




 广告
广告





















































自动驾驶视觉感知模块的闭环迭代
2019-09-12 21:53:21· 来源:纽劢科技

在自动驾驶领域,包括感知在内,很多问题可以更好的用深度学习算法去解决,这是当今的一个趋势。如果有留意CVPR 2019或者今年arxiv上面比较新的论文的同学,也会
在自动驾驶领域,包括感知在内,很多问题可以更好的用深度学习算法去解决,这是当今的一个趋势。如果有留意CVPR 2019或者今年arxiv上面比较新的论文的同学,也会发现这一趋势。
在过去,传统机器学习算法需要手工设计特征,视觉感知落地往往变成一个特征工作问题。那么随着深度学习的不断发展,视觉感知算法的发展日新月异,可以通过网络设计来提升算法性能。同样的,不管传统机器学习、深度学习的视觉感知算法,尤其在自动驾驶领域,都需要某种程度的后处理算法来提升算法精度和鲁棒性。那么如果通过新的深度学习方法从而减轻这些人工设计的后处理步骤,也是自动驾驶视觉感知算法的一些新的尝试方向。
可以这么说,深度学习很大程度地提升了自动驾驶中视觉感知模块开发的效率。
数据在深度学习发展过程中起到了至关重要的作用,增加训练数据,尤其是有效数据,往往是感知性能提高的一个关键。在自动驾驶领域,视觉感知需要面对各种复杂场景,那么就会对数据本身提出更高的要求。
正是因为这样,深度学习所依赖的数据在视觉感知开发中有着无可替代的作用。基于这一点,本文将围绕以下三点进行介绍:当前比较主流的公开数据集,自动驾驶所面临的数据挑战,以及如何形成视觉感知模块的闭环迭代。
01、自动驾驶公开数据集
目前的一些自动驾驶公开数据集中,比较经典的有KITTI数据集,以及用于分割的CityScapes,还有NuTonomy公司提出的NuScenes数据集,伯克利开源的BDD。在CVPR 2019上,Waymo、Argo和Lyft也分别开放了一些自动驾驶相关的数据集。

自动驾驶中的公开数据集
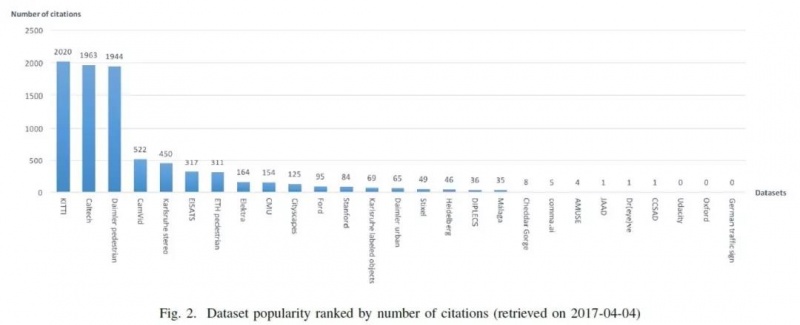
截至2017年时,KITTI是被引用最多的数据集。KITTI的传感器的配置、数据集的分类,比如说障碍物的分类,或者照片中有多少种类的分布的统计,有助于开发者构建数据集的时候去统计自己的数据。
数据统计有助于了解数据的分布,同样也会对算法benchmark有所帮助。
NuScenes开源的是一个比较大的公开数据集,同样包括了摄像头、激光雷达和毫米波雷达等信息。这些细分数据对自动驾驶公司自己收集数据提供了很大的参考。
此外,伯克利也推出了100K数据,其中包含了目标检测和图像分割,主要覆盖纽约、伯克利、三藩和湾区四个地方的数据采集。
02、自动驾驶的数据挑战
在有了大规模数据之后,我们还需要了解的是:模型它基本上是Garbage in, Garbage out。如果扔进去的是一些无用的信息,那么模型很难学到一些有用的信息。
因此这里要强调的是,视觉模型上线是一个闭环迭代过程,涵盖数据采集、数据清洗、数据标注、模型训练、模型测试,最终才可上线。
另外,在数据集中,难免出现一些错误或丢失。
噪声数据的清洗是工业界数据处理首要解决的问题。
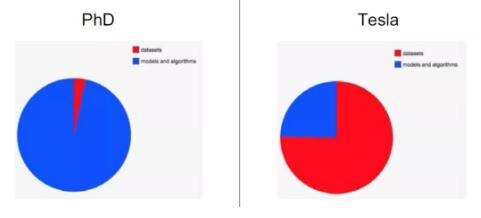
李飞飞的学生 Andrej Karpathy曾在一个演讲上指出,一个PhD学生可能95%的时间在学校设计算法,因为它可以使用一些公开的数据集;余下5%的时间可能就是下载数据,做一些评测。而他到了特斯拉领导自动驾驶小组,变成了75%时间专注在数据。这一点也说明了数据是极其重要的一环,对此我非常认同。
Building the Software 2 0 Stack (Andrej Karpathy), 2018
某种程度上说,自动驾驶的数据挑战,很多还是来源于视觉图像的一些挑战。比如视角、光照等变化,都可能对自动驾驶算法造成影响。
在自动驾驶数据中,很可能大多是一些比较简单的场景,比如:视野开阔,车少,车道线有比较清楚的样例。
但在实际场景中有很多更复杂场景,比如夜间虚线的车道线场景中,夜间光线比较弱,那么识别这些车道线其实是很难的,即使去做标注也很难去准确地把车道线给标出来。
另外,像是拥堵跟车时候拍到的物体、比较近距离的障碍物,这对车道线、障碍物标注或者算法设计都会有一些挑战。一个极端例子是cut-in:如果一辆车从旁边车道cut-in,那么它会挡住视野中的车道线,这对车道线标注、训练或者上线都会带来挑战。特别是有时候一辆大车会完全挡住所有的视线,这对车道线的算法会带来很大的挑战。

