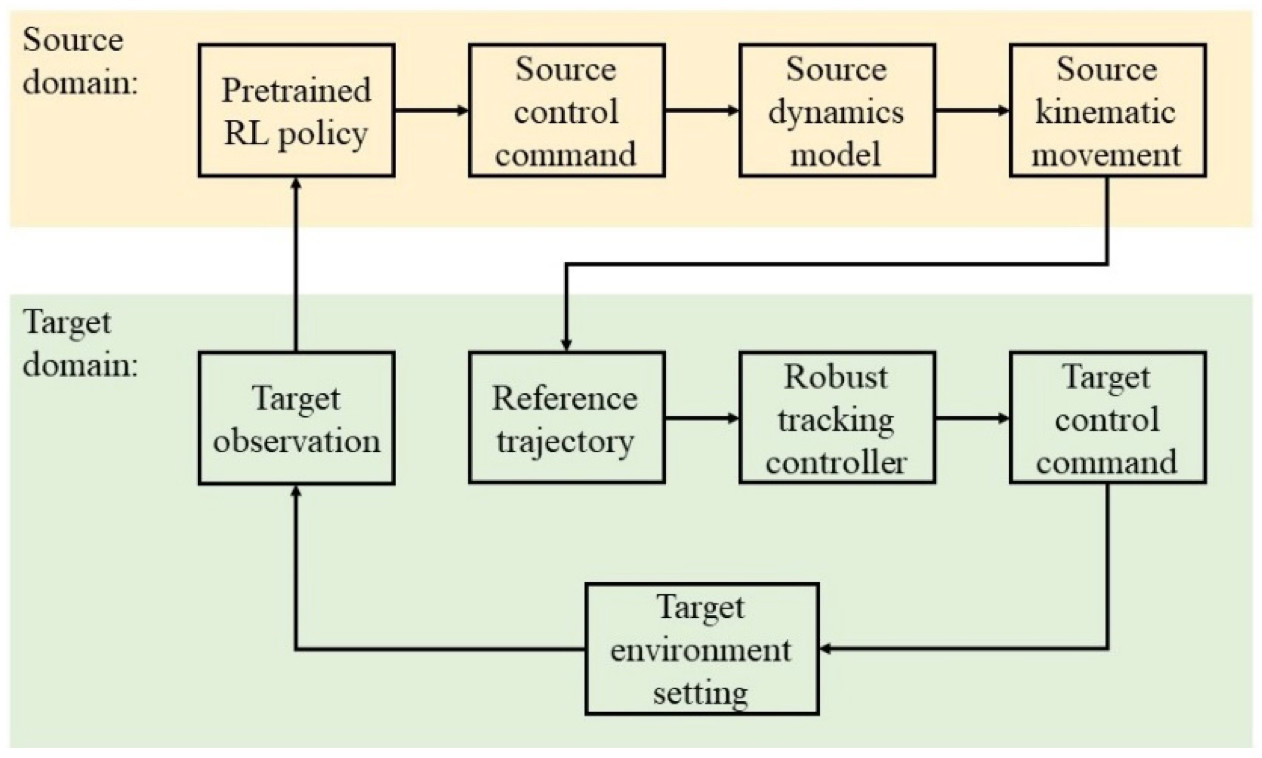
RL-RC 策略迁移框架示意图
在这一框架中,我们将轨迹作为可直接迁移的中间变量,增加了迁移过程的可解释性,并且避免了在目标环境中对策略的调整,提高了安全性。利用鲁棒控制理论,我们可以保障底层追踪控制器在存在扰动情况下的效果,更加有效地提高迁移框架的鲁棒性。在实际的实验中,我们用策略梯度(Policy Gradient)算法PPO训练驾驶策略完成车道保持、换道以及避障任务,在目标环境中,我们设计了基于Disturbance Observer (DOB)的控制器实现轨迹追踪。我们在不同的仿真环境之间,取得了良好的策略迁移效果。在车辆模型参数有一定程度的随机变化或是存在外加侧向力的情况下,RL-RC方法可以在目标环境中保持训练环境中的表现,顺利完成指定任务。而原本的驾驶策略在目标环境中的表现有着显著的下降。在之后的研究中,我们将尝试把RL-RC方法应用在从仿真环境到真实车辆的策略迁移,用实车实验进一步验证迁移方法的可行性。同时,改进RL策略以及鲁棒控制器,使得迁移过程更加安全可靠,实现更加复杂场景下的策略迁移。
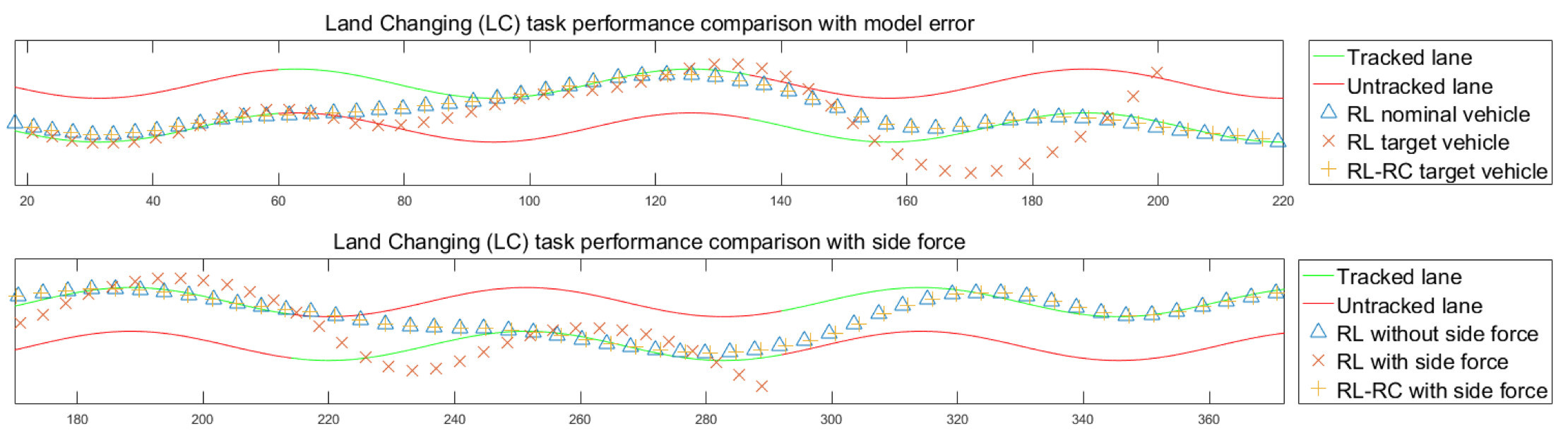
RL-RC方法可以控制车辆在目标环境中实现与训练时几乎相同的行驶轨迹,而原本的RL策略在模型参数有变化或是存在扰动的情况下会失去稳定性,无法完成任务
(具体方法及更详尽的分析请参考论文)
Zhuo Xu*, Chen Tang*, and M. Tomizuka, “Zero-shot Deep Reinforcement Learning Driving Policy Transfer for Autonomous Vehicles based on Robust Control”, in IEEE Intelligent Transportation System Conference (ITSC), Nov. 2018. Best paper finalist.
https://arxiv.org/abs/1812.03216



编辑推荐




最新资讯
-
imc/GRAS/AP首次联袂亮相ATE India 盛会
2025-04-11 13:49
-
GB/T 31486-2024 与 GB/T 31484-2015 修改
2025-04-11 13:48
-
标准介绍丨ASAM ARTI 运行实时接口
2025-04-11 10:29
-
自动驾驶中基于深度学习的雷达与视觉融合用
2025-04-11 10:25
-
标准研究丨《汽车开闭件性能要求和试验方法
2025-04-11 10:24
