




 广告
广告





















































车道感知多样化轨迹预测的分治策略
2021-05-26 23:33:01· 来源:同济智能汽车研究所

编者按:随着自动驾驶的快速发展,如何理解自动驾驶周围目标的行为成为自动驾驶系统中的重要一环。轨迹预测任务旨在根据目标(如行人、车辆等交通参与者)当前或者
编者按:随着自动驾驶的快速发展,如何理解自动驾驶周围目标的行为成为自动驾驶系统中的重要一环。轨迹预测任务旨在根据目标(如行人、车辆等交通参与者)当前或者历史轨迹与环境信息,对该目标未来的行驶轨迹进行预测。轨迹预测结果是自动驾驶系统进行提前决策的重要信息之一。而目前多使用赢家通吃(WTA)解决轨迹预测中的多模态特性和目标间的交互关系,而本文的DAC可以初始化WTA,避免伪模式。同时结合车道语义信息作为锚点,也能更好避免不合理轨迹的产生。
本文译自:
《Divide-and-Conquer for Lane-Aware Diverse Trajectory Prediction》
文章来源:
CVPR 21 (Oral)
作者:
Sriram Narayanan, Ramin Moslemi, Francesco Pittaluga, Buyu Liu, Manmohan Chandraker
原文链接:
https://arxiv.org/abs/2104.08277
摘要:轨迹预测是自动驾驶汽车在规划和执行环节中的关键一步。我们的工作解决了轨迹预测中的两个关键挑战:学习多模态输出,以及通过使用驾驶信息施加约束来实现更好的预测。最近的方法采用多个目标函数,如赢家通吃(WTA)或多项中的最佳,取得了很好的效果。但是,这些方法没有充分考虑假设的多样性,而目标函数高度依赖于它们对多样性的初始化。作为我们的第一个贡献,我们提出了一种新颖的分而治之(DAC)方法,对WTA目标函数进行更好初始化,得到没有任何伪模式的不同输出。我们的第二个贡献是一个新的轨迹预测框架,称为ALAN,它使用现有的车道中心线作为锚点,为输入车道提供轨迹约束。我们的框架通过超列描述子捕捉交互,并以栅格化图像和车道锚点的形式结合场景信息,提供多个轨迹输出。对合成数据和真实数据的实验表明,与其他WTA目标函数相比,DAC更好地捕捉了数据分布。此外,ALAN在Nuscenes城市驾驶基准数据集上,取得了与SOTA方法相当或更好的性能。
关键词:自动驾驶汽车,轨迹预测,WTA,分治策略,轨迹约束
1 引言
多模态行为的预测是自动驾驶汽车主动做出安全决策的关键。一个主要的挑战在于,不仅要预测最主要的模式,还要解释偶尔出现的不那么主要的模式。因此,模型不仅需要能够确定合理的输出空间,还需要对任意给定数量的样本进行预测。此外,绝大多车辆执行的是符合底层场景结构的常理可接受的策略。常理不可行的输出可能导致不安全的规划决策,而且其中一些决策比其他决策更危险[7]。例如,与遵循场景结构的方法相比,提供足够接近的预测而不遵循道路语义信息的方法更危险。
通常,生成模型被广泛用于捕捉与轨迹预测问题相关的不确定性[29,24,42,23,44]。然而,生成模型可能会遭遇模式崩溃问题,这降低了其在重视安全性的问题(如自动驾驶汽车)上的适用性。最近的方法[36,32]使用多个目标函数[30],如赢家通吃(WTA),但存在与网络初始化相关的不稳定性[34,39]。作为本文的第一个贡献,我们提出了一种分而治之(DAC)方法,该方法为WTA提供了更好的初始化。我们的方法解决了与伪模式相关的问题,伪模式指的是一些假设要么在训练过程中未经训练,要么不代表数据的任何部分。与WTA基线相比,我们所提出的DAC在具有多模态地面真值的真实场景和合成场景中都能更好地捕获数据分布结构[34,39]。
此外,轨迹预测方法通过栅格化图像[29,42,44,36,38,8]的形式,或者高清地图数据结构[32,17]的场景信息作为输入,融合驾驶信息。通常,这些信息被用作网络输入的特征,并且不能保证强语义耦合。本文的第二个贡献是ALAN,这是一种新的轨迹预测框架,使用车道中心线作为锚点来预测轨迹(图1)。ALAN的输出精确的预测,由FDE和OffRoadRate值可以证明良好的语义对齐,并通过定性可视化进行验证。
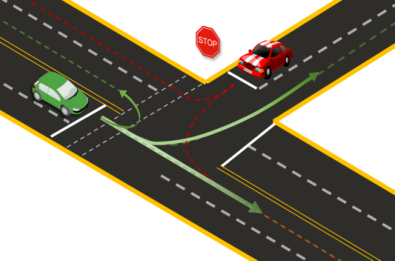
图1 交互场景下的轨迹预测问题,彩色虚线代表了交通参与者可能的车道锚点
具体来说,我们使用一个单一的表示模型[44]用于多交通参与者输入,并通过超列描述子[2]的新颖使用对交互进行编码,该描述子从多个尺度的特征中提取信息。此外,我们将预测问题转换为相对于输入通道的法向切向(nt) 坐标。考虑到我们使用车道中心线作为锚点,这种转换是至关重要的。此外,我们通过辅助的xy预测来规范锚点输出,使其不那么容易受到坏锚点的影响,并依赖于车辆动力学。最后,我们通过一个基于逆最优控制的排序模块[29]对我们的预测进行排序。
总而言之,本文的贡献如下:
· 一种新的分而治之的方法可以更好地初始化WTA目标函数,该方法可以捕获没有任何伪模式的数据分布。
· 一个新的基于锚点的轨迹预测框架 (ALAN),它使用现有的车道中心线作为锚点,以提供具有强语义耦合的环境感知输出。
· 在Nuscenes城市驾驶基准数据集上有较好的表现。
2 相关工作
多选择学习:过去通过多选择学习 (Multi-Choice Learning, MCL) [19,13,30]在不同领域实现了多模态预测。一些文献已经展示了MCL在分类[30,39]、分割[30,39]、字幕[30]、姿态估计[39]、图像合成[11]和轨迹建议[45]等方面的应用案例。与WTA目标函数相关的收敛问题已在[39,34]中得到证明。在此基础上,[39]提出了一种宽松的赢家通吃目标函数(RWTA)来解决收敛问题,但该方法本身存在假设错误捕获数据分布的问题。[34]提出了一种改进的赢家通吃(EWTA)损失函数,相较于[39]这种损失函数更好地获取了数据分布。尽管有了上述改进,但由于训练过程中存在的伪模式或未经训练的假设,这些方法仍不能准确捕捉数据分布。因此,我们提出了一种分而治之的方法,在训练过程中,通过在每个阶段捕获部分数据分布的假设集,以指数方式增加输出的有效数量。
