




 广告
广告





















































一文读懂自动驾驶数据闭环
2021-09-21 18:17:01· 来源:智驾最前沿

3 训练数据标注工具
其实AWS的机器学习平台本身也提供了数据标注工具Amazon SageMaker Ground Truth。
如图是微软开源标注工具VOTT(Video Object Tagging Tool):
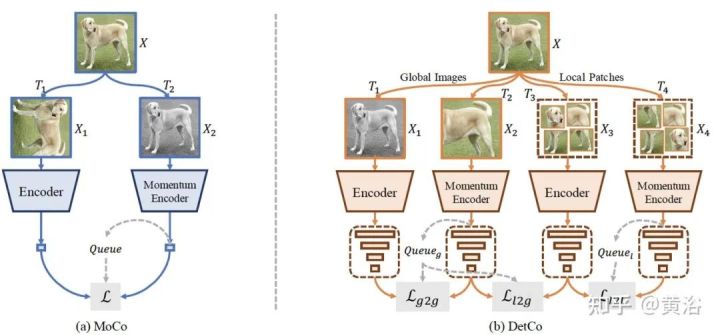
标注工具可以是全自动、半自动和手工等3类。
比如人工标注工具:摄像头图像LabelMe和激光雷达点云PCAT
还有半自动标注工具:摄像头CVAT、VATIC,激光雷达3D BAT、SAnE,图像点云融合Latte
自动标注工具:基本没有开源(商用也没有吧)的工具可用。
这里有一些自动标注方面的论文:
-
“Beat the MTurkers: Automatic Image Labeling from Weak 3D Supervision“
-
“Auto-Annotation of 3D Objects via ImageNet“

-
“Offboard 3D Object Detection from Point Cloud Sequences“
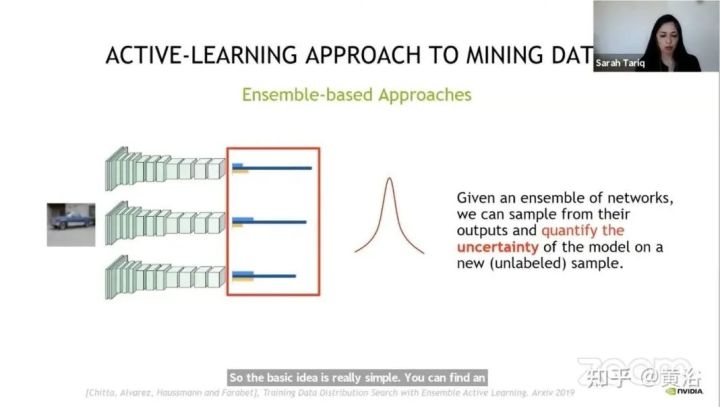
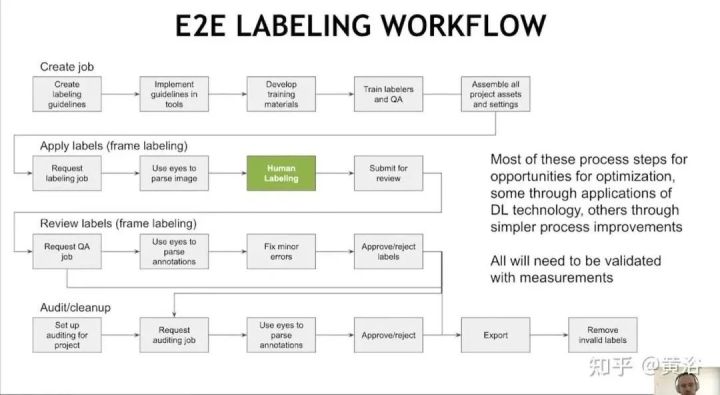
这里是Nvidia在会议报告中给出的端到端标注流水线:它需要人工介入
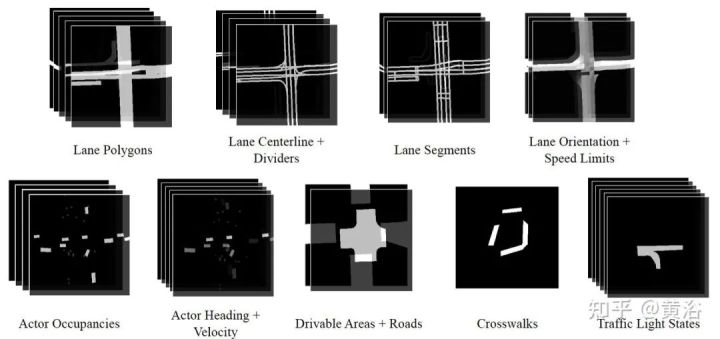
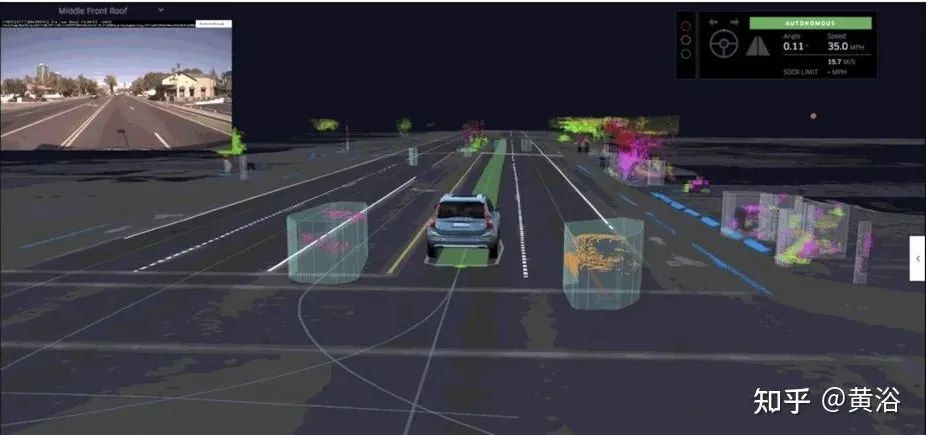
在这里顺便提一下“数据可视化”的问题,各种传感器数据除了标注,还需要一个重放、观察和调试的平台。如图是Uber提供的开源可视化工具 Autonomous Visualization System (AVS):
其中”XVIZ“是提出的自动驾驶数据实时传输和可视化协议:
另外,“streetscape.gl“是一个可视化工具包,在XVIZ 协议编码自动驾驶和机器人数据。它提供了一组可组合的 React 组件,对 XVIZ 数据进行可视化和交互。

