




 广告
广告





















































一文读懂自动驾驶数据闭环
2021-09-21 18:17:01· 来源:智驾最前沿

2 云计算平台的基建和大数据处理技术
数据闭环需要一个云计算/边缘计算平台和大数据的处理技术,这个不可能在单车或单机实现的。大数据云计算发展多年,在资源管理调度、数据批处理/流处理、工作流管理、分布式计算、系统状态监控和数据库存储等方面提供了数据闭环的基础设施支持,比如亚马逊AWS、微软Azure和谷歌云等。
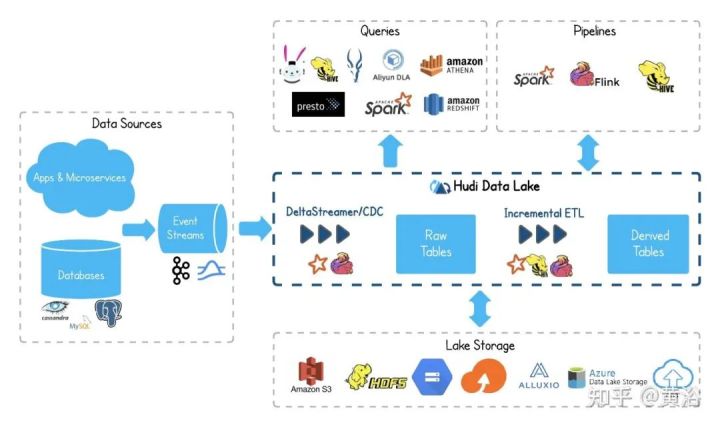
Amazon Elastic Compute Cloud(EC2)是亚马逊云服务AWS的一部分,而Amazon Elastic MapReduce(EMR) 是其大数据云平台,可使用多种开放源代码工具处理大量数据,例如数据流处理Apache Spark、数据仓库Apache Hive和Apache Hbase、数据流处理Apache Flink、数据湖Apache Hudi和大数据分布式SQL查询引擎Presto。
下图是亚马逊云AWS提供的自动驾驶数据处理服务平台例子:其中标明1-10个任务环节

-
使用 AWS Outposts (运行本地 AWS 基础设施和服务)从车队中提取数据以进行本地数据处理。
-
使用 AWS IoT Core (将 IoT 设备连接到 AWS 云,而无需配置或管理服务器)和 Amazon Kinesis Data Firehose (将流数据加载到数据湖、数据存储和分析服务中)实时提取车辆T-box数据,该服务可以捕获和转换流数据并将其传输给 Amazon S3(AWS全球数据存储服务)、Amazon Redshift(用标准 SQL 在数据仓库、运营数据库和数据湖中查询和合并 EB 级结构化和半结构化数据)、Amazon Elasticsearch Service(部署、保护和运行 Elasticsearch,是一种在 Apache Lucene 上构建的开源 RESTful 分布式搜索和分析引擎)、通用 HTTP 终端节点和服务提供商(如 Datadog、New Relic、MongoDB 和 Splunk),这里Amazon Kinesis 提供的功能Data Analytics, 可通过 SQL 或 Apache Flink (开源的统一流处理和批处理框架,其核心是分布流处理数据引擎)的实时处理数据流。
-
删除和转换低质量数据。
-
使用 Apache Airflow (开源工作流管理工具)安排提取、转换和加载 (ETL) 作业。
-
基于 GPS 位置和时间戳,附加天气条件来丰富数据。
-
使用 ASAM OpenSCENARIO (一种驾驶和交通模拟器的动态内容文件格式)提取元数据,并存储在Amazon DynamoDB (NoSQL 数据库服务)和 Amazon Elasticsearch Service中。
-
在 Amazon Neptune (图形数据库服务,用于构建查询以有效地导航高度互连数据集)存储数据序列,并且使用 AWS Glue Data Catalog(管理ETL服务的AWS Glue提供数据目录功能)对数据建立目录。
-
处理驾驶数据并深度验证信号。
-
使用 Amazon SageMaker Ground Truth (构建训练数据集的标记工具用于机器学习,包括 3D 点云、视频、图像和文本)执行自动数据标记,而Amazon SageMaker 整合ML功能集,提供基于 Web 的统一可视化界面,帮助数据科学家和开发人员快速准备、构建、训练和部署高质量的机器学习 (ML) 模型。
-
AWS AppSync 通过处理与 AWS DynamoDB、AWS Lambda(事件驱动、自动管理代码运行资源的计算服务平台) 等数据源之间连接任务来简化数据查询/操作GraphQL API 的开发,在此使用是为特定场景提供搜索功能。
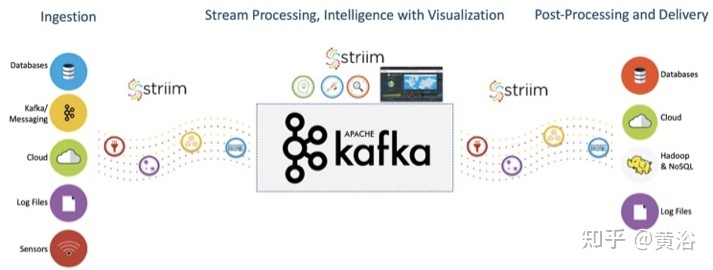
下图是AWS给出的一个自动驾驶数据流水线框架:数据收集、注入和存储、模型训练和部署;其中Snowball是AWS的边缘计算系列之一,负责车辆和AWS S3之间的数据传输;其他还有两个,是AWS Snowcone和 AWS Snowmobile。

