




 广告
广告





















































Tesla Autopilot 技术架构解读
2021-06-03 15:46:22· 来源:汽车电子与软件

本文来自对Karpathy的几个技术分享视频的分析,其中数据和截图也来自视频,其中加入作者自己的解读,所以不一定完全正确,如果有错误的地方欢迎大家指正探讨。01
本文来自对Karpathy的几个技术分享视频的分析,其中数据和截图也来自视频,其中加入作者自己的解读,所以不一定完全正确,如果有错误的地方欢迎大家指正探讨。
01 FSD Overview
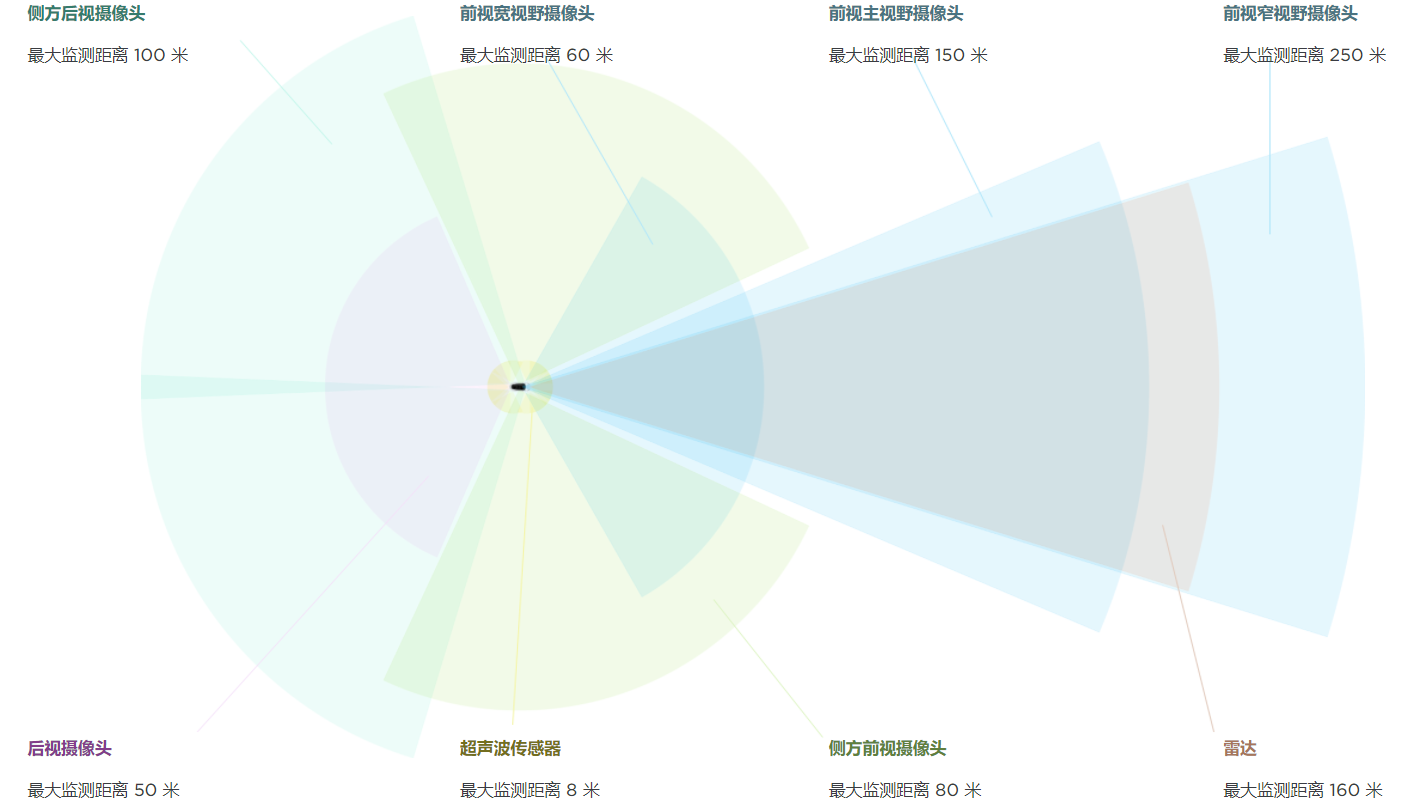
Figure 1 Tesla Autopilot传感器分布
FSD装备8台相机每台相机在36Hz频率采集960x1280的三通道图像(相机参数Karpathy只是举例说明,并不一定是Tesla实际使用的相机Spec),利用所有8个相机的图像,FSD进行超过1000种不同任务的感知预测(数字统计位2020年上半年数据现在可能有所增加)。
所有这些感知功能跑在Tesla自研的FSD Computer上,这台机器有着两颗冗余的FSD chip,每个芯片提供72TOPS(int8)的计算能力,两颗加起来共提供144TOPS算力,其中自带的高速图像处理模块理论上可以支持8颗摄像头在60Hz的频率上传输1080P的图像,其运算能力高于目前市场上的其他高端自动驾驶芯片如Xavier, EyeQ5等。
根据2020年底消息,Tesla将在近期将前向毫米波雷达更新成具有高度分辨率的4D毫米波雷达以提高对于静态障碍物的检测能力。
FSD目前包含的1000多项检测任务覆盖面非常广,包括但不限于下面分类的超过50种Main Task:
· Moving Objects: Pedestrian, Cars, Bicycles, Animals, etc.
· Static Objects: Road signs, Lane lines, Road Markings, Traffic Lights, Overhead Signs, Cross-Walks, Curbs, etc.
· Environment Tags: School Zone, Residential Area, Tunnel, Toll booth, etc.
