




 广告
广告





















































PointINet: 一种新型点云插帧网络
2021-01-09 00:10:33· 来源:同济智能汽车研究所

编者按:激光雷达和摄像头是智能驾驶车辆的主要感知器,针对于不同的任务,研究人员已经提出了许多表现优异的解决方案。但相较于图像,点云的研究起步和进展显得
编者按:激光雷达和摄像头是智能驾驶车辆的主要感知器,针对于不同的任务,研究人员已经提出了许多表现优异的解决方案。但相较于图像,点云的研究起步和进展显得较为缓慢。许多图像中已经得到很好处理和应用的领域,在点云中仍然少有人涉足。这里我们为大家带来的一篇AAAI2021论文就很好地借鉴图像领域,提出了点云的一个全新方向:点云插帧。文本的出发点在于克服雷达的低帧率,作者通过使用场景流、自适应架构和注意力模块成功地将低帧率的激光雷达点云流(10~20 Hz)上采样为高帧率的点云流(50~100 Hz)。随后作者通过详细的实验证实了其有效性,并且给出了实际应用实验展示此方向良好的使用前景。
本文译自:
PointINet: Point Cloud frame Interpolation Network
文章来源:
AAAI 2021
作者:
Fan Lu,Guang Chen,Sanqing Qu,Zhijun Li,Yinlong Liu,Alois Knoll
原文链接:
https://arxiv.org/abs/2012.10066
项目网址:
https://ispc-group.github.io/pages/pointinet.html
*通讯联系:guangchen@tongji.edu.cn
摘要:受硬件性能的限制,激光雷达点云流在时间维度上通常是稀疏的。通常,机械激光雷达传感器的帧率为10到20 Hz,这远低于其他常用的传感器(如相机)。为了克服激光雷达传感器的时间限制,本文研究了一种名为点云插帧的新的任务。给定两个连续的点云帧,点云插帧的目的是在它们之间生成中间帧。为此,我们提出了一种新颖的框架,即点云插帧网络(PointINet)。基于所提出的方法,我们可以将低帧率点云流上采样到更高的帧率。我们首先估算两个点云之间的双向3D场景流,然后根据3D场景流将它们转换到给定的时间步长。为了融合两个变换的帧并生成中间点云,我们提出了一种新颖的基于学习的点融合模块,该模块同时考虑了两个变换的点云。我们设计了定量和定性实验来评估点云插帧方法的性能,并且在两个大型室外LiDAR数据集上进行的广泛实验证明了所提出的PointINet的有效性。我们的代码发布在了https://github.com/ispc-lab/PointINet.git上。
关键词:超像素,平面特征,RANSAC
1 引言
激光雷达是众多应用(例如、自主车辆和智能机器人)中最重要的传感器之一。然而,典型的机械式激光雷达传感器(例如、Velodyne HDL-64E、Hesai Pandar64等)的帧率受到硬件性能的极大限制。激光雷达的帧率一般为10~20 Hz,这会造成点云流的时空不连续。与激光雷达的低帧率相比,智能车辆和机器人上其他常用传感器的帧率通常要高很多。例如,摄像头和惯性测量单元(IMU)的帧率可以达到100Hz以上。帧率的巨大差异会给激光雷达与其他传感器的同步带来困难。将低帧率的激光雷达点云流上采样到更高的帧率,可以有效地解决这一问题。此外,更高的帧率可能会提升一些应用的性能,比如物体跟踪。值得注意的是,视频插帧通常被用来从低帧率的视频生成高帧率的视频(例如,从30Hz到240Hz)。与目前得到广泛注意的视频插帧相比,3D点云的插帧还没有得到很好的探索。因此,我们需要探索3D点云的插帧算法,以克服激光雷达传感器的时间限制。
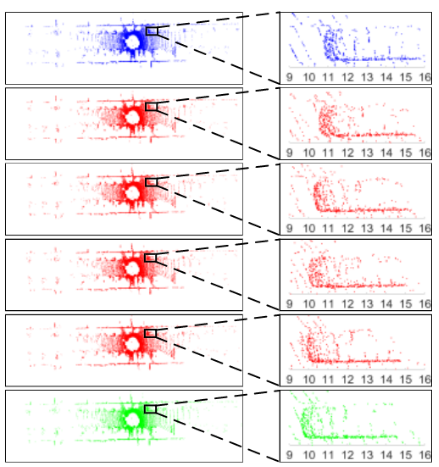
图1 点云插帧的示意图。 蓝色和绿色的点云是两个输入帧,红色的点云是四个插值帧。我们放大区域以显示详细信息,以实现更好的可视化。
