




 广告
广告





















































GS3D:一种用于自动驾驶的高效3D物体检测框架
2019-10-08 23:27:25· 来源:同济智能汽车研究所

编者按:在自动驾驶中,对目标进行3D检测近年来受到了越来越多的关注。虽然可以通过激光雷达生成的点云获取3D信息,但是从经济性的角度考虑,我们更希望能够直接
编者按:在自动驾驶中,对目标进行3D检测近年来受到了越来越多的关注。虽然可以通过激光雷达生成的点云获取3D信息,但是从经济性的角度考虑,我们更希望能够直接从RGB相机中获取3D信息。这篇文章提出了在自动驾驶场景中基于单目图像并结合可见表面的视觉特征投影来进行3D目标检测的框架,达到了目前最先进的水平。这篇文章对相关领域的研究具有非常大的学习和借鉴价值。
本文摘自:CVPR2019
原文题目:"GS3D: An Efficient 3D Object Detection framework for Autonomous Driving"
原作者:Buyu Li,Wanli Ouyang,Lu Sheng等
摘要:本文提出了在自动驾驶场景中基于单个RGB图像的高效3D物体检测框架。本文所做的贡献是在没有使用点云或双目数据的条件下,从2D图像中提取底层3D信息并确定对象的精确3D边框。利用现成的2D物体检测工具,本文提出了一种巧妙的方法,可以有效地为每个预测的2D框确定粗糙的3D边框。然后将其作为guidance,通过改进来确定目标精确的3D边框。与先前仅使用从2D边框提取的特征进行3D边框生成的最先进方法相比,本文通过使用可见表面的视觉特征来获取对象的3D结构信息。表面的视觉特征用于消除仅使用2D边界框造成的表示模糊的问题。此外,本文研究了3D边框改进的不同方法,并发现具有质量意识损失的分类方法具有比回归更好的性能。在KITTI数据集评估中,本文的方法达到了当前基于单个RGB图像的3D目标检测的最高水平。
1、简介
3D目标检测是自动驾驶领域的研究热点之一。近年来,它在计算机视觉社区中引起了越来越多的关注。使用3D激光雷达,可以获取点云形式的物体的离散3D位置数据,但设备非常昂贵。相反,对于大多数车辆而言,车载RGB相机更便宜且更灵活,但是它们只能提供2D照片。因此,使用单个RGB相机的3D目标检测对于经济的自动驾驶系统而言变得重要并且具有挑战性。本文着重于只使用单目图像来进行3D目标检测。

图1.本文方法的关键思想:(a)本文首先预测可靠的2D边界框及其横摆角的方向。(b)基于预测的2D信息,本文利用巧妙的技术有效地确定相应对象的基本长方体,称为guidance。(c) 本文的模型将利用guidance 投影至二维图像上,再利用该投影中的可见表面来提取的特征以及它的紧密2D边界框来执行具有分类公式和质量感知损失的精确改进。
本文提出了一种基于有效框架3Dguidance并使用表面特征进行改进的3D目标检测框架(GS3D)。并且,本文仅使用单目RGB图像检测目标的3D信息。典型的单目图像3D检测方法有如下:Mono3d采用的是传统的二维检测框架,利用三维空间中的穷举滑动窗口作为proposal,任务是选择那些能够很好地覆盖物体的proposal。但是问题是3D空间比2D空间大得多,这需要更多的计算成本,但是这些计算不是必需的。

