




 广告
广告





















































自动驾驶感知领域的革命:抛弃帧的事件相机将给高算力AI芯片沉重打击
2021-03-22 11:34:40· 来源:佐思汽车研究 作者:周彦武

今年1月初,瑞典初创公司Terranet宣布斩获了来自汽车产业巨头戴姆勒梅赛德斯奔驰的Voxelflow原型采购订单,订单价值31000欧元。这笔采购订单是Terranet和戴姆勒
今年1月初,瑞典初创公司Terranet宣布斩获了来自汽车产业巨头戴姆勒梅赛德斯奔驰的Voxelflow原型采购订单,订单价值31000欧元。这笔采购订单是Terranet和戴姆勒于2020年10月签署的谅解备忘录(MoU)的延续,双方的谅解备忘录涉及ADAS和防撞解决方案的原型验证、产品开发和产业化。下一步是将VoxelFlow集成到奔驰的测试车辆中。
实际Terranet的核心是基于事件的图像传感器(Event-based Camera Sensor,或Event-driven Camera Sensor,下文简称事件相机)。事件相机主要有两种,DVS(Dynamic Vision Sensor)以及DAVIS(Dynamic and ActivePixel Vision Sensor)。DVS是普通的事件相机,而DAVIS就是在回传事件的同时还可以回传灰度图。

事件相机的灵感来自人眼和动物的视觉,也有人称之为硅视网膜。生物的视觉只针对有变化的区域才敏感,比如眼前突然掉下来一个物体,那么人眼会忽视背景,会将注意力集中在这个物体上,事件相机就是捕捉事件的产生或者说变化的产生。在传统的视觉领域,相机传回的信息是同步的,所谓同步,就是在某一时刻t,相机会进行曝光,把这一时刻所有的像素填在一个矩阵里回传,一张照片就诞生了。一张照片上所有的像素都对应着同一时刻。至于视频,不过是很多帧的图片,相邻图片间的时间间隔可大可小,这便是我们常说的帧率(frame rate),也称为时延(time latency)。事件相机类似于人类的大脑和眼睛,跳过不相关的背景,直接感知一个场景的核心,创建纯事件而非数据。
实际上自动驾驶领域99%的视觉数据在AI处理中是无用的背景。这就好像检测鬼探头,变化的区域是很小一部分,但传统的视觉处理仍然要处理99%的没有出现变化的背景区域,这不仅浪费了大量的算力,也浪费了时间。亦或者像在沙砾里有颗钻石,AI芯片和传统相机需要识别每一颗沙粒,筛选出钻石,但人类只需要看一眼就能检测到钻石,AI芯片和传统相机耗费的时间是人类的100倍或1000倍。
事件相机的工作机制是,当某个像素所处位置的亮度发生变化达到一定阈值时,相机就会回传一个上述格式的事件,其中前两项为事件的像素坐标,第三项为事件发生的时间戳,最后一项取值为极性(polarity)0、1(或者-1、1),代表亮度是由低到高还是由高到低,也常被称作Positive or Negative Event,又被称作On or Off Event。