基于以上考虑,本文研究了一个名为 "点云插帧 "的新型任务。给定两个连续的点云,点云插帧的目的是根据给定的时间步长预测中间点云帧,形成空间和时间上相干的点云流(见图1)。因此,基于点云插帧,可以将低帧率的激光雷达点云流(10~20 Hz)上采样为高帧率的点云流(50~100 Hz)。
具体来说,为了实现点云流的时空插值,我们提出了一种新型的基于学习的框架,称为PointINet(点云插帧网络)。我们提出的PointINet主要由两部分组成:点云变换模块和点融合模块。首先将两个连续的点云输入点云变换模块,将两个点云变换到给定的时间步长。为此,我们首先估计两个连续点云之间的双向三维场景流以进行运动估计。3D场景流代表了从一个点云到另一个点云的运动场。这里我们采用名为FlowNet3D的基于学习的场景流估计网络来预测3D场景流。然后根据线性插值的3D场景流,将两个点云变换到给定的时间步长。此后,关键问题是如何将两帧融合,形成新的中间点云。3D点云是非结构化且无序化的。因此,两个点云中的点之间并不像两幅图像中的像素那样存在直接的对应关系。因而,要对两个点云进行融合是非易事。为了解决这个问题,我们提出了一种新的点融合模块。该点融合模块自适应地对两个变换点云中的点进行采样,并根据时间步长为每个采样点构建k最近邻(kNN)聚类,以调整两个点云的贡献。之后,我们提出的注意点融合采用注意机制将每个聚类中的点聚集起来以生成中间点云。所提出的PointINet的整体架构如图2所示。
为了评估该方法,我们设计了定性和定量实验。 此外,还进行了应用实验,以评估生成的插值点云的质量。在两个大型室外激光雷达数据集上进行的大量实验证明了所提出的PointINet的有效性。
总而言之,我们的主要贡献如下:
· 为了克服激光雷达传感器的时间限制,研究了一种新颖的任务——点云插帧。
· 提出了一种名为PointINet的基于学习的新框架,以有效地生成两个连续点云之间的中间帧。
· 通过定性和定量实验,以验证所提出方法的有效性。
2 相关工作
在本节中,我们简要回顾与点云插帧有关的文献。 我们从描述视频插帧的常用方法开始,然后回顾点云的3D场景流估计方法。
视频插帧
当前,大量视频插帧方法基于光流估计。基于光流的方法最具代表性的工作之一是Super SloMo,它利用基于学习的方法来预测双向光流来估计连续帧之间的运动。然后,将两个输入帧进一步变换并与遮挡推理结合以生成最终的中间帧。Reda et al. 利用循环一致性来支持视频插帧的无监督学习。Xu et al.提出了一种二次视频插值方法来利用视频中的加速度信息。视频插帧方法的另一部分是基于内核的(Niklaus, Mai, and Liu 2017a,b)。(Niklaus, Mai, andLiu 2017a)估计每个位置的内核,并通过对补丁进行卷积来预测输出像素的位置。Niklaus, Mai, and Liu 2017b通过使用一对一维内核将插帧公式化为输入帧上的局部可分卷积来进一步改进了该方法。最近,(Bao et al. 2019)结合了基于核和光流的方法。他们利用光流来预测像素的大致位置,然后使用估计的核来完善位置。
3D场景流估计
点云的3D场景流可以看作是3D场景中2D光流的推广,它表示点的3D运动场。与研究者对2D光流估计的高度研究兴趣相比,关于3D场景流估计的工作相对较少。FlowNet3D是基于深度学习的3D场景流估计的开创性工作。(Liu,Qi, and Guibas 2019)提出了一个流嵌入层,以对不同点云中点的运动进行建模。在FlowNet3D之后,FlowNet3D ++提出了几何约束来进一步提高精度。HPLFlowNet在场景流估计中引入了双边卷积层(BCL)。PointPWC-Net提出了一种新颖的成本方法,并以从细到精的方式估算了3D场景的流量。最近,(Mittal, Okorn, and Held 2020)提供了几个不受监督的损失函数,以支持在更真实的数据集上推广预训练的场景流估计模型。在我们的实现中,由于简单性和有效性,我们选择FlowNet3D在两个点云之间执行3D场景流估计。