预测方法:大量文献对未来轨迹预测进行了广泛的研究,包括经典的[47,31,27]和基于深度学习的方法[18,1,44]。确定性模型[1,33,41]预测场景中每个交通参与者最可能的轨迹,而忽略了轨迹预测问题中继承的不确定性。为了捕捉不确定性并创造不同的轨迹预测,提出了随机方法,通过抽样随机变量来编码未来轨迹的可能模式。非参数深度生成模型,如条件变分自动编码器 (CVAE) [29,3,24,22,44]和生成对抗网络(generative Adversarial Networks, GANs)[28,18,40]在该领域得到了广泛的应用。然而,由于潜在分布[48]的不平衡,这些方法不能捕获所有的潜在模式。最近的方法预测了同一输入环境下的固定的不同轨迹[36,32]。我们的方法使用类似的方法来预测一组M假设。
表征:高清地图栅格化在文献中被广泛应用于,利用神经网络对地图信息进行编码和处理[3,51,14,6,44]。一些方法[43,35]利用透视图像的语义和深度信息构造顶视图地图。有些方法[49,6]使用了栅格化高清地图和传感器信息的结合。最近的一些著作[32,17]通过将矢量化的地图数据表示为图数据结构来直接利用地图信息。我们的工作使用混合地图输入,结合栅格化地图和矢量化车道数据,作为空间网格[44]上每个交通参与者的输入。
轨迹预测:传统上,一些文献[44,32,17,36]将轨迹预测问题表述为笛卡尔坐标上的回归问题。[43]将其作为空间网格上未来位置的分类。Chang等人的[9]使用了与我们类似的法向切线坐标,但仅限于经典的最近邻和简单LSTM[21]方法。与我们的工作相关,一些方法通过将输出空间量化为几个预定义的不同锚点,然后将原始轨迹问题重新构造为顺序锚点分类(选择)和偏移回归子问题来解决多模态问题[50,38,8,49]。然而,锚点通常是预先聚类到一个固定的集合中,或者是根据运动学[50]实时计算。因此,创建锚点的过程可能会增加推理时间的计算复杂度,而且它可能高度依赖于场景,难以泛化。相比之下,我们的方法使用高清地图中心线信息作为锚点,这对于不同的场景是一致的,也易于在推理中获得。
3 分治策略
在本节中,我们详细描述了我们训练多假设预测网络的方法,而我们的方法是赢家通吃[30]目标函数的初始化步骤。设χ表示输入的向量空间,у表示输出变量的向量空间。设D={(xi, yi),…,(xN, yN)}是N个训练元组的集合,p(x, y) = p(y|x)p(x)是联合概率密度。我们的目标是学习一个函数fθ:χ—> уM,它将χ中的每个输入映射到一组M假设的集合。在数学上,我们定义:
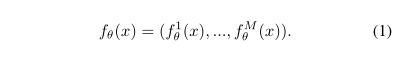
正如Rupprecht等人在[39]中所示,赢家通吃的目标函数通过尽可能接近M个假设使损失最小化:
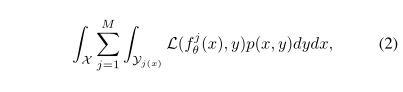
其中уj是标记空间的Voronoi剖分у=∪j=1Mуj。而目标函数将导致输出的质心Voronoi剖分[15],其中每个假设最小化到由它包围的Voronoi标记空间уj的概率质量质心。在实践中,为了获得不同的假设,WTA目标函数可以写成一种元损失[34, 39, 30, 19],
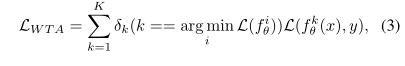
其中δ(·)是当条件为真时值为1,否则为0的Kronecker δ函数,。
WTA的初始化困难 正如Makansi等人在[34]中提到的,方程3可以类比为EM算法和K-means聚类,它们主要依赖于初始化来获得最优收敛。如2b所示,这使得训练过程非常脆弱,因为只有少数几个假设的Voronoi区域包含了数据分布,由于赢家通吃的目标函数,使得大多数假设未被训练。Ruppercht等人在[39]提出的通过给非赢家分配权重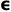 来解决收敛问题的备选方案并不奏效,因为每个地面真值最多只与一个假设相关联,使得其他非赢家达到2c所示的均衡。
来解决收敛问题的备选方案并不奏效,因为每个地面真值最多只与一个假设相关联,使得其他非赢家达到2c所示的均衡。
Ruppercht等人在[39]中提出的通过分配策略,对非赢家的权重并不起作用,因为每个基础真理最多只与一个假设相关联,使其他非赢家达到2c所示的均衡。Makansi 等人在[34]中提出了改进赢家通吃(EWTA) 的目标函数,其中他们将前k名视作赢家。k从k=M到k=1不等,导致赢家在训练过程中获得全部目标。与RWTA和WTA相比,这种方法可以更好地捕捉数据分布,但仍然产生了模态不正确的假设,如图2d所示。
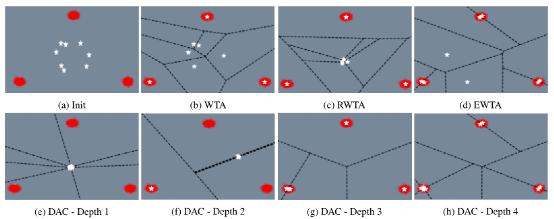
图2 比较不同版本的赢家通吃和封闭的预测假设的Voronoi区域的玩具示例。玩具数据用红色表示,假设用白色表示。当DAC的Depth=1时,它包含一个单一的假设集,其中有M个假设,因此所有的假设都被抑制以匹配数据并达到平衡。随着深度的增加,当每个集合被分解成两半(e —> f —> g —> h) 时,列表中集合的数量呈指数增长。由于我们对一个集合中的所有假设都使用相同的地面真值,他们达到相同的平衡位置,形成质心Voronoi剖分,使得输出的数量等于列表中集合的数量(e —> 1,f —> 2,g —> 4,h —> 8)。在最后阶段(h),每个集合包含一个类似WTA目标函数的假设。与DAC相比,其他WTA目标函数对数据分布的建模不正确,因为一些Voronoi区域没有捕获数据的任何部分,导致了伪模式。
DAC用于不同的非伪模式 我们提出了一种新的初始化技术,称为分治(Divide and Conquer),它缓解了伪模式的问题,让每个输出假设的Voronoi区域捕获数据的一部分,如图2h所示。我们将M个假设划分为k个集合,用最小输出更新集合以匹配地面真值。k的值从1开始,随着训练的进行,每个集合被分解成两部分,k的值呈指数级增长。这创建了一个二叉树,树的深度依赖于输出假设M的数量。算法1显示了所提出的分治的伪代码。这里深度指的是当前训练阶段可以达到的最大深度,列表定义为在训练的任何阶段包含假设集的变量。此外,我们将kth中新形成的集合定义为setk1和setk2。列表中产生最小输出的集合表示为mSet。最后我们取mSet中所有假设的平均损失来得到LDAC。

如图2e所示,当k=1时,列表中只包含一个集合,所有的M个假设都趋于平衡。随着列表中集合的数量从2e增加到2f,假设根据Voronoi区域划分分布空间,以捕获数据的不同部分。输出的有效数量在每个阶段都在增长,前一阶段的kth集合捕获的数据在下一阶段被拆分为两个新形成的集。最后,当我们到达叶节点时,每个集合包含一个假设,导致类似于等式3的赢家通吃的目标函数。
