




 广告
广告





















































驾驶员特性辨识与驱动力矩增益匹配方法研究
2021-03-03 14:26:33· 来源:天津汽车研究所

摘要汽车电动化、智能化是未来发展方向,为实现符合驾驶员动力学响应特性的整车控制提供了可能。文章针对四轮独立驱动电动汽车,进行驾驶员加速特性辨识和驱动力
作者:姬 晓 李 刚
公众号编辑:冷棘宇
来源:《汽车工程师》摘要
汽车电动化、智能化是未来发展方向,为实现符合驾驶员动力学响应特性的整车控制提供了可能。文章针对四轮独立驱动电动汽车,进行驾驶员加速特性辨识和驱动力矩增益匹配方法研究。在驾驶模拟器上设置道路工况,采集了驾驶员的操纵数据和车辆行驶状态数据,应用K-means聚类算法将驾驶员的加速行为进行分类。基于人工神经网络算法训练分类数据得到高速超车和低速加速辨识模型,并给出了匹配不同类型驾驶员驱动力矩增益的方法。本研究方法能够对驾驶员加速特性进行有效辨识以及合理匹配力矩增益。
驾驶员特性是指驾驶员在操纵汽车时反映出的驾驶风格,是受到驾驶员大脑控制四肢的速度和心理状态变化的影响表现出的一种行为趋势,主要由驾驶员操纵汽车的行为和汽车对其行为的反馈两部分共同决定。国内外各研究机构都进行了一定的研究,文献对驾驶员的个性化驾驶行为模式进行了研究,提出使用小脑模型关联控制器建立驾驶员行为模型,有效辨别了驾驶员的行为特征。文献依靠从电子稳定性程序(ESC)中获取的车辆状态参数信息,开发了一款评估系统,对操纵危险系数做出定义并将驾驶员进行分类。文献对车辆集成控制算法进行人性化设计,采用神经网络方法建立了驾驶员转向特性辨识系统。文章主要针对四轮独立驱动电动汽车,研究不同工况下的驾驶员加速特性辨识及驱动力矩增益匹配方法,以满足不同特性驾驶员的驾驶要求。
1 驾驶员行驶数据采集
1.1 试验平台简介
驾驶模拟器为驾驶员提供一个动态可靠的驾驶环境,dSPACE实时仿真系统通过传感器采集到的驾驶操纵信息,再与车辆动力学模型结合,最后计算得到的车辆行驶状态信息通过投影显示和音响设备输出的方式传送给驾驶员。驾驶员可以根据信息修正自己的驾驶操作,如释放加速踏板,由此形成一个完整的闭环回路。驾驶模拟器试验平台,如图1所示。

1.2 试验工况设计
文章以四轮独立驱动电动汽车为研究对象,研究工况选择40~90km/h的加速工况和90~120km/h的超车工况。
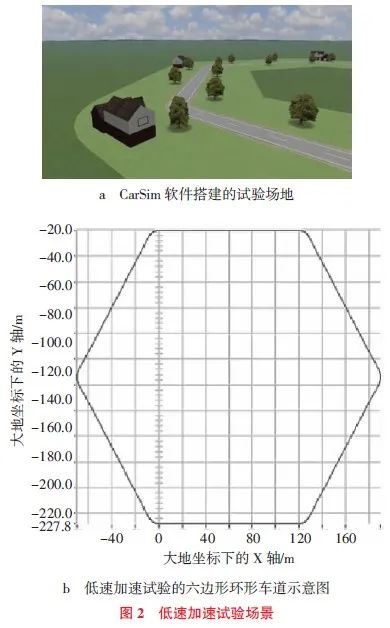
应用驾驶模拟器中CarSim(汽车动力学仿真软件)搭建试验场景。低速加速试验场景为六边形环形车道,边线车道长度为120m,如图2所示。过弯后开始记录驾驶员的操纵信息。采集的驾驶员操纵数据包括:纵向车速、纵向加速度、踏板开度、踏板开度变化率以及总驱动力矩。被测对象为若干具有驾驶经验的人员,采集多组数据,并取完整度较好的一组。