3 点云插帧
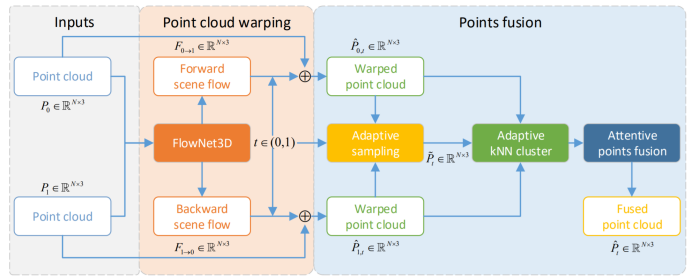
图2 PointINet的总体结构。给定输入两个连续的点云,PointINet遵循由点云变换模块和点融合模块组成的通道。
在本节中,我们首先介绍了所提出的点云插帧网络(PointINet)的整体架构,然后详细介绍了PointINet的两个关键部分,即点云变换模块和点融合模块。
架构总览
PointINet的整体架构如图2所示。给定两个连续的点云P0和P1,时间步长t∈ (0,1),PointINet的目标是预测时间步长t中的中间点云。PointINet由两个关键模块组成:点云变换模块将两个输入的点云变换到给定的时间步t,点融合模块将两个变换的点云进行融合。下面我们将详细介绍这两个模块。
点云变换
给定两个点云P0和P1,点云变换模块旨在预测P0中每个点在的位置,其中是P0的在时间步长t对应的点云(对于点云P1我们也预测)。这里的关键是估计每个点从P0到
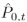 的运动。我们首先预测两个点云P0和P1之间的双向3D场景流
的运动。我们首先预测两个点云P0和P1之间的双向3D场景流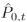 和
和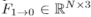 来估计点的运动。3D场景流是指点的3D运动场,它可以看作是3D点云中光流的推广。这里我们利用现有的基于学习的框架FlowNet3D来估计双向的3D场景流。假设连续两帧点云之间的点的运动是线性的,那么场景流
来估计点的运动。3D场景流是指点的3D运动场,它可以看作是3D点云中光流的推广。这里我们利用现有的基于学习的框架FlowNet3D来估计双向的3D场景流。假设连续两帧点云之间的点的运动是线性的,那么场景流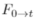 和
和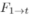 可以通过线性插值
可以通过线性插值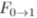 和
和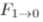 来逼近,可以表示为:
来逼近,可以表示为: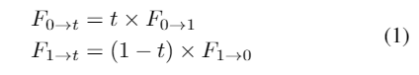
然后P0和P1可以根据插值3D场景流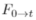 和
和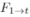 被变换为给定的时间步长,
被变换为给定的时间步长,
和被变换为给定的时间步长,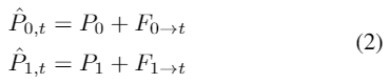
点云融合
点融合模块的目标是将两个变换的点云进行融合,生成中间点云。点融合模块的架构显示在图2的右栏中。该模块的输入是两个变换的点云
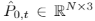 和
和 ,输出是融合后的中间点云
,输出是融合后的中间点云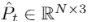 。在视频插帧中,由于图像可以表示为结构化的2D网格,融合步骤大多集中在遮挡和缺失区域预测上。然而,由于点云是非结构化和无序的,因此两个点云的融合是不易的。在所提出的PointINet中,我们首先基于时间步长t从两个变换的点云中自适应地采样,然后以采样点为中心构建k最近邻(kNN)聚类来进行融合。之后,注意点融合模块采用注意力机制,生成最终的中间点云。下面将详细介绍点融合模块的主要组成部分。