就这样,在整个相机视野内,只要有一个像素值变化,就会回传一个事件,这些所有的事件都是异步发生的(再小的时间间隔也不可能完全同时),所以事件的时间戳均不相同,由于回传简单,所以和传统相机相比,它具有低时延的特性,可以捕获很短时间间隔内的像素变化。延迟是微秒级的。
除了冗余信息减少和几乎没有延迟的优点外,事件相机的优点还有由于低时延,在拍摄高速物体时传统相机会发生模糊(由于会有一段曝光时间),而事件相机几乎不会。再就是真正的高动态范围,由于事件相机的特质,在光强较强或较弱的环境下(高曝光和低曝光),传统相机均会“失明”,但像素变化仍然存在,所以事件相机仍能看清眼前的东西。

传统相机

事件相机
传统相机的动态范围是无法做宽的,因为放大器会有线性范围,照顾了低照度就无法适应强光,反过来适应了强光就无法顾及低照度。
事件相机在目标追踪、动作识别等领域具备压倒性优势,尤其适合自动驾驶领域。
空中一个球的轨迹

扔一个球,看看两种相机的轨迹记录
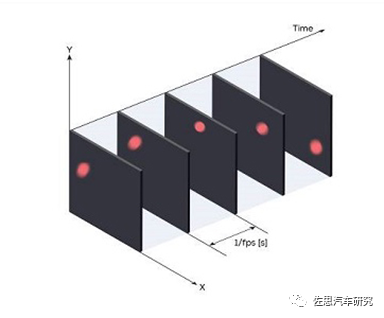
传统相机的帧记录
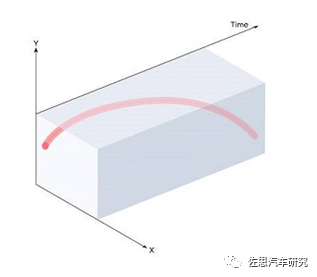
事件相机的轨迹记录
事件相机的出现对高算力AI芯片是致命打击,它只需要传统高算力AI芯片1%甚至0.1%的算力就可完美工作,功耗是毫瓦级。并且它是基于流水线时间戳方式处理数据,而不是一帧帧地平面处理各个像素。传统卷积算法可能无用,AI芯片最擅长的乘积累加运算可能没有用武之地。
像特斯拉目前最顶配的FSD,8个摄像头的分辨率只有130万像素,就已经需要144TOPS的算力,而目前英伟达的自动驾驶试验车型用的摄像头已经是800万像素,因此1000TOPS的算力是必须的,如此大的算力不仅带来高成本,还有高热量。除非能挖矿,否则是太浪费了。即便如此,高算力和安全也没有关系,摄像头的帧率一般是30Hz,注定了至少有33毫秒的延迟,这个哪怕你的算力达到1亿TOPS也于事无补。为了准确检测行人并预测其路径,需要多帧处理,至少是10帧,也就是330毫秒。这意味着相关系统可能需要数百毫秒才能实现有效探测,而对于一辆以60公里每小时行进中的车辆来说,330毫秒的时间就能行驶5.61米。而事件相机理论上不超过1毫秒。
视频即静止图像序列,计算机视觉一直朝着“视频摄像头+计算机+算法=机器视觉”的主流方向,却很少人质疑用图像序列(视频)表达视觉信息的合理性,更少人质疑是否凭借该计算机视觉算法就能实现真正机器视觉。人类视觉系统具有低冗余、低功耗、高动态及鲁棒性强等优势,可以高效地自适应处理动态与静态信息,且具有极强地小样本泛化能力和全面的复杂场景感知能力。1990 年Mead 首次在《Proceedings of IEEE》上提出神经形态(Neuromorphic)的概念,利用大规模集成电路来模拟生物神经系统。