同样在CarSim软件中搭建高速超车试验场景,该场景为1200m长的直线双车道,如图3所示。车辆前方每隔100m放置一辆目标车,目标车车速为固定值100km/h。试验操控人员开启数据采集开关,采集被测人员加速超过每辆目标车时的操纵数据,包括:纵向车速、纵向加速度、踏板开度、踏板开度变化率以及转向盘转角。被测对象为若干具有驾驶经验的人员,采集多组数据并取完整度较好的一组。

2 试验数据处理
2.1 试验数据预处理
由于驾驶模拟器的限制,采集到的试验数据采样间隔为0.001s,每一组数据长度大约为60s,因此处理数据的工作量非常巨大。冗余的试验数据不但耗费时间,而且会带来MATLAB(矩阵试验室)软件处理困难等问题,所以对数据进行预处理,将采样时间重新调整到0.1s。
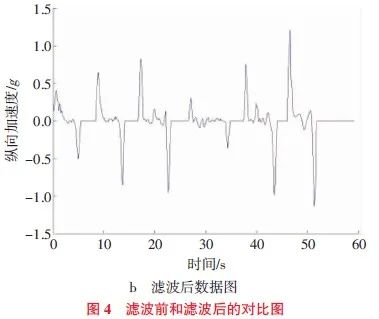
另一方面,驾驶模拟器采集的信号属于模拟量电信号,受车内电磁波及其他机械设备等不同程度的干扰,所采数据会夹杂着一些白噪声。中值滤波可以最大限度地剔除设备干扰,有效减小白噪声带来的影响,相较于传统的滤波算法,对数据准确性的影响更小,因此文章采用中值滤波进行数据处理,滤波前后对比,如图4所示。
2.2 提取特征值
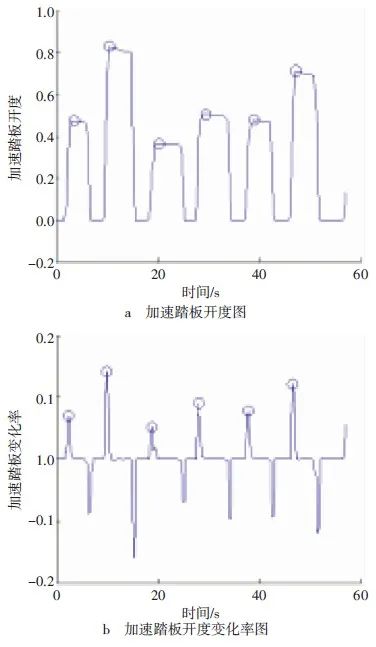
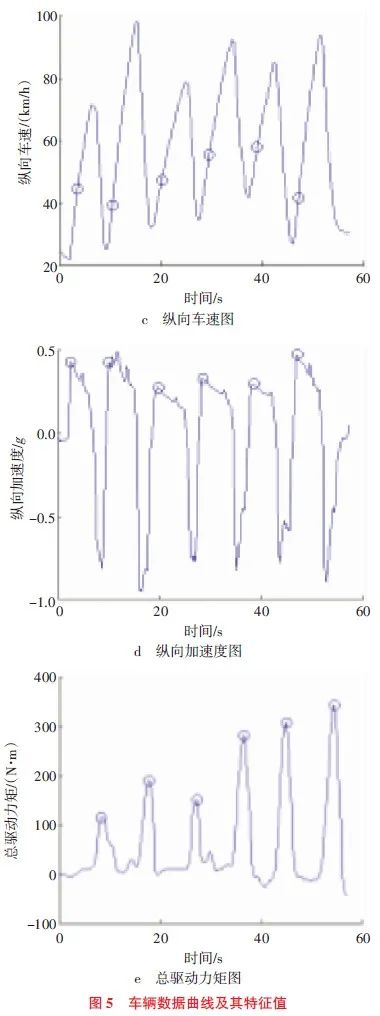
在对驾驶员加速特性分类前首先要提取有效的特征值,该数据和原始数据具有同样的意义,所以可用前者替代后者。据研究,车辆的加速性能与加速踏板开度及其变化率的大小有某种关联,而驾驶员加速特性在很大程度上被数据的极大值所影响。应用MATLAB从滤波后的数据中提取出加速踏板开度极大值所对应的时间点附近的速度、加速度、驱动力矩以及转向盘转角最大值。低速加速试验工况的数据曲线及其特征值,如图5所示。
3 驾驶员加速特性分类
所谓聚类就是根据对象间的相近因素和分类标准将数据分为几类。聚类后的数据中同类对象间相似性较大,不同类中的数据差异性较大。其中应用最广泛的是K-means聚类算法。K-means算法是基于区域分化的聚类算法,其特点是根据距离划分k类有相同特点的簇,具有简单、快捷的优点,是聚类分析中一种被广泛应用的启发式划分方法。
应用K-means聚类算法对特征值进行分类。文章把驾驶员加速特性分为谨慎型、一般型、激进型3类,故设定聚类数目k为3,并根据特征值的种类数确定聚类维度为5,最终编写聚类程序如下:
[Idx,C,sumD,D]=kmeans(Data,3,'dist','sqEuclidean','rep',4)
等号左边,Idx代表聚类标号,C代表聚类后的k个质心位置,sumD代表类别中的数据点与该类质心点的距离和,D代表每个点与质心的距离;等号右边,kmeans表示使用K-均值聚类,Data、3表示将数据聚为3类,dist、sqEuclidean表示计算距离为欧式距离,rep、4表示聚类重复次数为4。高速超车工况的特征点聚类中心,如表1所示。

