




 广告
广告





















































基于学习的自动驾驶汽车路径跟踪模型预测控制
2021-06-23 23:08:28· 来源:同济智能汽车研究所

编者按:近年来,基于车辆运动学与动力学模型的模型预测控制(MPC)理论在自动驾驶车辆控制方面得到了广泛的应用,MPC基于预先设定的系统模型,通过滚动优化,解
编者按:近年来,基于车辆运动学与动力学模型的模型预测控制(MPC)理论在自动驾驶车辆控制方面得到了广泛的应用,MPC基于预先设定的系统模型,通过滚动优化,解决设定的优化问题并求解出控制输入。MPC的主要优点在于能够系统地处理多个优化目标,并且可以处理输入和输出的约束。本文中提出了一种逆最优控制(IOC)算法用于从人类演示数据中学习成本函数,将学习得到的成本函数应用于路径跟踪MPC中。结果显示,该控制器不仅可以遵循参考轨迹,还可以使侧向速度、侧向加速度等特征更接近人类驾驶。
本文译自:
《Learning-based Model Predictive Control for Path Tracking Control of Autonomous Vehicle》
文章来源:
2020 IEEE International Conference on Systems, Man, and Cybernetics (SMC)
作者:
Mohammad Rokonuzzaman, Navid Mohajer, Saeid Nahavandi, Shady Mohamed
原文链接:
https://ieeexplore.ieee.org/document/9283293
摘要:自动驾驶汽车的路径跟踪控制器在改善车辆的动态行为方面起着重要作用。模型预测控制 (MPC) 是最强大的控制器之一,可以处理多个优化目标,并适应执行器和车辆状态的物理限制,以确保安全和其他所需行为。作为一种高潜力的解决方案,可以将人工演示的学习成本函数集成到 MPC 中。通过从人工演示中学习成本函数,可以避免大量参数调整,更重要的是,可以调整控制器以提供对人类更自然的所需控制动作。在本研究中,提出了一种创新的逆最优控制 (IOC) 算法,以使用从人工演示中收集的数据为控制任务学习合适的成本函数。目标是设计一种控制器,该控制器生成的运动与人类产生的运动的特定特征相匹配。这些特征包括侧向加速度、侧向速度和偏离车道中心。从结果中可以看出,设计的控制器能够学习人类驾驶的所需特征并在生成适当的控制动作的同时实现它们。
关键词:自动驾驶汽车,路径跟踪控制器,模型预测控制,逆最优控制
1 引言
模型预测控制(MPC)被认为是设计自动驾驶汽车路径跟踪控制器的合适框架。该技术在每个时间步解决一个优化问题,并且可以同时处理多个目标。此外,它可以适应执行器和车辆状态的物理限制,以确保安全和其他所需的行为。为了为自动驾驶汽车制定有效的模型预测控制,应该定义适当的成本函数。成本函数的设计往往取决于设计者的经验和精通程度。当乘客的感觉被考虑到车辆性能中时,设计成本函数会更加复杂。
从客观的角度来看,可以通过改善自动驾驶汽车的操控行为来提高人类的舒适度和安全性[1]、[2]。这种考虑是对传统车辆乘坐舒适性的补充,其主要取决于车辆的振动特性[3]-[5]。从主观角度看,舒适度取决于人的感觉,难以表述为一组成本函数。作为一种高潜力的解决方案,从人工演示中学习成本函数一直是研究人员的一个有吸引力的选择。
为了学习成本函数或成本函数的一些参数,许多研究人员提出了逆最优控制(IOC)。在这种方法中,对于未知的成本函数,专家演示通常用作最优控制问题的解决方案[6]。考虑 IOC 环境下的 MPC 问题,对于成本函数的未知参数,可以将演示输入视为最优输入序列。给定演示数据和参数成本函数,初步概述了参数控制的最优条件。此外,IOC 问题可以定义为一种搜索算法,用于寻找满足最佳条件的合适参数值[7]。
从演示中估计成本函数的另一种方法是使用逆强化学习 (IRL)。在某些情况下,IOC 和 IRL 被互相定义为相同的方法。在 IRL 的背景下,使用诸如马尔可夫决策过程 (MDP) 之类的概率方法从已证明的最佳行为中提取奖励函数[8]、[9]。在 MDP 方法中,特别是对于强化学习 (RL) 的情况,假设成本函数是已知的。然而,如前所述,为 RL 设计合适的成本函数同样困难。IRL 已被用于模仿学习(有时称为学徒学习),其目标是找到一种控制策略,该策略在未知奖励函数的情况下能表现得和演示者一样好[9]。
