




 广告
广告





















































自动驾驶是怎样工作的?SLAM介绍
2019-09-04 22:19:10· 来源:磐创AI

本篇文章主要介绍了自动驾驶是如何工作的以及SLAM简介。SLAM是机器人或车辆建立当前环境的全局地图并使用该地图在任何时间点导航或推断其位置的过程。SLAM常用于
本篇文章主要介绍了自动驾驶是如何工作的以及SLAM简介。

SLAM是机器人或车辆建立当前环境的全局地图并使用该地图在任何时间点导航或推断其位置的过程。
SLAM常用于自主导航,特别是在GPS无信号或不熟悉的地区的导航。本文中我们将车辆或机器人称为“实体”。实体的传感器会实时获得周围环境的信息,并对信息进行分析然后做出决策。
介绍
SLAM是一种时间模型,它的目标是从复杂的信息中计算出一系列状态,包括预期环境,距离,以及根据之前的状态和信息得出的路径 。有许多种状态,例如,Rosales和Sclaroff(1999)使用状态作为行人边界框的3D位置来跟踪他们的移动。Davison 等人(2017)使用单目相机的相机位置,相机的4D方向,速度和角速度以及一组3D点作为导航状态。
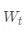
SLAM一般包含两个步骤,预测和测量。为了准确表示导航系统,SLAM需要在状态之间以及状态和测量之间进行学习。SLAM最常用的学习方法称为 卡尔曼滤波。
卡尔曼滤波
卡尔曼滤波是一种用于状态估计的贝叶斯滤波类型。它是一种递归算法,作为系统中不确定性的函数,使预测可以随着时间的推移进行校正。不确定性表示为当前状态估计和先前测量之间的权重,称为卡尔曼增益。该算法将实体先前的状态,观测和控制输入以及当前的观测和控制输入作为输入。过滤器包括两个步骤:预测和测量。预测过程使用运动模型,可以根据给定的先前位置和当前的输入估计当前位置。测量校正过程使用观察模型,该模型基于估计的状态,当前和历史观察以及不确定性来对当前状态进行最终估计。
根据历史状态,传感输入和观测以及当前传感输入和观测来估计新状态w_{t+1}和m
第一步涉及了时间模型,该模型基于先前的状态和一些噪声生成预测。
公式1. 预测模型。μ表示状态的平均变化向量。ψ是状态数量的矩阵,将当前状态与先前的平均值相关联。ε是转换噪声,可以确定当前状态与前一个状态的紧密相关程度。
第二步是“校正”预测。传感器收集自主导航的测量值。有两类传感器:外传感器器和内传感器(proprioceptive)。外传感器从外部环境中收集信息,包括声纳,距离激光,相机和GPS。在SLAM中,这些是观察值。内传感器利用编码器,加速度计和陀螺仪等设备收集系统内部信息,如速度,位置,变化和加速度。在SLAM中,这些是单元控制,传感器结果输入到实体中进行计算。这些传感器各有利弊,但相互组合可以产生非常有效的反馈系统。
公式2. μₘ表示测量平均向量。Φ是状态数量的将测量的平均值与当前状态相关联。εₘ是测量噪声,通常以协方差Σₘ分布。
卡尔曼增益增强了测量的可信性。例如,如果相机失焦,我们就不会对拍摄内容的质量报太大期望。卡尔曼增益较小意味着测量对预测的贡献很小并且不可靠,而卡尔曼增益较大则正好相反。
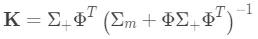
公式 3.卡尔曼增益计算,Σ₊是预测的协方差。
更新过程如下:
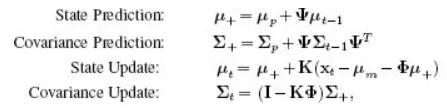
公式4. 使用卡尔曼增益的卡尔曼滤波学习过程。图片来自Simon JD Prince(2012)。
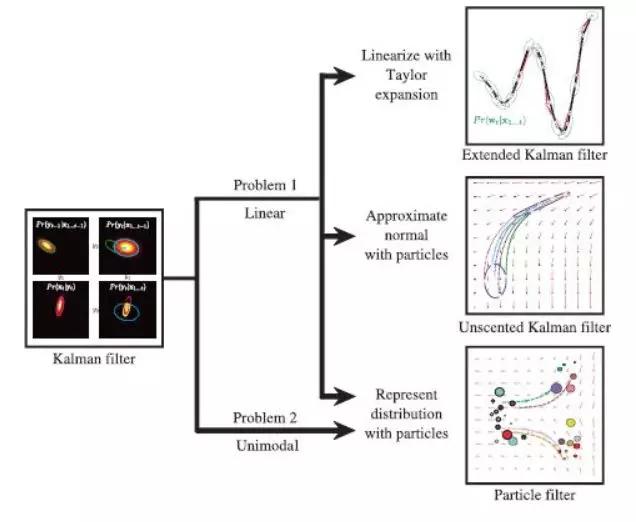
虽然这种方法非常有用,但它还存在一些问题。卡尔曼滤波假定单模态分布可以用线性函数表示。解决线性问题的两种方法是扩展卡尔曼滤波器(EFK)和无迹卡尔曼滤波器(UFK)。EFK使用泰勒展开来逼近线性关系,而UFK使用一组质量点近似表示正态,这些质量点具有与原始分布相同的均值和协方差。一旦确定了质量点,算法就通过非线性函数传递质量点以创建一组新的样本,然后将预测分布设置为正态分布,均值和协方差等效于变换点。
由卡尔曼滤波强加的单模分布假设意味着不能表示其他状态假设。粒子滤波是解决这些问题的常用方法。
图片来自Simon JD Prince(2012)
粒子滤波
粒子滤波允许通过空间中的粒子来表示多个假设,高维度需要更多粒子。每个粒子都被赋予一个权重,该权重表示其所代表的状态假设中的置信度。预测从原始加权粒子的采样开始,并从该分布中采样预测状态。测量校正根据粒子与观测数据的一致程度(数据关联任务)来调整权重。最后一步是对结果权重进行归一化,使总和为1,因此它们是0到1的概率分布。
图片来自Simon JD Prince(2012)。粒子滤波的步骤。
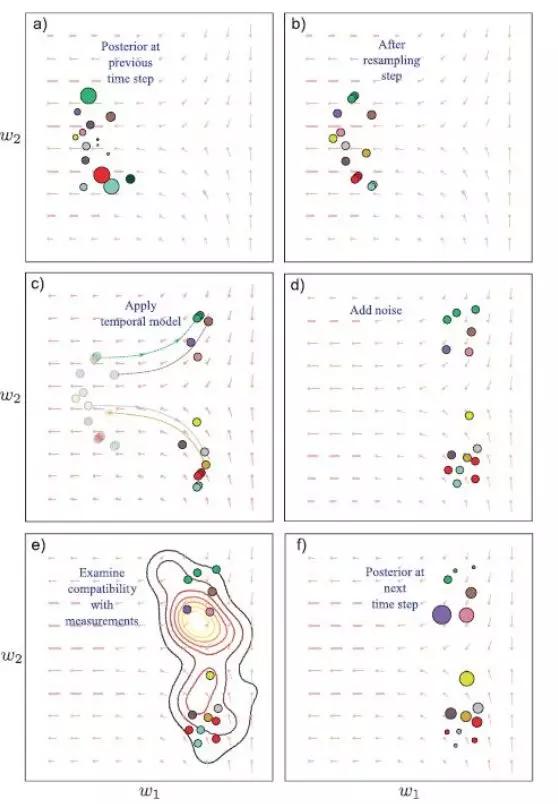
因为粒子的数量可以不断增多,因此对该算法的改进集中在如何降低采样的复杂性。重要性采样和Rao-Blackwellization分区是常用的两种方法。
研究现状
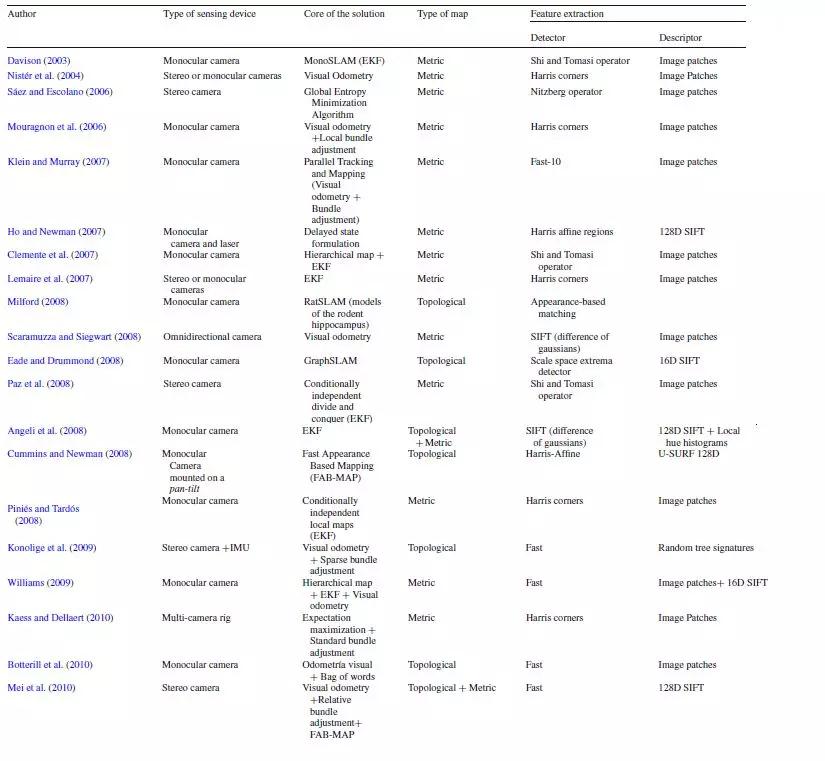
下图来自Fuentes-Pacheco, J., Ruiz-Ascencio, J., & Rendón-Mancha, J. M. (2012)的论文“Visual simultaneous localization and mapping: a survey”,总结了到2010年的SLAM中的一些方法。他们的研究分为几个方面。核心方案是使用学习算法,其中一些在上文讨论过。地图的类型是捕获环境几何属性的度量图,或者是描述不同位置之间的连接的拓扑图。
在线跟踪中最常用的功能是显著特征和标记。标记是在环境中由3D位置和外观描述的区域(Frintrop和Jensfelt,2008)。显著特征是由2D位置和外观描述的图像区域。深度学习技术通常用于在每个时间点描述并检测这些显着特征,以向系统添加更多信息。检测是识别环境中的显著元素的过程,描述是将对象转换为特征向量的过程。
表1来自J. Fuentes-Pacheco等人(2012年)。与特征提取相关的研究
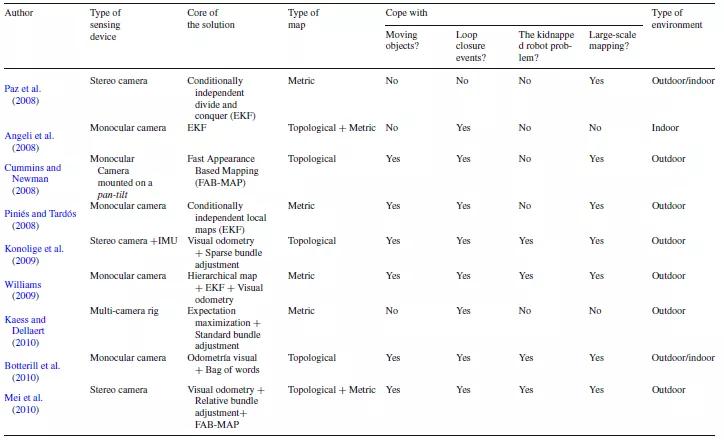
应用SLAM的方案有两种,一种是回环检测(loop closure),另一种是“机器人绑架(kidnapped robot)”。回环检测是识别已经访问过的任意长度的循环偏移,“机器人绑架”不使用先前的信息去映射环境。
表2仍然来自J. Fuentes-Pacheco等人。(2012)针对环境特定的方法。
总结
SLAM是自主导航中常用的状态时间建模的框架。它主要基于概率原理,对状态和测量的后验和先验概率分布以及两者之间的关系进行推断。这种方法的主要挑战是计算复杂。状态越多,测量越多,计算量越大,在准确性和复杂性之间进行权衡。