其中每个Main Task下边还有若干Sub tasks,例如车辆检测还包括车辆的静止,朝向,开门等子任务的检测,Stop Sign检测包括如右转无需停车等细分类检测等等。
除了检测任务,FSD还有训练很多功能网络,包括但不限于下面功能48个子网络:
· Depth Network: 用以进行稠密的深度估计
· Birdeye View Network: 用以进行图像到Birdeye view的坐标投影
· Layout Network: 用以推测道路元素的布局情况
· Pointer Network: 用以预测道路元素间的关联,例如红绿灯对应车道
另外FSD将基于sampling的输出变为基于rasters的输出,二者区别是sampling的输出来自确定geometry的采样,rasters则能够表示uncertainty,more uncertainty意味着输出更加的diffused。
02 Model Architecture
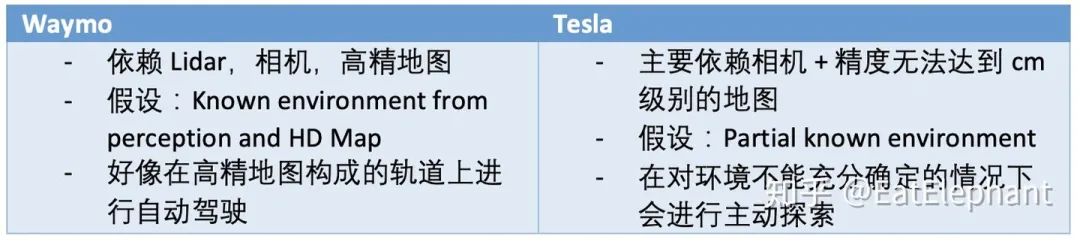
为了进行如此复杂的感知任务,特斯拉在神经网络结构的选择上做了很多考量。
2.1. Single task network vs Multi tasks network


2.2. Loosely coupled heads vs Tightly coupled heads
松耦合指的是每个相机单独进行感知,然后将不同相机的感知结果利用Filter或其他技术进行拼接(stitch),例如1.0版本的Smart Summon就采用了这一方法,利用不同相机检测到的curb进行拼接的到停车场的Occupancy Grid的地图,从而在这个地图进行导航。

Figure 2 基于Occupancy Grid的老版本Smart Summon
但是在不同相机和不同frame间track不同的grid是一件困难的工作。在新版本的Smart Summon中,Tesla采用了对不同相机Feature层输入一个Fusion Layer进行Feature层面的融合,然后输入Birdeye View Network,最终在Birdeye的基础上再分支成不同的heads进行如Object Detection, Road Line Segmentation, Road edge detection等输出。

Figure 3 利用各相机直接进行Birdeye View输出,可输出道路边缘,隔离带,通行区域等分割结果
最终FSD使用的是一个规模巨大的Multi-head network,其中主干网络采用类似ResNet-50的架构用以进行Feature的提取,功能分支采用与FPN/DeepLabV3/UNet类似的结构用以实现不同功能的输出。