可以看到,AWS使用了数据存储S3、数据传输Snowball、数据库DynamoDB、数据流处理Flink和Spark、搜索引擎Elasticsearch、工作流管理Apache Airflow和机器学习开发平台SageMaker等。
其他开源的使用,比如流处理的实时数据馈送平台Apache Kafka、资源管理&调度Apache Mesos和分布NoSQL数据库Apache Cassandra。
如图是国内自动驾驶公司Momenta基于亚马逊AWS建立的系统架构实例图:
其中AWS IoT Greengrass 提供边缘计算及机器学习推理功能,可以实时处理车辆中的本地规则和事件,同时最大限度地降低向云传输数据的成本。
其中P3实例和C5实例是Amazon EC2提供的。Amazon CloudFront是AWS的CDN,Amazon Glacier是在线文件存储服务,而Amazon FSx for Lustre 是可扩展的高性能文件存储系统。
除此之外,亚马逊指出的,Momenta采用的AWS服务还包括:监控可观测性服务Amazon CloudWatch、关系数据库Amazon Relational Database Service (Amazon RDS)、实时流数据处理和分析服务Amazon Kinesis(包括Video Streams、Data Streams、Data Firehose和Data Analytics)和消息队列服务Amazon Simple Queue Service (Amazon SQS)等。
最近Momenta还采用Amazon Elastic Kubernetes Service (EKS) 运行容器Kubernetes。此外亚马逊也推荐了Kubernetes服务,AWS Fargate。
Apache Kafka
Apache Spark
Apache Flink
Apache Hbase
Apache Cassandra
Presto
Apache Hudi
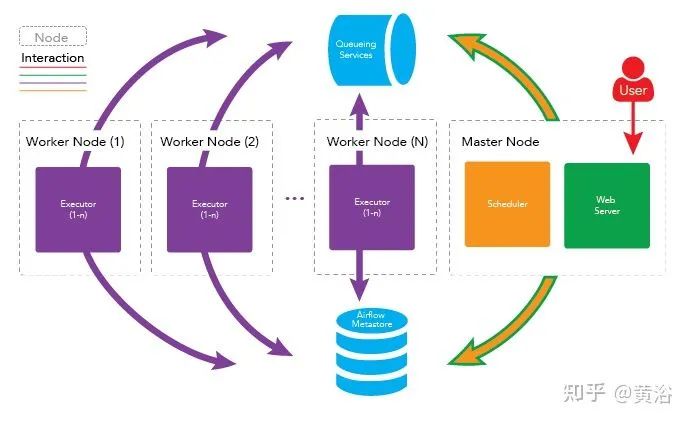
Apache Airflow



编辑推荐




最新资讯
-
大卓智能端到端直播实测,16公里复杂路段挑
2025-04-25 17:16
-
《汽车轮胎耐撞击性能试验方法-车辆法》等
2025-04-25 11:45
-
“真实”而精确的能量流测试:电动汽车能效
2025-04-25 11:44
-
GRAS助力中国高校科研升级
2025-04-25 10:25
-
梅赛德斯-AMG使用VI-CarRealTime开发其控制
2025-04-25 10:21
