




 广告
广告





















































机器学习之全面了解模型验证
2021-03-04 00:53:59· 来源:MATLAB 作者:MathWorks

作者:Laura Martinez Molera ◆ ◆ ◆ ◆ 本专栏我们将和大家一起探讨机器学习与数据科学的主题,解释相关背景知识,并就一些来自 MATLAB 和 Simulink 社区的问题进行解答。 本文主要介绍模型验证及其相关主题,如过拟合和超参数调优。我将概括介绍该主题

本专栏我们将和大家一起探讨机器学习与数据科学的主题,解释相关背景知识,并就一些来自 MATLAB 和 Simulink 社区的问题进行解答。
本文主要介绍模型验证及其相关主题,如过拟合和超参数调优。我将概括介绍该主题及其重要性,然后探讨以下四个问题:
1. 模型准确率为什么会变差?
2. 训练数据集和测试数据集有什么区别?
3. 验证数据集用来做什么?
4. 如何在改进模型的同时避免过拟合?
引言
模型验证是机器学习的一项基础方法。如果使用得当,它将帮助您评估机器学习模型在新数据上的表现。
这可以提供两方面的帮助:
它可以帮助您确定要使用的算法和参数。 它可以防止训练过程中出现过拟合。
当我们用手头的数据集解决问题时,找到合适的机器学习算法来创建模型非常重要。每个模型都有自己的优点和缺点。
例如,某些算法能更好地处理小型数据集,另一些算法则在处理大量高维数据时表现出色。
因此,两个不同的模型可能基于同一个数据集预测出不同的结果,并且具有不同的准确度。
为您的数据找到最佳模型是一个交互式过程,需要测试不同的算法以最大程度地减少模型误差。
控制机器学习算法行为的参数称为超参数。
根据超参数取值的差异,所得的模型可能大相径庭。因此,通过调整超参数的值,您可以得到不同并且有可能更好的模型。
如果没有模型验证,很容易不知不觉将模型调整到过拟合的程度。
您的训练算法应该调整参数以最小化损失函数,但有时会做得太过。
发生这种情况时,模型将变得过拟合,也就是说,模型过于复杂,不能很好地处理新数据。
我将在下面的问题中更深入地探讨这一点。
要测试您的模型在新数据上的表现,可以使用模型验证,方法是对数据集进行划分,然后使用一个子集训练算法,使用其余数据测试算法。
由于模型验证并未将全部数据用于构建模型,因此是防止训练过程中出现过拟合的一种常用方法。
|
小贴士
如果您想深入了解有关使用 MATLAB 进行交叉验证和超参数优化的函数和语法,请参见:模型构建和评估(https://ww2.mathworks.cn/help/stats/classification-model-building-and-assessment.html)。
|
现在讨论第一个问题。
Q1、我的模型可以很好地处理训练数据,但是处理新数据时,结果并不理想。我该如何解决这个问题?