1991 年 Mahowald 和Mead在《Scientific American》的封面刊登了一只运动的猫,标志了第一款硅视网膜的诞生,其模拟了视网膜上视锥细胞、水平细胞以及双极细胞的生物功能,正式点燃了神经形态视觉传感器这一新兴领域。Mahowald解释称,“模仿人类视网膜,这种‘硅视网膜’通过从图像中减去平均强度水平,只报告空间和时间变化,从而减少了带宽。”1993 年 Mahowald团队为了解决集成电路的稠密三维连线的问题,提出了一种新型的集成电路通信协议,即地址事件协议(Address-Event Representation, AER ),实现了事件的异步读出。2003年Culurciello 等人设计了一种 AER 方式的积分发放的脉冲模型,将像素光强编码为频率或脉冲间隔,称为章鱼视网膜(Octopus Retina)。2005年 Delbruck 团队研制出动态视觉传感器(Dynamic Vision Sensor, DVS),以时空异步稀疏的事件表示像素光强变化,其商业化具有里程牌的意义。然而,DVS无法捕捉自然场景的精细纹理图像。2008 年 Posh 等人提出了一种基于异步视觉的图像传感器(Asynchronous Time-based Image Sensor, ATIS),引入了基于事件触发的光强测量电路来重构变化处的像素灰度。
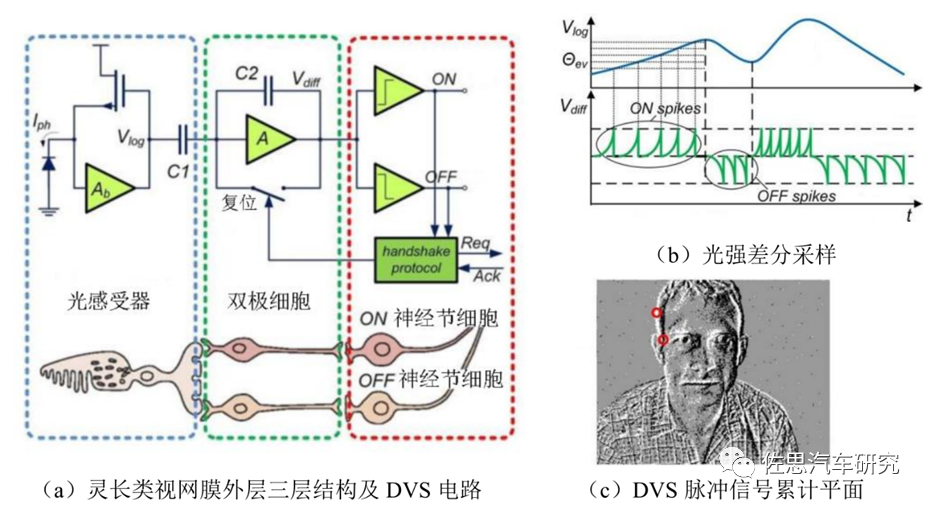
分型视觉采样
硅视网膜这种灵感推动了动态视觉传感器背后的概念,使苏黎世联邦理工学院成为该技术的创新中心,并孕育了像Prophesee、Insightness等无数初创企业。瑞士创新公司iniVation也是其中之一。百度则资助了CelePixel,后来韦尔股份收购了Celepixel。还有中科创星和联想创投联合投资的锐思智芯。
目前主要是索尼和三星在激烈竞争。初创公司不得不和这些传感器巨头合作,如Prophesee和索尼,iniVation和三星。2019年12月,索尼悄悄收购了总部位于苏黎世的Insightness公司。三星为其移动和平板电脑应用的动态视觉传感器(Dynamic Vision Sensor, DVS)技术提交了商标申请。
Prophesee和索尼是目前最接近商业化的。2020年2月,总部位于巴黎的Prophesee公司在完成2800万美元额外融资后不久,和索尼一起在美国旧金山举行的国际固态电路会议(International Solid-State Circuits Conference)上联合发布了这个130万像素的事件相机图像传感器。
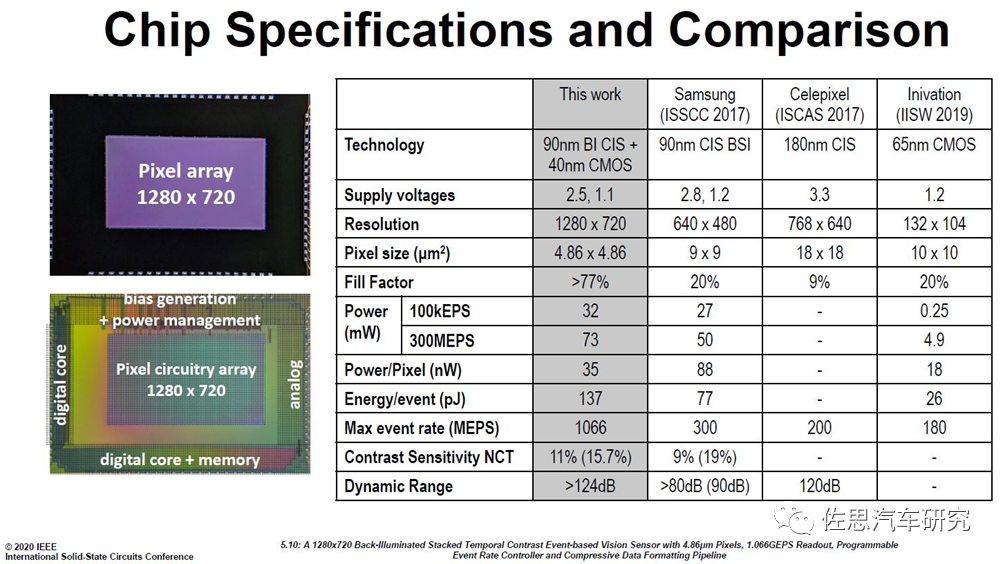
