




 广告
广告





















































特斯拉、高通、华为AI处理器深度分析
2021-09-12 19:15:05· 来源:佐思汽车研究 作者:周彦武

很多人会问,为什么没有英伟达?目前所有主流深度学习运算主流框架后端都是英伟达的CUDA,包括TensorFlow、Caffe、Caffe2、PyTorch、mxnet、PaddlePaddle,CUDA
很多人会问,为什么没有英伟达?目前所有主流深度学习运算主流框架后端都是英伟达的CUDA,包括TensorFlow、Caffe、Caffe2、PyTorch、mxnet、PaddlePaddle,CUDA包括微架构和指令集以及并行计算引擎。CUDA垄断了深度学习或者也可以说垄断了人工智能,这一点类似ARM的微架构和指令集。CUDA强大的生态系统,造就了英伟达牢不可破的霸主地位。深度学习的理论基础在上世纪五十年代就已经齐备,无法应用的关键就是缺乏像GPU这样的密集简单运算设备,是英伟达的GPU开创了人类的深度学习时代,或者说人工智能时代,CUDA强化了英伟达的地位。你可以不用英伟达的GPU,但必须转换格式来适应CUDA。
CUDA开启了并行计算或多核运算时代,今天人工智能用的所有加速器都是多核或众核处理器,几乎都离不开CUDA。CUDA程序构架分为两部分:Host和Device。一般而言,Host指的是CPU,Device指的是GPU或者叫AI加速器。在CUDA程序构架中,主程序还是由CPU 来执行,而当遇到数据并行处理的部分,CUDA 就会将程序编译成 GPU能执行的程序,并传送到GPU。而这个程序在CUDA里称做核(kernel)。CUDA允许程序员定义称为核的C语言函数,从而扩展了C语言,在调用此类函数时,它将由N个不同的CUDA线程并行执行N次,这与普通的C语言函数只执行一次的方式不同。执行核的每个线程都会被分配一个独特的线程ID,可通过内置的threadIdx变量在内核中访问此ID。在 CUDA 程序中,主程序在调用任何 GPU内核之前,必须对核进行执行配置,即确定线程块数和每个线程块中的线程数以及共享内存大小。你可以不用英伟达的GPU,但最终都离不开CUDA,也就是需要转换成CUDA格式,这就意味着效率的下降。所以英伟达是参考级的存在。
从CUDA的特性我们不难看出,单独的AI加速器是无法使用的。今天我们分析三款可用于智能驾驶领域的AI加速器,分别是高通的AI100,华为的昇腾,特斯拉的FSD。这其中高通AI100比较少见。
高通AI100最早于2019年4月在深圳的高通AI开放日露面,2020年9月量产。AI100是高通目前唯一的AI推理运算加速器,定位四个方面的应用:一是数据中心的边缘计算,二是5G行动边缘计算,三是智能驾驶与智能交通,四是5G基础设施。AI100有两个侧重点:一是5G游戏,AI100发布当天邀请了VIVO手机、腾讯王者荣耀开发团队利用AI100现场开了一场电玩竞赛,即把部分运算放到5G边缘服务器上,减轻手机端的负载。二是智能交通和智能驾驶,高通自动驾驶Ride平台的AI加速器很有可能就是AI100的车规翻版。

图片来源:互联网
高通特别展示了AI100在智能交通/智能驾驶领域的应用。

图片来源:互联网
同时支持24路200万像素帧率25Hz的图像识别,特斯拉的FSD不过是同时8路130万像素帧率30Hz的图像识别,性能至少是特斯拉FSD的3倍。
AI100可以像刀片服务器那样应用,用PCIe交换机最多16个级联。