。在视频插帧中,由于图像可以表示为结构化的2D网格,融合步骤大多集中在遮挡和缺失区域预测上。然而,由于点云是非结构化和无序的,因此两个点云的融合是不易的。在所提出的PointINet中,我们首先基于时间步长t从两个变换的点云中自适应地采样,然后以采样点为中心构建k最近邻(kNN)聚类来进行融合。之后,注意点融合模块采用注意力机制,生成最终的中间点云。下面将详细介绍点融合模块的主要组成部分。自适应采样
点融合模块的第一步是将两个变换的点云合并成一个新的点云。直观上,两个点云对中间点云的贡献并不总是相同的。例如,在t=0.2时的中间帧 与第一帧P0应该比第二帧P1更相似。基于上述观察,我们从和中随机抽取N0和N1个点,分别生成两个采样点云
与第一帧P0应该比第二帧P1更相似。基于上述观察,我们从和中随机抽取N0和N1个点,分别生成两个采样点云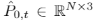 和
和 。其中N0=(1-t)×N和N1=t×N。这种操作使得网络能够根据目标时间步长t自适应地调整两个变换点云的贡献。接近时间步长t的点云对中间帧的贡献更大。之后,
。其中N0=(1-t)×N和N1=t×N。这种操作使得网络能够根据目标时间步长t自适应地调整两个变换点云的贡献。接近时间步长t的点云对中间帧的贡献更大。之后,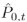 和
和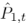 合并成一个新的点云
合并成一个新的点云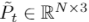 。
。
点融合模块的第一步是将两个变换的点云合并成一个新的点云。直观上,两个点云对中间点云的贡献并不总是相同的。例如,在t=0.2时的中间帧
与第一帧P0应该比第二帧P1更相似。基于上述观察,我们从和中随机抽取N0和N1个点,分别生成两个采样点云和。其中N0=(1-t)×N和N1=t×N。这种操作使得网络能够根据目标时间步长t自适应地调整两个变换点云的贡献。接近时间步长t的点云对中间帧的贡献更大。之后,和合并成一个新的点云。自适应kNN聚类
我们将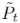 输入到自适应的kNN聚类模块中,生成k个最近邻聚类,作为后续注意点融合模块的输入。对于中的每一个点,我们在两个变换点云
输入到自适应的kNN聚类模块中,生成k个最近邻聚类,作为后续注意点融合模块的输入。对于中的每一个点,我们在两个变换点云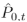 和
和 中搜索K个邻近点。与自适应采样类似,
中搜索K个邻近点。与自适应采样类似,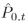 和
和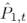 中的邻近点数也根据t进行自适应调整,以平衡两个点云的贡献。因此,我们在中查询K0个邻近点,在中查询K1个邻近点,其中K0= (1-t) ×K,K1=t×K。因此,我们得到N个聚类,每个聚类由K个邻近点组成。将聚类的中心点表示为xi,邻点表示为
中的邻近点数也根据t进行自适应调整,以平衡两个点云的贡献。因此,我们在中查询K0个邻近点,在中查询K1个邻近点,其中K0= (1-t) ×K,K1=t×K。因此,我们得到N个聚类,每个聚类由K个邻近点组成。将聚类的中心点表示为xi,邻点表示为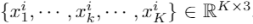 。然后将每个邻点以
。然后将每个邻点以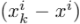 的形式减去中心点,得到邻点在聚类中的相对位置。此外,邻点与中心点之间的欧氏距离
的形式减去中心点,得到邻点在聚类中的相对位置。此外,邻点与中心点之间的欧氏距离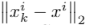 作为聚类的附加通道被计算出来。因此,单个聚类的最终特征可以表示为
