




 广告
广告





















































一种面向自动驾驶汽车定位的基于深度神经网络的大尺度建图方法
2021-09-14 21:28:08· 来源:同济智能汽车研究所

3 基于LiDAR面向占用栅格地图生成的DNN
首先,应该注意OGM是用于推断地图上每个单元格的占用概率。每个单元格的占用概率可以假设为一个介于0和1之间的连续值,因此可以用来将单元格分类为空闲或已占用单元格。
A. NeuralMapper子系统
NeuralMapper(图1)是一个子系统,它接收IARA的LiDAR传感器数据作为输入,并生成汽车周围的占用栅格地图作为输出。NeuralMapper的输入数据遵循Caltagirone等人[11]所使用格式。首先,每个LiDAR点云在LiDAR参考系中从球面坐标转换为二维笛卡尔坐标。同Caltagirone等人[11]一样,从二维坐标矩阵计算五个统计矩阵,并在0和1之间进行归一化。这五个归一化统计矩阵组合成一个五通道张量,用作网络的输入。所考虑的统计数据是落入单元格的激光射线数量、最大/最小/平均/标准高度。
为了使FCN[11]输出适应IARA的地图,确定网络应返回三个类别的概率图:Occupied、Free和Unknown。因此,神经网络将使输出结果与IARA子系统中广泛采用的概率方法兼容(图1)。
通过这种方式,网络的输出是一个占用栅格地图,每个输出神经元(单元格)三个类中的每一个都具有相应的概率。该地图被转换至汽车参考系并发布到其他IARA的子系统。输出神经元概率按照如下规则转换为占用概率。如果最可能的类别是Unknown,则地图单元格接收值-1,否则类别Unknown的概率为零,并且其他两个类别的概率被归一化,使两者之和等于1。该代码作为IARA的模块可在https://github.com/LCAD-UFES/carmen_lcad获得。
B. 深度神经网络架构
图1显示了FCN的一般架构,它分为三大层,称为编码器、Context Module和解码器。
编码器接收输入并减少输入数据的大小,尝试最大程度地减少信息丢失。为此,两个普通卷积层被使用,它们有3x3大小的卷积核以及使用指数线性单元(ELU)激活函数且步长为1和32的特征映射[19],然后是一个卷积核为2x2步长为 2的最大池化层。
Context Module主要由扩展的卷积层构成。扩展卷积能够增加卷积滤波器的感受野,以增加推断连续地图单元之间连续性的能力。对于障碍物建图,传感器读数在长距离上存在许多不连续性。因此,应用扩展来预测障碍物在更远的地方的延续很有意义,在那里传感器不再非常有效。有8个具有 ELU 激活函数、3x3 卷积核和128个特征图的扩展卷积层。这些层的扩展逐渐增加,因此在最后一层有32x64的扩张。与Caltagirone等人[11]提出的工作不同,本文确定输出地图为正方形,范围为汽车周围60米。因此,每一层使用的扩展具有相同的量级(例如,最后一层具有64x64的膨胀)。
解码器是架构的最后一部分,神经网络处理过的数据通过去池化操作恢复其原始维度。所使用的去池化实现形式[11]保存了在最大池化层中提取的最大值的位置,以便在相同的位置再次插入这些值,同时将其他值设置为零。解码器继续使用另外两个具有3x3卷积核、步长为1、具有32个特征映射的普通卷积层和具有3个通道输出的最后一层。最后,特征图进入一个log softmax层,它返回一个多维图输出,其中每个维度是每个类的对数概率。因此,如第III.A节所述,通过比较网络输出中每个单元的这三个类中的每一个的概率来构建占用图。
4 实验方法
本节介绍了用于评估所提出系统的方法。首先,描述了实验中使用的数据集,然后是训练神经网络的超参数和程序。之后,本文提出了为定位生成真值的方法以及用于评估神经网络性能和定位精度的指标。
A. 数据集
训练深度神经网络需要大型数据集。首先,可以通过手动标记地图单元格或使用平面图来创建数据集。不过,成本较低的解决方案是借助IARA的离线地图系统从传感器数据日志生成输入和输出对。日志中的所有数据都用于生成环境的 OGM。然后,对于每个LiDAR点云,本文在OGM中裁剪一个以汽车姿态为中心、半径为60m的圆。该裁剪圆被定义为LiDAR点云的输出。
每个单元格考虑三个类:未知、已占用和空闲。由于OGM是概率性的,本文使用软标签而不是独热编码(one-hot encoding)。每个类别的概率由单元格的占用概率给出。图4说明了一个点云及其相关的输出。使用离线地图代替在线OGM的优点如下。首先,由于集成了多个瞬时地图,因此更准确。其次,它提供了更多的占用信息,使神经网络能够学习如何填充传感器未观察到的区域。
实验中使用了从传感器数据日志生成的两个数据集。这些数据集将被称为数据集1和数据集2。数据集记录在相同的环境中,即3.5公里的UFES环城公路,并分成三个不相交的区域,如图3所示。
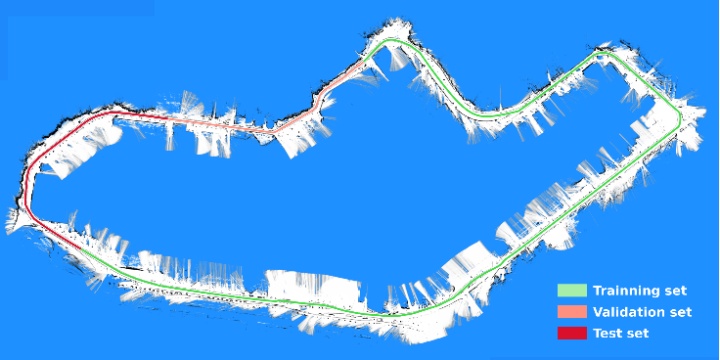
图3 UFES环城公路地图。绿色、橙色和红色分别显示了训练、验证和测试集区域