许多不同类型的系统提出了IRL和IOC,例如类人机器人[10]、直升机控制[11]和特定驾驶风格的复制[12]。在[10]中,IRL被提出来寻找奖励函数,以使用来自人工演示的数据来设计仿人机器人更自然和动态的运行行为。从模拟结果来看,学习到的奖励函数显示出可用于不同环境的良好泛化特性。即使优化问题是离线解决的,学习到的奖励函数也可以很容易地集成到在线 MPC 算法中。类似地,在[13]中,IOC 被实现为类人运动控制。但是,在这种情况下,没有考虑每个关节的运动;相反,类人机器人的位置和方向用于使用双层优化问题来描述运动。高层控制迭代代价函数的权重,并试图最小化测量数据与从低层控制收集的最优控制的解之间的距离。
在自动驾驶的背景下,IRL 已被提出用于预测人类意图。例如,它用于对人类行为进行建模,推断人类驾驶员的路线偏好[14]。类似地,在[15]中,IRL用于预测驾驶员在道路上的意图。人类驾驶员的运动被表述为一个优化问题,并使用IRL找到奖励函数。在[12]中,IRL也被用于在生成自动驾驶汽车跟随的轨迹时复制个人驾驶风格。在这项工作中,最大熵IRL[14]用于解决自动驾驶的路径规划问题。此外,成本函数以类似于[9]的方式近似为特征的线性组合。IRL的最终目标是为成本函数的每个特征找到合适的权重,最终用于为车辆生成优化轨迹。
尽管 IOC 和 IRL 已针对上述不同应用实现,但据我们所知,这些技术尚未用于自动驾驶汽车的路径跟踪控制器。考虑到可以通过提高车辆的操纵性能来提高乘客的舒适度,基于人工演示数据的基于学习的 MPC 有可能适应这种措施,从而提高乘客的舒适度。在本文中,我们建议将 IOC 用于基于学习的 MPC,用于自动驾驶汽车的路径跟踪任务。为了实现此功能,设计了一种新颖的基于特征的 MPC 参数成本函数。此外,提出了一种创新的 IOC 算法,以使用从人工演示中收集的数据来学习 MPC 的合适成本函数参数。数据是使用集成的3D模拟环境“虚幻引擎”和 Matlab-Simulink 平台收集的。目标是设计一个控制器,产生与人类产生的运动的特定特征相匹配的运动。这些特征包括横向加速度、横向速度、与车道中心的距离和偏航率。成本函数的参数是从人工演示数据中学习的。然后使用这些参数来实现自动驾驶汽车的 MPC 控制器。
本文的其余部分组织如下。在第Ⅱ节中,介绍了人工演示学习成本函数背后的理论框架。详细解释了MPC的制定、成本函数的定义和IOC的方法论。第Ⅲ节概述了从人工演示中收集数据的实验,以及从收集的数据中学习成本函数所采取的步骤,以及在路径跟踪控制器中应用学习到的参数。在第Ⅳ节和第Ⅴ节中,展示并进一步讨论了结果,并给出了研究的结论。
2 从人工演示中学习成本函数
本工作的主要目标是使用从人工演示中收集的数据为路径跟踪任务找到合适的成本函数。道路路径剖面对自动驾驶汽车的操控行为有显着影响[16];在本工作中,对于给定的参考路径,人工演示的轨迹被认为是最佳解决方案。此外,假设存在与人类驾驶员生成的轨迹相关联的成本函数。目标是找到成本函数的适当参数,该参数捕获个人人类驾驶任务的选定特征。在本节中,首先讨论 MPC 控制器的公式。然后,建立了基于特征的 MPC 成本函数的设计。最后,详细阐述了 IOC 的设计。
A. 模型预测控制
在 MPC 中,基于车辆的过渡模型计算车辆在特定范围内的未来状态。在每个时间步,求解非线性优化问题以生成最小化成本函数的控制动作。在优化后的控制序列中,只有第一个控制动作被发送到车辆,接下来的时间间隔内重复整个过程。MPC控制器的主要优点之一是可以处理多个目标。此外,由于它解决了约束优化问题,因此可以约束车辆的状态(例如转向角)以匹配物理限制。对于本工作,考虑车辆状态六χ=[X,Y,ψ,vy, r, ay]被考虑,其中X和Y是车辆在全局坐标系中的位置,ψ是偏航角,r是偏航率,vy是纵向速度,ay是纵向加速度。对于这些车辆状态和转向角输入u=δ ,车辆过渡模型可以表示为
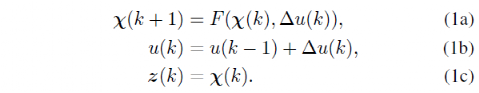
基于学习的控制器的成本函数可以用参数形式表示并更新以提高控制器的性能,即复制人工演示。带有参数成本函数的MPC问题可以表示为
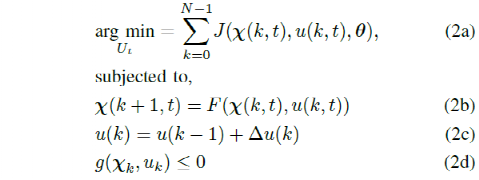
