




 广告
广告





















































特斯拉、高通、华为AI处理器深度分析
2021-09-12 19:15:05· 来源:佐思汽车研究 作者:周彦武

常见AI加速器的NoC如上表。需要指出高通和华为都用了Arteris,这家公司实际是高通的子公司,高通在2013年11月收购了这家仅有43人的法国小公司,今天中国几乎所有的大中型芯片公司都是其客户,包括瑞芯微、国民技术、华为、全志、炬力、展讯等,可以说都在给高通打工。英特尔在2019年收购了Netspeed,Facebook在2019年收购了Sonics,这两家的NoC使用面远不如高通的Arteris。

图片来源:互联网
每个AI核内部框架如上,主要分4个部分,分别是标量处理、向量处理、存储处理和张量处理。深度学习中经常出现4种量,标量、向量、矩阵和张量。神经网络最基本的数据结构就是向量和矩阵,神经网络的输入是向量,然后通过每个矩阵对向量进行线性变换,再经过激活函数的非线性变换,通过层层计算最终使得损失函数的最小化,完成模型的训练。
标量(scalar):一个标量就是一个单独的数(整数或实数),不同于线性代数中研究的其他大部分对象(通常是多个数的数组)。标量通常用斜体的小写字母来表示,标量就相当于Python中定义的x=1。
向量(Vector),一个向量表示一组有序排列的数,通过次序中的索引我们能够找到每个单独的数,向量通常用粗体的小写字母表示,向量中的每个元素就是一个标量,向量相当于Python中的一维数组。
矩阵(matrix),矩阵是一个二维数组,其中的每一个元素由两个索引来决定,矩阵通常用加粗斜体的大写字母表示,我们可以将矩阵看作是一个二维的数据表,矩阵的每一行表示一个对象,每一列表示一个特征。
张量(Tensor),超过二维的数组,一般来说,一个数组中的元素分布在若干维坐标的规则网格中,被称为张量。如果一个张量是三维数组,那么我们就需要三个索引来决定元素的位置,张量通常用加粗的大写字母表示。
不太严谨地说,标量是0维空间中的一个点,向量是一维空间中的一条线,矩阵是二维空间的一个面,三维张量是三维空间中的一个体。也就是说,向量是由标量组成的,矩阵是向量组成的,张量是矩阵组成的。
标量运算部分可以看作一个小CPU,控制整个AI Core的运行。标量计算单元可以对程序中的循环进行控制,可以实现分支判断,其结果可以通过在事件同步模块中插入同步符的方式来控制AI Core中其它功能性单元的执行流水。它还为矩阵计算单元或向量计算单元提供数据地址和相关参数的计算,并且能够实现基本的算术运算。复杂度较高的标量运算如数据流量控制则由专门的AI CPU通过算子完成,AI处理器是无法单独工作的,必须要外置的CPU给予配合。
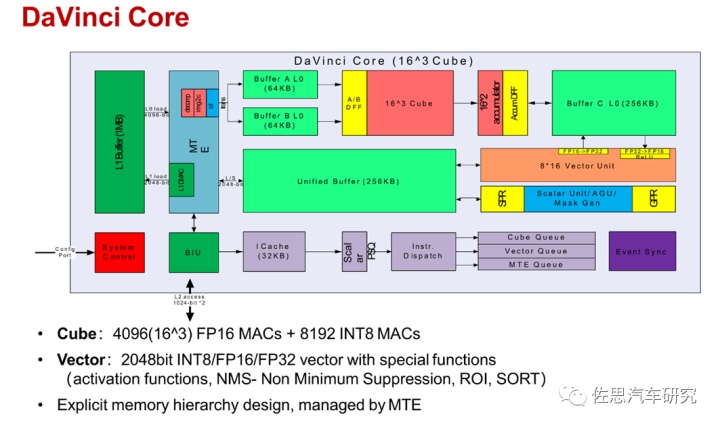
华为昇腾系列内核架构。图片来源:互联网
华为的昇腾910即Davinci Max,和高通AI100一样,也是8192个Int8,4096个FP16。不过昇腾910是训练用的,高通AI100是推理用的,但910不计成本使用HBM2代存储,性能远超AI100。