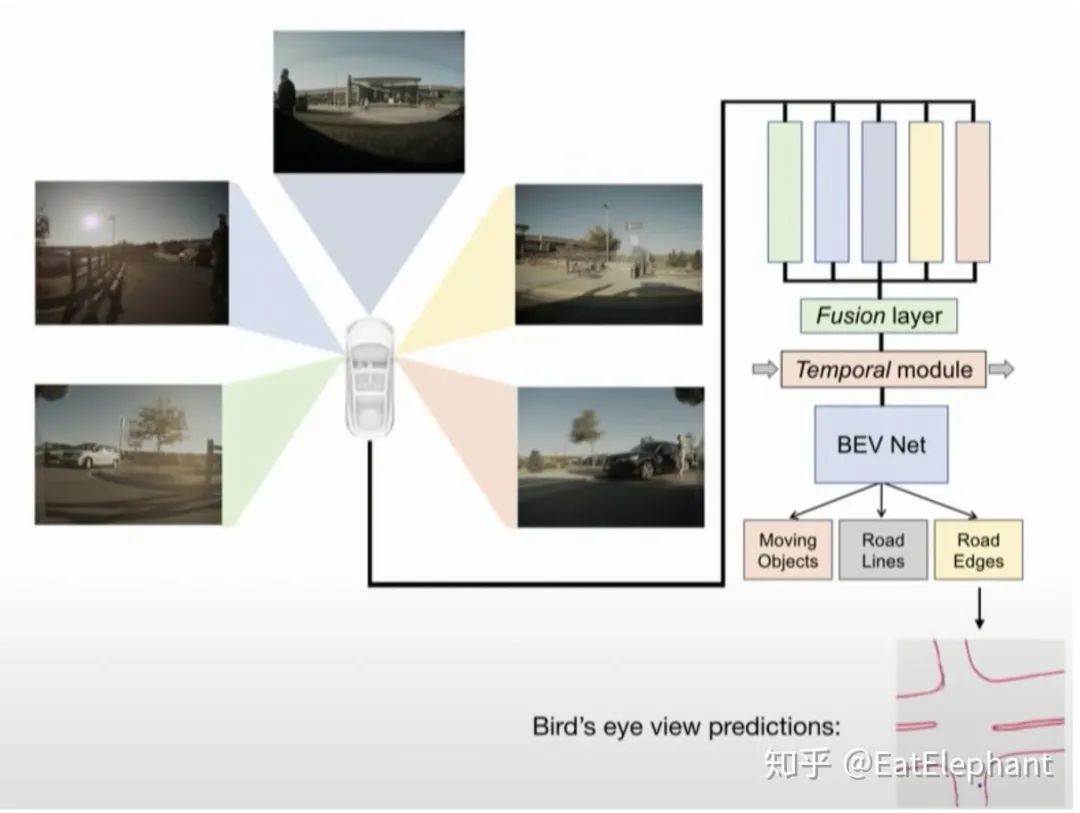
Figure 4 不同相机间特征共享的架构
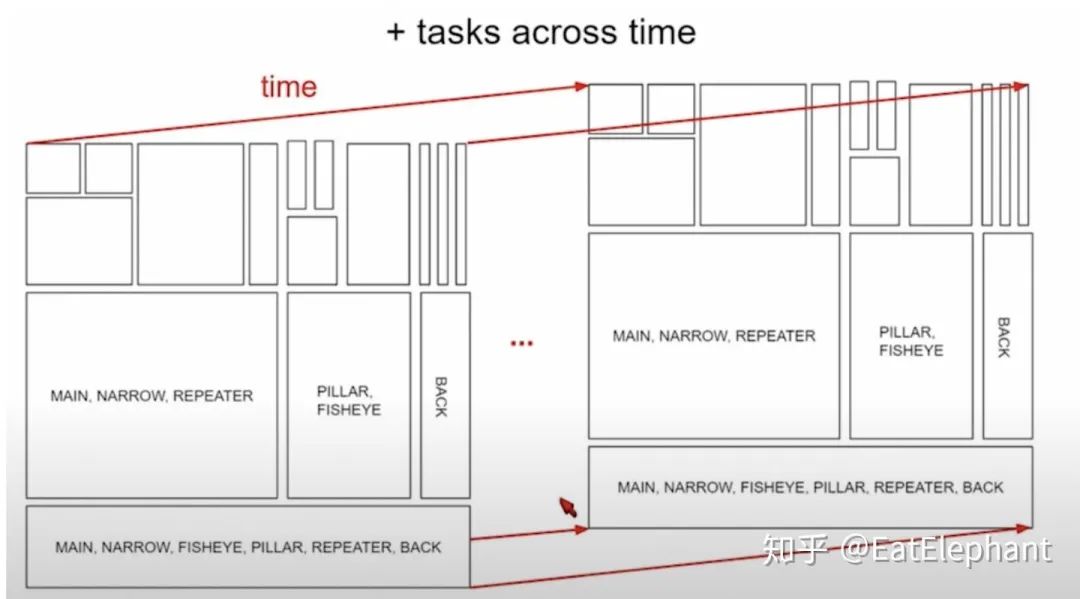
Figure 5 不同相机负责不同的功能分支
最终FSD的网络架构如上面两图所示的共享Backbone加上众多功能Heads的多任务HydraNet,不同相机负责不同的功能,且网络引入了RNN的结构来进行跨时间的感知预测,例如前向3相机Main+ Narrow+ Fisheye+ Pillar 相机的feature负责车道线检测追踪,Pillar+ Fisheye加上过去时刻的输出一同负责Cut-in(加塞)检测等。不同功能在不同相机中共享层次结构是基于一些cross features可以促进各自任务的观察而设计的,同时有些任务间共享层次结构又会相互影响,应以避免。例如动态物体和红绿灯就不应该共享过于底层的Feature,但是车道线检测和可通行区域就应共享更多的底层特征。Karpathy还提到他发现的一些有趣的现象,例如在训练部分网络的时候同时使用5个task的loss来获得更好的features,但是训练得到的网络只会用于5个task中的3个任务的inference使用。
03 Training
训练这样一个拥有48个网络,1000多个感知输出的庞大的Multi-task模型是十分苦难的,单次训练就要花费70000GPU小时,更别说模型训练要经过多次迭代,调优等过程,虽然为了提高训练效率,Tesla自研了专门用于训练的Dojo Computer,但是训练过程仍充满了各种挑战。
3.1. Loss Function
在庞大的HydraNet中,所有的子任务的Heads最终都通过加权平均的办法整合到一个Loss里面,训练的过程就是优化这个整合后的Loss。这些不同子任务的weights则是这个模型的hyperparameter。
学术研究中有通过自动的方法找到最优的子任务权重的办法,但是当子任务数量扩展到数百上千后,这样的自动方法就变得不可使用。
最终这些子任务权重的选择变成一个十分需要谨慎思考,且一旦确定不能轻易更改的超参数。选择这些超参数需要综合考虑许多因素,例如:
· 不同任务的Loss有着不同的scale,而且classification和regression也需要不同的权重
· 不同任务有着不同的重要性,例如行人检测就有着比限速标志牌更高的优先级。
· 有些任务比较简单,其他任务比较困难,例如标示牌变化不大,很快模型就能训练到很好的效果,但是车道元素分布网络则十分难寻来呢
· 长尾任务数据十分稀少(例如异型车辆,事故等检测数据十分稀有)
· 有些任务数据有着大量的噪声