Cut-in
从中可以看到,自动驾驶如何高效地收集这些有效数据其实是很难的,而且这些数据大量都是不均衡的。如果想搜集这些数据场景,比如道路分叉,其实是比较费精力的一件事,因为即使是在高速上面或者环线上面,道路分叉占整个数据量的比例其实是很低的。覆盖更复杂的场景,是数据方面的一个挑战。
当场景定义结束后,有效数据的获得也很重要,最后是模型的迭代。
03、数据驱动闭环迭代
英特尔CEO曾做过类似的表述,自动驾驶数据量很大,如果要收集所有信息的话,大概是4000 GB/天,但是我们并不需要每时每刻都把所有信息收集起来。
数据方面要考虑的四大步骤:第一个是数据获取,即如何获取一些最有效、最关键信息;第二个数据存储;第三个是数据管理,即如何从中间拿到最有效信息、如何管理这些信息,使大家都能够快速便捷地获取这些信息进行算法开发;还有一个关键是数据标注。那么,如何打通数据获取到数据标注的这个闭环呢?
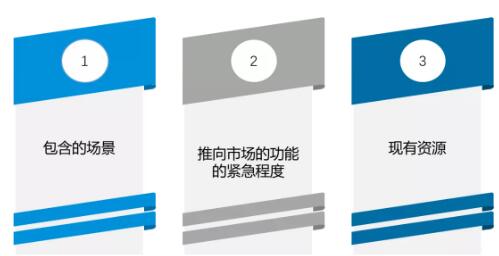
数据获取要平衡三个因素。第一个是包含场景,比如要包含各种天气、各种城市或者高速场景、各种车道线的细分类型直线/虚线,等等。第二个因素,要考虑推向市场的功能的紧急程度。比如模块迭代,因为从算法开发第一天就支持所有各种复杂场景并不现实,所以需要根据推向市场功能的紧急程度来定义要获取什么数据。第三个是基于现有资源。比如现有的人员,现有的算法。
数据获取
数据存储也有几个方面需要考虑:第一个是需要本地存储还是云端存储,如何更高效地利用云端或者本地的这些架构。第二是如何存储采集车上的数据,因为采集车运行一天或者连续跑很长时间,数据量是非常大的,可能很多时间会花费在如何从采集车上面把数据拷走。另外一个是数据安全如何保证。此外还有数据管理,多与存储相关。比如原来数据存在什么地方,或者需要存储哪些数据,如何使每个人都能便捷地读取这些数据也有利于整个开发效率的提升。
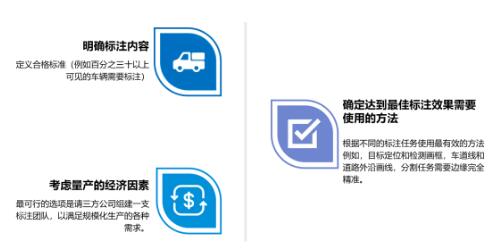
关于数据标注,上面介绍了几大公开数据集,每一个都有自己标注的一些定义,所以我们首先需要根据自己算法设计或者功能实现定义合理的标准。第二是要考虑量产经济因素,比如说和第三方合作,也要考虑如何让这些定义的标准能够使第三方快速接受。最后是确保达到最佳标准,因为标注即使是通过人工筛选、人工验证,还是有很多噪声涵盖其中,所以如何提升标注的准确性,也是很重要的一个因素。
数据标注
最后总结一下:视觉方案是一个闭环,从数据的采集到数据清洗,到拿到清洗有效数据之后的数据标注,再到从标注团队拿到标准数据之后进行模型训练或者内部评测,经过模型测试之后,如果达到要求模型即可上线,这是一个完整的过程。
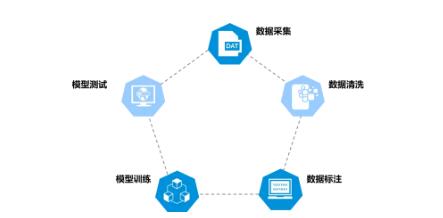
形成闭环
有了整个闭环的流程之后,即可支持模型的迭代,通过模型迭代不断解决上一个版本遇到的问题。一个模块或者视觉模块迭代的快慢,往往取决于提及的这几个步骤,比如数据采集,或者根据某个版本发现问题后进行的数据清洗,更准确的数据标注,模型内部的测试和上线。如果能形成一个快速的闭环,那么开发节奏会高效很多。
在过去,传统机器学习算法需要手工设计特征,视觉感知落地往往变成一个特征工作问题。那么随着深度学习的不断发展,视觉感知算法的发展日新月异,可以通过网络设计来提升算法性能。同样的,不管传统机器学习、深度学习的视觉感知算法,尤其在自动驾驶领域,都需要某种程度的后处理算法来提升算法精度和鲁棒性。那么如果通过新的深度学习方法从而减轻这些人工设计的后处理步骤,也是自动驾驶视觉感知算法的一些新的尝试方向。
