




 广告
广告





















































鲁棒的多层次大范围定位算法
2020-11-10 22:06:36· 来源:同济智能汽车研究所 作者:SLAM研究组

编者按:在自动驾驶任务中,鲁棒的高精度定位信息对后续的决策规划等模块至关重要。近年来视觉定位技术迅速发展,总体可分为基于图像级全局特征匹配和基于局部特
编者按:在自动驾驶任务中,鲁棒的高精度定位信息对后续的决策规划等模块至关重要。近年来视觉定位技术迅速发展,总体可分为基于图像级全局特征匹配和基于局部特征直接匹配两类。基于图像级全局特征匹配的方法类似于图像检索,速度快且鲁棒,但精度较低;基于局部特征的2D-3D匹配的方法依赖于关键点的穷举匹配,虽然在精度方面有所提升,但是效率低,鲁棒性差。本文结合两类方法的优势提出了分层的定位方法,可实现高精度、鲁棒的、实时的定位效果。
本文译自:
From Coarse to Fine: Robust Hierarchical Localization at Large Scale
文章来源:
Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, vol. 2019-June, pp. 12708–12717(2019)
作者:
Yinlong Liu, Guang Chen and Alois Knoll
Paul-Edouard Sarlin, Cesar Cadena, Roland Siegwart, Marcin Dymczyk
原文链接:
https://arxiv.org/abs/1812.03506
摘要:鲁棒的高精度定位是许多应用的关键,比如自动驾驶、移动机器人,但是这仍是一项具有挑战的任务,尤其是在大场景和外观特征显著变化的情况下。最先进的定位方法在精度、鲁棒性及实时性上都有待提升,本文提出了一种基于卷积神经网络(CNN)的分层定位方法,该方法可以同时预测局部特征和全局特征。我们的由粗到精的分层定位方法:首先利用全局特征进行全局检索获取候选位置,然后通过局部特征匹配候选位置中的局部特征,这种分层的方法节省了大量的时间,使得系统适用于实时操作。通过学习获取的描述符在定位精度和鲁棒性上都得到了提升,并且在两个公开数据集(Aachen, RobotCar)上都取得了最优成绩。
关键词:无人驾驶,视觉定位,图像检索
1 前言
在现有的3D模型中进行精确的6自由度定位是计算机视觉的核心功能之一,它可以应用于很多新的场景,比如在没有GPS环境下[8,31,33,6]的自动驾驶和具有增强现实功能的消费设备[32,24],其中厘米级的6自由度位姿估计对于无人车的安全行驶以及完全沉浸式体验至关重要。更广泛的说,视觉定位是计算机视觉任务的一个关键组成部分,如SfM或SLAM。视觉定位的应用越来越广泛,这就要求在室内和室外都能可靠的工作,不受天气、光照或季节变化的影响。
目前主流的方法主要依赖于使用局部描述符估计查询图像中2D关键点与稀疏模型中3D点的对应关系。这类方法虽然精度较高,但是效率较低[51,55,43];对效率进行改进后,精度便下降了[29]。在这两种情况下,经典方法的鲁棒性受到了手工制作局部特征不变性的限制[9,28]。卷积神经网络(CNN)的最新特征在低计算成本下表现出无与伦比的鲁棒性[14,15,34]。然而,直到最近[52]才将它们应用于视觉定位问题,而且只是以一种密集的、高计算成本的方式。学习得到的稀疏描述子表现出了许多优点[14,38],但未应用到定位任务上。基于图像检索的定位方法在鲁棒性和效率方面都得到了优秀的结果,但精度较差。
在这篇论文中,我们建议使用网络学习到的特征来提升定位的鲁棒性和效率,利用分层定位方法平衡效率和精度两者间的关系。与人类定位相似,我们采用由粗略到精细的位姿估计方法,该方法利用了全局描述符和局部特征,在大型场景中取得了很好的效果(图1)。我们展示了经过学习的描述符在挑战性条件下实现了无与伦比的鲁棒性,而经学习得到的关键点由于其更高的可重复性降低了计算成本。为了进一步提高这种方法的效率,我们提出了一种层次特征网络(HF-Net),它可以同时估算全局和局部特征,从而最大程度共享计算。我们展示了如何使用多任务蒸馏以灵活的方式训练这种压缩模型,通过多任务蒸馏将多个最新的特征预测模型压缩成一个模型,获得了高效率、高精度的定位结果。这种特殊的蒸馏方法可应用于视觉定位以外的任务,比如一些需要多模型预测且又需要低计算成本的任务。我们的主要贡献如下:
- 我们在多个具有挑战性的公开视觉定位数据集上取得了最优定位结果;
- 我们提出了一种可以有效预测层次结构特征的网络HF-Net,以实现快速而鲁棒的定位;
- 我们展示了多任务蒸馏的实用性和有效性,以提升异构的预测器的实时性。