对于激进型驾驶员,操纵车辆时多存在以下行为趋势:目标车速相同时,加速踏板开度较大或纵向加速度较高;目标踏板开度相同时,加速踏板开度变化率较大或车速明显较快。因此,结合客观评价,可将A类驾驶员归为谨慎型,将B类驾驶员归为一般型,将C类驾驶员归为激进型。最终驾驶员加速特性的分类结果为:谨慎型驾驶员为19人,一般型驾驶员为17人,激进型驾驶员为14人。和专业主观评价师的评价作对比发现,该分类结果也具有较好的主客观一致性。
4 驾驶员加速特性辨识方法研究
4.1 辨识模型建立
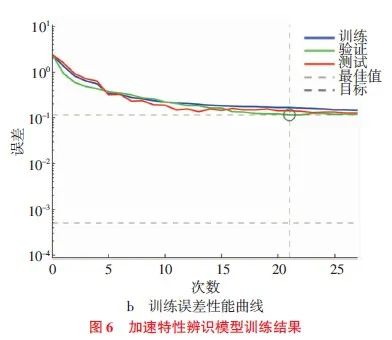
根据低速加速工况和高速超车工况2种试验工况的不同要求,分别训练2种辨识模型。人工神经网络模式是21世纪最受关注的模式识别方法。神经网络的参数设置如下:最高迭代次数为1000、训练预期精度为0.001,隐含层传递函数为S型函数tan-sigmoid,输出层传递函数为purlin函数,应用MATLAB软件中的工具箱完成对神经网络模型的训练,结果如图6所示。
4.2 离线验证
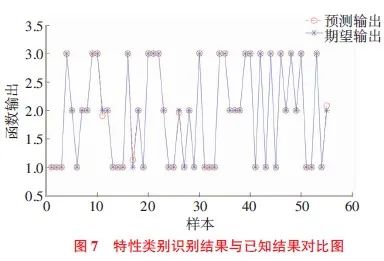
用50组测试集验证建立好的辨识模型。输入五维特征值数据,输出表示驾驶员加速特性的一维数值,范围在0.5~3.5之间。输出在0.5~1.5之间的数值时,判定输出结果为1,即辨识结果为谨慎型驾驶员;1.5~2.5之间的数值判定输出结果为2,视为一般型驾驶员;2.5~3.5之间的数值判定为3,视为激进型驾驶员。将模型输出和测试集原有的分类结果进行对比,如图7所示。可以看出,预测输出和已知特性类别基本吻合,表明辨识模型在离线仿真阶段表现较好。
4.3 在线验证
根据车辆当前速度将在线辨识模型分为2类:高速超车和低速加速。速度大于门限值时选用前者;小于门限值则选取后者。采集驾驶员的操作数据积累达一定值后,驾驶员加速特性辨识系统开始工作并输出辨识结果。
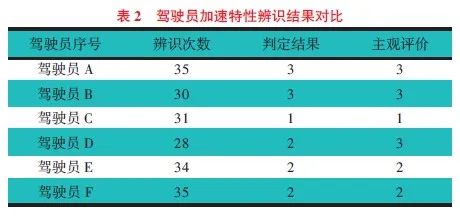
从分类完成的3种类型的驾驶员中,随机挑选6名驾驶员进行在线辨识,比对结果,如表2所示。可以看出,驾驶员加速特性辨识模型显示结果与已知分类结果基本一致。

由表3可以看出,激进型驾驶员倾向使用偏大的加速特性增益因子,对这类驾驶员而言,他们期望的车辆反应比真实车辆反馈的偏大;一般型驾驶员喜欢当前的加速特性增益因子,对这类驾驶员,他们的期望大多已经与车辆反馈相一致;谨慎型驾驶员则偏爱较小的加速特性增益,这类驾驶员驾驶风格较为保守,这也符合我们生活中的实际情况。对于激进型驾驶员,其踏板开度总是接近全开状态,说明当前驱动力矩太小而不能满足其激进特性,选择较大的增益因子可以降低踏板工作负荷;对于谨慎型驾驶员,其踏板开度常处于较小状态,说明当前的驱动力矩较大,选择适当小的增益因子可以降低驾驶员的精神压力;对于一般型驾驶员,其踏板开度使用频率及其位置都是正常的,说明当前驱动力矩已经满足其驾驶需求,故驱动力矩可保持当前状态不变而增益因子为1。