DAC从拟合整个数据的所有假设开始,在每一阶段,DAC确保将一些数据封装在Voronoi空间中。在分裂过程中,假设对包含在Voronoi空间中的数据进行分割,以达到新的平衡。虽然DAC不能保证相同数量的假设,可以捕获数据的不同模式,但它保证了收敛。此外,值得一提的是,DAC没有任何显著的计算复杂性,因为只涉及到划分为集合和最小计算。在第5节中,我们展示了DAC在更好地捕获多模态分布方面的优势,与其他WTA目标函数相比,DAC可以产生不同的假设集。
4 基于车道锚点的轨迹预测
在本节中,我们将介绍一种称为ALAN的单一表示模型,它在向前传递中为多个交通参与者生成车道感知轨迹。我们将问题表述为跨越时间的不同假设的单例回归。接下来将详细描述我们的方法。
4.1 问题陈述
我们的方法采用两种形式的场景信息输入:a) 场景的栅格化鸟瞰(BEV)表示,记为尺寸为H × W × 3的I,b) 每个交通参与者的车道中心线信息作为锚点。我们定义车道锚点L={L1,…,Lp}作为包含p个点的序列,在BEV参考系中坐标为Lp =(x, y)。我们将Xi = {Xi1,…,XiT}表示为包含每个交通参与点的过去和未来观测结果的笛卡尔形式的轨迹坐标,其中Xit = (xit,yit)。对于每个交通参与者i,我们根据轨迹信息,如最近距离、偏航对齐和其他参数,确定车辆可能采取的一组候选车道。我们将其表示为一组可信的车道中心线A = { L1,…,Lk},其中k表示车辆可能沿着其行驶的车道中心线的总数。然后我们在二维曲线法向—切向坐标系(nt)中沿这些中心线定义车辆轨迹Xi。将Ni, k = {Ni, k1,…,Ni, kT}表示为交通参与者i沿车道中心线Lk的nt坐标,其中Ni, kt = (ni, kt,li, kt)表示到车道最近点的法向和纵向距离。nt坐标的使用对于捕获复杂的道路拓扑和相关的动态是至关重要的,坐标用以提供语义一致的预测,这已经在我们的实验中得到了研究(第5节)。
然后,我们将轨迹预测问题定义为对给定的车道锚点Lk作为网络输入,进行ntYi, k = { Ni, ktobs,…,Ni, kT }预测的任务。我们遵循一个类似于[44]的输入表示,其中我们在空间网格上的Xi,tobs 位置对交通参与者的信息进行编码。最后,为了得到BEV参考系中的轨迹,我们将输出预测转换为基于网络输入锚点Li, k的笛卡尔坐标。
4.2 用于轨迹预测的ALAN框架
框架的概述如图3所示。我们的方法包括五个主要部分:a) 中心线编码器b) 过去的轨迹编码器c) 多交通参与者卷积交互编码器d) 超列[2]轨迹解码器和e) 基于逆最优控制(IOC) 的排序模块[29]。
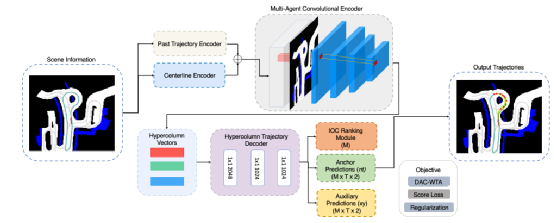
图3:ALAN方法的概述。该方法以过去的轨迹、车道锚点和BEV映射作为输入,一次性对所有交通参与者进行多假设预测。
中心线编码器:对每个交通参与者的输入车道信息Li, k进行编码,通过一系列1D卷积,为场景中的每个交通参与者生成一个嵌入向量Ci, k = Cenc(Li, k)。
过去的轨迹编码器:除了用于车道锚点的nt坐标Ni, k外,我们还为过去轨迹的编码器提供了额外的Xi输入。我们首先通过MLP嵌入时间输入,然后通过LSTM[21]网络提供过去状态向量hitobs。在形式上,
多交通参与者卷积编码器:我们通过卷积编码器模块[44],在前向传播中实现了多交通参与者的轨迹预测。首先,在BEV空间网格中,将交通参与者的特定信息Ci,k,hitobs编码到它们各自的位置Xitobs。这将生成一个场景状态映射S,大小为H ×W ×128,包含场景中每个交通参与者的信息。然后,我们将其与栅格化的BEV映射I一起,通过卷积编码器产生不同特征尺度上的激活。为了计算每个交通参与者的特征向量,我们采用Bansal等人在[2]中的技术,从它们的位置提取超列描述子Di。超列描述子包含通过对不同特征维度的Xitobs进行双线性插值在不同尺度上提取的特征。因此,
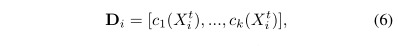
其中ck是通过双线性插值,从输入位置到给定维数在kth层提取的特征。简单来说,在不同的尺度上捕获交互信息,深层的卷积层捕获全局环境信息,而低层特征保留交通参与者周边的交互信息。在第5节中,我们证明了在轨迹预测任务中使用超列描述子,比仅使用全局环境向量更有益。
超列轨迹解码器:每个交通参与者的超列描述子Di,通过包含一系列1x1卷积的解码器,一次性输出M个假设。在这里,我们研究了两种不同的ALAN预测。ALAN-nt:我们预测在车道方向上的 nt 坐标系下轨迹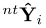 ;ALAN-ntxy:提供一个辅助预测xy方向预测的
;ALAN-ntxy:提供一个辅助预测xy方向预测的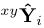 。nt中的线性值可以对应基于输入锚点的高阶轨迹。此外,具有相同nt值的两条轨迹可能具有完全不同的动力学。因此,我们利用辅助预测来正则化基于锚点的输出,使网络意识到交通参与者的动力学,并减少对坏锚点的影响。网络预测的M个假设为:
。nt中的线性值可以对应基于输入锚点的高阶轨迹。此外,具有相同nt值的两条轨迹可能具有完全不同的动力学。因此,我们利用辅助预测来正则化基于锚点的输出,使网络意识到交通参与者的动力学,并减少对坏锚点的影响。网络预测的M个假设为:

排序模块:我们使用Lee等人在[29]中的技术生成分数sYi={sYi, 1,sYi, 2,…,sYi, M}表示M个输出假设。它通过最大化目标朝向[46]来衡量预测假设的好坏程度。该模块使用预测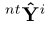 得到目标分布q,其中q = softmax(-d(ntYi, )),d为d为地面真值与预测输出之间的L2距离。因此,损失函数定义为Lscore = Cross-Entropy(sYi, q)。
得到目标分布q,其中q = softmax(-d(ntYi, )),d为d为地面真值与预测输出之间的L2距离。因此,损失函数定义为Lscore = Cross-Entropy(sYi, q)。
4.3 学习
我们用它们各自的地面真值标签ntY作为输入车道锚点的L2距离监督网络输出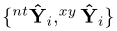 。我们使用提出的分治技术来训练我们的多假设预测网络。因此,主预测和辅助预测的重构损失函数分别为:
。我们使用提出的分治技术来训练我们的多假设预测网络。因此,主预测和辅助预测的重构损失函数分别为:
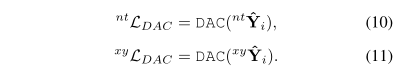
此外,我们通过将预测转换为输入车道上的nt坐标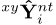 来训练基于锚点的预测。我们还添加了正则化的其他方法,通过将nt坐标转化为xy坐标
来训练基于锚点的预测。我们还添加了正则化的其他方法,通过将nt坐标转化为xy坐标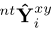 ,来抑制基于锚点输出
,来抑制基于锚点输出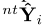 的
的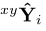 预测。我们将所有假设转换后的主要预测和辅助预测之间的L2距离作为正则化:
预测。我们将所有假设转换后的主要预测和辅助预测之间的L2距离作为正则化:
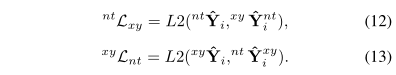
使网络的总目标函数最小化:

5 实验
我们首先在合成汽车行人数据集[34]上,评估了我们提出的分治技术。此外,我们在Nuscenes[5]预测数据集上,对DAC和提出的基于锚点的预测技术进行了评估。
5.1 汽车行人数据集
与现实世界中只观察到单一结果的设置不同,CPI数据集由具有多模态地面真值的交互交通参与者组成。我们的目的是评估我们的多假设预测对测试集中样本的真实分布的捕获效果。我们使用与[34]中类似的训练策略,即ResNet-18[20]编码主干,在此基础上我们训练两阶段混合密度网络[4]。第一阶段将过去对汽车和行人的观察作为输入,预测∆t时间后包含两个参与者的未来目标的k个输出假设。我们使用不同的赢家通吃的损失函数来训练第一阶段。第二阶段通过预测输出的软分类来拟合假设上的M个模态的混合分布。关于计算混合分布参数的更多细节,请参考[34]中的公式7、8和9。我们使用[34]中的oracle偏差(FDE)和推土距离 (EMD)等评估指标。
Oracle偏差 (FDE)通过选择与地面真值最接近的假设来衡量输出预测的多样性。
推土距离量化为使预测分布匹配真实分布必须移除的概率质量的数量。
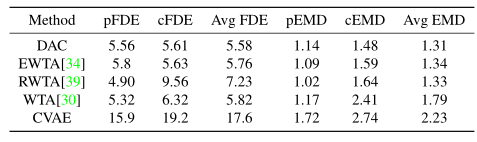
从表1可以推断,我们提出的DAC方法优于WTA目标函数的其他变体,这表明DAC比EWTA、RWTA和WTA更好地捕捉数据分布。这也可以在图4中看到,与其他变体相比,DAC目标函数训练的网络更好地捕获了参与者的地面真值分布。DAC的平均EMD明显优于WTA,与EWTA和RWTA目标函数相当。与行人目标相比,DAC能更好地捕捉到车辆目标。此外,如表1所示,DAC方法的平均oracle 偏差(FDE)明显低于其他变体,这证实了DAC产生了与WTA不同的假设。

图4:图中展示了CPI测试集上使用不同WTA目标函数的预测假设和学习到的目标混合分布。紫色和黑色的方形代表汽车和行人的当前位置。预测的假设用它们各自的颜色表示。(e) 类似于地面真实分布的假设沿着人行横道上展开,更好地捕获数据分布。
表1:基于FDE和EMD指标的CPI数据集方法比较,其中p代表行人和c代表车辆
5.2 Nuscenes数据集
Nuscenes[5]包含了波士顿和新加坡的大量城市复杂道路场景,大约包含4万个实例,且包括挑战性的序列,比如u型转弯和复杂的道路布局。
5.2.1 基线
我们将ALAN预测结果与在Nuscenes基准数据集上评估的几种基线方法进行了比较。MTP[12]使用栅格化图像作为输入来预测轨迹。CoverNet[38]使用固定的轨迹集,将轨迹预测问题转为对轨迹集的分类。Multipath[8]是最接近的基线,它使用从训练集获得的时间参数化锚点轨迹,并将问题表述为相对于锚点的偏移值的回归。MHA JAM[36]是一种使用联合交通参与者-映射的表示,它输出具有多头注意力。Trajectron++[42]是结合交通参与者动力学和语义的预测轨迹的图循环模型。我们利用[36]中的[12]和[8]的数据。
5.2.2 指标
我们使用标准的评估指标,如平均位移误差(mADEM)和最终位移误差(mFDEM)。此外,我们计算前M个轨迹相较于地面真值的遗漏率(Missd, M)。如果在所有预测中不存在最大位移点小于阈值d的假设,则认为一组预测都是错误的。OffRoadRate计算可行驶区域以外的输出轨迹百分比。我们使用由Nuscenes提供的示例API来计算这些指标。
5.2.3 量化结果
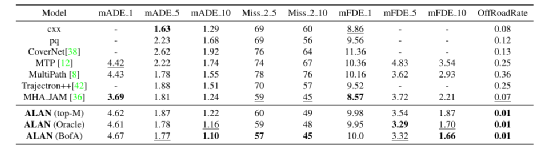
首先,与基线方法相比,ALAN可以达到同等或更好的性能。在这里,我们用不同的锚点抽样策略 (top-M、oracle和best-of-all (BofA)) 来评估ALAN。在ALAN (top-M)中,我们根据预测的每个轨迹的IOC分数,从不同的锚点上选取前M个轨迹输出。ALAN (oracle)使用车道中心线得分最高的oracle锚点,同时ALAN (BofA)从前k个假设的车道锚点中选择最佳。表2的结果表明,ALAN评估要么表现出与其他基准相当的性能,要么在几个指标上显著优于其他基准,如mADE10方面至少有11%的改进,mFDE10方面相较于BofA提高了25%。此外,所有的ALAN预测的OffRoadRate为0.01,即只有1%的预测轨迹落在道路之外。这明显低于其他有7%或更高的OffRoadRate的基线表现。输出预测与语义的强耦合可以归因于车道锚点,它有助于在车道方向上提供输出预测。其他方法,如[8,38],使用从训练集提取的轨迹作为锚点或进行分类,这可能导致输出对未出现场景和具有复杂车道结构的轨迹的泛化能力较差。此外,值得注意的是,ALAN性能被低估了,因为数据中没有连接的车道和没有车道中心线的地方会导致坏锚点。但为了便于与基线比较,在此没有删除这些情况。
表2:轨迹预测基准
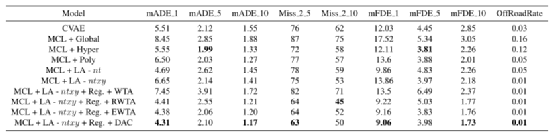
