




 广告
广告





















































自动驾驶感知中的深度学习
2021-05-07 13:29:02· 来源:数理之家

导 读自动驾驶是一种自主决策系统,它处理来自不同车载来源的观测流,如照相机、雷达、激光雷达、超声波传感器、GPS装置和/或惯性传感器。这些观察结果被汽车的
导 读
自动驾驶是一种自主决策系统,它处理来自不同车载来源的观测流,如照相机、雷达、激光雷达、超声波传感器、GPS装置和/或惯性传感器。这些观察结果被汽车的计算机用来做驾驶决定。
1 传统目标检测与识别的步骤
所谓目标检测,就是区分图像或者视频中的目标与其他不感兴趣的部分,不同物体同画面产生了一些明显区分,那么如何让计算机像人类一样做到明确区分呢?
这就涉及目标检测,可以说让计算机能够区分出这些,是目标检测的第一步:目标特征提取。
目标检测的第二步:目标识别。是让计算机识别刚才区分出来的画面究竟是什么,从而确定视频或图像中目标的种类。例如为了实现自动驾驶的目标,最初需要让计算机认识交通目标,才能让其成为真正的AI老司机。
如何建立一个高准确率、高召回率的物体识别系统?这实际是无人车感知的一个核心问题,而物体检测更是重中之重,要求我们对不同传感器设计不同的算法来准确检测障碍物。
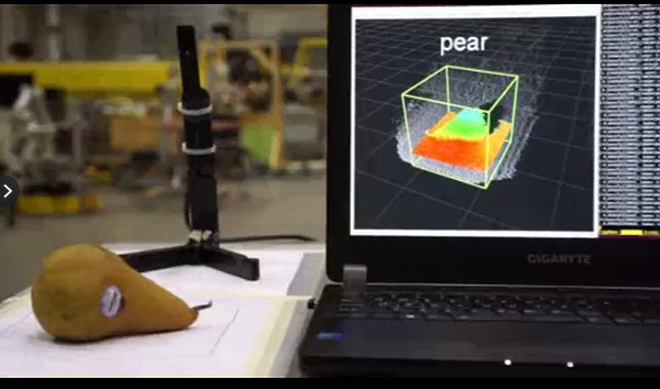
具体说到物体检测,我们要求完成单帧障碍物的检测,并借助传感器内外参数标定转换矩阵,将检测结果统一影射到车身的座标系中,这种物体检测算法既快速又准确。
2 为何要引入深度学习