图2.仅使用2D边界框导致的特征表示歧义的示例。3D框彼此差异很大,只有左框是正确的,但它们对应的2D边界框完全相同。
本文的第二个观察到的方面,是可以通过利用3D框的可见表面来作为基础的3D信息。基于该guidance来进行下一步的优化,为了实现高精度,需要进一步分类以消除误报以及适当的改进来实现更好的定位。但是,仅使用2D边界框进行特征提取时缺少的信息会带来3D框表示模糊的问题。如图2所示,彼此大小不同的3D框具有相同的2D边界框。因此,该模型将采用与输入相同的特征,但是分类器预期会预测它们不同的置信度(左图所示为高置信度,图2中其他两张图片所示情况为低置信度)。仅从2D边界框,模型几乎不知道(指导的)原始参数是什么,但是却基于这些参数来预测残差,因此训练是没有效果的。为了解决这个问题,本文探究了2D图像中的基础3D信息,并提出了一种新方法,该方法采用从3D框投影的可见表面来解析特征。如图1(c)所示,分别提取可见表面的特征然后合并,以便利用结构信息来区分不同形式的3D框。
对于3D框的进一步修正,本文将传统的回归形式重新修改为分类形式,并为其设计了质量损失函数,结果显示这样对检测性能有了显著提高。
本文的主要贡献如下:
1.基于可靠的2D检测结果,本文提出了一种基于单张RGB图像的3D目标检测方法。该方法可以有效地获得目标的基本长方体轮廓。基本长方体提供了对象的位置,大小和方向的可靠近似,并作为进一步改进的guidance。
2.本文利用2D图像上投影3D框的可见表面中的潜在3D结构信息,并通过从这些表面提取的特征来克服以前方法中的特征模糊问题。通过表面特征的融合,该模型实现了更好的判断能力,提高了检测精度。
本文设计并研究了几种改进方法,并得出结论:基于离散分类的方法具有质量意识损失,比直接采用回归方法对3D框改进的效果要好得多。
本文在KITTI目标检测数据集上评估了本文提出的方法。实验表明,本文的提出方法在仅使用单个RGB图像的条件下效果超越了当前最先进的方法,甚至可以与使用立体数据的方法相媲美。
2、相关工作
随着对物体和场景的3D理解受到越来越多的关注。早期的方法主要使用低级特征或统计分析的方法来处理3D识别或恢复任务,而3D目标检测任务更具挑战性。
3D目标检测方法可以通过数据分为三类,即点云,多视角图像(视频或立体数据)和单目图像。基于点云的方法,可以直接获取三维空间中物体表面上点的坐标,因此与没有点云的方法相比,它们可以轻松获得更高的精度。基于多视图的方法,可以使用从不同视角的图像计算的视差来获得深度图。虽然基于点云和立体数据的方法具有更准确的3D推理信息,但是使用单目RGB相机更加便宜和便利。
与本文最相关的文献是那些在自动驾驶场景中使用单个RGB图像进行3D物体检测的文献。由于缺乏3D空间信息,因此最具挑战性。最近的许多文章的重点都在单目图像上。Mono3d通过使用3D滑动窗口解决了这个问题。它详尽地从几个预定义的3D区域中采集3D的proposals(候选框)。然后,它利用分段,形状,上下文和位置的复杂特征来过滤不可能的proposals,并最终通过分类器选择最佳的proposals。
Mono3d的复杂性带来了严重的低效问题。而本文设计了一种基于纯投影几何的方法,并采用合理的假设,可以有效地生成数量少得多但精度更高的3D proposals。
Mono3d的复杂性带来了严重的低效问题。而本文设计了一种基于纯投影几何的方法,并采用合理的假设,可以有效地生成数量少得多但精度更高的3D proposals。
3、问题描述
本文采用KITTI数据集的3D坐标系:坐标原点在摄像机中心, x轴指向2D图像平面的右侧, y轴指向下方,z轴指向与图像平面正交代表深度。3D边框表示为。这里是盒子的大小(宽度,高度和长度),是底部中心的坐标,它遵循KITTI注释。尺寸和中心坐标以米为单位测量。分别围绕y轴,x轴和z轴旋转。由于本文的目标物体都在地面上,本文只考虑θ旋转,就像之前的所有工作一样。2D边界框用特定标记表示,即,其中是二维框的中心。