4 大型模型训练平台
模型训练平台,主要是机器学习(深度学习)而言,前面亚马逊AWS提供了自己的ML平台SageMaker。我们知道最早有开源的软件Caffe,目前最流行的是Tensorflow和Pytorch(Caffe2并入)。
Tensorflow
Pytorch
在云平台部署深度学习模型训练,一般采用分布式。按照并行方式,分布式训练一般分为数据并行和模型并行两种。当然,也可采用数据并行和模型并行的混合。
模型并行:不同GPU负责网络模型的不同部分。例如,不同网络层被分配到不同的GPU,或者同一层不同参数被分配到不同GPU。
数据并行:不同GPU有模型的多个副本,每个GPU分配不同的数据,将所有GPU计算结果按照某种方式合并。
模型并行不常用,而数据并行涉及各个GPU之间如何同步模型参数,分为同步更新和异步更新。同步更新等所有GPU的梯度计算完成,再计算新权值,同步新值后,再进行下一轮计算。异步更新是每个GPU梯度计算完无需等待,立即更新权值,然后同步新值进行下一轮计算。
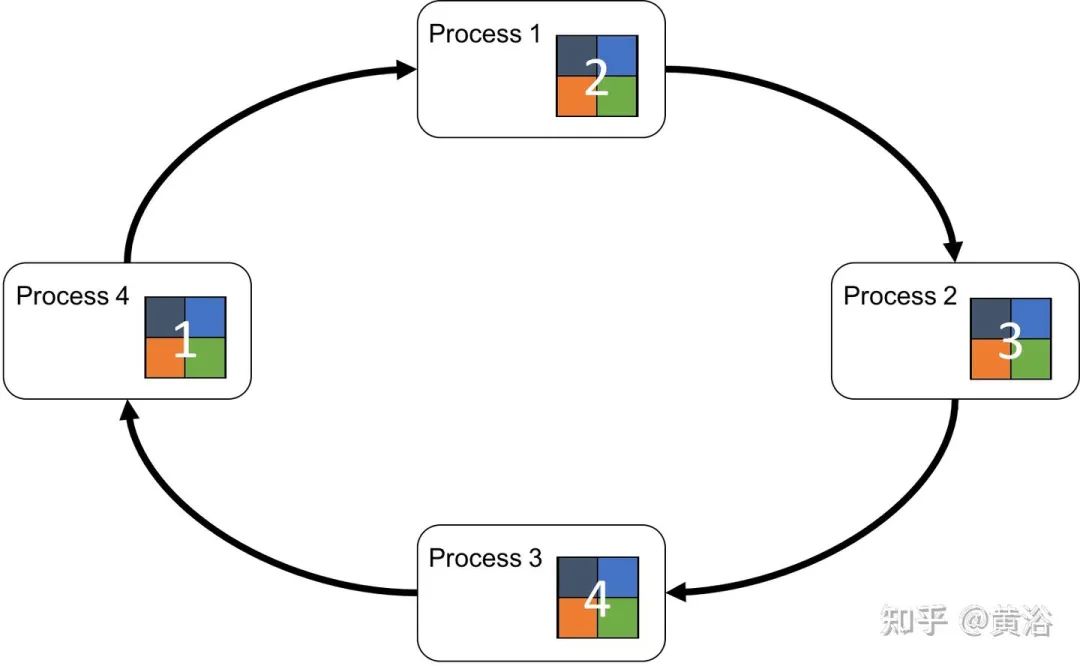
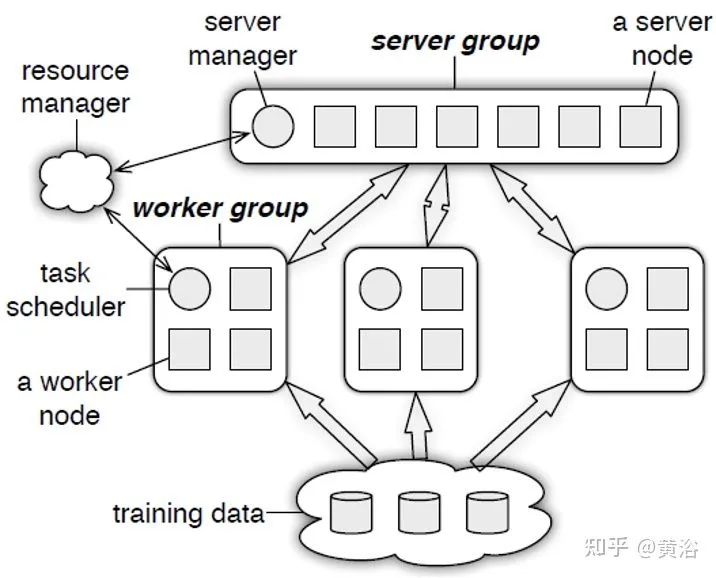
分布式训练系统包括两种架构:Parameter Server Architecture(PS,参数服务器)和Ring -AllReduce Architecture(环-全归约)。
如下图是PS结构图:
这个图是Ring AllReduce的架构图:
Pytorch现在和多个云平台建立合作关系,可以安装使用。比如AWS,在AWS Deep Learning AMIs、AWS Deep Learning Containers和Amazon SageMaker,都可以训练Pytorch模型,最后采用TorchServe进行部署。
Pytorch提供两种方法在多GPU平台切分模型和数据:
-
DataParallel
-
distributedataparallel
DataParallel更易于使用。不过,通信是瓶颈,GPU利用率通常很低,而且不支持分布式。DistributedDataParallel支持模型并行和多进程,单机/多机都可以,是分布训练。