作为聚类的附加通道被计算出来。因此,单个聚类的最终特征可以表示为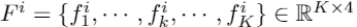 。
。
我们将
输入到自适应的kNN聚类模块中,生成k个最近邻聚类,作为后续注意点融合模块的输入。对于中的每一个点,我们在两个变换点云和中搜索K个邻近点。与自适应采样类似,和中的邻近点数也根据t进行自适应调整,以平衡两个点云的贡献。因此,我们在中查询K0个邻近点,在中查询K1个邻近点,其中K0= (1-t) ×K,K1=t×K。因此,我们得到N个聚类,每个聚类由K个邻近点组成。将聚类的中心点表示为xi,邻点表示为。然后将每个邻点以的形式减去中心点,得到邻点在聚类中的相对位置。此外,邻点与中心点之间的欧氏距离作为聚类的附加通道被计算出来。因此,单个聚类的最终特征可以表示为。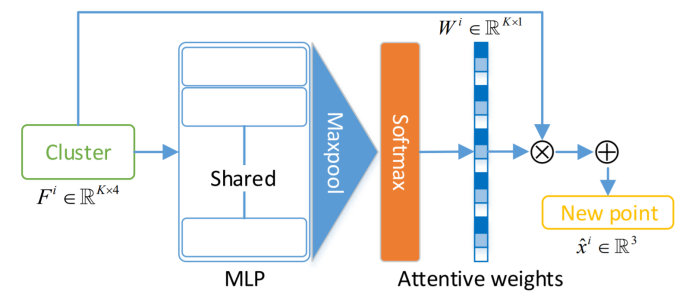
图3 注意点融合模块的网络架构
注意点融合 注意力机制在3D点云学习中已经得到了广泛的应用。在这里,我们采用注意机制来聚合相邻点的特征来生成中间点云的新的点。注意力点融合模块的网络架构可参见图3。受PointNet和PointNet++的启发,我们将单个聚类的特征Fi输入共享多层感知器(Shared-MLP)以生成特征图。然后应用后续的maxpool层和Softmax函数对聚类中的所有邻点预测一维注意权重Wi=
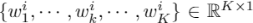
。之后,新点
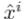 可以表示为邻点的加权和。
可以表示为邻点的加权和。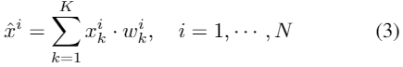
最后,生成的中间点云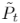 可以表示为
可以表示为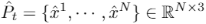 。直观地讲,所提出的注意点融合模块可以给点集中与目标点云更一致的点分配更高的权重。在点融合模块之后,新的中间点云中的每一个生成点都是由其接受场中的两个点云中的邻点聚合而成。此外,借助自适应采样和自适应kNN集群模块,可以根据时间步长t动态调整两个点云的贡献。因此,生成的中间点云是两个输入点云的有效融合。
。直观地讲,所提出的注意点融合模块可以给点集中与目标点云更一致的点分配更高的权重。在点融合模块之后,新的中间点云中的每一个生成点都是由其接受场中的两个点云中的邻点聚合而成。此外,借助自适应采样和自适应kNN集群模块,可以根据时间步长t动态调整两个点云的贡献。因此,生成的中间点云是两个输入点云的有效融合。
可以表示为。直观地讲,所提出的注意点融合模块可以给点集中与目标点云更一致的点分配更高的权重。在点融合模块之后,新的中间点云中的每一个生成点都是由其接受场中的两个点云中的邻点聚合而成。此外,借助自适应采样和自适应kNN集群模块,可以根据时间步长t动态调整两个点云的贡献。因此,生成的中间点云是两个输入点云的有效融合。损失
倒角距离通常用于测量两个点云的相似度。在这里,我们利用倒角距离来监督所提出的PointINet的训练。给定生成的中间点云
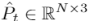 和真值点云
和真值点云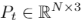 ,倒角距离损失可以表示为
,倒角距离损失可以表示为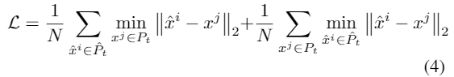
其中||·||代表L2归一化。
4 实验
我们进行定性和定量实验,以证明所提出的方法的性能。 此外,我们还在两个应用上(例如,关键点检测和多帧迭代最近点(ICP))进行了实验,以更好地评估生成的中间点云的质量。
数据集