可以这么说,深度学习很大程度地提升了自动驾驶中视觉感知模块开发的效率。
数据在深度学习发展过程中起到了至关重要的作用,增加训练数据,尤其是有效数据,往往是感知性能提高的一个关键。在自动驾驶领域,视觉感知需要面对各种复杂场景,那么就会对数据本身提出更高的要求。
正是因为这样,深度学习所依赖的数据在视觉感知开发中有着无可替代的作用。基于这一点,本文将围绕以下三点进行介绍:当前比较主流的公开数据集,自动驾驶所面临的数据挑战,以及如何形成视觉感知模块的闭环迭代。
01、自动驾驶公开数据集
目前的一些自动驾驶公开数据集中,比较经典的有KITTI数据集,以及用于分割的CityScapes,还有NuTonomy公司提出的NuScenes数据集,伯克利开源的BDD。在CVPR 2019上,Waymo、Argo和Lyft也分别开放了一些自动驾驶相关的数据集。
自动驾驶中的公开数据集
截至2017年时,KITTI是被引用最多的数据集。KITTI的传感器的配置、数据集的分类,比如说障碍物的分类,或者照片中有多少种类的分布的统计,有助于开发者构建数据集的时候去统计自己的数据。
数据统计有助于了解数据的分布,同样也会对算法benchmark有所帮助。
NuScenes开源的是一个比较大的公开数据集,同样包括了摄像头、激光雷达和毫米波雷达等信息。这些细分数据对自动驾驶公司自己收集数据提供了很大的参考。
此外,伯克利也推出了100K数据,其中包含了目标检测和图像分割,主要覆盖纽约、伯克利、三藩和湾区四个地方的数据采集。
02、自动驾驶的数据挑战
在有了大规模数据之后,我们还需要了解的是:模型它基本上是Garbage in, Garbage out。如果扔进去的是一些无用的信息,那么模型很难学到一些有用的信息。
因此这里要强调的是,视觉模型上线是一个闭环迭代过程,涵盖数据采集、数据清洗、数据标注、模型训练、模型测试,最终才可上线。
另外,在数据集中,难免出现一些错误或丢失。
噪声数据的清洗是工业界数据处理首要解决的问题。
李飞飞的学生 Andrej Karpathy曾在一个演讲上指出,一个PhD学生可能95%的时间在学校设计算法,因为它可以使用一些公开的数据集;余下5%的时间可能就是下载数据,做一些评测。而他到了特斯拉领导自动驾驶小组,变成了75%时间专注在数据。这一点也说明了数据是极其重要的一环,对此我非常认同。
Building the Software 2 0 Stack (Andrej Karpathy), 2018
某种程度上说,自动驾驶的数据挑战,很多还是来源于视觉图像的一些挑战。比如视角、光照等变化,都可能对自动驾驶算法造成影响。
在自动驾驶数据中,很可能大多是一些比较简单的场景,比如:视野开阔,车少,车道线有比较清楚的样例。
但在实际场景中有很多更复杂场景,比如夜间虚线的车道线场景中,夜间光线比较弱,那么识别这些车道线其实是很难的,即使去做标注也很难去准确地把车道线给标出来。
另外,像是拥堵跟车时候拍到的物体、比较近距离的障碍物,这对车道线、障碍物标注或者算法设计都会有一些挑战。一个极端例子是cut-in:如果一辆车从旁边车道cut-in,那么它会挡住视野中的车道线,这对车道线标注、训练或者上线都会带来挑战。特别是有时候一辆大车会完全挡住所有的视线,这对车道线的算法会带来很大的挑战。