看样子您的模型是过拟合了,也就是说您的模型完全跟着训练集走,但不知道如何对新输入或数据作出响应。模型对训练所用数据集的响应“好过头了”。
一开始,过拟合模型可能会显得很成功,因为它在训练集上的误差很小。然而,模型在测试集上的误差会变大,也就不那么准确了。
模型过拟合的最常见原因是训练数据不足,因此最好的解决方法是收集更多的数据,更好地训练模型。
但是,您不仅需要更多的数据,还需要确保这些数据足以代表模型的复杂性和多样性,以便模型知道如何对其作出响应。
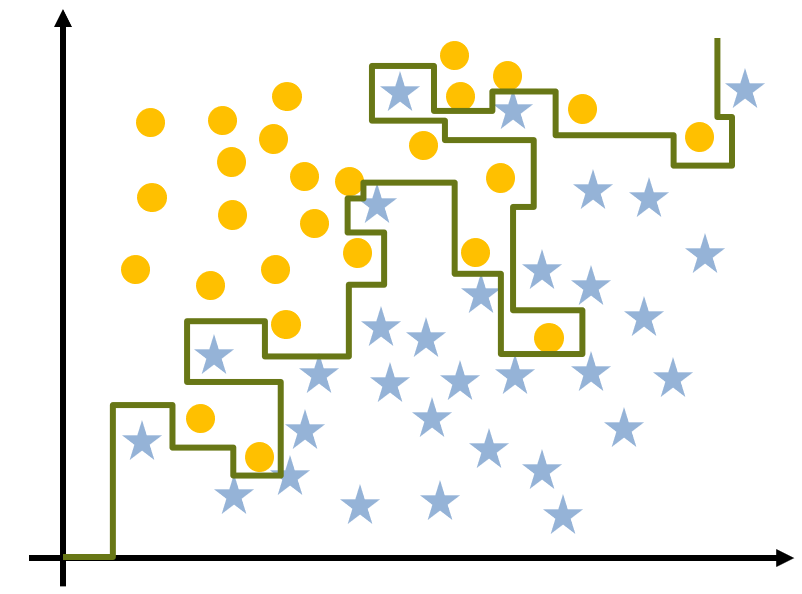
Q2、我知道数据需要分组,但是我以为测试数据集和训练数据集的用途相同。它们之间有什么区别?
实际上,测试数据集和训练数据集是不同的。在前面介绍模型验证时,我谈到了模型验证如何将数据划分为这样两个子集,接下来我深入探讨一下。
模型验证使用随机划分到不同子集的数据,通过调整模型来对新输入作出正确的响应,从而降低模型过拟合的风险。两种典型的数据子集如下:
-
训练集 - 这部分数据用于训练和拟合模型并确定参数,通常占数据的 60-70%,需要反映模型的复杂性和多样性。
-
测试集 - 这部分数据用于评估模型的性能,通常占数据的 30-40%,同样需要反映模型的复杂性和多样性。
由于这两个数据集都需要反映模型的复杂性和多样性,因此数据应该是随机划分的。
这种方法也会降低模型过拟合的风险,帮助我们得出更准确但更简单的模型,以将其结果用于研究。
如果我们使用非随机选择的数据集训练模型,则就这一特定数据子集而言,模型将得到很好的训练。
问题在于,非随机数据不能代表其余数据,也不能代表我们要用模型处理的新数据。
比如说,我们要分析一个城镇的能源消耗。如果我们用于训练和测试的数据集不是随机的,只包含周末的能源消耗数据(通常低于工作日),那么当我们将该模型应用于新数据(例如新月份)时,它会是不准确的,因为它只代表周末。
为了形象说明,我们来看两个基于同一训练数据集的模型。这里使用的是机器学习入门之旅(https://ww2.mathworks.cn/learn/tutorials/machine-learning-onramp.html)中的一个基本示例。
以下是一个简单模型和一个复杂模型:
简单模型
84% 准确度
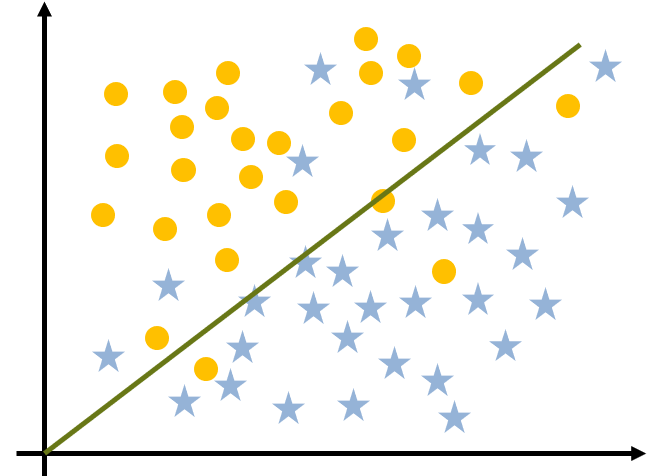
复杂模型
100% 准确度
我们会看到,复杂模型可以更好地适应训练数据,其准确度为 100%,而简单模型为 84%。
我们会倾向于认为复杂模型胜出。
但是,让我们看看如果将测试数据集(未在训练中使用的新数据)输入这些模型会有什么结果:
简单模型
70% 准确度
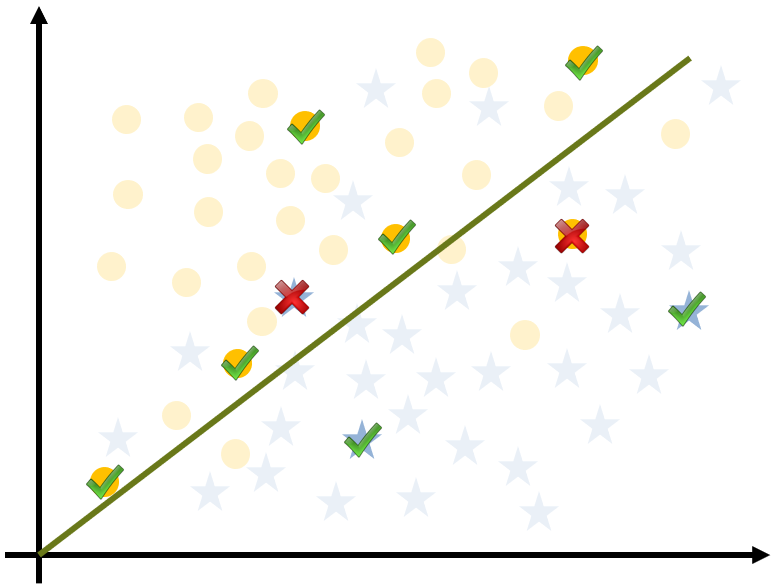
复杂模型
60% 准确度