消融研究:此外,我们还对ALAN以及DAC和其他变体进行了消融研究,如表3所示。我们首先引入超列描述子[2]来提取多尺度特征,并将其与作为输入进入解码器的全局环境向量进行比较。然后我们研究了ALAN预测的几个变体。首先,我们添加了参考中心线作为输入,并预测xy坐标空间(MCL + Poly)的轨迹。这大大提高了性能。使用车道中心线作为锚点并预测nt空间的轨迹(MCL+LA-nt)表现稍差,但我们认为这是由于网络难以从基于锚点的输入计算交通参与者的动力学特征。例如,具有相同nt坐标的两个轨迹可以根据它们所行驶的车道具有不同的动力学。因此,我们进一步增加xy坐标作为输入,并在笛卡尔空间(MCL+LA-ntxy) 预测辅助轨迹。如表3所示,这样的辅助预测改进了基于主要锚点的输出。
此外,我们使用辅助预测正则化锚点输出,反之亦然。通常意义上,锚点输出可以从辅助预测中受益,因为辅助预测并不局限于只提供沿车道方向的轨迹。添加一个正则化步骤来匹配主轨迹和辅助轨迹,显著提高了锚定输出性能,如表3中MCL+LA-ntxy+Reg值所示。
表3:Nuscenes数据集上的消融研究
5.2.4 量化结果
图5显示了来自ALAN的定性结果。一般来说,使用车道作为锚点,将预测问题转化到nt空间有助于指导预测和跟踪语义。当我们预测较长时间的轨迹时,所执行的轨迹会变得复杂,而不仅仅是一个直行或转弯动作,而使用车道作为锚点可以简化问题。
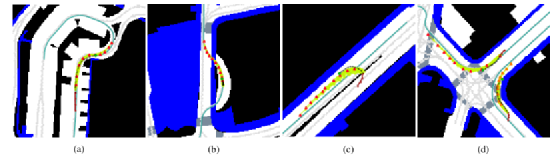
图5:来自ALAN的预测示例。过去的轨迹用棕色表示,地面真值(GT)用黑色表示。GT的端点用绿点表示。输入车道锚点用青色表示,预测轨迹用绿色表示,终点用三角形表示。(a)和(b)显示了一个复杂的车道结构的预测。基于锚点的预测效果更好,特别是预测较长时间轨迹。由于轨迹的复杂性,锚点的存在有助于遵循语义信息。(c) 当目标车道在相反方向时,适当结合动力学信息预测u型转弯;(d) 多交通参与者的预测场景。
6 结论
在本文中,我们讨论了使用WTA目标函数学习多模态输出和使用驾驶知识对输出预测施加约束的相关问题。首先,我们引入了一种新的DAC方法,该方法可以学习不同的假设,从而在不存在任何伪模式的情况下捕获数据分布。此外,我们还介绍了ALAN,它使用车道作为锚点提供了不同的环境感知轨迹。我们在合成数据和真实数据上的实验都证明了,本文的DAC方法在学习多模态输出方面的优越性。此外,我们还证明了使用车道锚点有助于提供具有强语义耦合的准确预测。
参考文献




本文译自:
《Divide-and-Conquer for Lane-Aware Diverse Trajectory Prediction》
文章来源:
CVPR 21 (Oral)
作者:
Sriram Narayanan, Ramin Moslemi, Francesco Pittaluga, Buyu Liu, Manmohan Chandraker
原文链接:
https://arxiv.org/abs/2104.08277
摘要:轨迹预测是自动驾驶汽车在规划和执行环节中的关键一步。我们的工作解决了轨迹预测中的两个关键挑战:学习多模态输出,以及通过使用驾驶信息施加约束来实现更好的预测。最近的方法采用多个目标函数,如赢家通吃(WTA)或多项中的最佳,取得了很好的效果。但是,这些方法没有充分考虑假设的多样性,而目标函数高度依赖于它们对多样性的初始化。作为我们的第一个贡献,我们提出了一种新颖的分而治之(DAC)方法,对WTA目标函数进行更好初始化,得到没有任何伪模式的不同输出。我们的第二个贡献是一个新的轨迹预测框架,称为ALAN,它使用现有的车道中心线作为锚点,为输入车道提供轨迹约束。我们的框架通过超列描述子捕捉交互,并以栅格化图像和车道锚点的形式结合场景信息,提供多个轨迹输出。对合成数据和真实数据的实验表明,与其他WTA目标函数相比,DAC更好地捕捉了数据分布。此外,ALAN在Nuscenes城市驾驶基准数据集上,取得了与SOTA方法相当或更好的性能。
关键词:自动驾驶汽车,轨迹预测,WTA,分治策略,轨迹约束
1 引言
多模态行为的预测是自动驾驶汽车主动做出安全决策的关键。一个主要的挑战在于,不仅要预测最主要的模式,还要解释偶尔出现的不那么主要的模式。因此,模型不仅需要能够确定合理的输出空间,还需要对任意给定数量的样本进行预测。此外,绝大多车辆执行的是符合底层场景结构的常理可接受的策略。常理不可行的输出可能导致不安全的规划决策,而且其中一些决策比其他决策更危险[7]。例如,与遵循场景结构的方法相比,提供足够接近的预测而不遵循道路语义信息的方法更危险。
通常,生成模型被广泛用于捕捉与轨迹预测问题相关的不确定性[29,24,42,23,44]。然而,生成模型可能会遭遇模式崩溃问题,这降低了其在重视安全性的问题(如自动驾驶汽车)上的适用性。最近的方法[36,32]使用多个目标函数[30],如赢家通吃(WTA),但存在与网络初始化相关的不稳定性[34,39]。作为本文的第一个贡献,我们提出了一种分而治之(DAC)方法,该方法为WTA提供了更好的初始化。我们的方法解决了与伪模式相关的问题,伪模式指的是一些假设要么在训练过程中未经训练,要么不代表数据的任何部分。与WTA基线相比,我们所提出的DAC在具有多模态地面真值的真实场景和合成场景中都能更好地捕获数据分布结构[34,39]。
此外,轨迹预测方法通过栅格化图像[29,42,44,36,38,8]的形式,或者高清地图数据结构[32,17]的场景信息作为输入,融合驾驶信息。通常,这些信息被用作网络输入的特征,并且不能保证强语义耦合。本文的第二个贡献是ALAN,这是一种新的轨迹预测框架,使用车道中心线作为锚点来预测轨迹(图1)。ALAN的输出精确的预测,由FDE和OffRoadRate值可以证明良好的语义对齐,并通过定性可视化进行验证。
图1 交互场景下的轨迹预测问题,彩色虚线代表了交通参与者可能的车道锚点
具体来说,我们使用一个单一的表示模型[44]用于多交通参与者输入,并通过超列描述子[2]的新颖使用对交互进行编码,该描述子从多个尺度的特征中提取信息。此外,我们将预测问题转换为相对于输入通道的法向切向(nt) 坐标。考虑到我们使用车道中心线作为锚点,这种转换是至关重要的。此外,我们通过辅助的xy预测来规范锚点输出,使其不那么容易受到坏锚点的影响,并依赖于车辆动力学。最后,我们通过一个基于逆最优控制的排序模块[29]对我们的预测进行排序。
总而言之,本文的贡献如下:
· 一种新的分而治之的方法可以更好地初始化WTA目标函数,该方法可以捕获没有任何伪模式的数据分布。
· 一个新的基于锚点的轨迹预测框架 (ALAN),它使用现有的车道中心线作为锚点,以提供具有强语义耦合的环境感知输出。