图片来源:互联网
上图为特斯拉FSD信号内部流转,相干流量即深度学习的数据流量需要CPU控制,当然也不只是为深度学习服务。
图像识别深度学习中运算量最大的卷积部分实际就是矩阵的乘和累加。可以分解为1维的标量或者叫算子(即权重)与2维的向量即输入图像乘和累加。
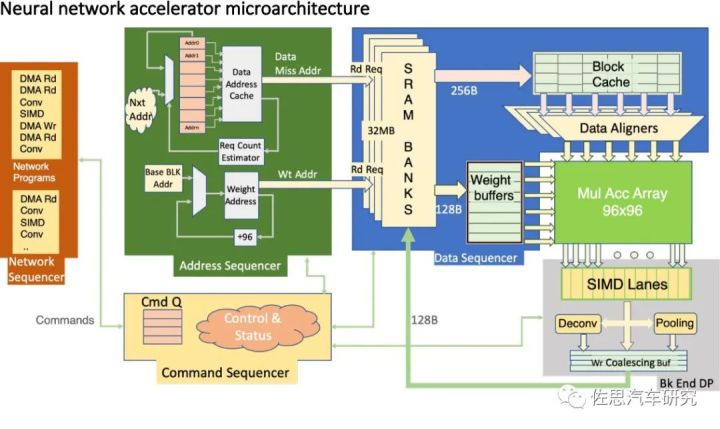
图片来源:互联网
上图为特斯拉FSD神经网络架构,特斯拉把矩阵的乘和累加简单写成了MulAccArray。特斯拉做芯片刚刚入门,FSD上除了NPU是自己做的外,其余都是对外采购的IP。NPU方面,主要就是堆砌MAC乘和累加单元,在稍微有技术含量的标量计算领域,特斯拉没有公布采用何种指令集,应该是没什么特色。华为和高通都是采用了VLIW。
高通的向量处理器可以简单看作一个DSP。众所周知,高通的AI技术来源于其DSP技术,高通对DSP非常青睐,而已经失去生命力的VLIW超长指令集非常适合用在深度学习上,深度学习运算算法非常单一且密集度极高,并不需要通用场景下的实时控制。并且其程序运行有严格的时间要求,cache这种不可控时间的结构就不适合了,通常采用固定周期的TCM作为缓存,这样内存访问时间就固定了。有了上述的特征,静态编译在通用场合下面临的那些困难就不存在了,而DSP其更高效的并行运算能力和简化的硬件结构被完全发挥出来。
AI100为了考虑多种应用场合,有FP16和Int8两种精度阵列,Int8即8位整数精度是智能驾驶领域最常见的,FP16则是游戏、AR/VR领域常用的。Int8有8192个,FP16有4096,特斯拉则是9216个Int8阵列,如果AI100只考虑智能驾驶,在总面积(差不多可等同于成本)不变的情况下算力还可以再提高不少。
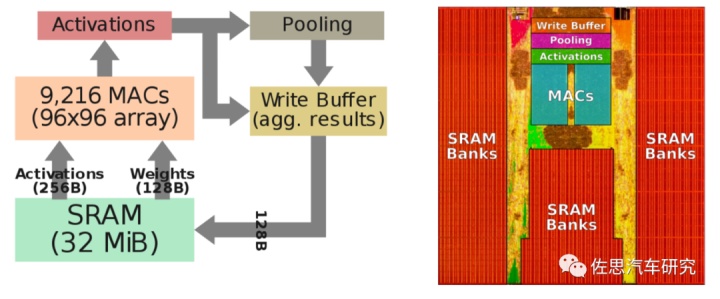
图片来源:互联网
上图为特斯拉NPU部分流程与裸晶分布,算力理论峰值只是根据MAC数量简单计算得出,实际存储器是瓶颈,存储器能让算力大打折扣,这也是为什么训练用AI芯片都不惜成本用HBM内存的原因。特斯拉的芯片上,大部分都给了SRAM,也是为了解决存储器瓶颈问题。这里常见到两个单位,GiB和GB,GB是十进制,GiB是二进制,1GiB=(1024*1024*1024)B=1073741824B,1GB=(1000*1000*1000)B=1000000000B,1GiB/1GB=1073741824/1000000000=1.073741824。要求精度不高的话,可以直接替换,高通AI100有144MB的片上存储,特斯拉只有32MiB,高通显然可以碾压特斯拉的,此外外围的LPDDR4存储上,高通也是碾压特斯拉,特斯拉带宽只有63.58 GiB/s,高通AI100是136GB/s。
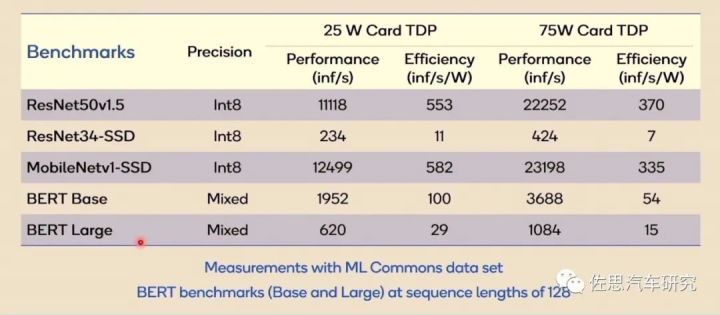
图片来源:互联网
最后说算力,AI处理器对比似乎离不开算力对比,实际单独讲算力数据毫无意义,上图是高通AI100在五个数据集上的表现,我们可以看到性能与效率差别巨大,AI算力越强,其适用面就越窄,与深度学习模型的捆绑程度就越高,换句话说,AI芯片只能在与其匹配的深度学习模型上才能发挥最大性能,换一个模型,可能只能发挥芯片10%的性能,所有AI芯片目前的算力数据都是理论峰值数据,实际应用中都无法达到理论峰值,某些情况下,可能只有峰值算力的10%甚至2%。100TOPS的算力可能会萎缩到2TOPS。