比较两种模型的性能时,我们会发现简单模型的准确度从 84% 下降到 70%;
然而,相比复杂模型 40 个百分点的跌幅(从 100% 降至 60%),这点变化就不那么明显了。
总结一下,对此分析而言,简单模型更好、更准确,同时我们也看到,使用测试数据集来评估模型非常重要。
最后,还有一个建议。为了降低变异性,不妨使用数据集的多种划分进行多轮模型验证,以使模型更好地适应您的分析。
这种方法称为 K 折交叉验证。了解其他交叉验证方法,您可以访问:https://ww2.mathworks.cn/discovery/cross-validation.html。
我使用的示例可以在机器学习入门之旅中找到。您可以通过这个链接在 PC 端访问这个两小时的免费、交互式学习课程:https://ww2.mathworks.cn/learn/tutorials/machine-learning-onramp.html。

很遗憾,验证集再次遭到误解。
这是一个常见的问题。一般情况下,没有人会质疑训练集和测试集的必要性,但验证集的必要性则不是那么确凿。
简单的解释是,超参数调整中需要使用验证集,以查看调整是否有效,换句话说,能否在完整模型上进行迭代。但是,有时人们错误地使用验证集来描述测试数据集。
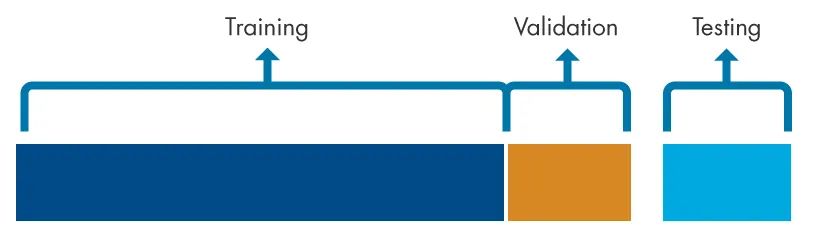
下面,我会详细说明验证数据集的重要性:
-
验证集 - 此数据集用于在调整模型的超参数时评估模型的性能。该数据用于更频繁的评估,并用于更新超参数,因此验证集会间接影响模型。调整模型的超参数并不是绝对必要的,但通常建议这样做。
-
测试集 - 此数据集用于对训练集中的最终模型拟合进行无偏评估。此数据集只在模型训练完成后使用一次,并且不影响模型;它只是用于计算性能。
总结一下,训练数据集用于训练可用的各种算法,验证数据集用于比较不同算法(使用不同的超参数)的性能,并决定采用哪一种算法。测试数据集用于了解特定模型的准确度、敏感度和性能。
这是个好问题。
在本文的简介部分,我简要提到了超参数可以控制机器学习算法的行为。接下来,我将对此进行更深入的介绍。
您可以将超参数想像成自行车的部件:我们可以通过改变它们来影响系统的性能。
假设您购买了一辆二手自行车。车架尺寸合适,但如果您调整一下座椅高度,收紧或放松刹车,给链条上油或安装适合地形的轮胎,这辆自行车可能会更高效。
外部因素也会影响您的骑行,但是有了一辆优化过的自行车,同一段行程会变得更轻松。类似地,优化超参数将帮助您改进模型。
下面是一个机器学习示例。在人工神经网络 (ANN) 中,超参数是确定网络结构的变量,例如人工神经元的隐藏层数和每一层中的人工神经元数;或者是定义如何训练模型的变量,例如学习率,即学习过程的速度。
超参数是在学习过程开始之前定义的。相对地,ANN 的参数是每个人工神经元连接的系数或权重,并在训练过程中进行调整。

典型的神经网络架构
超参数是在训练或学习过程开始之前确定的模型参数,它位于模型的外部;换句话说,如果您想更改超参数,需要手动更改。
自行车座椅不会自行调整,您需要在出发前先行调整;类比到机器学习模型中,就是使用验证数据集进行调整。
相对地,其他参数是在训练过程中使用训练数据集确定的。
训练和测试模型所需的时间取决于其超参数,模型的超参数越少,越易于验证或调整,因此您可以减小验证数据集的大小。

非凸曲面示例
大多数机器学习问题都是非凸的。
这意味着根据我们为超参数选择的值,我们可以得到完全不同的模型,并且,通过更改超参数的值,我们可以找到不同的、更好的模型。
这就是验证数据集的重要之处,它让您能够使用不同的超参数进行迭代,从而为您的分析找到最佳模型。
如果您想进一步了解超参数,不妨看看 Adam Filion 这段 5 分钟的视频,其中相当扼要地介绍了超参数优化。
以上就是本文的全部内容。希望您喜欢这个“模型验证”专栏。如果您希望看到更多其他机器学习与数据科学主题的探讨,欢迎留言告诉我们。
- 下一篇:多功能——电动车模块化平台全面推行
- 上一篇:汽车座椅横梁轻量化设计方法研究



编辑推荐




最新资讯
-
大卓智能端到端直播实测,16公里复杂路段挑
2025-04-25 17:16
-
《汽车轮胎耐撞击性能试验方法-车辆法》等
2025-04-25 11:45
-
“真实”而精确的能量流测试:电动汽车能效
2025-04-25 11:44
-
GRAS助力中国高校科研升级
2025-04-25 10:25
-
梅赛德斯-AMG使用VI-CarRealTime开发其控制
2025-04-25 10:21