为了达到模型在所有任务都能取得良好的性能,需要合理的调节不同任务的权重,并且一旦确定不同权重的比重,就要在确定的权重下进行任务的调优,而不能频繁更改权重,导致其他任务的性能回退。
3.2. Training Across Different Tasks
因为模型在不同任务间进行不同程度的参数共享,因此利用不同的数据对一些子任务进行训练的时候,并不是整个网络模型都会得到训练,而是根据任务和数据sample整体网络的一部分进行训练,如下图所示。
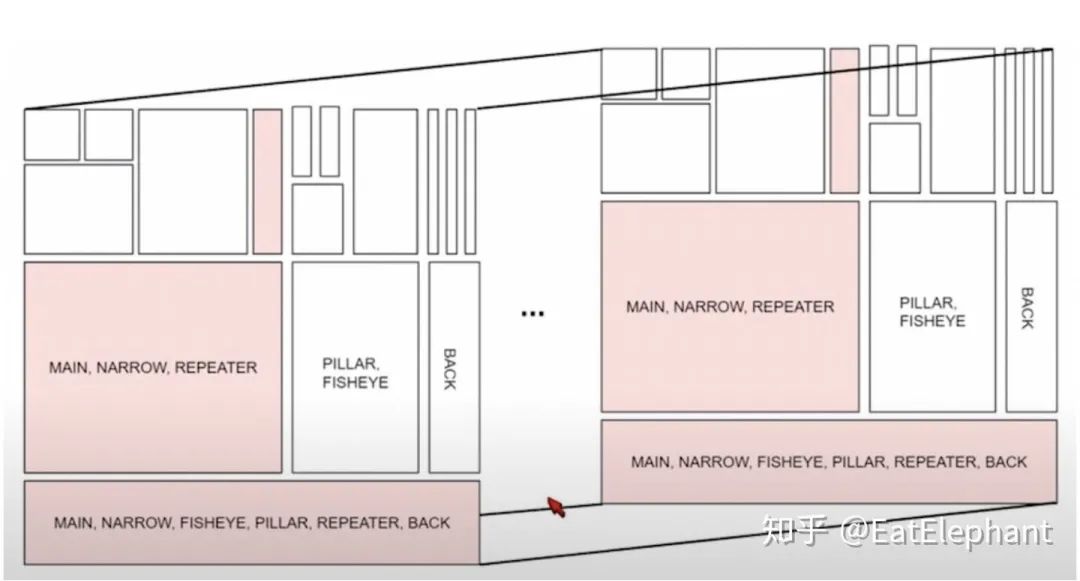
Figure 6某一项子任务对应的数据只对粉色部分的模型进行训练
为了避免训练部分网络的时候对于其他任务的影响,可以采取类似Transfer Learning中的freeze部分参数的方法。
3.3. Data Balance
为了解决长尾任务的训练,采用Data Oversampling来保证任务内的Data Balance以及任务间的Data Balance。下图是红绿灯检测任务内的Data Oversampling的示意图:
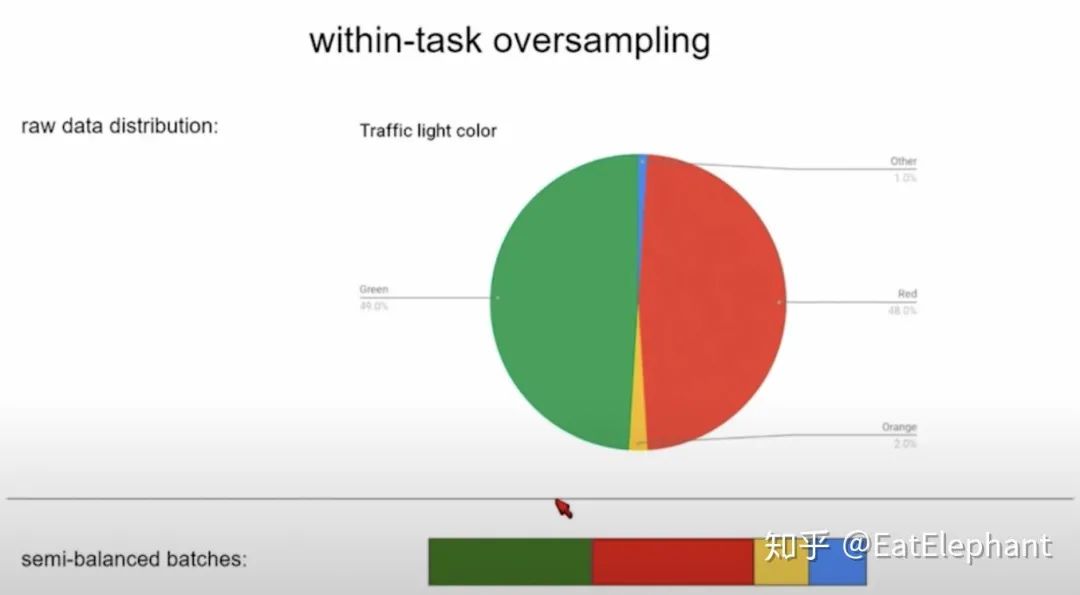
Figure 7 通过Oversampling使黄灯和蓝色通行等的比例达到合适程度
在现实交通灯数据中,黄灯和表示通行的蓝灯非常有限,然而过度inbalance的数据将使得训练正确识别这些数据的模型变得十分困难,通过oversampling达到在一项任务内基本的一个数据分布的平衡。
另外在任务间也通过不同任务的优先级,重要程度等设定oversampling rate来调节不同任务的性能。
3.4. Hyper Parameter
除了上面提到的oversampling rates,task loss weights等hyperparameter外不同任务head的复杂程度,正则方法等也是hyperparameter调节的重要参数。
例如对于数据量不同的任务,应该对长尾任务及噪声较多的任务应使用较小规模的head以避免overfitting。
对于常用的正则方法early stopping,由于不同任务有不同的训练曲线,应通过调节不同任务的权重使得曲线趋势基本一致,以决定·一个统一的early stopping的条件。
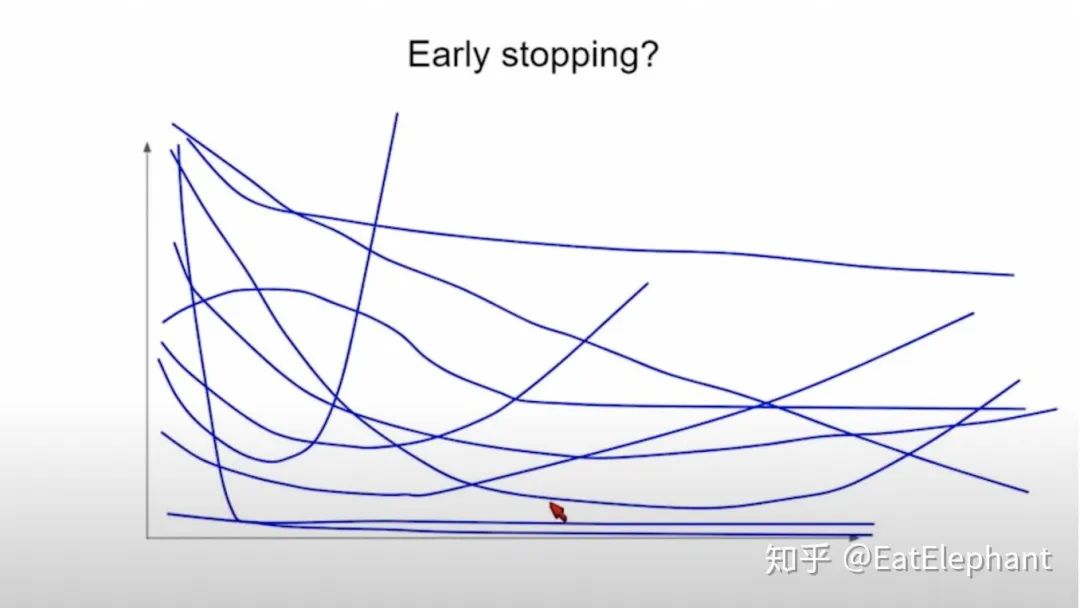
Figure 8 多任务的模型在调节权重前无法使用Early Stopping
3.5. Multi-task Training Scheduler
如下图所示,Tesla利用分布式的训练机器进行多任务的训练以减少训练时间,Karpathy提到Tesla更多采用后两种训练任务安排