图4 上图是最大高度统计图,是NeuralMapper的五个输入之一,下图是相应真值。两个图像都经过标准化以进行可视化
数据集1中的区域用于训练、验证和测试神经网络,而数据集2中的所有区域用于测试。请注意,在两个数据集中选择了相同的区域,并且数据集2中的区域之一对应于用于训练神经网络的相同区域。
数据集1是从2016年3月26日黎明收集的日志中提取的。数据集1具有1445次扫描和数据增强后(详细信息在下一节中介绍)共计7228 个样本,这些样本分为74%的训练集、10%的验证集和16%的测试集。日志是在黎明时记录的,以尽量减少移动物体的存在。数据集2是从2019年3月10日记录的日志中提取的。由于日志是在用于构建数据集1的日志三年后捕获的,因此随着时间的推移,它呈现出不同的特征,例如植被生长、新建筑物和道路变化。数据集2也有 1445次扫描和7228个带有数据集增强的样本。
车辆每行驶两米就会生成输入和输出对,以防止网络不同区域的数据不平衡。通过这样做,数据库不再有模拟日志中汽车移动较慢的区域的信息。
B. 训练
DNN 输入由五个关于汽车周围点高度的统计图组成。这些统计图由一个浮点张量表示,其中每个单元格代表一个20x20平方厘米的环境。汽车始终位于地图的中心。激光观察到的每个单元格都会存储最大高度、最小高度、平均高度、高度标准偏差和点数。为此,首先将云中的点进行坐标转换,从球面坐标转换为笛卡尔坐标。然后,位于同一单元格的点被分组并用于计算统计数据。最后,这五个统计维度(最大、最小高度、标准偏差和点数)在0和1之间归一化,并用作网络的输入。
为了对地图进行标准化,在使用高度的统计地图的情况下,上限值是LIDAR的高度位置(在本文案例中为1.86米),对于点数,计算了一个单元格内的最大可能点数(在本文案例中为64)。地图的单元格被初始化为-1,这是最小值。
从图4中可以看出,每张图像中障碍单元格的像素数远小于自由和未知单元格。这种现象导致网络倾向于选择最后两个类别而不是第一个类别。为了避免这种情况,使用了与每批中类的像素数成反比的权重,在计算误差时损失函数乘以权重。这种与不太频繁的类别相关的误差“评估”补偿了它们之间的不平衡[20]。
对于数据增强[21],本文对所有训练图像应用水平翻转和每个方向90度旋转,这将数据集增加了3倍。根据Caltagirone等人的工作[11]选择交叉熵损失函数和 ELU 激活函数,此外还有25%的去除率 神经网络训练了50个epoch,初始学习率为0.0005,每15个epoch的学习衰减率为 0.5。训练是在12GB Nvidia Tesla K40 GPU上进行的。
C. 生成定位真值
定位是自动驾驶汽车导航的重要任务。生成用于评估定位的真值非常具有挑战性。一个简单的想法是使用GPS与定位估计进行比较。然而,虽然全球一致,但GPS数据具有大量噪声,并且GPS测量值不一定与地图一致。
本文生成定位真值的方法类似于文献[4]、[22]和[23]中采用的方法。本文使用文献[3]中描述的GraphSLAM技术,使用来自GPS、里程计和LiDAR(用于处理闭环)的数据来估计车辆的位姿。然后,这些位姿用于使用NeuralMapper构建离线地图,之后定位模块用于估计车辆相对于NeuralMapper的位姿。在GraphSLAM优化的第二步中获得位姿真值。在优化的第二步中,除了来自 GPS、里程计和LiDAR(闭环)的数据外,定位模块输出还用作该方法的输入。通过这样做,本文鼓励在使用传感器数据纠正局部定位错误的同时与地图保持一致。
D. 评价指标
评估训练模型的指标是DNN输出中类别的平均准确率。为每个单元格预测的类别与真值进行比较,并在等式(1)中定义:
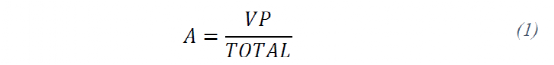
其中VP是正确预测类别的单元格总数,TOTAL是数据库中的单元格总数VP和TOTAL考虑数据库中的所有图像。
在测试期间用于分析结果的另一个指标是混淆矩阵。每个矩阵行代表类别真值,而列代表网络的预测。因此,可以在视觉上检查预测更好或更差的类别。混淆矩阵的值都是每个类别总数的百分比,所有行的总和为每个类别的100%。矩阵的对角线代表网络关于真值的正确性。
此外,本文在自主导航模式下的真实世界环境中,对使用DNN和IARA自动驾驶汽车生成的离线地图进行了定性评估。
用于评估定位的指标与文献[22]和[23]中使用的相同。使用定位估计的位姿
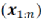
与第IV.C节中描述的获得的位姿真值
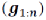
进行了比较。选择的评价指标是由方程(2)给出的均方根误差(RMSE):
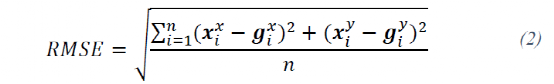
其中