图1分层定位。首先使用全局特征进行检索获取候选地点,然后使用局部特征匹配查询图片与候选地点,从匹配成功的局部特征中估计6自由度位姿。
2 相关工作
在本节中,我们将回顾与我们方法相关的其他工作。
6自由度视觉定位传统上分为基于结构的定位方法和基于图像的定位方法。前者执行查询图像的2D关键点和SfM模型的3D点之间的局部描述符直接匹配[51,55,43,27,52],这些方法可以估算精确的位姿,但通常依赖穷举匹配,计算量大;同时,这种方法在外观发生强烈变化的情况下不够鲁棒,如白天和夜间、四季变化。有些方法直接从单张图片中回归位姿[7,22],但是精度较低。基于图像的方法与图像检索相关[2,56,57],并且只能提供数据库离散化的近似位姿,对于许多应用而言不够精确[44,52]。然而,由于它们依赖于全局图像范围内的信息,因此比直接局部匹配更具有鲁棒性,但最先进的图像检索是基于大型深度学习模型的,计算量较大。
可扩展定位通过使用廉价的特征来提取、存储和匹配,降低计算成本来处理额外的计算约束[9,26,39]。虽然改善了移动设备上的运行时间,但进一步削弱了定位的鲁棒性[29]。分层定位将问题分为全局粗略搜索,然后进行精细姿态估计。最近,[42]建议使用图像检索在地图级别进行搜索并通过匹配手工提取的局部特征进行定位。正如第3节中所述,其鲁棒性和效率受到底层描述符和结构的限制。
局部特征学习:经网络学习的特征被提出用于代替手工制作的特征。稠密特征可用于图像匹配[11,15,37,40]和定位[52,44],然而,有限的计算能力难以匹配密集的特征。由关键点和描述符组成的稀疏特征为手工制作的特征提供了优秀的替代品,并且表现出出色的性能[14,38,18]。稀疏特征可以很容易的从密集特征中采样获得,预测速度快,更适合在移动设备上部署。基于CNN的关键点检测器也被证明优于经典方法,尽管训练过程很困难。其中,SuperPoint[14]采用自监督学习,DELF[36]对于路标识别任务采用注意力机制优化。
移动设备上的深度学习:将高精度和鲁棒的模型部署到移动设备上并非易事。多任务学习使得无需手动调整即可有效的跨任务共享计算[23,10,50],从而减小所需网络的规模;蒸馏[20]可以帮助从一个已训练过的较大的网络[41,59,60]中训练一个较小的网络,但通常不适用于多任务环境。
我们的方法是第一种结合上述领域的先进技术来优化效率和鲁棒性的方法。所提出的方法利用这些算法的协同作用提供一个有竞争力的大范围定位解决方案,并可应用于资源受限的实时在线应用程序。
3 分层定位