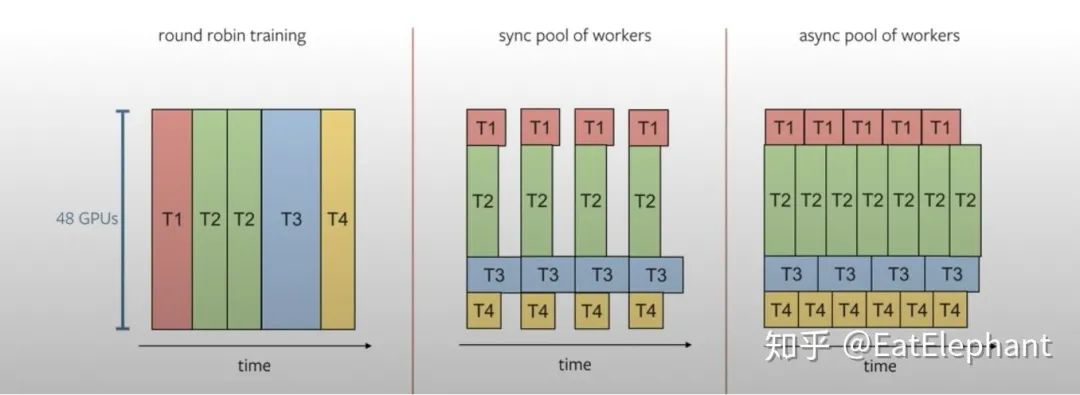
Figure 9 利用分布服务器对子任务采取不同的训练流程
04 Workflow & Collaboration
4.1. Data Engine& Active Learning
Tesla利用Shadow Mode来采集数据,利用Trigger来触发主动的数据获取,从而实现Active Learning。Data Engine的示意图如下所示:
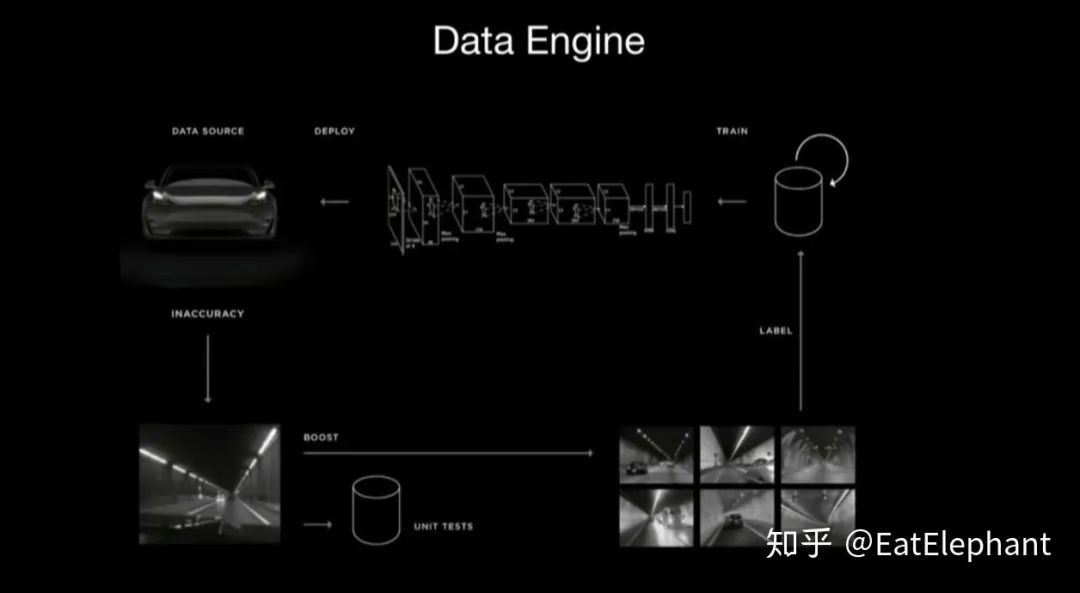
Figure 10 Tesla Data Engine示意图
使用Data Engine来完成一项新任务的流程如下:

其中Trigger是利用高recall低precision的粗分类器来识别特定需要训练的场景来达到对上传数据进行筛选的机制,以提取rare cases从而提高数据的获取率。同时利用不同任务trigger的sampling rate可以控制不同任务占用的训练资源,从而平衡不同任务的训练效果。之所以trigger可以工作是因为trigger本质上是一个简化了的模型,同时data engine获取的数据量已经大大精简,因此后面还可以再利用人工进行一轮筛选来剔除trigger获取的的false positive的训练数据。
通过不断主动向Tesla超过1百万在全球行驶的车辆索取数据,Tesla得以获得大量所需的特定类型的数据以训练庞大的HydraNet模型。
4.2. Collaboration
由于Tesla Autopilot Team是一个规模很小的团队,而庞大复杂的模型功能使得每个人经常负责不同的任务,因此一个标准的团队合作流程就成了如何调优模型同时不使得模型退化的关键。
Karpathy的报告中提到几点在多人合作的AI项目中合作的经验,值得工业界团队借鉴。
- Hyperparameter不能够随意更改以改进自己的工作任务性能
因为Tesla FSD要处理复杂的任务,进行1000+项感知任务,因此即使FSD使用一个极其巨大的HydraNet模型,该模型的表达能力也是有限的(Finite Model Capacity),每个团队成员在优化自己任务的时候应选用正确的方法,而不损害已有的模型性能。例如通过提高自己sub task在Data Engine里的sampling rate,或者提高sub task在整体Loss中的权重,甚至简单提高自己sub task loss function的scale,就可以使训练资源,模型capacity向自己sub task倾斜已获得虚假的性能提升,这种行为是容易实施的投机取巧,要严格杜绝。
- 要尽量避免Finetune历史记录复杂化