新款基于事件的图像传感器分辨率为1280 x 720像素,填充系数为77%,300MEPS版本的功耗为73mW。当基于帧的图像传感器根据帧速率以固定的间隔输出整幅图像时,基于事件的图像传感器使用“行选择仲裁电路”异步选择像素数据。通过在亮度发生变化的像素地址中添加1μs精度的时间信息,以确保具有高时间分辨率的事件数据读出。通过有效压缩事件数据,即每个事件的亮度变化极性、时间和x/y坐标信息,实现了1.066Geps的高输出事件发生率。
事件相机图像传感器并不复杂,每个像素都包含一个检测亮度变化的电路。
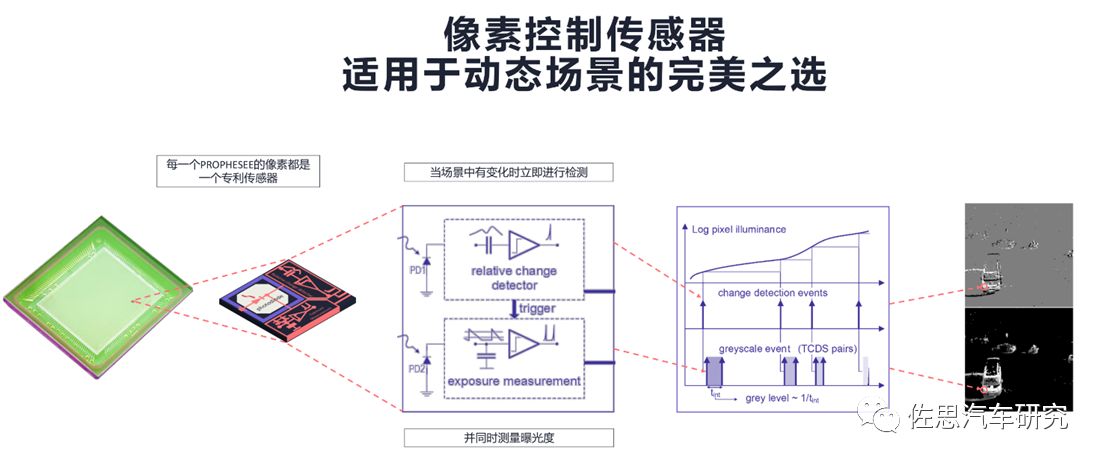
理念非常简洁,但是要商业化就要注意控制成本,对芯片来说,面积越大意味着成本越高,检测亮度变化的电路增加了面积,这意味着事件相机的像素会随着分辨率的增加而成本大增。索尼的BSI技术是关键,将背照式CMOS图像传感器部分(顶部芯片)和逻辑电路(底部芯片)堆叠时,通过连接的铜焊盘提供电连续性的技术。与硅通孔(Through Silicon Via, TSV)布线相比,通过在像素区域周围穿透电极来实现连接,与之相比,此方法在设计上具有更大的自由度,提高了生产率,缩小了尺寸并提高了性能。索尼于2016年12月在旧金山举行的国际电子设备会议(IEDM)上宣布了这项技术。也靠这项技术稳居图像传感器霸主位置。
通过在像素芯片(顶部)只放置背光像素和N型MOS晶体管的一部分,将光孔进光率提高到77%,从而实现业界最高的124dB HDR性能(或更高)。索尼在CMOS图像传感器开发过程中经年累积的高灵敏度/低噪声技术使得事件检测能在微光条件下(40mlx)进行。像素芯片(顶部)和逻辑芯片(底部)结合信号处理电路,检测亮度变化基于异步增量调制法分别排列。两个单独芯片的每个像素都使用Cu-Cu连接以堆叠配置进行电连接。除了业界较小的4.86μm像素尺寸,该传感器通过采用精细的40nm逻辑工艺实现高密度集成,为1/2英寸,1280x720高清分辨率。
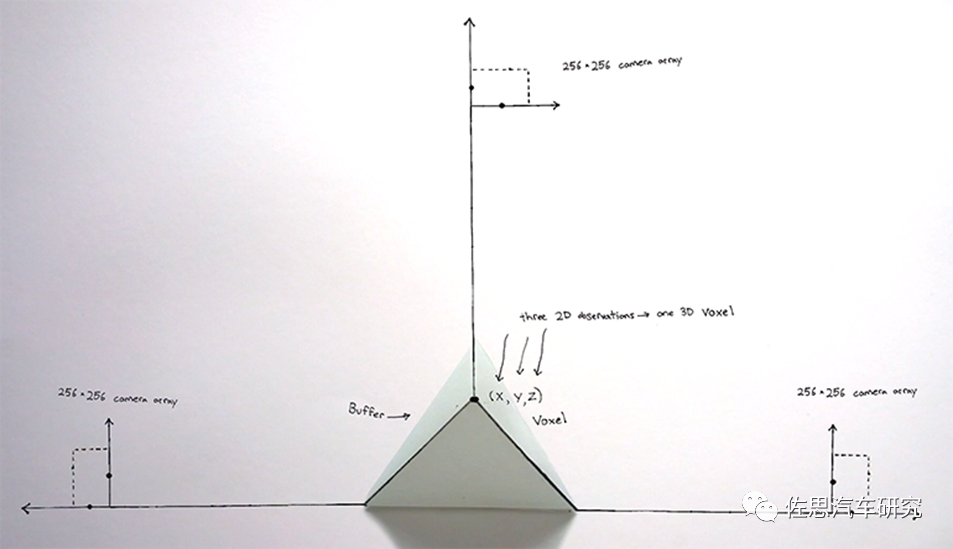
事件相机仍然无法取代激光雷达或双目系统,因为它无法提供深度信息,因此事件相机必须配合激光雷达才能实现完美的3D感知。这就回到了文章开头,Terranet的秘密武器就是事件相机,Terranet用事件相机增强激光雷达的性能,这就是Terranet开发的所谓VoxelFlow,Terranet认为现在很多环境感知系统所使用的摄像头和传感器并不比苹果iPhone的标准配置强多少,而iPhone的FaceID每帧也只能产生33000个光点。Terranet公司目前正在开发的基于事件的传感技术VoxelFlow,能够凭借很低的算力,以极低的延时对动态移动物体进行分类。VoxelFlow技术每秒可以生成1000万个3D点云,提供没有运动模糊的快速边缘检测。基于事件的传感器的超低延时性能,能够确保车辆及时应对“鬼探头”问题,采取紧急制动、加速或绕过突然出现在车辆后方的物体以避免碰撞事故。Voxelflow是一种新型的计算机视觉解决方案,它由三个基于事件的摄像头和一个激光扫描仪组成。Voxelflow用主动照明技术通过3D三角测量,创建带时间戳的点云(x、y、z)光栅图像。