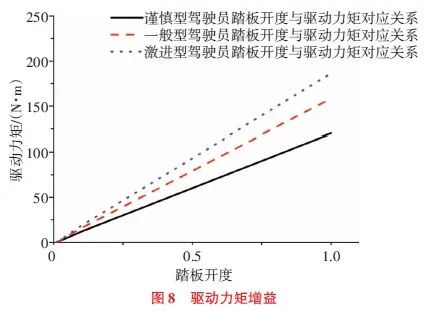
在车辆行进过程中,为不同加速特性的驾驶员配备了不同的驱动力矩增益,踏板开度与驱动力矩的对应关系,如图8所示。相同加速踏板开度下,谨慎型驾驶员的驱动力矩值最小;激进型驾驶员的驱动力矩值最大;而一般型驾驶员的驱动力矩值介于上述二者之间。
5 驱动力矩增益匹配
驾驶员操纵车辆加速过程中,驾驶员踩踏板的频率、踩踏板的深浅程度及其他驾驶操作可以反映驾驶员的加速行为特性。合理反推,可以得出:不同加速特性的驾驶员,达到目标车速状态过程中所需的加速踏板到电机的驱动力矩之间的联系也不尽相同。由此引入一个驱动力矩增益,将该增益定义为加速特性增益因子,用车辆模型下的驱动力矩乘以该因子,即可得到不同增益下的等效驱动力矩。
上文将驾驶员加速特性分成了3类,在此基础上,从每一类驾驶员中各选出5个代表在驾驶模拟器上进行试验。通过对驾驶模拟器车辆模型中的驱动力矩增益不断进行调整,直到车辆运动状态满足驾驶员的需求喜好为止再停止调试,由此得到不同类驾驶员的加速特性增益因子。表3示出不同加速特性驾驶员对应的最匹配的驱动力矩增益因子以及最终得到的平均值。
6 结论
通过设计不同的城市道路工况,分别研究了高速超车工况和低速加速工况下的驾驶员加速特性分类,利用K-means聚类算法将驾驶员分为谨慎型、一般型和激进型。应用分类结果,分别训练了高速超车工况和低速加速工况的神经网络辨识模型并进行了试验台验证。通过试验不断地调整驱动力矩增益,直到车辆运动状态符合驾驶员的喜好加速特性,实现了不同类型驾驶员与驱动力矩增益的匹配。试验结果表明,研究方法能够对驾驶员加速特性进行合理分类,准确辨别驾驶员的加速特性并匹配合适的加速增益因子。
公众号编辑:冷棘宇
来源:《汽车工程师》摘要
汽车电动化、智能化是未来发展方向,为实现符合驾驶员动力学响应特性的整车控制提供了可能。文章针对四轮独立驱动电动汽车,进行驾驶员加速特性辨识和驱动力矩增益匹配方法研究。在驾驶模拟器上设置道路工况,采集了驾驶员的操纵数据和车辆行驶状态数据,应用K-means聚类算法将驾驶员的加速行为进行分类。基于人工神经网络算法训练分类数据得到高速超车和低速加速辨识模型,并给出了匹配不同类型驾驶员驱动力矩增益的方法。本研究方法能够对驾驶员加速特性进行有效辨识以及合理匹配力矩增益。
驾驶员特性是指驾驶员在操纵汽车时反映出的驾驶风格,是受到驾驶员大脑控制四肢的速度和心理状态变化的影响表现出的一种行为趋势,主要由驾驶员操纵汽车的行为和汽车对其行为的反馈两部分共同决定。国内外各研究机构都进行了一定的研究,文献对驾驶员的个性化驾驶行为模式进行了研究,提出使用小脑模型关联控制器建立驾驶员行为模型,有效辨别了驾驶员的行为特征。文献依靠从电子稳定性程序(ESC)中获取的车辆状态参数信息,开发了一款评估系统,对操纵危险系数做出定义并将驾驶员进行分类。文献对车辆集成控制算法进行人性化设计,采用神经网络方法建立了驾驶员转向特性辨识系统。文章主要针对四轮独立驱动电动汽车,研究不同工况下的驾驶员加速特性辨识及驱动力矩增益匹配方法,以满足不同特性驾驶员的驾驶要求。