4、GS3D
4.1 概观
图5表示了本文所提出的框架的概述。该框架将单个RGB图像作为输入,并且包括以下步骤:1)利用基于CNN的检测器来获得可靠的2D边界框和目标的观察方向。该子网称为2D + O(orientation)子网。2)将获得的2D边界框和方向与关于驾驶场景的先验知识一起使用,以生成称为guidance的基本长方体。3)guidance投影在图像平面上。从2D边界框和可见表面提取特征。这些特征被融合为可区分的结构信息,用于消除特征模糊。4)融合的特征被另一个称为3D子网的CNN用于重新指导。3D检测被认为是分类问题,质量感知分类损失用于学习分类器和CNN特征。
4.2 二维检测和方向预测
对于2D检测,本文通过添加新的方向预测分支以获得更快的R-CNN框架。细节如图3所示。

图3. 2D + O子网头部的详细信息。所有线路连接都代表全连接层。
具体而言,CNN作为2D + O子网用于从图像中提取特征,然后区域提议网络生成候选2D边框提议(proposals)。根据这些提议,ROI池化层用于提取RoI特征,然后将其用于分类,以及边界框的回归和方向估计。在2D + O子网中估计的方向是目标的观察角度,其与目标的外观直接相关。本文将观察角度表示为α,以便将其与全局旋转θ区分开。α和θ都在KITTI数据集中注释,它们的几何关系如图4所示。

图4.观察角α和全局旋转角θ的俯视图。蓝色箭头表示观察轴,红色箭头表示汽车的前进方向。由于它是右手坐标系,正向旋转方向是顺时针方向。

图5.3D目标检测范例概述。基于CNN的模型(2D + O子网)用于获得2D边界框和目标的观察方向。然后通过本文提出的算法使用得到的2D框和投影矩阵来生成指导。从可见表面提取的特征以及投影指导的2D边界框被改进模型(3D子网)利用。改进模型不是直接回归,而是采用具有质量感知损失的分类公式,以获得更准确的结果。
4.3 guidance生成
基于可靠的2D检测结果,本文可以估算每个2D边界框的3D框。具体来说,本文的目标是获得指导,给定2D框,观察角α和摄像机内参矩阵K。


4.3.1获取指导大小
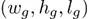
在自动驾驶场景中,相同类别的实例的大小分布是低方差和单峰的。由于目标是由2D子网预测的,因此本文只使用针对具有相同类别的指导的训练数据来计算特定类的指导大小。所以本文有,这是依赖于不同的类别的(为了便于表示,类别没有出现在等式中)。


4.3.2估算指导位置

如第3节所述,指的是底面中心,表示为。因此,本文研究底部中心的特征,并提出一个精心设计的方法。


本文的估算方法基于自动驾驶场景设置中的发现。物体3D边框的顶部中心在2D平面上具有稳定的投影,非常接近2D边框的顶部中点,并且3D底部中心具有类似于在2D边框上方和附近的稳定投影。这一发现可以通过以下事实来解释:大多数物体的顶部位置具有非常接近2D图像的消失线的投影,因为摄像机设置在数据采集车辆的顶部和驾驶场景中的其他物体有相似的高度。
使用预测的2D框,其中是框中心,本文有顶部中点和底部中点。然后得到大约有均匀形式的投影顶部中心和底部中心,其中λ来自训练数据的统计结果。利用已知的相机内参矩阵K,本文可以获得标准化的3D坐标,用于指导底部中心,和顶部中心,如下所示:










如果深度d已知,则可通过以下方式获得:
所以本文现在的目标是获得d。本文可以通过等式(1)计算顶部中心的归一化3D坐标。底部中心和顶部中心都有标准化高度。由于已经获得了的引导高度,因此本文有。最后本文有。




4.3.3计算指导方向θ
从图4可以看出,观察角度α与全局旋转角度θ之间的关系是:

式中,和α可通过先前的估算获得。

4.4 表面特征提取
本文使用给定3D框的投影表面区域(guidance)来提取3D结构特定的特征,以便更准确地确定。图6中示出了一个例子,可见投影表面分别对应于浅红色,绿色和蓝色所示的物体的顶部,左侧和后部。
由于所有目标物体都在地面上,因此底部表面始终不可见,本文使用顶部表面来提取特征。对于其他4个表面,它们的可见性可以通过目标的观察方向α来确定。在图4所示的KITTI坐标系中,有,观察者的右手方向为零角度,即,顺时针方向为正向旋转。因此,当为前表面可见,当为后表面可见,时右侧可见,否则左侧可见。

图6.通过透视变换从3D框的投影表面中提取特征的可视化。
通过透视变换将可见表面区域中的特征扭曲成规则形状(例如,5×5特征图)。具体而言,对于可见表面F,本文首先使用相机投影矩阵在图像平面中获得四边形,然后根据网络的步幅在特征图上计算缩放的四边形。利用4个角的坐标和5x5图的4个角,本文可以得到透视变换矩阵P。设X,Y分别表示透视变换前后的特征映射。具有X坐标(i,j)的Y上的值通过以下等式计算:

通常(u,v)不是整数坐标,本文使用最接近的整数坐标和双线性插值来获得值。可见表面的提取特征是连接的,本文使用卷积层来压缩通道的数量并将信息融合在不同的表面上。如图7所示,本文还从2D边框中提取特征以提供上下文信息。2D边框特征与融合表面特征连接在一起,它们最终用于改进3D边框。

图7. 3D子网头部的详细信息。
4.5 改进方法
4.5.1残差回归
使用候选框和目标基础,残差可以写为:



常用的方法是通过回归模型预测残差。
4.5.2分类方法
大范围内的回归通常不会比离散分类更好,因此本文将残差回归转换为3D边框改进的分类公式。主要思想是将残差范围分成几个区间,并将残差值分类为一个区间。
将表示为第i个指导(guidance)与其对应的地面实况3D设置的区别,其中。计算训练数据中的标准偏差。然后本文将指定为描述符d的间隔的中心,并且每个间隔的长度为。根据的范围选择。由于指导可能来自误报的2D框,本文将区间视为多个二元分类问题。在训练期间,如果指导的2D边框不能与任何地面实况相匹配,则所有区间的分类概率将接近0。通过这种方式,本文可以将指导视为背景,如果所有类别的信息都非常低,则可以在推理期间拒绝它。





4.5.3偏移后的分类
由于将2D区域映射到3D空间是一个未确定的问题,本文进一步考虑从3D坐标中的偏差开始。具体而言,每个类(残差区间)使用最相关的区域(相应的残差移位后的引导投影)来为自身提取单个特征。所有剩余的间隔的分类都可以共享参数。
该模块的作用指在原来的guidance的基础上,对guidance的长宽高进行4.5.2节中所给方差的偏移,偏移完成后会得到一系列的3D候选框,然后对这些候选框与真值进行比较,得到分数最高的那个候选框即为最后检测的结果。
4.5.4质量意识损失
本文期望分类中预测的置信度反映相应类别的目标边框的质量,以便更准确的目标边框获得更高的分数。这很重要,因为AP(平均精度)是通过对候选框的分数进行排序来计算的。但是,常用的0/1标签不适用于此问题,因为无论质量如何变化,模型都被迫为所有正候选者预测1。受2D检测损失的启发,本文将0/1标签更改为质量感知形式:

其中ov是目标框与地面实况之间的3D重叠。本文使用BCE作为损失函数:

5、实验
本文在KITTI目标检测数据集上评估本文的框架。它包括7,481个训练和7,518个测试图像。本文的实验与之前其他的相关工作一样只针对汽车的类别。
5.1、实施细节
5.1.1网络设置
本文的2D子网和3D子网都基于VGG16网络架构。2D子网在ImageNet数据集上进行了预训练。并且2D子网训练模型用于初始化训练中的3D子网参数。
5.1.2优化
本文使用Caffe深度学习框架进行训练和评估。在训练期间,本文将图像放大2倍,并使用4个GPU,每个GPU上同时训练一张图像。本文采用SGD优化器,在第一个30K迭代中基本学习率为0.001,并在后续的10K迭代中将其降低到0.0001。
5.2、消融研究
5.2.1二维检测和定位
由于本文的工作重点是3D检测,本文不遗余力地调整超参数(例如损失权重,anchor的尺寸)以获得2D模型的最佳性能。本文按照标准的KITTI设置评估了2D模型的平均精度(AP)和平均方向相似度(AOS)。得到结果并与表2中其他最先进的工作进行了比较。本文的结果优于或与其他方法相当,尽管Deep3Dbox具有更高的AP。此外,虽然Deep3DBox使用更好的2D边框来进行3D边框估计,但本文的3D结果大大超过了他们的范围(表1),这突出了本文的3D边框检测方法的强度。
5.2.2指导(guidance)生成
根据训练数据的统计数据,本文将,,设置为指导大小,将设置为预测底部中心的移位。


为了更好地评估准确性,本文使用Recallloc和Recall3D度量。对于Recallloc,计算候选框中心与地面实况之间的欧几里德距离,如果候选框的距离在阈值范围内,则调用地面实况框。Recall3D类似于从距离到3D重叠的标准。
如表3所示,本文还将本文的指导建议与Mono3D的召回建议进行了比较,因为它们在3D检测框架中具有相似的作用。结果表明比生成Mono3D的复杂提议方法更有效。
注意,指导(guidance)的数量恰好等于2D检测到的边框的数量,其与地面实况具有相同的数量级。所以Recall3D的指导与AP3D类似,本文改进的3D边框可以达到超过指导Recall值的AP。
5.2.3改进粗糙的3D框
表5中给出了表面特征,分类公式和质量意识损失贡献的消融研究。
本文首先在先前的工作中使用直接残差回归训练基线模型。并且比较基准仅使用从图像的特征图汇集的引导区域(边界框)特征。
然后本文采用图7中的网络架构并训练表面特征识别模型。利用表面特征提供3D结构可区分的信息,回归精度得到改善。对于分类制定的改进,分析训练集上每个维度的的分布,如表4所示。如第4.5.2节所述,本文将每个维度的区间长度设置为。本文选择用于和,主要是根据超过std比率的范围。
在确定了类的参数后,本文使用分类公式而不是直接回归的方法进行实验。还进行了使用shift后的特征进行分类的比较实验。在表5中,“+ cls”和“+ scls”分别代表这两种方法。本文可以看到两类制定的方法都超过了回归方法。基于固定特征的方法在AP@0.5中表现更好,而基于移位特征的方法在AP@0.7中表现更好。
表1.使用AP3D的度量评估的汽车类别的KITTI的3D检测精度。结果在两个验证集 / 上。 “额外”是指培训中使用的额外数据或标签。“scls”表示使用移位特征进行分类的方法。
表2.在KITTI数据集的 / 中评估的汽车类别的2D检测和方向结果的比较。仅显示moderate标准下的结果,即KITTI的原始度量,以便于表的大小。
表3.与Mono3D相比,本文的结果的Recallloc和Recall3D。Recall3D的IoU阈值为0.5。这些是在集上评估的。