现在的AI本质上还是一种蛮力计算,依靠海量数据和海量算力,对数据集和算力的需求不断增加,这显然离初衷越来越远,文明的每一次进步都带来效率的极大提高,唯有效率的提高才是进步,而依赖海量数据和海量算力的AI则完全相反,效率越来越低,事件相机才是正确的方向。
实际Terranet的核心是基于事件的图像传感器(Event-based Camera Sensor,或Event-driven Camera Sensor,下文简称事件相机)。事件相机主要有两种,DVS(Dynamic Vision Sensor)以及DAVIS(Dynamic and ActivePixel Vision Sensor)。DVS是普通的事件相机,而DAVIS就是在回传事件的同时还可以回传灰度图。
事件相机的灵感来自人眼和动物的视觉,也有人称之为硅视网膜。生物的视觉只针对有变化的区域才敏感,比如眼前突然掉下来一个物体,那么人眼会忽视背景,会将注意力集中在这个物体上,事件相机就是捕捉事件的产生或者说变化的产生。在传统的视觉领域,相机传回的信息是同步的,所谓同步,就是在某一时刻t,相机会进行曝光,把这一时刻所有的像素填在一个矩阵里回传,一张照片就诞生了。一张照片上所有的像素都对应着同一时刻。至于视频,不过是很多帧的图片,相邻图片间的时间间隔可大可小,这便是我们常说的帧率(frame rate),也称为时延(time latency)。事件相机类似于人类的大脑和眼睛,跳过不相关的背景,直接感知一个场景的核心,创建纯事件而非数据。
实际上自动驾驶领域99%的视觉数据在AI处理中是无用的背景。这就好像检测鬼探头,变化的区域是很小一部分,但传统的视觉处理仍然要处理99%的没有出现变化的背景区域,这不仅浪费了大量的算力,也浪费了时间。亦或者像在沙砾里有颗钻石,AI芯片和传统相机需要识别每一颗沙粒,筛选出钻石,但人类只需要看一眼就能检测到钻石,AI芯片和传统相机耗费的时间是人类的100倍或1000倍。
事件相机的工作机制是,当某个像素所处位置的亮度发生变化达到一定阈值时,相机就会回传一个上述格式的事件,其中前两项为事件的像素坐标,第三项为事件发生的时间戳,最后一项取值为极性(polarity)0、1(或者-1、1),代表亮度是由低到高还是由高到低,也常被称作Positive or Negative Event,又被称作On or Off Event。
就这样,在整个相机视野内,只要有一个像素值变化,就会回传一个事件,这些所有的事件都是异步发生的(再小的时间间隔也不可能完全同时),所以事件的时间戳均不相同,由于回传简单,所以和传统相机相比,它具有低时延的特性,可以捕获很短时间间隔内的像素变化。延迟是微秒级的。