深度学习的方法进行图像处理,最大的区别就是特征图不再通过人工特征提取,而是利用计算机,这样提取出来的特征会非常丰富,也很全面,深度学习可以实现端到端的感知效果。
深度学习可以被理解为全自动的算法,可以在没有人干预的情况下完成一个算法的流程,这是深度学习相较于传统机器学习最大的优势所在。
所谓的深度学习就是通过集联多层的神经网络形成一个很深的层,当层数越多,提取出来的特征也就越多而且越丰富。所以在目标检测和识别的过程中,最主要使用的深度学习特征提取模型就是深度卷积网络,英文简称CNN。
为什么CNN图像处理的方式比以前更好呢?究其原因,根本还是在于对图像特征提取。例如,当我们使用多层进行特征提取的时候,其实有些层是针对图像的边缘轮廓来提取的,有些则是针对质地或者纹理来进行的,还有些是针对物体特征进行操作,总而言之不同的层有不同的分割方式。
回归到目标检测这个问题上,卷积神经网络的每一层如果能够准确提取出所需特征,最后也就容易判断许多。因此决定CNN的目标检测和识别的关键就在于对每一层如何设计。
3 深度学习目标检测方法分类
深度学习针对当前目标检测的方法
1) 对于候选区域的目标检测算法,典型的网络是R-CNN和FasterR-CNN
以FasterR-CNN为例,首先提取图像中的候选区域,随后针对这些候选区域进行分类判断,当然由于这些候选区域是通过算法搜索出来的,所以并不一定准确,因此还需要对选出的区域做位置回归,随之进行目标定位,最后输出一个定位结果。总体来说,首先要先选择、再判断,最后剔除不想要的。
这种算法精度较高,不过由于需要反复进行候选区域的选择,所以算法的效率被限制。
2) 基于回归的目标检测算法,典型实现是YOLO和SSD
SSD的典型回归目标检测算法,分为四个步骤:第一步通过深度神经网络提取整个图片的特征;第二步对于不同尺度的深度特征图设计不同大小的特征抓取盒;第三步通过提取出这些抓去盒中的特征进行目标识别,最后,在识别出的这些结果中运用非极大值抑制选择最佳的目标识别结果。
只需观测一次图片就能进行目标的检测以及识别,因此算法的效率非常高。
3) 基于增强学习的目标检测算法,典型表现为深度Q学习网络
可以说场景适应性算是比较强的。增强学习算法目标检测可被看成不断动态调整候选区域边框的过程。
4 在自动驾驶中的应用
深度学习方法特别适合于从摄像机和lidar(光探测和测距)设备获取的2d图像和3d点云中检测和识别对象。
在自动驾驶中,三维感知主要基于激光雷达传感器,它以三维点云的形式提供对周围环境的直接三维表示。激光雷达的性能是根据视场、距离、分辨率和旋转/帧速率来衡量的。
3D传感器,如Velodyne通常具有360度水平视野。为了高速行驶,一辆自动驾驶汽车至少需要200米的行驶距离,使汽车能够及时对路况的变化作出反应,三维目标检测精度取决于传感器的分辨率,最先进的激光雷达能够提供3cm的精度。
摄像机则是对获取的图像通过深度学习方法进行处理,其主要依赖于分辨率的高度和算法的精准程度。
一辆自动驾驶汽车应该能够检测到交通参与者和可行驶区域,特别是在城市地区,那里可能出现各种各样的物体外观和遮挡。
基于深度学习的感知,特别是卷积神经网络(CNN)成为目标检测和识别的事实标准,在ImageNet大规模视觉识别挑战赛等比赛中取得显著成绩。
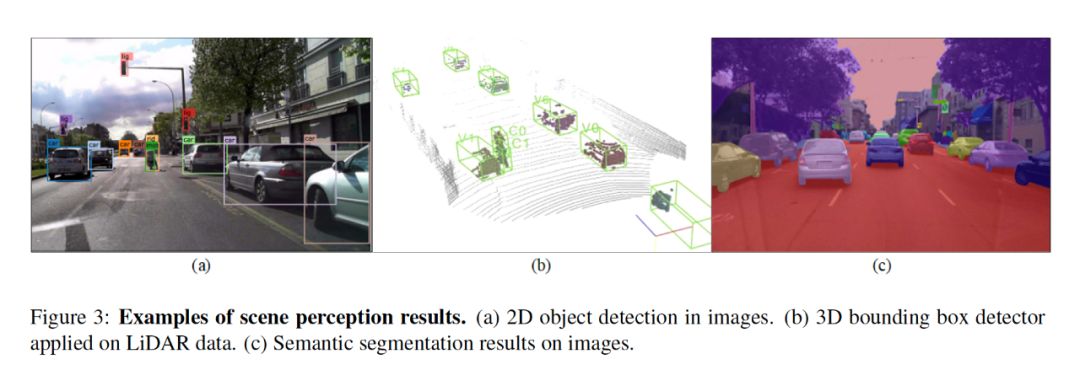
不同的神经网络结构用于检测二维感兴趣区域或图像中的像素分割区域,3DLidar点云中的边界盒以及组合相机Lidar数据中对象的三维表示。
场景感知结果的示例如图3所示。图像数据信息丰富,更适合于目标识别任务。然而,由于在将成像场景投影到成像传感器上时丢失了深度信息,因此必须估计被检测对象的真实3d位置。
以百度Apollo 为例,Apollo 障碍物感知系统分为 3D 检测、ROI 滤波、识别、运算、感知五大版块。
其感知过程如下:首先LiDAR探测到信号,传递给ROI的Filter,滤波后的信号通过Obstacle Segmentation和Detection识别,然后进行 Tracking。
Apollo在运算这一块采用的是NVIDIA GPU,运算能力强劲,可以实现10Hz的输出,最后是Obstacles感知。
环境感知主要包括当前环境的语义分割和静态、动态的目标检测,采用人工智能技术中的深度卷积神经网络通过前期的数据训练以及特征提取,给出复杂环境中场景物体类别等信息,帮助计算机精准地理解周边的环境态势。
自动驾驶是一种自主决策系统,它处理来自不同车载来源的观测流,如照相机、雷达、激光雷达、超声波传感器、GPS装置和/或惯性传感器。这些观察结果被汽车的计算机用来做驾驶决定。
1 传统目标检测与识别的步骤
所谓目标检测,就是区分图像或者视频中的目标与其他不感兴趣的部分,不同物体同画面产生了一些明显区分,那么如何让计算机像人类一样做到明确区分呢?
这就涉及目标检测,可以说让计算机能够区分出这些,是目标检测的第一步:目标特征提取。
目标检测的第二步:目标识别。是让计算机识别刚才区分出来的画面究竟是什么,从而确定视频或图像中目标的种类。例如为了实现自动驾驶的目标,最初需要让计算机认识交通目标,才能让其成为真正的AI老司机。