· 在Nuscenes城市驾驶基准数据集上有较好的表现。
2 相关工作
多选择学习:过去通过多选择学习 (Multi-Choice Learning, MCL) [19,13,30]在不同领域实现了多模态预测。一些文献已经展示了MCL在分类[30,39]、分割[30,39]、字幕[30]、姿态估计[39]、图像合成[11]和轨迹建议[45]等方面的应用案例。与WTA目标函数相关的收敛问题已在[39,34]中得到证明。在此基础上,[39]提出了一种宽松的赢家通吃目标函数(RWTA)来解决收敛问题,但该方法本身存在假设错误捕获数据分布的问题。[34]提出了一种改进的赢家通吃(EWTA)损失函数,相较于[39]这种损失函数更好地获取了数据分布。尽管有了上述改进,但由于训练过程中存在的伪模式或未经训练的假设,这些方法仍不能准确捕捉数据分布。因此,我们提出了一种分而治之的方法,在训练过程中,通过在每个阶段捕获部分数据分布的假设集,以指数方式增加输出的有效数量。
预测方法:大量文献对未来轨迹预测进行了广泛的研究,包括经典的[47,31,27]和基于深度学习的方法[18,1,44]。确定性模型[1,33,41]预测场景中每个交通参与者最可能的轨迹,而忽略了轨迹预测问题中继承的不确定性。为了捕捉不确定性并创造不同的轨迹预测,提出了随机方法,通过抽样随机变量来编码未来轨迹的可能模式。非参数深度生成模型,如条件变分自动编码器 (CVAE) [29,3,24,22,44]和生成对抗网络(generative Adversarial Networks, GANs)[28,18,40]在该领域得到了广泛的应用。然而,由于潜在分布[48]的不平衡,这些方法不能捕获所有的潜在模式。最近的方法预测了同一输入环境下的固定的不同轨迹[36,32]。我们的方法使用类似的方法来预测一组M假设。
表征:高清地图栅格化在文献中被广泛应用于,利用神经网络对地图信息进行编码和处理[3,51,14,6,44]。一些方法[43,35]利用透视图像的语义和深度信息构造顶视图地图。有些方法[49,6]使用了栅格化高清地图和传感器信息的结合。最近的一些著作[32,17]通过将矢量化的地图数据表示为图数据结构来直接利用地图信息。我们的工作使用混合地图输入,结合栅格化地图和矢量化车道数据,作为空间网格[44]上每个交通参与者的输入。
轨迹预测:传统上,一些文献[44,32,17,36]将轨迹预测问题表述为笛卡尔坐标上的回归问题。[43]将其作为空间网格上未来位置的分类。Chang等人的[9]使用了与我们类似的法向切线坐标,但仅限于经典的最近邻和简单LSTM[21]方法。与我们的工作相关,一些方法通过将输出空间量化为几个预定义的不同锚点,然后将原始轨迹问题重新构造为顺序锚点分类(选择)和偏移回归子问题来解决多模态问题[50,38,8,49]。然而,锚点通常是预先聚类到一个固定的集合中,或者是根据运动学[50]实时计算。因此,创建锚点的过程可能会增加推理时间的计算复杂度,而且它可能高度依赖于场景,难以泛化。相比之下,我们的方法使用高清地图中心线信息作为锚点,这对于不同的场景是一致的,也易于在推理中获得。
3 分治策略
在本节中,我们详细描述了我们训练多假设预测网络的方法,而我们的方法是赢家通吃[30]目标函数的初始化步骤。设χ表示输入的向量空间,у表示输出变量的向量空间。设D={(xi, yi),…,(xN, yN)}是N个训练元组的集合,p(x, y) = p(y|x)p(x)是联合概率密度。我们的目标是学习一个函数fθ:χ—> уM,它将χ中的每个输入映射到一组M假设的集合。在数学上,我们定义:
正如Rupprecht等人在[39]中所示,赢家通吃的目标函数通过尽可能接近M个假设使损失最小化:
其中уj是标记空间的Voronoi剖分у=∪j=1Mуj。而目标函数将导致输出的质心Voronoi剖分[15],其中每个假设最小化到由它包围的Voronoi标记空间уj的概率质量质心。在实践中,为了获得不同的假设,WTA目标函数可以写成一种元损失[34, 39, 30, 19],
其中δ(·)是当条件为真时值为1,否则为0的Kronecker δ函数,。
WTA的初始化困难 正如Makansi等人在[34]中提到的,方程3可以类比为EM算法和K-means聚类,它们主要依赖于初始化来获得最优收敛。如2b所示,这使得训练过程非常脆弱,因为只有少数几个假设的Voronoi区域包含了数据分布,由于赢家通吃的目标函数,使得大多数假设未被训练。Ruppercht等人在[39]提出的通过给非赢家分配权重
Ruppercht等人在[39]中提出的通过分配策略,对非赢家的权重并不起作用,因为每个基础真理最多只与一个假设相关联,使其他非赢家达到2c所示的均衡。Makansi 等人在[34]中提出了改进赢家通吃(EWTA) 的目标函数,其中他们将前k名视作赢家。k从k=M到k=1不等,导致赢家在训练过程中获得全部目标。与RWTA和WTA相比,这种方法可以更好地捕捉数据分布,但仍然产生了模态不正确的假设,如图2d所示。
图2 比较不同版本的赢家通吃和封闭的预测假设的Voronoi区域的玩具示例。玩具数据用红色表示,假设用白色表示。当DAC的Depth=1时,它包含一个单一的假设集,其中有M个假设,因此所有的假设都被抑制以匹配数据并达到平衡。随着深度的增加,当每个集合被分解成两半(e —> f —> g —> h) 时,列表中集合的数量呈指数增长。由于我们对一个集合中的所有假设都使用相同的地面真值,他们达到相同的平衡位置,形成质心Voronoi剖分,使得输出的数量等于列表中集合的数量(e —> 1,f —> 2,g —> 4,h —> 8)。在最后阶段(h),每个集合包含一个类似WTA目标函数的假设。与DAC相比,其他WTA目标函数对数据分布的建模不正确,因为一些Voronoi区域没有捕获数据的任何部分,导致了伪模式。
DAC用于不同的非伪模式 我们提出了一种新的初始化技术,称为分治(Divide and Conquer),它缓解了伪模式的问题,让每个输出假设的Voronoi区域捕获数据的一部分,如图2h所示。我们将M个假设划分为k个集合,用最小输出更新集合以匹配地面真值。k的值从1开始,随着训练的进行,每个集合被分解成两部分,k的值呈指数级增长。这创建了一个二叉树,树的深度依赖于输出假设M的数量。算法1显示了所提出的分治的伪代码。这里深度指的是当前训练阶段可以达到的最大深度,列表定义为在训练的任何阶段包含假设集的变量。此外,我们将kth中新形成的集合定义为setk1和setk2。列表中产生最小输出的集合表示为mSet。最后我们取mSet中所有假设的平均损失来得到LDAC。