表4. 对训练数据的分布分析
最后,本文将基于0-1标签的损失更改为第4.5.4节中介绍的质量感知形式。在基于分类的两种方法中都获得了显著的增益。
5.3 与其他方法比较
本文将本文的工作与基于最先进RGB图像的3D目标检测方法进行比较:Mono3D ,Deep3DBox ,DeepManta ,MF3D 和3DOP 。
除了单个RGB图像之外,大多数这些方法还需要额外的数据或标签。3DOP是基于立体数据的方法。Mono3D需要分割数据。DeepManta需要3D CAD数据和顶点进行3D模型预测。MF3D采用MonoDepth中的模型进行视差预测,实际上是对立体数据进行训练。而只有Deep3DBox以及本文的工作,不需要额外的数据或标签。
表5.KITTI 组中汽车类别的3D检测结果的消融研究。“Modr”在这里意味着难度适中。并且“+ surf”,“+ cls”,“+ scls”,“+qua”分别代表表面特征,类别公式,基于shift的类别表达和质量意识损失的使用。
AP3D:本文的3D检测评估的主要指标是官方3D平均精度(AP3D)的KITTI:如果检测框具有重叠(IoU)且地面实况框大于阈值IoU = 0.7,则认为检测框为真阳性。本文还显示了与IoU = 0.5的结果比较。正如本文在表1中所看到的,本文的方法在官方度量(IoU = 0.7)中大大超过了其他工作,而3DOP在IoU = 0.5时评估的性能更好。这表明本文的方法可以为某些良好的指导实现精确的结果,但不善于纠正大部分偏离的指导。推理时间也显示在此表中,这表明了本文方法的效率。
ALP:由于DeepMANTA仅提供在平均本地化精度(ALP)度量[1]中评估的结果,因此本文还在此度量标准中进行结果比较。如表6所示,本文的方法在当前最先进的工作中非常出色,只是3DOP在这个指标中优于本文。由于ALP仅关注位置精度并且不考虑尺寸和旋转,因此其反映3D盒子的性能的能力可能不如3D重叠。
图8.本文的3D检测结果的定性图示
表6.使用ALP度量评估的汽车类别的3D检测。结果在两个验证集 / 中。“额外”是指培训中使用的额外数据或标签。

测试集的结果:在所有已发表的单目3D检测工作中,只有MF3D显示了在官方测试集上评估的结果。他们的结果与本文的结果比较如表7所示。
本文只提交一次,因此没有超参数搜索技巧。但即便如此,本文的方法也胜过其他工作。请注意,MF3D和本文在测试集上的结果与验证集上的结果相比有差距(表1)。这很可能是由于训练和测试集之间的数据分配差距造成的,因为KITTI训练集非常小。
5.4 定性结果
图8显示了本文方法的一些定性结果。本文的方法在可以处理不同的场景,它在距离相机不同距离的物体的检测中仍然非常稳定。当场景拥挤时,本文的方法在大多数情况下仍然表现良好。最后一行中两个图像中的红色框显示了本文工作的典型故障情况。在左图中,右下角的车厢(红色)位置与真车有明显的偏差。在右图中,本文的模型将红色虚线框误认为是负框。本文的方法不善于处理图像边界上的对象(通常使用遮挡或截断)。需要进一步努力来解决这个问题。
表7.本文在官方测试集上的3D检测结果
6、结论
在本文中,本文提出了一种用于自动驾驶的单目3D目标检测框架。本文利用成熟的2D检测技术和投影知识,有效地生成称为guidance的基本3D边框。基于该guidance,进行进一步的改进以实现高精度。本文利用表面特征中潜在的三维结构信息,消除了仅使用二维边框造成的表示模糊。本文将残差回归问题重新划分为分类,这更容易受到良好的训练。本文使用质量意识损失来增强模型的辨别能力。实验表明,本文的框架达到了最高的检测水平,并且作为仅使用单个RGB图像的方法,没有任何额外的数据或标签用于训练。



编辑推荐




最新资讯
-
沃尔沃汽车:创新驱动的豪华品牌
2025-04-24 18:16
-
飞书项目落地ASPICE解决方案,助力汽车软件
2025-04-24 09:59
-
驾驶员监控系统DMS合规认证的“中西结合”
2025-04-24 08:23
-
自动驾驶汽车测试关键行人场景生成
2025-04-23 17:12
-
R171.01对DCAS的要求⑧
2025-04-23 17:08