我们在两个大型室外LiDAR数据集(即KITTI里程表数据集和nuScenes数据集)上评估了该方法。KITTI里程表数据集提供了11个具有地面真实性的序列(00-10),我们使用序列00训练网络,使用01进行验证,而使用其他序列进行评估。NuScenes数据集包含850个训练场景,我们使用前100个场景进行训练,其余750个场景进行评估。由于缺乏高帧速LiDAR传感器,我们简单的将KITTI里程表数据集中的10 Hz点云下采样为2 Hz,将nuScenes数据集中的20 Hz点云下采样为4 Hz,用于训练和定量实验。因此,在降采样点云流的两个连续帧之间有4个中间点云。
实施细节
我们首先在Flythings3D数据集上训练FlowNet3D,然后在KITTI场景流数据集上优化网络。我们直接使用(Liu, Qi, and Guibas 2019)预处理的数据来训练FlowNet3D。然后,我们分别在KITTI里程表数据集和nuScenes数据集上分别完善预训练的FlowNet3D。在此过程中,将当前帧与前后Ns帧内随机选择的帧作为训练对。然后,以预测的场景流将第一帧变换到第二帧,并使用变换点云和第二点云之间的倒角距离(请参见公式4)损失函数进行监督FlowNet3D的完善。之后,在训练随后的点融合模块时,FlowNet3D的权重是固定的。在训练点融合模块的过程中,将两个连续的帧和来自4个中间点云的随机采样帧以及相应的时间步长用作训练样本。我们在训练期间将点云随机降采样为16384点,并且在我们的实现中将相邻点的数量K设置为32。注意点融合模块中Shared-MLP的层的通道设置为[64,64,128]。所有网络均使用PyTorch实现,而Adam被用作优化器。此外,点融合模块仅在KITTI里程表数据集上进行训练,我们仅将训练后的模型推广到nuScenes数据集进行评估。

图4 PointINet的定性结果。从上至下是三对连续帧的插值结果。列从左到右的时间步长t分别为0.25、0.50和0.75。蓝色,绿色和红色点云分别代表第一帧,第二帧和预测的中间帧。此外,我们放大点云的某个区域,然后将其旋转到适当的角度,以更好地可视化插值点云的细节。
定性实验
提出的PointINet的目标是从低帧率的流生成高帧率的激光雷达流。但是,没有现有的高帧率LiDAR传感器。因此,我们用Ns= 1训练FlowNet3D,以便为更近的点云提供适当的场景流估计,然后将在降采样点云流上训练的点融合模块直接应用于KITTI里程表数据集的10 Hz点云流上以生成高帧速率点云流。在这里,我们在图4中提供定性可视化,其中此处的点数设置为32768。10Hz点云流被上采样到40 Hz,中间帧的时间步长设置为0.25、0.50和0.75。根据图4,提出的PointINet很好地估计了两个云之间的点的运动,并且融合算法可以保留点云的细节。除此之外,我们还在补充材料中提供了一些演示视频,以比较高帧率点云流和低帧率点云流。根据演示视频,高帧率点云流在时间和空间上明显比低帧率点云平滑。
定量实验
评价指标 我们使用两个评估指标:倒角距离(CD)和推土机距离(EMD)来评估降采样点云流上生成的点云与地面真实云之间的相似性和一致性。CD先前在等式4中进行了描述。EMD也是比较两个点云(Weng et al. 2020)的常用度量,其是通过解决线性分配问题来实现的。给定两点云
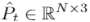 和,EMD可以被描述为:
和,EMD可以被描述为: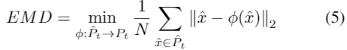
其中,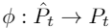 是一个双映射。
是一个双映射。
是一个双映射。基线
为了演示建议的PointINet的性能,我们定义了3个基线与我们的方法进行比较:(1)一致性方法 我们仅将第一点云框架复制为中间点云。(2)对齐ICP方法 我们首先使用迭代最近点(ICP)算法估计点云的两个连续帧之间的刚性变换,然后对其进行线性插值以获得第一帧和中间帧之间的变换。之后,基于该变换将第一点云变换为中间帧。(3)场景流方法 我们使用FlowNet3D估计连续两个帧之间的3D场景流,并通过线性插值计算从第一帧到中间帧的场景流,然后根据3D场景流对第一点云进行变换得到中间点云。在定量实验中,通过随机采样将所有点云降采样为16384点。