其中,g(χk,uk)表示状态和输入约束,θ表示成本函数的参数向量。解决这个优化问题,找到一个优化的控制序列 U* = [uk*....uk+N*] 并且在每个时间步只将序列的第一个控制动作发送到车辆。在接下来的时间间隔内重复此过程。
B. 成本函数
改进的自动驾驶汽车路径跟踪控制器应适应准确和安全的路径跟踪,同时生成控制动作,提供对人更自然的运动。此处考虑了参数成本函数,并使用基于特征的学习技术来找到产生与人类驾驶员相似特征的参数的最佳值。对于人工演示或控制器生成的每个轨迹,以下特征用于设计参数成本函数。
a)车道中心距离:该特征表示车辆与车道中心的偏差,可以表示为
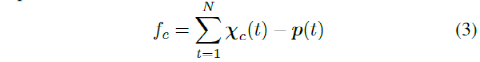
其中t为时间,χc(t)=[X, Y]是t时刻车辆在道路上的位置,p(t)=[Xref, Yref]是车道中心距离车辆位置最近的道路点,N是轨迹中的样本数。
b)与路径的偏离角:车辆横摆角与路径角的偏离由该特征表示。
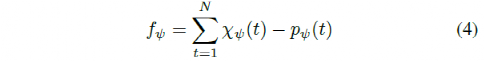
其中,χψ为车辆航向角,pψ为路径角度。
c)横向速度:另一个需要与人工演示进行比较的特征是车辆的横向速度,它表示为
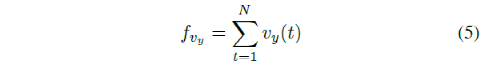
d)偏航率:对于路径跟踪任务,偏航率是影响乘客舒适度的重要特征。此特征可以由下式计算得到
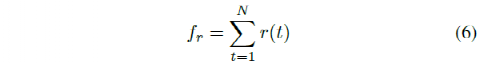
e)横向加速度:对乘客舒适度有显着影响的最重要特征之一是车辆的横向加速度。该特征计算为
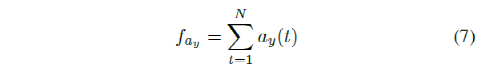
最后,利用这些特征,路径跟踪任务的成本函数表示为
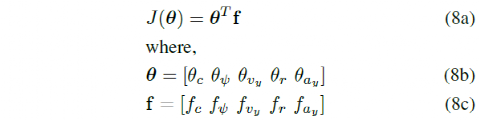
其中,θ为是需要从人工演示中学习的参数或权重向量,以便使用 MPC 生成的运动与人工演示中的特征相匹配。
C. 逆最优控制
在一般最优控制问题中,目标是找到基于某些特定准则的控制动作或策略。这些准则通常使用提供选择动作的成本的成本函数来表达。然而,设计一个合适的成本函数很困难,而且通常需要大量的时间进行调整。在 IOC 方法中,目标是基于用户演示找到合适的成本函数,而不是找到最优策略。然后可以使用该成本函数来生成最优策略。图1显示了 IOC 过程的一般示意图。IOC 和 IRL 技术可以互换使用,因为它们描述了类似的方法。
在此过程中,重要的是设计适当的成本函数,明确解决设计偏好和目标。例如,对于自动驾驶的复杂任务,调整成本函数的不同参数以获得优选性能并不简单。在这方面,IOC提供了一个合适的选项,可以根据从人工演示收集的数据来调整成本函数。
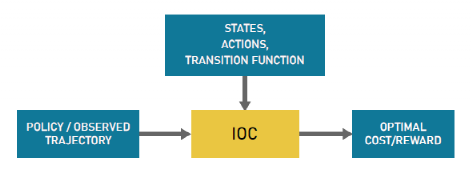
图1 IOC过程示意图
人工演示数据集D=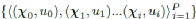 用于考虑各种驾驶场景的P条轨迹。对于人工演示,我们假设存在与人类驾驶任务相关的成本函数,因此通过为 MPC 控制器找到合适的权重,可以复制人类驾驶运动的某些特征。为了实现这一点,人类的驾驶任务使用 II-B 中讨论的特征来表达。对于一组未知的成本参数,人工演示的预期特征可以表示为
用于考虑各种驾驶场景的P条轨迹。对于人工演示,我们假设存在与人类驾驶任务相关的成本函数,因此通过为 MPC 控制器找到合适的权重,可以复制人类驾驶运动的某些特征。为了实现这一点,人类的驾驶任务使用 II-B 中讨论的特征来表达。对于一组未知的成本参数,人工演示的预期特征可以表示为
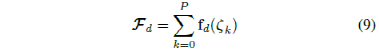
其中,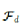 是所有演示的特征向量,fd是演示轨迹的特征向量,ζk是数据集D中第k个轨迹。这里的目标是找到一组成本参数,使得学习到的控制器的预期特征与人工演示的特征相匹配。演示特征和控制器特征之间的差异可以表示为以下梯度
是所有演示的特征向量,fd是演示轨迹的特征向量,ζk是数据集D中第k个轨迹。这里的目标是找到一组成本参数,使得学习到的控制器的预期特征与人工演示的特征相匹配。演示特征和控制器特征之间的差异可以表示为以下梯度