Cut-in
从中可以看到,自动驾驶如何高效地收集这些有效数据其实是很难的,而且这些数据大量都是不均衡的。如果想搜集这些数据场景,比如道路分叉,其实是比较费精力的一件事,因为即使是在高速上面或者环线上面,道路分叉占整个数据量的比例其实是很低的。覆盖更复杂的场景,是数据方面的一个挑战。
当场景定义结束后,有效数据的获得也很重要,最后是模型的迭代。
03、数据驱动闭环迭代
英特尔CEO曾做过类似的表述,自动驾驶数据量很大,如果要收集所有信息的话,大概是4000 GB/天,但是我们并不需要每时每刻都把所有信息收集起来。
数据方面要考虑的四大步骤:第一个是数据获取,即如何获取一些最有效、最关键信息;第二个数据存储;第三个是数据管理,即如何从中间拿到最有效信息、如何管理这些信息,使大家都能够快速便捷地获取这些信息进行算法开发;还有一个关键是数据标注。那么,如何打通数据获取到数据标注的这个闭环呢?
数据获取要平衡三个因素。第一个是包含场景,比如要包含各种天气、各种城市或者高速场景、各种车道线的细分类型直线/虚线,等等。第二个因素,要考虑推向市场的功能的紧急程度。比如模块迭代,因为从算法开发第一天就支持所有各种复杂场景并不现实,所以需要根据推向市场功能的紧急程度来定义要获取什么数据。第三个是基于现有资源。比如现有的人员,现有的算法。
数据获取
数据存储也有几个方面需要考虑:第一个是需要本地存储还是云端存储,如何更高效地利用云端或者本地的这些架构。第二是如何存储采集车上的数据,因为采集车运行一天或者连续跑很长时间,数据量是非常大的,可能很多时间会花费在如何从采集车上面把数据拷走。另外一个是数据安全如何保证。此外还有数据管理,多与存储相关。比如原来数据存在什么地方,或者需要存储哪些数据,如何使每个人都能便捷地读取这些数据也有利于整个开发效率的提升。
关于数据标注,上面介绍了几大公开数据集,每一个都有自己标注的一些定义,所以我们首先需要根据自己算法设计或者功能实现定义合理的标准。第二是要考虑量产经济因素,比如说和第三方合作,也要考虑如何让这些定义的标准能够使第三方快速接受。最后是确保达到最佳标准,因为标注即使是通过人工筛选、人工验证,还是有很多噪声涵盖其中,所以如何提升标注的准确性,也是很重要的一个因素。
数据标注
最后总结一下:视觉方案是一个闭环,从数据的采集到数据清洗,到拿到清洗有效数据之后的数据标注,再到从标注团队拿到标准数据之后进行模型训练或者内部评测,经过模型测试之后,如果达到要求模型即可上线,这是一个完整的过程。
形成闭环
有了整个闭环的流程之后,即可支持模型的迭代,通过模型迭代不断解决上一个版本遇到的问题。一个模块或者视觉模块迭代的快慢,往往取决于提及的这几个步骤,比如数据采集,或者根据某个版本发现问题后进行的数据清洗,更准确的数据标注,模型内部的测试和上线。如果能形成一个快速的闭环,那么开发节奏会高效很多。



编辑推荐




最新资讯
-
奇石乐推出用于DAQ数据采集系统的KiStudio
2025-04-28 17:51
-
全球首次!IVISTA 2023版修订版引入带灯光
2025-04-28 09:59
-
我国首批5G毫米波行业标准送审稿审查通过
2025-04-28 08:56
-
5/16 厦门- 新能源汽车电驱测试技术的创新
2025-04-28 08:53
-
国内首个汽车电磁防护技术验证体系EMTA正式
2025-04-28 08:49