如图2e所示,当k=1时,列表中只包含一个集合,所有的M个假设都趋于平衡。随着列表中集合的数量从2e增加到2f,假设根据Voronoi区域划分分布空间,以捕获数据的不同部分。输出的有效数量在每个阶段都在增长,前一阶段的kth集合捕获的数据在下一阶段被拆分为两个新形成的集。最后,当我们到达叶节点时,每个集合包含一个假设,导致类似于等式3的赢家通吃的目标函数。
DAC从拟合整个数据的所有假设开始,在每一阶段,DAC确保将一些数据封装在Voronoi空间中。在分裂过程中,假设对包含在Voronoi空间中的数据进行分割,以达到新的平衡。虽然DAC不能保证相同数量的假设,可以捕获数据的不同模式,但它保证了收敛。此外,值得一提的是,DAC没有任何显著的计算复杂性,因为只涉及到划分为集合和最小计算。在第5节中,我们展示了DAC在更好地捕获多模态分布方面的优势,与其他WTA目标函数相比,DAC可以产生不同的假设集。
4 基于车道锚点的轨迹预测
在本节中,我们将介绍一种称为ALAN的单一表示模型,它在向前传递中为多个交通参与者生成车道感知轨迹。我们将问题表述为跨越时间的不同假设的单例回归。接下来将详细描述我们的方法。
4.1 问题陈述
我们的方法采用两种形式的场景信息输入:a) 场景的栅格化鸟瞰(BEV)表示,记为尺寸为H × W × 3的I,b) 每个交通参与者的车道中心线信息作为锚点。我们定义车道锚点L={L1,…,Lp}作为包含p个点的序列,在BEV参考系中坐标为Lp =(x, y)。我们将Xi = {Xi1,…,XiT}表示为包含每个交通参与点的过去和未来观测结果的笛卡尔形式的轨迹坐标,其中Xit = (xit,yit)。对于每个交通参与者i,我们根据轨迹信息,如最近距离、偏航对齐和其他参数,确定车辆可能采取的一组候选车道。我们将其表示为一组可信的车道中心线A = { L1,…,Lk},其中k表示车辆可能沿着其行驶的车道中心线的总数。然后我们在二维曲线法向—切向坐标系(nt)中沿这些中心线定义车辆轨迹Xi。将Ni, k = {Ni, k1,…,Ni, kT}表示为交通参与者i沿车道中心线Lk的nt坐标,其中Ni, kt = (ni, kt,li, kt)表示到车道最近点的法向和纵向距离。nt坐标的使用对于捕获复杂的道路拓扑和相关的动态是至关重要的,坐标用以提供语义一致的预测,这已经在我们的实验中得到了研究(第5节)。
然后,我们将轨迹预测问题定义为对给定的车道锚点Lk作为网络输入,进行ntYi, k = { Ni, ktobs,…,Ni, kT }预测的任务。我们遵循一个类似于[44]的输入表示,其中我们在空间网格上的Xi,tobs 位置对交通参与者的信息进行编码。最后,为了得到BEV参考系中的轨迹,我们将输出预测转换为基于网络输入锚点Li, k的笛卡尔坐标。
4.2 用于轨迹预测的ALAN框架
框架的概述如图3所示。我们的方法包括五个主要部分:a) 中心线编码器b) 过去的轨迹编码器c) 多交通参与者卷积交互编码器d) 超列[2]轨迹解码器和e) 基于逆最优控制(IOC) 的排序模块[29]。
图3:ALAN方法的概述。该方法以过去的轨迹、车道锚点和BEV映射作为输入,一次性对所有交通参与者进行多假设预测。
中心线编码器:对每个交通参与者的输入车道信息Li, k进行编码,通过一系列1D卷积,为场景中的每个交通参与者生成一个嵌入向量Ci, k = Cenc(Li, k)。
过去的轨迹编码器:除了用于车道锚点的nt坐标Ni, k外,我们还为过去轨迹的编码器提供了额外的Xi输入。我们首先通过MLP嵌入时间输入,然后通过LSTM[21]网络提供过去状态向量hitobs。在形式上,
多交通参与者卷积编码器:我们通过卷积编码器模块[44],在前向传播中实现了多交通参与者的轨迹预测。首先,在BEV空间网格中,将交通参与者的特定信息Ci,k,hitobs编码到它们各自的位置Xitobs。这将生成一个场景状态映射S,大小为H ×W ×128,包含场景中每个交通参与者的信息。然后,我们将其与栅格化的BEV映射I一起,通过卷积编码器产生不同特征尺度上的激活。为了计算每个交通参与者的特征向量,我们采用Bansal等人在[2]中的技术,从它们的位置提取超列描述子Di。超列描述子包含通过对不同特征维度的Xitobs进行双线性插值在不同尺度上提取的特征。因此,
其中ck是通过双线性插值,从输入位置到给定维数在kth层提取的特征。简单来说,在不同的尺度上捕获交互信息,深层的卷积层捕获全局环境信息,而低层特征保留交通参与者周边的交互信息。在第5节中,我们证明了在轨迹预测任务中使用超列描述子,比仅使用全局环境向量更有益。
超列轨迹解码器:每个交通参与者的超列描述子Di,通过包含一系列1x1卷积的解码器,一次性输出M个假设。在这里,我们研究了两种不同的ALAN预测。ALAN-nt:我们预测在车道方向上的 nt 坐标系下轨迹
排序模块:我们使用Lee等人在[29]中的技术生成分数sYi={sYi, 1,sYi, 2,…,sYi, M}表示M个输出假设。它通过最大化目标朝向[46]来衡量预测假设的好坏程度。该模块使用预测
4.3 学习
我们用它们各自的地面真值标签ntY作为输入车道锚点的L2距离监督网络输出
此外,我们通过将预测转换为输入车道上的nt坐标
使网络的总目标函数最小化:
5 实验
我们首先在合成汽车行人数据集[34]上,评估了我们提出的分治技术。此外,我们在Nuscenes[5]预测数据集上,对DAC和提出的基于锚点的预测技术进行了评估。
5.1 汽车行人数据集
与现实世界中只观察到单一结果的设置不同,CPI数据集由具有多模态地面真值的交互交通参与者组成。我们的目的是评估我们的多假设预测对测试集中样本的真实分布的捕获效果。我们使用与[34]中类似的训练策略,即ResNet-18[20]编码主干,在此基础上我们训练两阶段混合密度网络[4]。第一阶段将过去对汽车和行人的观察作为输入,预测∆t时间后包含两个参与者的未来目标的k个输出假设。我们使用不同的赢家通吃的损失函数来训练第一阶段。第二阶段通过预测输出的软分类来拟合假设上的M个模态的混合分布。关于计算混合分布参数的更多细节,请参考[34]中的公式7、8和9。我们使用[34]中的oracle偏差(FDE)和推土距离 (EMD)等评估指标。
Oracle偏差 (FDE)通过选择与地面真值最接近的假设来衡量输出预测的多样性。