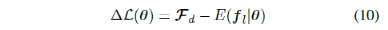
其中,fl是由控制器为一组固定参数值θ生成的轨迹的特征向量。使用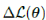 可以通过求解基于梯度的优化方法找到优化值θ*。然而,计算学习系统的预期特征并不简单,尤其是对于像自动驾驶汽车这样的高维复杂系统。当我们为自动驾驶汽车设计路径跟踪控制器时,我们将最可能的轨迹近似为给定参数集的非线性MPC问题的解决方案,然后使用MPC生成的轨迹计算学习控制器的预期特征。然后,基于梯度
可以通过求解基于梯度的优化方法找到优化值θ*。然而,计算学习系统的预期特征并不简单,尤其是对于像自动驾驶汽车这样的高维复杂系统。当我们为自动驾驶汽车设计路径跟踪控制器时,我们将最可能的轨迹近似为给定参数集的非线性MPC问题的解决方案,然后使用MPC生成的轨迹计算学习控制器的预期特征。然后,基于梯度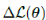 ,改变权重值并重复相同的过程直到收敛。
,改变权重值并重复相同的过程直到收敛。
3 基于模型的人工演示和实施
在本节中,解释了从人工演示中收集的数据。此外,还讨论了提出的IOC方法的实施。
A. 人工演示数据
为了实施基于学习的控制方法,使用模拟器收集人体演示数据。对于车辆,非线性动力学模型可用于有效模拟其运动[17],[18]。14自由度车辆动力学模型用于捕捉车辆的动态行为。此外,使用 3D 模拟环境“Unreal Engine”来渲染环境。车辆模型实现和环境仿真均在MATLAB-Simulink中进行。罗技G290转向踏板系统用于在模拟环境中驱动车辆,同时通过虚幻引擎和车辆动力学模型之间的通信收集所需的数据。图2显示了数据收集流的软件架构。
收集了10位人类驾驶员的数据,用于评估所提出方法的有效性。图3显示了硬件设置和虚幻引擎中环境渲染的快照。最初要求所有驾驶员熟悉驾驶控制器和环境,以了解他们对模拟环境的反应。行驶10分钟后,要求驾驶员在三种特定路况下行驶,同时保持车速在30~35km/h之间。有不同类型曲线组成的选定路径轮廓,对于每条道路,记录了每个驾驶员的5次试验。在三个驾驶场景中,两个场景用于学习成本函数参数,一个场景用于测试控制器的性能。
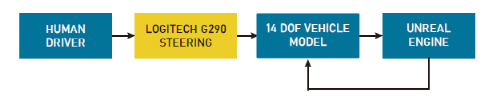
图2 数据采集系统架构

图3 用于人工演示的虚幻引擎中的驾驶控制器和环境渲染
B.从人工演示中学习成本函数
对于收集到的属于驾驶员的数据集,使用以下公式计算特征值
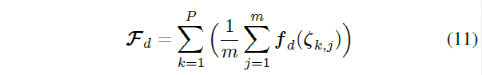
其中,m 是每个驾驶场景的试验次数,P 是驾驶场景的总数。对于所有驾驶场景,参考位置为车道的中心。
为了学习权重参数θ,车辆被设置为每个驾驶场景的起点。随机选择一组初始的权重参数(θ)数值,然后使用 MPC 控制器在所有道路上驾驶车辆。驾驶场景完成后,控制器生成的轨迹的预期特征由下式计算
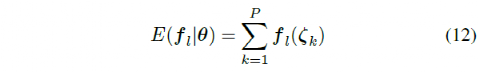
基于此控制器的预期特征和人工演示,优化的梯度可以计算为
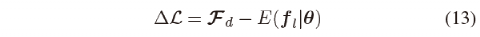
使用此梯度更新θ的值,并继续该过程直到收敛。
C. 轨迹跟踪控制器
从IOC算法中找到的学习权重用于MPC的成本函数,以执行自动驾驶汽车的路径跟踪任务。II-A中描述的MPC公式用于模拟控制器的性能。我们之前的工作中可以找更多MPC实现的细节[19]。对于MPC控制器,使用预测范围 Np = 5 和控制范围 Np = 5。非线性优化问题使用“Ipopt”包和开源优化工具“CasAdi”[20]来解决。
4 结果与讨论
权重参数利用两种驾驶场景学习得到。第三个是测试驾驶场景,用于评估控制器的性能。图4显示了控制器和人工驾驶在训练驾驶场景中计算特征的性能比较。图5显示了测试驾驶场景的相同比较。可以如期观察到,图4中特征值更接近相应的人类演示。从图5的结果来看,学习到的控制器显示出适当的泛化能力,因此它可以用于其他环境。图6描绘了人类驾驶轨迹和由学习控制器生成的用于测试驾驶场景的轨迹。从该图中可以看出,学习到的控制器不仅能够遵循参考轨迹,还能够学习人类驾驶的所需特征并在生成适当的控制动作的同时实施它们。