如何建立一个高准确率、高召回率的物体识别系统?这实际是无人车感知的一个核心问题,而物体检测更是重中之重,要求我们对不同传感器设计不同的算法来准确检测障碍物。
具体说到物体检测,我们要求完成单帧障碍物的检测,并借助传感器内外参数标定转换矩阵,将检测结果统一影射到车身的座标系中,这种物体检测算法既快速又准确。
2 为何要引入深度学习
深度学习的方法进行图像处理,最大的区别就是特征图不再通过人工特征提取,而是利用计算机,这样提取出来的特征会非常丰富,也很全面,深度学习可以实现端到端的感知效果。
深度学习可以被理解为全自动的算法,可以在没有人干预的情况下完成一个算法的流程,这是深度学习相较于传统机器学习最大的优势所在。
所谓的深度学习就是通过集联多层的神经网络形成一个很深的层,当层数越多,提取出来的特征也就越多而且越丰富。所以在目标检测和识别的过程中,最主要使用的深度学习特征提取模型就是深度卷积网络,英文简称CNN。
为什么CNN图像处理的方式比以前更好呢?究其原因,根本还是在于对图像特征提取。例如,当我们使用多层进行特征提取的时候,其实有些层是针对图像的边缘轮廓来提取的,有些则是针对质地或者纹理来进行的,还有些是针对物体特征进行操作,总而言之不同的层有不同的分割方式。
回归到目标检测这个问题上,卷积神经网络的每一层如果能够准确提取出所需特征,最后也就容易判断许多。因此决定CNN的目标检测和识别的关键就在于对每一层如何设计。
3 深度学习目标检测方法分类
深度学习针对当前目标检测的方法
1) 对于候选区域的目标检测算法,典型的网络是R-CNN和FasterR-CNN
以FasterR-CNN为例,首先提取图像中的候选区域,随后针对这些候选区域进行分类判断,当然由于这些候选区域是通过算法搜索出来的,所以并不一定准确,因此还需要对选出的区域做位置回归,随之进行目标定位,最后输出一个定位结果。总体来说,首先要先选择、再判断,最后剔除不想要的。
这种算法精度较高,不过由于需要反复进行候选区域的选择,所以算法的效率被限制。
2) 基于回归的目标检测算法,典型实现是YOLO和SSD
SSD的典型回归目标检测算法,分为四个步骤:第一步通过深度神经网络提取整个图片的特征;第二步对于不同尺度的深度特征图设计不同大小的特征抓取盒;第三步通过提取出这些抓去盒中的特征进行目标识别,最后,在识别出的这些结果中运用非极大值抑制选择最佳的目标识别结果。
只需观测一次图片就能进行目标的检测以及识别,因此算法的效率非常高。
3) 基于增强学习的目标检测算法,典型表现为深度Q学习网络
可以说场景适应性算是比较强的。增强学习算法目标检测可被看成不断动态调整候选区域边框的过程。
4 在自动驾驶中的应用
深度学习方法特别适合于从摄像机和lidar(光探测和测距)设备获取的2d图像和3d点云中检测和识别对象。
在自动驾驶中,三维感知主要基于激光雷达传感器,它以三维点云的形式提供对周围环境的直接三维表示。激光雷达的性能是根据视场、距离、分辨率和旋转/帧速率来衡量的。
3D传感器,如Velodyne通常具有360度水平视野。为了高速行驶,一辆自动驾驶汽车至少需要200米的行驶距离,使汽车能够及时对路况的变化作出反应,三维目标检测精度取决于传感器的分辨率,最先进的激光雷达能够提供3cm的精度。
摄像机则是对获取的图像通过深度学习方法进行处理,其主要依赖于分辨率的高度和算法的精准程度。
一辆自动驾驶汽车应该能够检测到交通参与者和可行驶区域,特别是在城市地区,那里可能出现各种各样的物体外观和遮挡。
基于深度学习的感知,特别是卷积神经网络(CNN)成为目标检测和识别的事实标准,在ImageNet大规模视觉识别挑战赛等比赛中取得显著成绩。
不同的神经网络结构用于检测二维感兴趣区域或图像中的像素分割区域,3DLidar点云中的边界盒以及组合相机Lidar数据中对象的三维表示。
场景感知结果的示例如图3所示。图像数据信息丰富,更适合于目标识别任务。然而,由于在将成像场景投影到成像传感器上时丢失了深度信息,因此必须估计被检测对象的真实3d位置。
以百度Apollo 为例,Apollo 障碍物感知系统分为 3D 检测、ROI 滤波、识别、运算、感知五大版块。
其感知过程如下:首先LiDAR探测到信号,传递给ROI的Filter,滤波后的信号通过Obstacle Segmentation和Detection识别,然后进行 Tracking。
Apollo在运算这一块采用的是NVIDIA GPU,运算能力强劲,可以实现10Hz的输出,最后是Obstacles感知。
环境感知主要包括当前环境的语义分割和静态、动态的目标检测,采用人工智能技术中的深度卷积神经网络通过前期的数据训练以及特征提取,给出复杂环境中场景物体类别等信息,帮助计算机精准地理解周边的环境态势。



编辑推荐




最新资讯
-
2025年10大隐形车衣品牌排行榜
2025-04-07 10:40
-
沃尔沃卡车与Greenlane合作推动商业电动化
2025-04-07 08:42
-
江铃晶马:美标转欧标充电结构专利
2025-04-07 08:39
-
EMC成为新贸易壁垒,零跑在乌兹被全面叫停
2025-04-07 08:37
-
Euro-NCAP 2026 鞭打规程解读
2025-04-07 08:36