通过Finetune,可以获得更好的模型参数,然而不像传统软件有着像git一样的版本控制软件去记录代码的更改,neural network的finetune历史往往难以追踪。如果放任复杂的finetune历史交织在一起,所导致的问题是可能最终获得了一个很好的模型参数,但这样的参数是强依赖于复杂的finetune顺序而获得的,因为finetune顺序不可追踪,因此这样的模型参数即使性能优秀,但是其缺点是不能复现,因此实际工作中要尽量避免复杂的finetune叠加。
05 evaluation & Test
Karpathy将以Neural Network为主实现功能的软件称为Software2.0,与依赖逻辑,数据结构,算法的传统软件不同,Software2.0缺乏业界共识的Best Practice。为此Tesla在开发过程中借鉴了很多传统软件中Test Driven的思路思路。
Tesla利用强大的Data Engine获取大量的Corner case的数据生成Unit Tests/Regression Tests for neural networks,例如下图所示就是特斯拉Stop Signs的CT流程,所有对于模型的更新必须保证模型的性能不发生回退,才能够提交更改,而保证不回退的办法就是所有Unit tests必须通过。
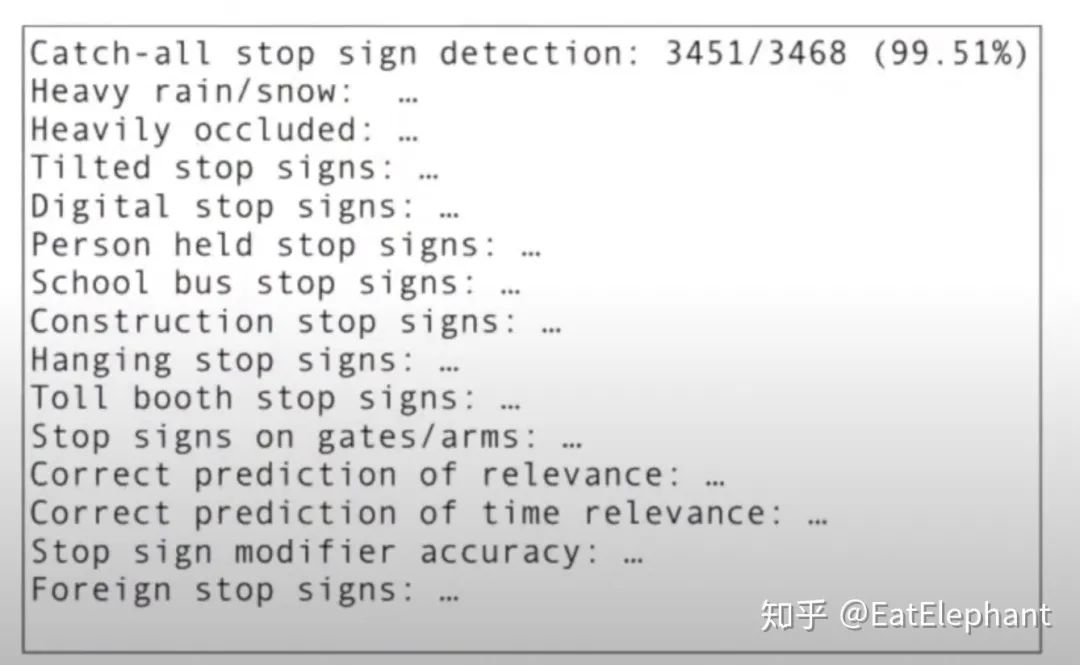
Figure 11 Tesla Stop Sign Regression Test示意图
01 FSD Overview
Figure 1 Tesla Autopilot传感器分布
FSD装备8台相机每台相机在36Hz频率采集960x1280的三通道图像(相机参数Karpathy只是举例说明,并不一定是Tesla实际使用的相机Spec),利用所有8个相机的图像,FSD进行超过1000种不同任务的感知预测(数字统计位2020年上半年数据现在可能有所增加)。
所有这些感知功能跑在Tesla自研的FSD Computer上,这台机器有着两颗冗余的FSD chip,每个芯片提供72TOPS(int8)的计算能力,两颗加起来共提供144TOPS算力,其中自带的高速图像处理模块理论上可以支持8颗摄像头在60Hz的频率上传输1080P的图像,其运算能力高于目前市场上的其他高端自动驾驶芯片如Xavier, EyeQ5等。
根据2020年底消息,Tesla将在近期将前向毫米波雷达更新成具有高度分辨率的4D毫米波雷达以提高对于静态障碍物的检测能力。
FSD目前包含的1000多项检测任务覆盖面非常广,包括但不限于下面分类的超过50种Main Task:
· Moving Objects: Pedestrian, Cars, Bicycles, Animals, etc.