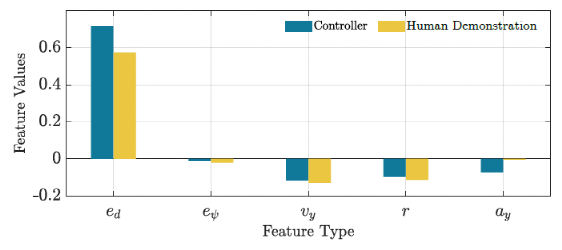
图4 训练驾驶场景的人工演示和控制器功能的比较
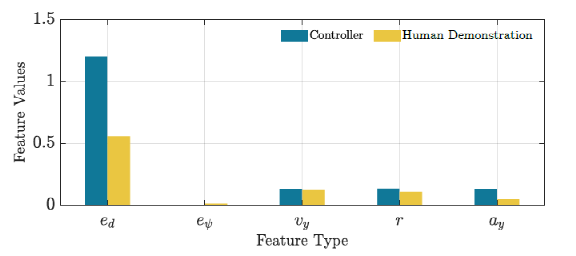
图5 测试驾驶场景的人工演示和控制器功能的比较
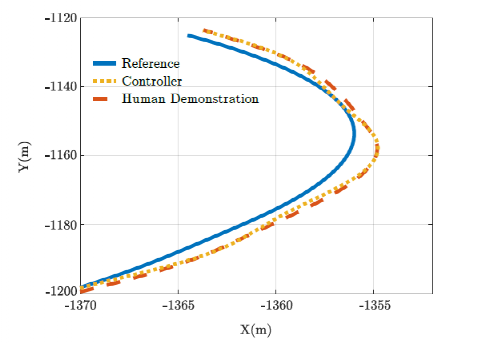
图6 试驾场景中人工演示和控制器轨迹的比较
我们在基于学习的 MPC 的初步实现的研究中做了几个假设。首先,前向速度保持在人类演示的小范围内(30-35km/h)。对于训练,收集的数据未考虑速度小于30km/h的情景。类似地,为了进行权重的学习,模拟的车辆速度保持恒定在每个特定驾驶场景的人工演示的平均速度上。此外,训练和测试场景仅包含不同曲率的路径。我们未来的计划是进行更严格的训练,以使用这种方法评估学习控制器的泛化特性。
5 总结
模型预测控制 (MPC) 是一种用于设计自动驾驶汽车路径跟踪控制器的有效控制技术。该技术实施了一个优化步骤,可以处理多个目标并适应执行器和车辆状态的物理限制,以确保安全和其他所需的行为。从人工演示中学习成本函数被认为是避免对 MPC 进行大量参数调整的有吸引力的选择。最重要的是,它使控制器能够进行调整,以提供对人类更自然的控制动作。为了学习成本函数或成本函数的一些参数,已经提出了逆最优控制(IOC)和逆强化学习(IRL)方案。
在本文中,我们提出了一种创新的 IOC 算法,以使用从人类演示中收集的数据为控制任务学习合适的成本函数。目标是设计一个控制器,该控制器生成的运动与人类产生的运动的特定特征相匹配。这些特征包括横向加速度、横向速度、与车道中心的距离和偏航率。为了实现此功能,成本函数的参数是从人工演示数据中学习的。然后使用这些参数来实现用于自动驾驶车辆路径跟踪的 MPC 控制器。针对训练和测试驾驶场景,展示了控制器和人类驾驶对计算特征的性能比较。正如预期的那样,观察到训练场景中的特征值更接近相应的人工演示。学习到的控制器表现出适当的泛化能力,因此可以在不同的环境中使用。还观察到,学习到的控制器不仅能够学习人类驾驶的期望特征,而且能够遵循参考轨迹。未来的计划是使用实际驾驶场景进行更严格的训练,并使用这种方法增强学习控制器的泛化特性。
参考文献



本文译自:
《Learning-based Model Predictive Control for Path Tracking Control of Autonomous Vehicle》
文章来源:
2020 IEEE International Conference on Systems, Man, and Cybernetics (SMC)
作者:
Mohammad Rokonuzzaman, Navid Mohajer, Saeid Nahavandi, Shady Mohamed
原文链接:
https://ieeexplore.ieee.org/document/9283293
摘要:自动驾驶汽车的路径跟踪控制器在改善车辆的动态行为方面起着重要作用。模型预测控制 (MPC) 是最强大的控制器之一,可以处理多个优化目标,并适应执行器和车辆状态的物理限制,以确保安全和其他所需行为。作为一种高潜力的解决方案,可以将人工演示的学习成本函数集成到 MPC 中。通过从人工演示中学习成本函数,可以避免大量参数调整,更重要的是,可以调整控制器以提供对人类更自然的所需控制动作。在本研究中,提出了一种创新的逆最优控制 (IOC) 算法,以使用从人工演示中收集的数据为控制任务学习合适的成本函数。目标是设计一种控制器,该控制器生成的运动与人类产生的运动的特定特征相匹配。这些特征包括侧向加速度、侧向速度和偏离车道中心。从结果中可以看出,设计的控制器能够学习人类驾驶的所需特征并在生成适当的控制动作的同时实现它们。
关键词:自动驾驶汽车,路径跟踪控制器,模型预测控制,逆最优控制
1 引言
模型预测控制(MPC)被认为是设计自动驾驶汽车路径跟踪控制器的合适框架。该技术在每个时间步解决一个优化问题,并且可以同时处理多个目标。此外,它可以适应执行器和车辆状态的物理限制,以确保安全和其他所需的行为。为了为自动驾驶汽车制定有效的模型预测控制,应该定义适当的成本函数。成本函数的设计往往取决于设计者的经验和精通程度。当乘客的感觉被考虑到车辆性能中时,设计成本函数会更加复杂。