除了冗余信息减少和几乎没有延迟的优点外,事件相机的优点还有由于低时延,在拍摄高速物体时传统相机会发生模糊(由于会有一段曝光时间),而事件相机几乎不会。再就是真正的高动态范围,由于事件相机的特质,在光强较强或较弱的环境下(高曝光和低曝光),传统相机均会“失明”,但像素变化仍然存在,所以事件相机仍能看清眼前的东西。
传统相机
事件相机
传统相机的动态范围是无法做宽的,因为放大器会有线性范围,照顾了低照度就无法适应强光,反过来适应了强光就无法顾及低照度。
事件相机在目标追踪、动作识别等领域具备压倒性优势,尤其适合自动驾驶领域。
空中一个球的轨迹
扔一个球,看看两种相机的轨迹记录
传统相机的帧记录
事件相机的轨迹记录
事件相机的出现对高算力AI芯片是致命打击,它只需要传统高算力AI芯片1%甚至0.1%的算力就可完美工作,功耗是毫瓦级。并且它是基于流水线时间戳方式处理数据,而不是一帧帧地平面处理各个像素。传统卷积算法可能无用,AI芯片最擅长的乘积累加运算可能没有用武之地。
像特斯拉目前最顶配的FSD,8个摄像头的分辨率只有130万像素,就已经需要144TOPS的算力,而目前英伟达的自动驾驶试验车型用的摄像头已经是800万像素,因此1000TOPS的算力是必须的,如此大的算力不仅带来高成本,还有高热量。除非能挖矿,否则是太浪费了。即便如此,高算力和安全也没有关系,摄像头的帧率一般是30Hz,注定了至少有33毫秒的延迟,这个哪怕你的算力达到1亿TOPS也于事无补。为了准确检测行人并预测其路径,需要多帧处理,至少是10帧,也就是330毫秒。这意味着相关系统可能需要数百毫秒才能实现有效探测,而对于一辆以60公里每小时行进中的车辆来说,330毫秒的时间就能行驶5.61米。而事件相机理论上不超过1毫秒。
视频即静止图像序列,计算机视觉一直朝着“视频摄像头+计算机+算法=机器视觉”的主流方向,却很少人质疑用图像序列(视频)表达视觉信息的合理性,更少人质疑是否凭借该计算机视觉算法就能实现真正机器视觉。人类视觉系统具有低冗余、低功耗、高动态及鲁棒性强等优势,可以高效地自适应处理动态与静态信息,且具有极强地小样本泛化能力和全面的复杂场景感知能力。1990 年Mead 首次在《Proceedings of IEEE》上提出神经形态(Neuromorphic)的概念,利用大规模集成电路来模拟生物神经系统。1991 年 Mahowald 和Mead在《Scientific American》的封面刊登了一只运动的猫,标志了第一款硅视网膜的诞生,其模拟了视网膜上视锥细胞、水平细胞以及双极细胞的生物功能,正式点燃了神经形态视觉传感器这一新兴领域。Mahowald解释称,“模仿人类视网膜,这种‘硅视网膜’通过从图像中减去平均强度水平,只报告空间和时间变化,从而减少了带宽。”1993 年 Mahowald团队为了解决集成电路的稠密三维连线的问题,提出了一种新型的集成电路通信协议,即地址事件协议(Address-Event Representation, AER ),实现了事件的异步读出。