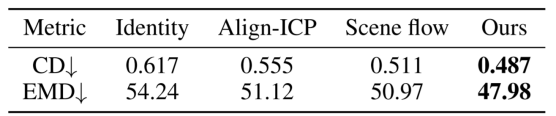
表1 在KITTI里程表数据集上对PointINet和其他基线进行定量评估的结果
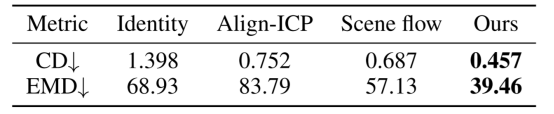
表2 在nuScenes数据集上对PointINet和其他基线进行定量评估的结果
结果
提议的PointINet的CD和EMD以及KITTI里程表数据集和nuScenes数据集上的其他基线分别显示在表1和表2中。根据结果,我们的方法的性能明显优于其他基准。例如,建议的PointINet的倒角距离约为KITTI里程表上一致性方法,对齐ICP方法和场景流方法的 1/3 ,3/5 和2/3。值得注意的是,我们的方法明显优于场景流方法,这也反映了点融合模块的有效性。注意,我们仅在KITTI里程表数据集上训练点融合模块,而在nuScenes数据集上的结果也证明了网络的泛化能力。
应用
为了更好地评估生成的中间点云的质量以及与原始点云的相似性,我们在插值点云流和原始点云流上测试了两个应用的性能,即关键点检测和多帧ICP。我们首先分别将KITTI里程表数据集中的10 Hz点云和nuScenes数据集中的20 Hz点云分别下采样到5 Hz和10 Hz,然后将它们作为内插点云流内插到原始的帧率。比较了两个不同点云流上两个应用程序的结果,以验证所提出的PointINet的有效性。
表3 KITTI里程表数据集上原始和插值点云的3个不同关键点的可重复性

关键点检测
我们在两个点云流中执行3D关键点检测,并评估检测到的关键点的可重复性。我们选择了3个手工制作的3D关键点,即SIFT-3D,Harris-3D和ISS。使用PCL中的实现提取所有关键点。如果点云中的一个关键点到另一个点云中最近的关键点的距离(在基于地面真相姿势进行刚性变换之后)在阈值δr(δr设置为0.5 m)之内,则该点被视为可重复。在此,可重复性是可重复关键点的比率。我们计算当前点云中关键点在前后5帧中的平均可重复性,并将关键点的数量设置为256。由于nuScenes数据集中缺少每帧地面真相姿势,因此关键点检测实验为仅在KITTI里程表数据集上执行,其结果显示在表3中。根据结果,与原始点云流相比,插值点云流的可重复性仅稍有降低。例如,插值点云的Harris-3D的可重复性仅比原始点云的可重复性低0.017。结果从侧面反映了生成的中间点云与地面真点云的高度一致性。
表4 KITTI里程表数据集上原始点和内插点云流的多帧ICP性能。
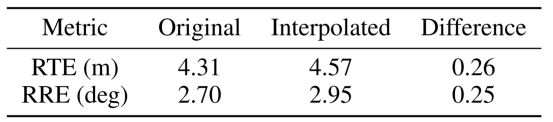
表5 nuScenes数据集上原始和内插点云流的多帧ICP性能。
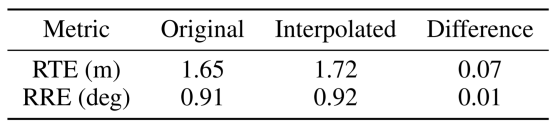
多帧ICP 我们对Nm个连续帧执行迭代最近点(ICP)算法,以估计第一帧与最后一帧之间的刚性变换。在KITTI里程表数据集上将Nm设置为10。对于nuScenes数据集,仅为关键帧(大约2 Hz)提供真实姿态。因此,将Nm设置为与nuScenes数据集上两个关键帧之间的帧数相同。我们利用PCL中的实现来执行ICP算法。累加一次转换以获得第一帧和最后一帧之间的转换。计算相对平移误差(RTE)和相对旋转误差(RRE),以评估多帧ICP估计变换的误差。有关KITTI里程表数据集和nuScenes数据集的结果分别显示在表4和表5中。我们还计算原始点和插值点云流的误差之间的差异,并将结果显示在表4和表5的右栏中,以便进行更好的比较。根据结果,插值点云流上的多帧ICP算法的RTE和RRE非常接近原始点云流。例如,根据表5,两个结果在nuScenes数据集上的RTE仅相差0.07 m。紧密的性能表明生成的中间点云与地面真实云之间的相似性。