从客观的角度来看,可以通过改善自动驾驶汽车的操控行为来提高人类的舒适度和安全性[1]、[2]。这种考虑是对传统车辆乘坐舒适性的补充,其主要取决于车辆的振动特性[3]-[5]。从主观角度看,舒适度取决于人的感觉,难以表述为一组成本函数。作为一种高潜力的解决方案,从人工演示中学习成本函数一直是研究人员的一个有吸引力的选择。
为了学习成本函数或成本函数的一些参数,许多研究人员提出了逆最优控制(IOC)。在这种方法中,对于未知的成本函数,专家演示通常用作最优控制问题的解决方案[6]。考虑 IOC 环境下的 MPC 问题,对于成本函数的未知参数,可以将演示输入视为最优输入序列。给定演示数据和参数成本函数,初步概述了参数控制的最优条件。此外,IOC 问题可以定义为一种搜索算法,用于寻找满足最佳条件的合适参数值[7]。
从演示中估计成本函数的另一种方法是使用逆强化学习 (IRL)。在某些情况下,IOC 和 IRL 被互相定义为相同的方法。在 IRL 的背景下,使用诸如马尔可夫决策过程 (MDP) 之类的概率方法从已证明的最佳行为中提取奖励函数[8]、[9]。在 MDP 方法中,特别是对于强化学习 (RL) 的情况,假设成本函数是已知的。然而,如前所述,为 RL 设计合适的成本函数同样困难。IRL 已被用于模仿学习(有时称为学徒学习),其目标是找到一种控制策略,该策略在未知奖励函数的情况下能表现得和演示者一样好[9]。
许多不同类型的系统提出了IRL和IOC,例如类人机器人[10]、直升机控制[11]和特定驾驶风格的复制[12]。在[10]中,IRL被提出来寻找奖励函数,以使用来自人工演示的数据来设计仿人机器人更自然和动态的运行行为。从模拟结果来看,学习到的奖励函数显示出可用于不同环境的良好泛化特性。即使优化问题是离线解决的,学习到的奖励函数也可以很容易地集成到在线 MPC 算法中。类似地,在[13]中,IOC 被实现为类人运动控制。但是,在这种情况下,没有考虑每个关节的运动;相反,类人机器人的位置和方向用于使用双层优化问题来描述运动。高层控制迭代代价函数的权重,并试图最小化测量数据与从低层控制收集的最优控制的解之间的距离。
在自动驾驶的背景下,IRL 已被提出用于预测人类意图。例如,它用于对人类行为进行建模,推断人类驾驶员的路线偏好[14]。类似地,在[15]中,IRL用于预测驾驶员在道路上的意图。人类驾驶员的运动被表述为一个优化问题,并使用IRL找到奖励函数。在[12]中,IRL也被用于在生成自动驾驶汽车跟随的轨迹时复制个人驾驶风格。在这项工作中,最大熵IRL[14]用于解决自动驾驶的路径规划问题。此外,成本函数以类似于[9]的方式近似为特征的线性组合。IRL的最终目标是为成本函数的每个特征找到合适的权重,最终用于为车辆生成优化轨迹。
尽管 IOC 和 IRL 已针对上述不同应用实现,但据我们所知,这些技术尚未用于自动驾驶汽车的路径跟踪控制器。考虑到可以通过提高车辆的操纵性能来提高乘客的舒适度,基于人工演示数据的基于学习的 MPC 有可能适应这种措施,从而提高乘客的舒适度。在本文中,我们建议将 IOC 用于基于学习的 MPC,用于自动驾驶汽车的路径跟踪任务。为了实现此功能,设计了一种新颖的基于特征的 MPC 参数成本函数。此外,提出了一种创新的 IOC 算法,以使用从人工演示中收集的数据来学习 MPC 的合适成本函数参数。数据是使用集成的3D模拟环境“虚幻引擎”和 Matlab-Simulink 平台收集的。目标是设计一个控制器,产生与人类产生的运动的特定特征相匹配的运动。这些特征包括横向加速度、横向速度、与车道中心的距离和偏航率。成本函数的参数是从人工演示数据中学习的。然后使用这些参数来实现自动驾驶汽车的 MPC 控制器。
本文的其余部分组织如下。在第Ⅱ节中,介绍了人工演示学习成本函数背后的理论框架。详细解释了MPC的制定、成本函数的定义和IOC的方法论。第Ⅲ节概述了从人工演示中收集数据的实验,以及从收集的数据中学习成本函数所采取的步骤,以及在路径跟踪控制器中应用学习到的参数。在第Ⅳ节和第Ⅴ节中,展示并进一步讨论了结果,并给出了研究的结论。
2 从人工演示中学习成本函数
本工作的主要目标是使用从人工演示中收集的数据为路径跟踪任务找到合适的成本函数。道路路径剖面对自动驾驶汽车的操控行为有显着影响[16];在本工作中,对于给定的参考路径,人工演示的轨迹被认为是最佳解决方案。此外,假设存在与人类驾驶员生成的轨迹相关联的成本函数。目标是找到成本函数的适当参数,该参数捕获个人人类驾驶任务的选定特征。在本节中,首先讨论 MPC 控制器的公式。然后,建立了基于特征的 MPC 成本函数的设计。最后,详细阐述了 IOC 的设计。