· Static Objects: Road signs, Lane lines, Road Markings, Traffic Lights, Overhead Signs, Cross-Walks, Curbs, etc.
· Environment Tags: School Zone, Residential Area, Tunnel, Toll booth, etc.
其中每个Main Task下边还有若干Sub tasks,例如车辆检测还包括车辆的静止,朝向,开门等子任务的检测,Stop Sign检测包括如右转无需停车等细分类检测等等。
除了检测任务,FSD还有训练很多功能网络,包括但不限于下面功能48个子网络:
· Depth Network: 用以进行稠密的深度估计
· Birdeye View Network: 用以进行图像到Birdeye view的坐标投影
· Layout Network: 用以推测道路元素的布局情况
· Pointer Network: 用以预测道路元素间的关联,例如红绿灯对应车道
另外FSD将基于sampling的输出变为基于rasters的输出,二者区别是sampling的输出来自确定geometry的采样,rasters则能够表示uncertainty,more uncertainty意味着输出更加的diffused。
02 Model Architecture
为了进行如此复杂的感知任务,特斯拉在神经网络结构的选择上做了很多考量。
2.1. Single task network vs Multi tasks network
2.2. Loosely coupled heads vs Tightly coupled heads
松耦合指的是每个相机单独进行感知,然后将不同相机的感知结果利用Filter或其他技术进行拼接(stitch),例如1.0版本的Smart Summon就采用了这一方法,利用不同相机检测到的curb进行拼接的到停车场的Occupancy Grid的地图,从而在这个地图进行导航。
Figure 2 基于Occupancy Grid的老版本Smart Summon
但是在不同相机和不同frame间track不同的grid是一件困难的工作。在新版本的Smart Summon中,Tesla采用了对不同相机Feature层输入一个Fusion Layer进行Feature层面的融合,然后输入Birdeye View Network,最终在Birdeye的基础上再分支成不同的heads进行如Object Detection, Road Line Segmentation, Road edge detection等输出。
Figure 3 利用各相机直接进行Birdeye View输出,可输出道路边缘,隔离带,通行区域等分割结果
最终FSD使用的是一个规模巨大的Multi-head network,其中主干网络采用类似ResNet-50的架构用以进行Feature的提取,功能分支采用与FPN/DeepLabV3/UNet类似的结构用以实现不同功能的输出。
Figure 4 不同相机间特征共享的架构
Figure 5 不同相机负责不同的功能分支
最终FSD的网络架构如上面两图所示的共享Backbone加上众多功能Heads的多任务HydraNet,不同相机负责不同的功能,且网络引入了RNN的结构来进行跨时间的感知预测,例如前向3相机Main+ Narrow+ Fisheye+ Pillar 相机的feature负责车道线检测追踪,Pillar+ Fisheye加上过去时刻的输出一同负责Cut-in(加塞)检测等。不同功能在不同相机中共享层次结构是基于一些cross features可以促进各自任务的观察而设计的,同时有些任务间共享层次结构又会相互影响,应以避免。例如动态物体和红绿灯就不应该共享过于底层的Feature,但是车道线检测和可通行区域就应共享更多的底层特征。Karpathy还提到他发现的一些有趣的现象,例如在训练部分网络的时候同时使用5个task的loss来获得更好的features,但是训练得到的网络只会用于5个task中的3个任务的inference使用。
03 Training
训练这样一个拥有48个网络,1000多个感知输出的庞大的Multi-task模型是十分苦难的,单次训练就要花费70000GPU小时,更别说模型训练要经过多次迭代,调优等过程,虽然为了提高训练效率,Tesla自研了专门用于训练的Dojo Computer,但是训练过程仍充满了各种挑战。
3.1. Loss Function
在庞大的HydraNet中,所有的子任务的Heads最终都通过加权平均的办法整合到一个Loss里面,训练的过程就是优化这个整合后的Loss。这些不同子任务的weights则是这个模型的hyperparameter。
学术研究中有通过自动的方法找到最优的子任务权重的办法,但是当子任务数量扩展到数百上千后,这样的自动方法就变得不可使用。
最终这些子任务权重的选择变成一个十分需要谨慎思考,且一旦确定不能轻易更改的超参数。选择这些超参数需要综合考虑许多因素,例如:
· 不同任务的Loss有着不同的scale,而且classification和regression也需要不同的权重
· 不同任务有着不同的重要性,例如行人检测就有着比限速标志牌更高的优先级。
· 有些任务比较简单,其他任务比较困难,例如标示牌变化不大,很快模型就能训练到很好的效果,但是车道元素分布网络则十分难寻来呢
· 长尾任务数据十分稀少(例如异型车辆,事故等检测数据十分稀有)
· 有些任务数据有着大量的噪声
为了达到模型在所有任务都能取得良好的性能,需要合理的调节不同任务的权重,并且一旦确定不同权重的比重,就要在确定的权重下进行任务的调优,而不能频繁更改权重,导致其他任务的性能回退。
3.2. Training Across Different Tasks
因为模型在不同任务间进行不同程度的参数共享,因此利用不同的数据对一些子任务进行训练的时候,并不是整个网络模型都会得到训练,而是根据任务和数据sample整体网络的一部分进行训练,如下图所示。
Figure 6某一项子任务对应的数据只对粉色部分的模型进行训练
为了避免训练部分网络的时候对于其他任务的影响,可以采取类似Transfer Learning中的freeze部分参数的方法。