1 驾驶员行驶数据采集
1.1 试验平台简介
驾驶模拟器为驾驶员提供一个动态可靠的驾驶环境,dSPACE实时仿真系统通过传感器采集到的驾驶操纵信息,再与车辆动力学模型结合,最后计算得到的车辆行驶状态信息通过投影显示和音响设备输出的方式传送给驾驶员。驾驶员可以根据信息修正自己的驾驶操作,如释放加速踏板,由此形成一个完整的闭环回路。驾驶模拟器试验平台,如图1所示。
1.2 试验工况设计
文章以四轮独立驱动电动汽车为研究对象,研究工况选择40~90km/h的加速工况和90~120km/h的超车工况。
应用驾驶模拟器中CarSim(汽车动力学仿真软件)搭建试验场景。低速加速试验场景为六边形环形车道,边线车道长度为120m,如图2所示。过弯后开始记录驾驶员的操纵信息。采集的驾驶员操纵数据包括:纵向车速、纵向加速度、踏板开度、踏板开度变化率以及总驱动力矩。被测对象为若干具有驾驶经验的人员,采集多组数据,并取完整度较好的一组。
同样在CarSim软件中搭建高速超车试验场景,该场景为1200m长的直线双车道,如图3所示。车辆前方每隔100m放置一辆目标车,目标车车速为固定值100km/h。试验操控人员开启数据采集开关,采集被测人员加速超过每辆目标车时的操纵数据,包括:纵向车速、纵向加速度、踏板开度、踏板开度变化率以及转向盘转角。被测对象为若干具有驾驶经验的人员,采集多组数据并取完整度较好的一组。
2 试验数据处理
2.1 试验数据预处理
由于驾驶模拟器的限制,采集到的试验数据采样间隔为0.001s,每一组数据长度大约为60s,因此处理数据的工作量非常巨大。冗余的试验数据不但耗费时间,而且会带来MATLAB(矩阵试验室)软件处理困难等问题,所以对数据进行预处理,将采样时间重新调整到0.1s。
另一方面,驾驶模拟器采集的信号属于模拟量电信号,受车内电磁波及其他机械设备等不同程度的干扰,所采数据会夹杂着一些白噪声。中值滤波可以最大限度地剔除设备干扰,有效减小白噪声带来的影响,相较于传统的滤波算法,对数据准确性的影响更小,因此文章采用中值滤波进行数据处理,滤波前后对比,如图4所示。
2.2 提取特征值
在对驾驶员加速特性分类前首先要提取有效的特征值,该数据和原始数据具有同样的意义,所以可用前者替代后者。据研究,车辆的加速性能与加速踏板开度及其变化率的大小有某种关联,而驾驶员加速特性在很大程度上被数据的极大值所影响。应用MATLAB从滤波后的数据中提取出加速踏板开度极大值所对应的时间点附近的速度、加速度、驱动力矩以及转向盘转角最大值。低速加速试验工况的数据曲线及其特征值,如图5所示。
3 驾驶员加速特性分类