根据这两个应用的实验,由于所提出的插值方法可能存在误差,因此在插值点云上算法的性能略逊于原始点云流。尽管如此,这两个应用程序的紧密性能证明了生成的点云与原始应用程序具有高度的相似性和一致性。
表6 PointINet及其组件针对不同数量的点的运行时间(ms)。
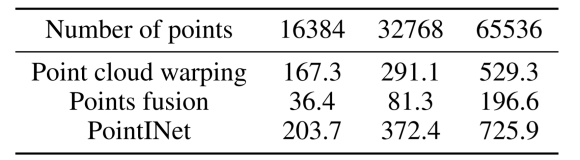
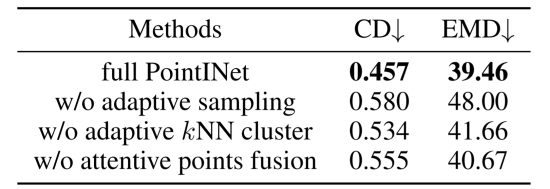
表7 在KITTI里程表数据集上对消融研究的定量评估结果。
效率
在配备NVIDIA Geforce RTX 2060的PC上评估了拟议的PointINet的效率,并在表6中显示了为包含16384、32768和65536点的点云生成一个中间帧的平均运行时间。根据结果,大多数运行时都用于变换点云,并且所提出的点融合模块需要相对较少的时间进行计算。然而,由于用于融合的每点计算,用于点融合模块的计算时间随着点的数量而增加。总体而言,建议的PointINet可以有效地生成中间帧。
消融实验
我们进行了多次消融研究,以分析拟议PointINet的不同组成部分(例如,自适应采样,自适应kNN聚类和注意点融合)对最终结果的影响。实验设置与定量实验一致,我们还使用倒角距离(CD)和推土机距离(EMD)来评估性能。所有消融研究均在KITTI里程表数据集上进行。
自适应采样
我们通过简单地随机采样两个变换点云中一半的点以形成一个新点云作为自适应kNN集群模块的输入来代替自适应采样策略。结果显示在表7的第二行中。根据结果,在不进行自适应采样的情况下,CD和EMD分别增加了0.123和8.54,这表明自适应采样策略显着提高了性能。
自适应kNN聚类
我们从两个变换的点云中固定地查询 K / 2 个邻居点,而不是根据时间步长 t 来查询点。根据表7第三行中显示的结果,没有自适应kNN聚类的CD和EMD分别从0.457增加到0.534,从39.46增加到41.66。结果证明了自适应kNN集群模块的有效性。
注意点融合
为了演示注意点融合模块的效果,我们直接使用自适应采样中的点云作为中间点云,并将结果显示在表格7的底行中。根据结果,注意点融合模块明显提高了最终性能。
5 结论
本文研究了一种名为点云插帧的新颖任务,并为此任务设计了基于学习的框架PointINet。给定两个连续的点云,该任务旨在预测它们之间在时间和空间上一致的中间帧。因此,使用所提出的方法可以将低帧率点云流上采样到高帧率。为此,我们利用现有的场景流估计网络进行运动估计,然后将两个点云变换到给定的时间步长。然后提出了一种新颖的基于学习的点融合模块,以有效地融合两个点云。我们为此任务设计了定性和定量实验。在KITTI里程表数据集和nuScenes数据集上进行的大量实验证明了所提出的PointINet的性能和有效性。
6 道德声明
提出的点云插帧方法可能对无人驾驶和智能机器人的发展产生积极影响,可以减轻驾驶员和工人的工作量,并减少交通事故的发生。 但是,这种发展也可能导致驾驶员和工人失业。此外,所提出的方法可能具有潜在的军事应用,例如军用无人机,可能会威胁到人类的安全。我们应该探索更多可以改善人类生活而不是有害生活的应用。
7 致谢
这项工作由中国国家自然科学基金( No. 61906138),欧盟根据特定拨款协议第945539号达成的Horizon 2020研究与创新框架计划(人脑计划SGA3)和 2 018上海AI创新发展计划资助。
参考文献:






编辑推荐




最新资讯
-
大卓智能端到端直播实测,16公里复杂路段挑
2025-04-25 17:16
-
《汽车轮胎耐撞击性能试验方法-车辆法》等
2025-04-25 11:45
-
“真实”而精确的能量流测试:电动汽车能效
2025-04-25 11:44
-
GRAS助力中国高校科研升级
2025-04-25 10:25
-
梅赛德斯-AMG使用VI-CarRealTime开发其控制
2025-04-25 10:21