3.3. Data Balance
为了解决长尾任务的训练,采用Data Oversampling来保证任务内的Data Balance以及任务间的Data Balance。下图是红绿灯检测任务内的Data Oversampling的示意图:
Figure 7 通过Oversampling使黄灯和蓝色通行等的比例达到合适程度
在现实交通灯数据中,黄灯和表示通行的蓝灯非常有限,然而过度inbalance的数据将使得训练正确识别这些数据的模型变得十分困难,通过oversampling达到在一项任务内基本的一个数据分布的平衡。
另外在任务间也通过不同任务的优先级,重要程度等设定oversampling rate来调节不同任务的性能。
3.4. Hyper Parameter
除了上面提到的oversampling rates,task loss weights等hyperparameter外不同任务head的复杂程度,正则方法等也是hyperparameter调节的重要参数。
例如对于数据量不同的任务,应该对长尾任务及噪声较多的任务应使用较小规模的head以避免overfitting。
对于常用的正则方法early stopping,由于不同任务有不同的训练曲线,应通过调节不同任务的权重使得曲线趋势基本一致,以决定·一个统一的early stopping的条件。
Figure 8 多任务的模型在调节权重前无法使用Early Stopping
3.5. Multi-task Training Scheduler
如下图所示,Tesla利用分布式的训练机器进行多任务的训练以减少训练时间,Karpathy提到Tesla更多采用后两种训练任务安排
Figure 9 利用分布服务器对子任务采取不同的训练流程
04 Workflow & Collaboration
4.1. Data Engine& Active Learning
Tesla利用Shadow Mode来采集数据,利用Trigger来触发主动的数据获取,从而实现Active Learning。Data Engine的示意图如下所示:
Figure 10 Tesla Data Engine示意图
使用Data Engine来完成一项新任务的流程如下:
其中Trigger是利用高recall低precision的粗分类器来识别特定需要训练的场景来达到对上传数据进行筛选的机制,以提取rare cases从而提高数据的获取率。同时利用不同任务trigger的sampling rate可以控制不同任务占用的训练资源,从而平衡不同任务的训练效果。之所以trigger可以工作是因为trigger本质上是一个简化了的模型,同时data engine获取的数据量已经大大精简,因此后面还可以再利用人工进行一轮筛选来剔除trigger获取的的false positive的训练数据。
通过不断主动向Tesla超过1百万在全球行驶的车辆索取数据,Tesla得以获得大量所需的特定类型的数据以训练庞大的HydraNet模型。
4.2. Collaboration
由于Tesla Autopilot Team是一个规模很小的团队,而庞大复杂的模型功能使得每个人经常负责不同的任务,因此一个标准的团队合作流程就成了如何调优模型同时不使得模型退化的关键。
Karpathy的报告中提到几点在多人合作的AI项目中合作的经验,值得工业界团队借鉴。
- Hyperparameter不能够随意更改以改进自己的工作任务性能
因为Tesla FSD要处理复杂的任务,进行1000+项感知任务,因此即使FSD使用一个极其巨大的HydraNet模型,该模型的表达能力也是有限的(Finite Model Capacity),每个团队成员在优化自己任务的时候应选用正确的方法,而不损害已有的模型性能。例如通过提高自己sub task在Data Engine里的sampling rate,或者提高sub task在整体Loss中的权重,甚至简单提高自己sub task loss function的scale,就可以使训练资源,模型capacity向自己sub task倾斜已获得虚假的性能提升,这种行为是容易实施的投机取巧,要严格杜绝。
- 要尽量避免Finetune历史记录复杂化
通过Finetune,可以获得更好的模型参数,然而不像传统软件有着像git一样的版本控制软件去记录代码的更改,neural network的finetune历史往往难以追踪。如果放任复杂的finetune历史交织在一起,所导致的问题是可能最终获得了一个很好的模型参数,但这样的参数是强依赖于复杂的finetune顺序而获得的,因为finetune顺序不可追踪,因此这样的模型参数即使性能优秀,但是其缺点是不能复现,因此实际工作中要尽量避免复杂的finetune叠加。
05 evaluation & Test
Karpathy将以Neural Network为主实现功能的软件称为Software2.0,与依赖逻辑,数据结构,算法的传统软件不同,Software2.0缺乏业界共识的Best Practice。为此Tesla在开发过程中借鉴了很多传统软件中Test Driven的思路思路。
Tesla利用强大的Data Engine获取大量的Corner case的数据生成Unit Tests/Regression Tests for neural networks,例如下图所示就是特斯拉Stop Signs的CT流程,所有对于模型的更新必须保证模型的性能不发生回退,才能够提交更改,而保证不回退的办法就是所有Unit tests必须通过。
Figure 11 Tesla Stop Sign Regression Test示意图
- 下一篇:车辆ECU开发组件Woodward
- 上一篇:激光雷达的探测范围是越越好吗?



编辑推荐




最新资讯
-
奇石乐推出用于DAQ数据采集系统的KiStudio
2025-04-28 17:51
-
全球首次!IVISTA 2023版修订版引入带灯光
2025-04-28 09:59
-
我国首批5G毫米波行业标准送审稿审查通过
2025-04-28 08:56
-
5/16 厦门- 新能源汽车电驱测试技术的创新
2025-04-28 08:53
-
国内首个汽车电磁防护技术验证体系EMTA正式
2025-04-28 08:49