图2 HF-Net的分层定位结构
上 图 2 为分层定位的 结构图,主要可分为以下三个步骤:
先验检索:通过使用全局描述符将查询图像与数据库图像匹配,在地图级别执行粗略搜索。利用K近邻找到K个先验帧表示地图中的候选位置,因为SfM模型中的3D点远多于数据库中图像数,所以该方法是可行的。
共视聚类:根据共视对k个先验帧进行聚类,相当于在SfM模型中找到先验帧所在的位置。
局部特征匹配:对于每个位置,依次将查询图像中检测到的2D关键点与该位置中包含的3D点进行匹配,并尝试在RANSAC中使用PnP进行几何一致性检验来估计6自由度位姿。因为3D点的数量明显低于整个模型,所以局部特征匹配也是有效的。当估计出一个有效的位姿,算法便停止。
4 HF-Net
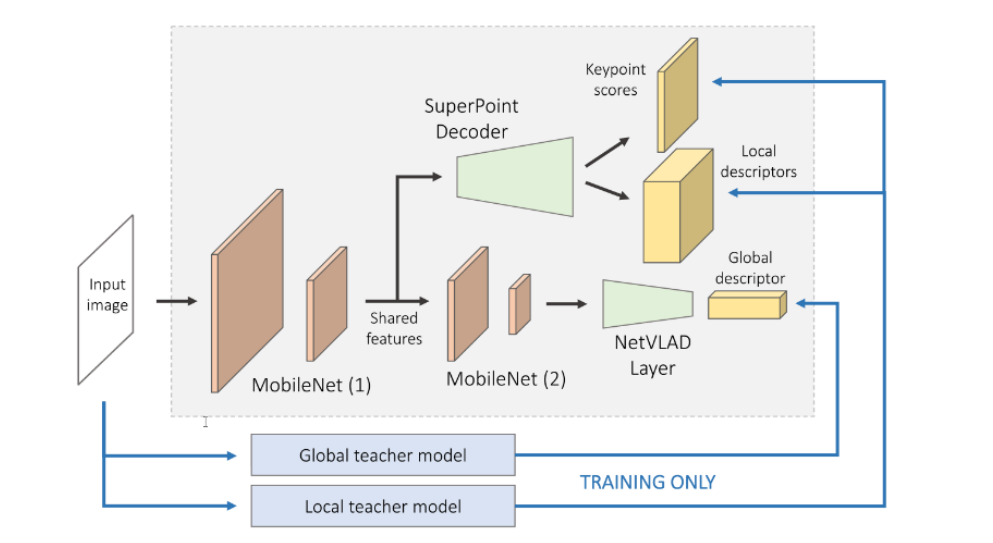
图3 HF-Net网络架构。输入为单帧图片,输出为全局描述符、稠密局部特征描述符及关键点检测分数。通过教师学生网络多任务蒸馏训练得到。
4.1 HF-Net 网络结构
卷积神经网络本质上表现出一种层次结构,这种结构很适合局部特征和全局特征的联合预测,并且计算成本较低。HF-Net如图3所示,由一个编码器和三个预测头组成:a.关键点检测分数;b.稠密局部特征描述符;c.全局图像描述符。
HF-Net的编码器由MobileNet[41]构成,在MobileNet的最后一个特征图后面添加一个NetVlad层[2]用来计算全局描述符。使用SuperPoint架构将MobileNet生成的局部特征进行解码,以得到关键点和稠密的局部描述子,这比使用卷积作为解码器向上采样特征快得多。因为需要更高的空间分辨率来保存空间上的特征,因此局部特征的语义级别低于全局描述符,所以局部特征预测分支比全局特征特征预测分支更早的从MobileNet中分出。
4.2训练过程
数据匮乏:目前没有符合如下两个条件的数据集:(1)在全局图像级别显示足够的感知多样性,例如,在各种条件下,如白天、夜晚、四季;(2)匹配图像之间包含真实的局部对应关系,这些对应关系通常是从SfM模型[47,49]计算的密集深度[38]中恢复出来的,而图像检索所需的数据规模难以构建SfM模型。
数据增强:自监督方法不依赖于对应关系,比如SuperPoint,需要大量的数据扩充,这是使得局部描述子具有鲁棒性的关键。虽然数据增强通常能够很好的捕捉到局部层次上真实世界的变化,但它会破坏图像的全局一致性,使全局描述子的学习变得非常困难。
多任务蒸馏:多任务蒸馏是我们解决数据问题的方案,采用蒸馏法直接从现有经过训练的教师模型中学习全局和局部特征。其训练设置允许使用任意数据集,因为可以从教师网络中获得无限量的标记数据。利用目前最新的网络作为教师网络,用于监督局部和全局特征的生成。通过学习最新网络的输出来优化当前网络的权重参数,以得到更好的全局和局部特征。多任务学习的最新方法使学生网络能够最佳地复制所有教师网络,而无需手动调整权重以平衡损失。损失函数定义如下:
其中d表示描述符,上标g和l分别表示全局和局部描述符,下标s和t分别表示学生网络和教师网络,p表示关键点检测分数,w表示权重。更一般的说,我们的多任务蒸馏公式可以应用于任何需要多个预测且需要保持计算效率的应用,特别是训练任务所需数据收集成本很高的情况。
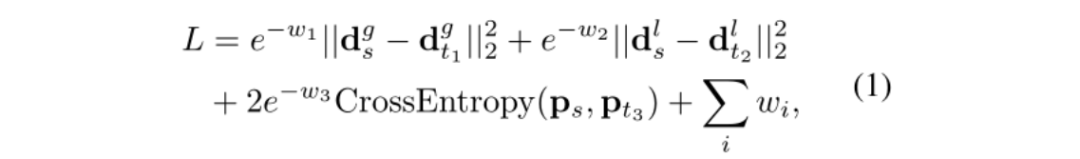
5 实验
5.1局部特征评估
数据集:在HPatches[4]和SfM[38]中评估,这两个数据集为2D和3D场景提供了图像对之间的稠密的真实对应关系。HPatches包含116个照明和视点变化的平面场景,每个场景有5个图像对;SfM由[19,53]收集的图像经过[38]三维重建而成,真值对应关系从每幅图像的稠密深度图和使用COLMAP计算的相对6自由度姿态获得。我们选取10个序列用于评估,每个序列由50个图像对组成。
性能指标:对于关键点检测器,评估其重复性和定位误差;对于关键点描述符,评估其平均精度和匹配得分。
评估方法:对于关键点检测器,评估了传统的DoG和Harris[17]方法以及基于深度学习的LF-Net[12]和SuperPoint;对于关键点描述符,评估了传统的Root-SIFT和基于深度学习的LF-Net、SuperPoint以及DOAP和NetVlad的特征图,并对两个特征图都使用SuperPoint作为关键点检测器。
关键点检测器:评估结果如表1所示,Harris拥有最高的重复性和最大的定位误差;相反,DoG的可重复性较差,但误差小;SuperPoint在重复性和误差之间取得了较好的平衡;LF-Net的性能与SuperPoint相似,但其计算量较大。
表1 特征点检测器评估表。Rep表示可重复性,MLE表示平均误差。
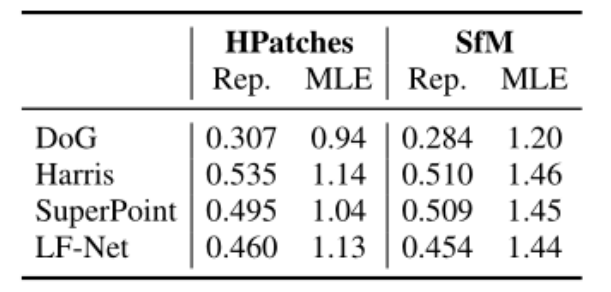
关键点描述符:DOAP在SfM数据集上所有指标均优于NetVlad,但其在HPatches上训练,故无法评估;NetVlad在SfM上具有良好的位姿估计性能,但是匹配精度差;SuperPoint在各项指标上均表现优秀;
表2 关键点描述符评估表
MS表示匹配得分,mPA表示平均精度,Homography表示单应性变化图像的正确率,Pose表示位姿正确率。
5.2分层定位评估
数据集:每个数据集由一组参考图像和稀疏SfM模型组成。Aachen昼夜数据集[45]包含4328张欧洲老城的白天数据库图像,以及分别在白天和夜间条件下采集的824张和98张查询图像。RobotCar数据集[30]是一个跨越多个城市街区的长期城市道路数据集,由20862张阴天参考图像和11934张在晴天、黄昏和夜晚等多种条件下拍车的查询图片构成。CMU数据集[5]在城市和郊区环境中记录了8.5公里的行程,包含7159张参考图像和75335张不同季节的查询图像。
SfM模型构建:(1)利用COLMAP构建SfM模型;(2)使用我们的特征点和描述子进行2D-2D匹配;(3)根据COLMAP构建的SfM模型的共视关系过滤匹配;(4)使用提供的真实位姿及匹配关系三角化获取稀疏新SfM模型。
评估方法:用NetVlad和SuperPoint提取特征来评估我们的分层定位,命名为NV+SP;用HF-Net提取全局和局部特征评估分层定位;同时还使用数据集作者使用的方法Active Search(AS)[43]和City Scale Localization(SCL)[51],这两个都是基于2D-3D直接匹配的方法;DenseVLAD[56]和NetVlad是图像检索方法,通过检索得到的最相似数据库图像的位姿来近似查询位姿;Semantic Match Consistency(SMC)依赖于语义分割来拒绝异常值;额外引入NV+SIFT,以RootSIFT作为局部特征执行分层定位。
定位结果:表3显示每种定位算法在Aachen、RobotCar和CMU数据集不同距离和方向阈值下的召回率(%),表中红色和蓝色分别表示最优和次优方法。X+Y表示利用X作为全局特征描述符,Y作为局部特征描述符。因为SMC利用RobotCar的语义信息,故不参与RobotCar数据集的比较。
表3 召回率评估