A. 模型预测控制
在 MPC 中,基于车辆的过渡模型计算车辆在特定范围内的未来状态。在每个时间步,求解非线性优化问题以生成最小化成本函数的控制动作。在优化后的控制序列中,只有第一个控制动作被发送到车辆,接下来的时间间隔内重复整个过程。MPC控制器的主要优点之一是可以处理多个目标。此外,由于它解决了约束优化问题,因此可以约束车辆的状态(例如转向角)以匹配物理限制。对于本工作,考虑车辆状态六χ=[X,Y,ψ,vy, r, ay]被考虑,其中X和Y是车辆在全局坐标系中的位置,ψ是偏航角,r是偏航率,vy是纵向速度,ay是纵向加速度。对于这些车辆状态和转向角输入u=δ ,车辆过渡模型可以表示为
基于学习的控制器的成本函数可以用参数形式表示并更新以提高控制器的性能,即复制人工演示。带有参数成本函数的MPC问题可以表示为
其中,g(χk,uk)表示状态和输入约束,θ表示成本函数的参数向量。解决这个优化问题,找到一个优化的控制序列 U* = [uk*....uk+N*] 并且在每个时间步只将序列的第一个控制动作发送到车辆。在接下来的时间间隔内重复此过程。
B. 成本函数
改进的自动驾驶汽车路径跟踪控制器应适应准确和安全的路径跟踪,同时生成控制动作,提供对人更自然的运动。此处考虑了参数成本函数,并使用基于特征的学习技术来找到产生与人类驾驶员相似特征的参数的最佳值。对于人工演示或控制器生成的每个轨迹,以下特征用于设计参数成本函数。
a)车道中心距离:该特征表示车辆与车道中心的偏差,可以表示为
其中t为时间,χc(t)=[X, Y]是t时刻车辆在道路上的位置,p(t)=[Xref, Yref]是车道中心距离车辆位置最近的道路点,N是轨迹中的样本数。
b)与路径的偏离角:车辆横摆角与路径角的偏离由该特征表示。
其中,χψ为车辆航向角,pψ为路径角度。
c)横向速度:另一个需要与人工演示进行比较的特征是车辆的横向速度,它表示为
d)偏航率:对于路径跟踪任务,偏航率是影响乘客舒适度的重要特征。此特征可以由下式计算得到
e)横向加速度:对乘客舒适度有显着影响的最重要特征之一是车辆的横向加速度。该特征计算为
最后,利用这些特征,路径跟踪任务的成本函数表示为
其中,θ为是需要从人工演示中学习的参数或权重向量,以便使用 MPC 生成的运动与人工演示中的特征相匹配。
C. 逆最优控制
在一般最优控制问题中,目标是找到基于某些特定准则的控制动作或策略。这些准则通常使用提供选择动作的成本的成本函数来表达。然而,设计一个合适的成本函数很困难,而且通常需要大量的时间进行调整。在 IOC 方法中,目标是基于用户演示找到合适的成本函数,而不是找到最优策略。然后可以使用该成本函数来生成最优策略。图1显示了 IOC 过程的一般示意图。IOC 和 IRL 技术可以互换使用,因为它们描述了类似的方法。
在此过程中,重要的是设计适当的成本函数,明确解决设计偏好和目标。例如,对于自动驾驶的复杂任务,调整成本函数的不同参数以获得优选性能并不简单。在这方面,IOC提供了一个合适的选项,可以根据从人工演示收集的数据来调整成本函数。
图1 IOC过程示意图
人工演示数据集D=
其中,
其中,fl是由控制器为一组固定参数值θ生成的轨迹的特征向量。使用
3 基于模型的人工演示和实施
在本节中,解释了从人工演示中收集的数据。此外,还讨论了提出的IOC方法的实施。
A. 人工演示数据
为了实施基于学习的控制方法,使用模拟器收集人体演示数据。对于车辆,非线性动力学模型可用于有效模拟其运动[17],[18]。14自由度车辆动力学模型用于捕捉车辆的动态行为。此外,使用 3D 模拟环境“Unreal Engine”来渲染环境。车辆模型实现和环境仿真均在MATLAB-Simulink中进行。罗技G290转向踏板系统用于在模拟环境中驱动车辆,同时通过虚幻引擎和车辆动力学模型之间的通信收集所需的数据。图2显示了数据收集流的软件架构。
收集了10位人类驾驶员的数据,用于评估所提出方法的有效性。图3显示了硬件设置和虚幻引擎中环境渲染的快照。最初要求所有驾驶员熟悉驾驶控制器和环境,以了解他们对模拟环境的反应。行驶10分钟后,要求驾驶员在三种特定路况下行驶,同时保持车速在30~35km/h之间。有不同类型曲线组成的选定路径轮廓,对于每条道路,记录了每个驾驶员的5次试验。在三个驾驶场景中,两个场景用于学习成本函数参数,一个场景用于测试控制器的性能。