引用
[1] Fuentes-Pacheco, J., Ruiz-Ascencio, J., & Rendón-Mancha, J. M. (2012). Visual simultaneous localization and mapping: a survey. Artificial Intelligence Review, 43(1), 55–81. https://doi.org/10.1007/s10462-012-9365-8
[2] Durrant-Whyte, H., & Bailey, T. (2006). Simultaneous localization and mapping: Part I. IEEE Robotics and Automation Magazine, 13(2), 99–108. https://doi.org/10.1109/MRA.2006.1638022
[3] T. Bailey and H. Durrant-Whyte (2006). “Simultaneous localization and mapping (SLAM): part II,” in IEEE Robotics & Automation Magazine, vol. 13, no. 3, pp. 108–117. doi: 10.1109/MRA.2006.1678144
[4] Simon J. D. Prince (2012). Computer Vision: Models, Learning and Inference. Cambridge University Press.
[5] Murali, V., Chiu, H., & Jan, C. V. (2018). Utilizing Semantic Visual Landmarks for Precise Vehicle Navigation.
[6] Seymour, Z., Sikka, K., Chiu, H.-P., Samarasekera, S., & Kumar, R. (2019). Semantically-Aware Attentive Neural Embeddings for Long-Term 2D Visual Localization. (1).
[7] Fuentes-Pacheco, J., Ruiz-Ascencio, J., & Rendón-Mancha, J. M. (2012). Visual simultaneous localization and mapping: a survey. Artificial Intelligence Review, 43(1), 55–81. https://doi.org/10.1007/s10462-012-9365-8



编辑推荐




最新资讯
-
奇石乐推出用于DAQ数据采集系统的KiStudio
2025-04-28 17:51
-
全球首次!IVISTA 2023版修订版引入带灯光
2025-04-28 09:59
-
我国首批5G毫米波行业标准送审稿审查通过
2025-04-28 08:56
-
5/16 厦门- 新能源汽车电驱测试技术的创新
2025-04-28 08:53
-
国内首个汽车电磁防护技术验证体系EMTA正式
2025-04-28 08:49