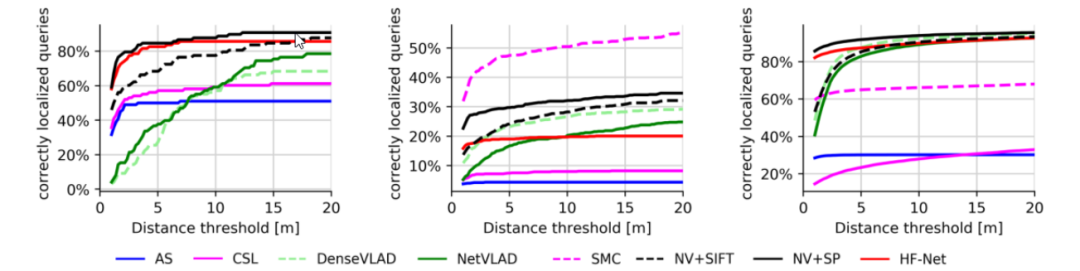
图4 正确率评估
图4显示在三个数据集Aachen(左侧)RobotCar(中间)CMU(右侧)不同距离阈值下定位正确率的变化。在Aachen数据集,HF-Net和NV+SP具有相似的性能,并优于基于全局检索和基于特征匹配的方法;在RobotCar数据集,HF-Net的性能比NV+SP差,说明了多任务蒸馏的局限性;在CMU数据集上,层级定位方法明显优于其他方法。
NV+SP:在Aachen数据集上,NV+SP在白天查询数据上表现优秀并优于所有夜间查询数据。随着阈值下降,其性能下降明显小于直接匹配方法;在RobotCar数据集上,它与其他方法在黄昏查询数据上性能类似,在更具挑战性的查询数据上,NV+SP的方法在各方面都明显优于其他方法;在CMU数据集上,与其他方法相比,NV+SP具有出色的鲁棒性。总体而言,NV+SP在三个数据集上均树立了新的技术水平,在高精度和粗精度两种情况下均具有出色的性能,这表明我们的分层定位方法是有效的、可靠的。
NV+SIFT:NV+SIFT始终优于AS和CSL,尽管这三种方法都是基于SIFT特征点。这表明我们分层定位方法的优越性,特别是在有挑战的查询数据上,图像检索有助于消除误匹配。在精度较高的情况下表现略优于NV+SP,但在粗精度的情况下,NV+SP显示出了基于深度学习获取的特征的优越性。
HF-Net:在大多数数据集上,HF-Net都仅次于NV+SP;在RobotCar夜间查询数据上,HF-Net明显比NV+SP差,这是由于提取的全局特征对模糊低质量图像的性能较差。这体现出了我们方法的局限性,全局检索的失败直接导致层次定位的失败。图5是利用HF-Net在Aachen数据集上成功定位的一个例子,左侧是查询图像,右侧是全局检索获取的图像。
图5 HF-Net在Aachen数据集上定位结果
5.3运行时间评估
表5中分别展示了特征提取、全局检索、聚类、局部特征匹配以及PnP这五个步骤所需要的时间,红色表示耗时最短的方法。HV+SP和HF-Net的计时显示,我们的由粗到细的分层定位方法可以很好的适应大场景。只受图像数量影响的全局检索速度很快,可以消除很多潜在的候选匹配集,实现一个规模较小的2D-3D匹配。当特征点越多,共视聚类和局部特征匹配耗时越多,因此NV+SIFT速度很慢。NV+SP显著改善了NV+SIFT,因为其稀疏的SfM模型拥有更少的特征点,然而NetVlad和SuperPoint的特征提取耗时较大,HF-Net对此进行了改进,将速度提高了7倍。
表5 运行时间评估表