2003年Culurciello 等人设计了一种 AER 方式的积分发放的脉冲模型,将像素光强编码为频率或脉冲间隔,称为章鱼视网膜(Octopus Retina)。2005年 Delbruck 团队研制出动态视觉传感器(Dynamic Vision Sensor, DVS),以时空异步稀疏的事件表示像素光强变化,其商业化具有里程牌的意义。然而,DVS无法捕捉自然场景的精细纹理图像。2008 年 Posh 等人提出了一种基于异步视觉的图像传感器(Asynchronous Time-based Image Sensor, ATIS),引入了基于事件触发的光强测量电路来重构变化处的像素灰度。
分型视觉采样
硅视网膜这种灵感推动了动态视觉传感器背后的概念,使苏黎世联邦理工学院成为该技术的创新中心,并孕育了像Prophesee、Insightness等无数初创企业。瑞士创新公司iniVation也是其中之一。百度则资助了CelePixel,后来韦尔股份收购了Celepixel。还有中科创星和联想创投联合投资的锐思智芯。
目前主要是索尼和三星在激烈竞争。初创公司不得不和这些传感器巨头合作,如Prophesee和索尼,iniVation和三星。2019年12月,索尼悄悄收购了总部位于苏黎世的Insightness公司。三星为其移动和平板电脑应用的动态视觉传感器(Dynamic Vision Sensor, DVS)技术提交了商标申请。
Prophesee和索尼是目前最接近商业化的。2020年2月,总部位于巴黎的Prophesee公司在完成2800万美元额外融资后不久,和索尼一起在美国旧金山举行的国际固态电路会议(International Solid-State Circuits Conference)上联合发布了这个130万像素的事件相机图像传感器。
新款基于事件的图像传感器分辨率为1280 x 720像素,填充系数为77%,300MEPS版本的功耗为73mW。当基于帧的图像传感器根据帧速率以固定的间隔输出整幅图像时,基于事件的图像传感器使用“行选择仲裁电路”异步选择像素数据。通过在亮度发生变化的像素地址中添加1μs精度的时间信息,以确保具有高时间分辨率的事件数据读出。通过有效压缩事件数据,即每个事件的亮度变化极性、时间和x/y坐标信息,实现了1.066Geps的高输出事件发生率。
事件相机图像传感器并不复杂,每个像素都包含一个检测亮度变化的电路。
理念非常简洁,但是要商业化就要注意控制成本,对芯片来说,面积越大意味着成本越高,检测亮度变化的电路增加了面积,这意味着事件相机的像素会随着分辨率的增加而成本大增。索尼的BSI技术是关键,将背照式CMOS图像传感器部分(顶部芯片)和逻辑电路(底部芯片)堆叠时,通过连接的铜焊盘提供电连续性的技术。与硅通孔(Through Silicon Via, TSV)布线相比,通过在像素区域周围穿透电极来实现连接,与之相比,此方法在设计上具有更大的自由度,提高了生产率,缩小了尺寸并提高了性能。索尼于2016年12月在旧金山举行的国际电子设备会议(IEDM)上宣布了这项技术。也靠这项技术稳居图像传感器霸主位置。