所谓聚类就是根据对象间的相近因素和分类标准将数据分为几类。聚类后的数据中同类对象间相似性较大,不同类中的数据差异性较大。其中应用最广泛的是K-means聚类算法。K-means算法是基于区域分化的聚类算法,其特点是根据距离划分k类有相同特点的簇,具有简单、快捷的优点,是聚类分析中一种被广泛应用的启发式划分方法。
应用K-means聚类算法对特征值进行分类。文章把驾驶员加速特性分为谨慎型、一般型、激进型3类,故设定聚类数目k为3,并根据特征值的种类数确定聚类维度为5,最终编写聚类程序如下:
[Idx,C,sumD,D]=kmeans(Data,3,'dist','sqEuclidean','rep',4)
等号左边,Idx代表聚类标号,C代表聚类后的k个质心位置,sumD代表类别中的数据点与该类质心点的距离和,D代表每个点与质心的距离;等号右边,kmeans表示使用K-均值聚类,Data、3表示将数据聚为3类,dist、sqEuclidean表示计算距离为欧式距离,rep、4表示聚类重复次数为4。高速超车工况的特征点聚类中心,如表1所示。
对于激进型驾驶员,操纵车辆时多存在以下行为趋势:目标车速相同时,加速踏板开度较大或纵向加速度较高;目标踏板开度相同时,加速踏板开度变化率较大或车速明显较快。因此,结合客观评价,可将A类驾驶员归为谨慎型,将B类驾驶员归为一般型,将C类驾驶员归为激进型。最终驾驶员加速特性的分类结果为:谨慎型驾驶员为19人,一般型驾驶员为17人,激进型驾驶员为14人。和专业主观评价师的评价作对比发现,该分类结果也具有较好的主客观一致性。
4 驾驶员加速特性辨识方法研究
4.1 辨识模型建立
根据低速加速工况和高速超车工况2种试验工况的不同要求,分别训练2种辨识模型。人工神经网络模式是21世纪最受关注的模式识别方法。神经网络的参数设置如下:最高迭代次数为1000、训练预期精度为0.001,隐含层传递函数为S型函数tan-sigmoid,输出层传递函数为purlin函数,应用MATLAB软件中的工具箱完成对神经网络模型的训练,结果如图6所示。
4.2 离线验证
用50组测试集验证建立好的辨识模型。输入五维特征值数据,输出表示驾驶员加速特性的一维数值,范围在0.5~3.5之间。输出在0.5~1.5之间的数值时,判定输出结果为1,即辨识结果为谨慎型驾驶员;1.5~2.5之间的数值判定输出结果为2,视为一般型驾驶员;2.5~3.5之间的数值判定为3,视为激进型驾驶员。将模型输出和测试集原有的分类结果进行对比,如图7所示。可以看出,预测输出和已知特性类别基本吻合,表明辨识模型在离线仿真阶段表现较好。
4.3 在线验证
根据车辆当前速度将在线辨识模型分为2类:高速超车和低速加速。速度大于门限值时选用前者;小于门限值则选取后者。采集驾驶员的操作数据积累达一定值后,驾驶员加速特性辨识系统开始工作并输出辨识结果。
从分类完成的3种类型的驾驶员中,随机挑选6名驾驶员进行在线辨识,比对结果,如表2所示。可以看出,驾驶员加速特性辨识模型显示结果与已知分类结果基本一致。