6 结论
本文提出了一种鲁棒的、精确的、实时的视觉定位方法。方法遵循由粗到精的定位模式,首先执行全局图像检索以获得一组数据库图像,然后使用3D-SfM模型的共视性将这些图聚类到各个位置,在这些候选位置上进行局部特征的2D-3D匹配得到相机精确的6自由度位姿。
本文方法的一个版本是基于现有用于图像检索和特征匹配的神经网络。在几个大型基准数据集中,其性能优于最新的定位方法,其中包括昼夜查询以及跨天气条件和跨季节查询。然后提出一种新颖的CNN网络HF-Net,可以一次性计算全局和局部描述符,从而提高其效率。同时证明了多任务蒸馏方法在保持原始网络性能的同时灵活地进行训练的有效性。最终的定位系统在大规模环境下运行速度超过20 FPS,并在具有挑战的数据集上体现了无与伦比的鲁棒性。
参考文献







编辑推荐




最新资讯
-
imc/GRAS/AP首次联袂亮相ATE India 盛会
2025-04-11 13:49
-
GB/T 31486-2024 与 GB/T 31484-2015 修改
2025-04-11 13:48
-
标准介绍丨ASAM ARTI 运行实时接口
2025-04-11 10:29
-
自动驾驶中基于深度学习的雷达与视觉融合用
2025-04-11 10:25
-
标准研究丨《汽车开闭件性能要求和试验方法
2025-04-11 10:24