通过在像素芯片(顶部)只放置背光像素和N型MOS晶体管的一部分,将光孔进光率提高到77%,从而实现业界最高的124dB HDR性能(或更高)。索尼在CMOS图像传感器开发过程中经年累积的高灵敏度/低噪声技术使得事件检测能在微光条件下(40mlx)进行。像素芯片(顶部)和逻辑芯片(底部)结合信号处理电路,检测亮度变化基于异步增量调制法分别排列。两个单独芯片的每个像素都使用Cu-Cu连接以堆叠配置进行电连接。除了业界较小的4.86μm像素尺寸,该传感器通过采用精细的40nm逻辑工艺实现高密度集成,为1/2英寸,1280x720高清分辨率。
事件相机仍然无法取代激光雷达或双目系统,因为它无法提供深度信息,因此事件相机必须配合激光雷达才能实现完美的3D感知。这就回到了文章开头,Terranet的秘密武器就是事件相机,Terranet用事件相机增强激光雷达的性能,这就是Terranet开发的所谓VoxelFlow,Terranet认为现在很多环境感知系统所使用的摄像头和传感器并不比苹果iPhone的标准配置强多少,而iPhone的FaceID每帧也只能产生33000个光点。Terranet公司目前正在开发的基于事件的传感技术VoxelFlow,能够凭借很低的算力,以极低的延时对动态移动物体进行分类。VoxelFlow技术每秒可以生成1000万个3D点云,提供没有运动模糊的快速边缘检测。基于事件的传感器的超低延时性能,能够确保车辆及时应对“鬼探头”问题,采取紧急制动、加速或绕过突然出现在车辆后方的物体以避免碰撞事故。Voxelflow是一种新型的计算机视觉解决方案,它由三个基于事件的摄像头和一个激光扫描仪组成。Voxelflow用主动照明技术通过3D三角测量,创建带时间戳的点云(x、y、z)光栅图像。
现在的AI本质上还是一种蛮力计算,依靠海量数据和海量算力,对数据集和算力的需求不断增加,这显然离初衷越来越远,文明的每一次进步都带来效率的极大提高,唯有效率的提高才是进步,而依赖海量数据和海量算力的AI则完全相反,效率越来越低,事件相机才是正确的方向。



编辑推荐



最新资讯
-
奇石乐推出用于DAQ数据采集系统的KiStudio
2025-04-28 17:51
-
全球首次!IVISTA 2023版修订版引入带灯光
2025-04-28 09:59
-
我国首批5G毫米波行业标准送审稿审查通过
2025-04-28 08:56
-
5/16 厦门- 新能源汽车电驱测试技术的创新
2025-04-28 08:53
-
国内首个汽车电磁防护技术验证体系EMTA正式
2025-04-28 08:49