由表3可以看出,激进型驾驶员倾向使用偏大的加速特性增益因子,对这类驾驶员而言,他们期望的车辆反应比真实车辆反馈的偏大;一般型驾驶员喜欢当前的加速特性增益因子,对这类驾驶员,他们的期望大多已经与车辆反馈相一致;谨慎型驾驶员则偏爱较小的加速特性增益,这类驾驶员驾驶风格较为保守,这也符合我们生活中的实际情况。对于激进型驾驶员,其踏板开度总是接近全开状态,说明当前驱动力矩太小而不能满足其激进特性,选择较大的增益因子可以降低踏板工作负荷;对于谨慎型驾驶员,其踏板开度常处于较小状态,说明当前的驱动力矩较大,选择适当小的增益因子可以降低驾驶员的精神压力;对于一般型驾驶员,其踏板开度使用频率及其位置都是正常的,说明当前驱动力矩已经满足其驾驶需求,故驱动力矩可保持当前状态不变而增益因子为1。
在车辆行进过程中,为不同加速特性的驾驶员配备了不同的驱动力矩增益,踏板开度与驱动力矩的对应关系,如图8所示。相同加速踏板开度下,谨慎型驾驶员的驱动力矩值最小;激进型驾驶员的驱动力矩值最大;而一般型驾驶员的驱动力矩值介于上述二者之间。
5 驱动力矩增益匹配
驾驶员操纵车辆加速过程中,驾驶员踩踏板的频率、踩踏板的深浅程度及其他驾驶操作可以反映驾驶员的加速行为特性。合理反推,可以得出:不同加速特性的驾驶员,达到目标车速状态过程中所需的加速踏板到电机的驱动力矩之间的联系也不尽相同。由此引入一个驱动力矩增益,将该增益定义为加速特性增益因子,用车辆模型下的驱动力矩乘以该因子,即可得到不同增益下的等效驱动力矩。
上文将驾驶员加速特性分成了3类,在此基础上,从每一类驾驶员中各选出5个代表在驾驶模拟器上进行试验。通过对驾驶模拟器车辆模型中的驱动力矩增益不断进行调整,直到车辆运动状态满足驾驶员的需求喜好为止再停止调试,由此得到不同类驾驶员的加速特性增益因子。表3示出不同加速特性驾驶员对应的最匹配的驱动力矩增益因子以及最终得到的平均值。
6 结论
通过设计不同的城市道路工况,分别研究了高速超车工况和低速加速工况下的驾驶员加速特性分类,利用K-means聚类算法将驾驶员分为谨慎型、一般型和激进型。应用分类结果,分别训练了高速超车工况和低速加速工况的神经网络辨识模型并进行了试验台验证。通过试验不断地调整驱动力矩增益,直到车辆运动状态符合驾驶员的喜好加速特性,实现了不同类型驾驶员与驱动力矩增益的匹配。试验结果表明,研究方法能够对驾驶员加速特性进行合理分类,准确辨别驾驶员的加速特性并匹配合适的加速增益因子。







最新资讯
-
推荐性国家标准《乘/商用车电子机械制动卡
2025-04-30 11:13
-
载荷分解
2025-04-30 10:46
-
布雷博在上海开设亚洲首个灵感实验室
2025-04-30 10:25
-
组分性能对锂离子电池卷芯挤压力学响应的影
2025-04-30 09:00
-
美国发布自动驾驶新框架,放宽报告要求+扩
2025-04-30 08:59