推土距离量化为使预测分布匹配真实分布必须移除的概率质量的数量。
从表1可以推断,我们提出的DAC方法优于WTA目标函数的其他变体,这表明DAC比EWTA、RWTA和WTA更好地捕捉数据分布。这也可以在图4中看到,与其他变体相比,DAC目标函数训练的网络更好地捕获了参与者的地面真值分布。DAC的平均EMD明显优于WTA,与EWTA和RWTA目标函数相当。与行人目标相比,DAC能更好地捕捉到车辆目标。此外,如表1所示,DAC方法的平均oracle 偏差(FDE)明显低于其他变体,这证实了DAC产生了与WTA不同的假设。
图4:图中展示了CPI测试集上使用不同WTA目标函数的预测假设和学习到的目标混合分布。紫色和黑色的方形代表汽车和行人的当前位置。预测的假设用它们各自的颜色表示。(e) 类似于地面真实分布的假设沿着人行横道上展开,更好地捕获数据分布。
表1:基于FDE和EMD指标的CPI数据集方法比较,其中p代表行人和c代表车辆
5.2 Nuscenes数据集
Nuscenes[5]包含了波士顿和新加坡的大量城市复杂道路场景,大约包含4万个实例,且包括挑战性的序列,比如u型转弯和复杂的道路布局。
5.2.1 基线
我们将ALAN预测结果与在Nuscenes基准数据集上评估的几种基线方法进行了比较。MTP[12]使用栅格化图像作为输入来预测轨迹。CoverNet[38]使用固定的轨迹集,将轨迹预测问题转为对轨迹集的分类。Multipath[8]是最接近的基线,它使用从训练集获得的时间参数化锚点轨迹,并将问题表述为相对于锚点的偏移值的回归。MHA JAM[36]是一种使用联合交通参与者-映射的表示,它输出具有多头注意力。Trajectron++[42]是结合交通参与者动力学和语义的预测轨迹的图循环模型。我们利用[36]中的[12]和[8]的数据。
5.2.2 指标
我们使用标准的评估指标,如平均位移误差(mADEM)和最终位移误差(mFDEM)。此外,我们计算前M个轨迹相较于地面真值的遗漏率(Missd, M)。如果在所有预测中不存在最大位移点小于阈值d的假设,则认为一组预测都是错误的。OffRoadRate计算可行驶区域以外的输出轨迹百分比。我们使用由Nuscenes提供的示例API来计算这些指标。
5.2.3 量化结果
首先,与基线方法相比,ALAN可以达到同等或更好的性能。在这里,我们用不同的锚点抽样策略 (top-M、oracle和best-of-all (BofA)) 来评估ALAN。在ALAN (top-M)中,我们根据预测的每个轨迹的IOC分数,从不同的锚点上选取前M个轨迹输出。ALAN (oracle)使用车道中心线得分最高的oracle锚点,同时ALAN (BofA)从前k个假设的车道锚点中选择最佳。表2的结果表明,ALAN评估要么表现出与其他基准相当的性能,要么在几个指标上显著优于其他基准,如mADE10方面至少有11%的改进,mFDE10方面相较于BofA提高了25%。此外,所有的ALAN预测的OffRoadRate为0.01,即只有1%的预测轨迹落在道路之外。这明显低于其他有7%或更高的OffRoadRate的基线表现。输出预测与语义的强耦合可以归因于车道锚点,它有助于在车道方向上提供输出预测。其他方法,如[8,38],使用从训练集提取的轨迹作为锚点或进行分类,这可能导致输出对未出现场景和具有复杂车道结构的轨迹的泛化能力较差。此外,值得注意的是,ALAN性能被低估了,因为数据中没有连接的车道和没有车道中心线的地方会导致坏锚点。但为了便于与基线比较,在此没有删除这些情况。
表2:轨迹预测基准
消融研究:此外,我们还对ALAN以及DAC和其他变体进行了消融研究,如表3所示。我们首先引入超列描述子[2]来提取多尺度特征,并将其与作为输入进入解码器的全局环境向量进行比较。然后我们研究了ALAN预测的几个变体。首先,我们添加了参考中心线作为输入,并预测xy坐标空间(MCL + Poly)的轨迹。这大大提高了性能。使用车道中心线作为锚点并预测nt空间的轨迹(MCL+LA-nt)表现稍差,但我们认为这是由于网络难以从基于锚点的输入计算交通参与者的动力学特征。例如,具有相同nt坐标的两个轨迹可以根据它们所行驶的车道具有不同的动力学。因此,我们进一步增加xy坐标作为输入,并在笛卡尔空间(MCL+LA-ntxy) 预测辅助轨迹。如表3所示,这样的辅助预测改进了基于主要锚点的输出。
此外,我们使用辅助预测正则化锚点输出,反之亦然。通常意义上,锚点输出可以从辅助预测中受益,因为辅助预测并不局限于只提供沿车道方向的轨迹。添加一个正则化步骤来匹配主轨迹和辅助轨迹,显著提高了锚定输出性能,如表3中MCL+LA-ntxy+Reg值所示。
表3:Nuscenes数据集上的消融研究
5.2.4 量化结果
图5显示了来自ALAN的定性结果。一般来说,使用车道作为锚点,将预测问题转化到nt空间有助于指导预测和跟踪语义。当我们预测较长时间的轨迹时,所执行的轨迹会变得复杂,而不仅仅是一个直行或转弯动作,而使用车道作为锚点可以简化问题。
图5:来自ALAN的预测示例。过去的轨迹用棕色表示,地面真值(GT)用黑色表示。GT的端点用绿点表示。输入车道锚点用青色表示,预测轨迹用绿色表示,终点用三角形表示。(a)和(b)显示了一个复杂的车道结构的预测。基于锚点的预测效果更好,特别是预测较长时间轨迹。由于轨迹的复杂性,锚点的存在有助于遵循语义信息。(c) 当目标车道在相反方向时,适当结合动力学信息预测u型转弯;(d) 多交通参与者的预测场景。
6 结论
在本文中,我们讨论了使用WTA目标函数学习多模态输出和使用驾驶知识对输出预测施加约束的相关问题。首先,我们引入了一种新的DAC方法,该方法可以学习不同的假设,从而在不存在任何伪模式的情况下捕获数据分布。此外,我们还介绍了ALAN,它使用车道作为锚点提供了不同的环境感知轨迹。我们在合成数据和真实数据上的实验都证明了,本文的DAC方法在学习多模态输出方面的优越性。此外,我们还证明了使用车道锚点有助于提供具有强语义耦合的准确预测。
参考文献



编辑推荐




最新资讯
-
《汽车轮胎耐撞击性能试验方法-车辆法》等
2025-04-25 11:45
-
“真实”而精确的能量流测试:电动汽车能效
2025-04-25 11:44
-
GRAS助力中国高校科研升级
2025-04-25 10:25
-
梅赛德斯-AMG使用VI-CarRealTime开发其控制
2025-04-25 10:21
-
天检新能力VOL.95 | 乘员晕车仿生测试能力
2025-04-25 10:14