图片来源:互联网
最高每瓦有12.37TOPs的算力,特斯拉FSD是36瓦的功耗,AI部分估计大约为24瓦,每瓦只有大约3TOPs每瓦的算力,英伟达的Orin大致为5.2TOPs每瓦的算力。
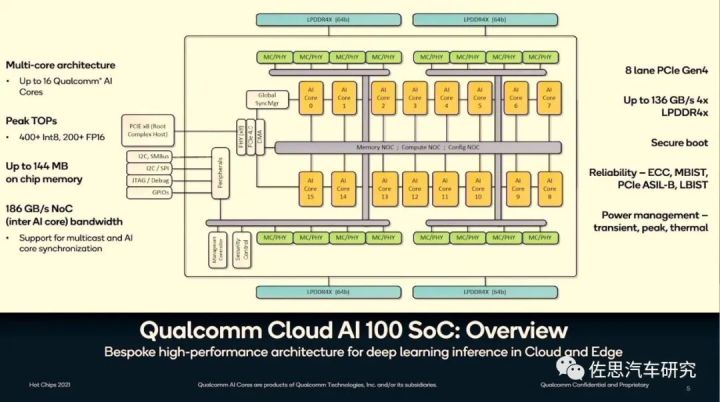
图片来源:互联网
上图为高通AI100内部框架图。设计很简洁,16个AI核,内核与内核之间是第四代PCIe连接,带宽有186GB/s,8通道的PCIe网络,然后再与各种片上网络(NoC),包括存储NoC、运算NoC和配置NoC通过PCIe总线连接。片上存储器容量高达144MB,带宽136GB/s。外围存储器为256Gb的LPDDR4。支持汽车行业的ISO26262安全标准,即ASIL,达到B级。
NoC是多核AI处理器的核心技术之一,特斯拉FSD只有两个NPU,很可能用不到NoC而用比较落后的总线技术,不过高通和华为都用到了。
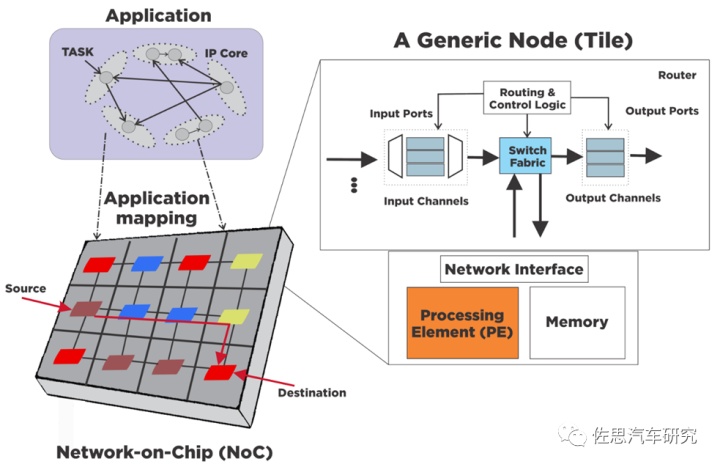
图片来源:互联网
NoC的详细理论就不说了,可以理解为一个运行在PE与存储之间的通讯网络。NoC技术和网络通信中的OSI(Open System Interconnection)技术有很多相似之处,NoC技术的提出也是因为借鉴了并行计算机的互联网络和以太网络的分层思想,二者的相同点有:支持包交换、路由协议、任务调度、可扩展等。NoC更关注交换电路和缓存器的面积占用,在设计时主要考量的方面也是这些。NoC的基本组成为:IP核、路由器、网络适配器以及网络链路,IP核和路由器位于系统层,网络适配器位于网络适配层。针对NoC的这四个基本组成,也衍生出了许多的研究方向和优化途径。

图片来源:互联网



编辑推荐




最新资讯
-
大卓智能端到端直播实测,16公里复杂路段挑
2025-04-25 17:16
-
《汽车轮胎耐撞击性能试验方法-车辆法》等
2025-04-25 11:45
-
“真实”而精确的能量流测试:电动汽车能效
2025-04-25 11:44
-
GRAS助力中国高校科研升级
2025-04-25 10:25
-
梅赛德斯-AMG使用VI-CarRealTime开发其控制
2025-04-25 10:21