图2 数据采集系统架构
图3 用于人工演示的虚幻引擎中的驾驶控制器和环境渲染
B.从人工演示中学习成本函数
对于收集到的属于驾驶员的数据集,使用以下公式计算特征值
其中,m 是每个驾驶场景的试验次数,P 是驾驶场景的总数。对于所有驾驶场景,参考位置为车道的中心。
为了学习权重参数θ,车辆被设置为每个驾驶场景的起点。随机选择一组初始的权重参数(θ)数值,然后使用 MPC 控制器在所有道路上驾驶车辆。驾驶场景完成后,控制器生成的轨迹的预期特征由下式计算
基于此控制器的预期特征和人工演示,优化的梯度可以计算为
使用此梯度更新θ的值,并继续该过程直到收敛。
C. 轨迹跟踪控制器
从IOC算法中找到的学习权重用于MPC的成本函数,以执行自动驾驶汽车的路径跟踪任务。II-A中描述的MPC公式用于模拟控制器的性能。我们之前的工作中可以找更多MPC实现的细节[19]。对于MPC控制器,使用预测范围 Np = 5 和控制范围 Np = 5。非线性优化问题使用“Ipopt”包和开源优化工具“CasAdi”[20]来解决。
4 结果与讨论
权重参数利用两种驾驶场景学习得到。第三个是测试驾驶场景,用于评估控制器的性能。图4显示了控制器和人工驾驶在训练驾驶场景中计算特征的性能比较。图5显示了测试驾驶场景的相同比较。可以如期观察到,图4中特征值更接近相应的人类演示。从图5的结果来看,学习到的控制器显示出适当的泛化能力,因此它可以用于其他环境。图6描绘了人类驾驶轨迹和由学习控制器生成的用于测试驾驶场景的轨迹。从该图中可以看出,学习到的控制器不仅能够遵循参考轨迹,还能够学习人类驾驶的所需特征并在生成适当的控制动作的同时实施它们。
图4 训练驾驶场景的人工演示和控制器功能的比较
图5 测试驾驶场景的人工演示和控制器功能的比较
图6 试驾场景中人工演示和控制器轨迹的比较
我们在基于学习的 MPC 的初步实现的研究中做了几个假设。首先,前向速度保持在人类演示的小范围内(30-35km/h)。对于训练,收集的数据未考虑速度小于30km/h的情景。类似地,为了进行权重的学习,模拟的车辆速度保持恒定在每个特定驾驶场景的人工演示的平均速度上。此外,训练和测试场景仅包含不同曲率的路径。我们未来的计划是进行更严格的训练,以使用这种方法评估学习控制器的泛化特性。
5 总结
模型预测控制 (MPC) 是一种用于设计自动驾驶汽车路径跟踪控制器的有效控制技术。该技术实施了一个优化步骤,可以处理多个目标并适应执行器和车辆状态的物理限制,以确保安全和其他所需的行为。从人工演示中学习成本函数被认为是避免对 MPC 进行大量参数调整的有吸引力的选择。最重要的是,它使控制器能够进行调整,以提供对人类更自然的控制动作。为了学习成本函数或成本函数的一些参数,已经提出了逆最优控制(IOC)和逆强化学习(IRL)方案。
在本文中,我们提出了一种创新的 IOC 算法,以使用从人类演示中收集的数据为控制任务学习合适的成本函数。目标是设计一个控制器,该控制器生成的运动与人类产生的运动的特定特征相匹配。这些特征包括横向加速度、横向速度、与车道中心的距离和偏航率。为了实现此功能,成本函数的参数是从人工演示数据中学习的。然后使用这些参数来实现用于自动驾驶车辆路径跟踪的 MPC 控制器。针对训练和测试驾驶场景,展示了控制器和人类驾驶对计算特征的性能比较。正如预期的那样,观察到训练场景中的特征值更接近相应的人工演示。学习到的控制器表现出适当的泛化能力,因此可以在不同的环境中使用。还观察到,学习到的控制器不仅能够学习人类驾驶的期望特征,而且能够遵循参考轨迹。未来的计划是使用实际驾驶场景进行更严格的训练,并使用这种方法增强学习控制器的泛化特性。
参考文献



编辑推荐




最新资讯
-
中汽中心工程院能量流测试设备上线全新专家
2025-04-03 08:46
-
上新|AutoHawk Extreme 横空出世-新一代实
2025-04-03 08:42
-
「智能座椅」东风日产N7为何敢称“百万级大
2025-04-03 08:31
-
基于加速度计补偿的俯仰角和路面坡度角估计
2025-04-03 08:30
-
《北京市自动驾驶汽车条例》正式实施 L3级
2025-04-02 20:23