PyTorch 自身提供几种加速分布数据并行的训练优化技术,如 bucketing gradients、overlapping computation with communication 以及 skipping gradient synchronization 等。
Tensorflow在模型设计和训练使用也方便,可以使用高阶 Keras API;对于大型机器学习训练任务,使用 Distribution Strategy API 在不同的硬件配置上进行分布式训练,而无需更改模型定义。
其中Estimator API 用于编写分布式训练代码,允许自定义模型结构、损失函数、优化方法以及如何进行训练、评估和导出等内容,同时屏蔽与底层硬件设备、分布式网络数据传输等相关的细节。
tf.distribute.MirroredStrategy支持在一台机器的多个 GPU 上进行同步分布式训练。该策略会为每个 GPU 设备创建一个副本。模型中的每个变量都会在所有副本之间进行镜像。这些变量将共同形成一个名为MirroredVariable的单个概念变量。这些变量会通过应用相同的更新彼此保持同步。
tf.distribute.experimental.MultiWorkerMirroredStrategy与MirroredStrategy非常相似。它实现了跨多个工作进程的同步分布式训练,而每个工作进程可能有多个 GPU。与MirroredStrategy类似,它也会跨所有工作进程在每个设备的模型中创建所有变量的副本。
tf.distribute.experimental.ParameterServerStrategy支持在多台机器上进行参数服务器PS训练。在此设置中,有些机器会被指定为工作进程,有些会被指定为参数服务器。模型的每个变量都会被放在参数服务器上。计算会被复制到所有工作进程的所有 GPU 中。(注:该策略仅适用于 Estimator API。)



编辑推荐




最新资讯
-
全国汽车标准化技术委员会汽车节能分技术委
2025-04-18 17:34
-
我国联合牵头由DC/DC变换器供电的低压电气
2025-04-18 17:33
-
中国汽研牵头的首个ITU-T国际标准正式立项
2025-04-18 17:32
-
为什么要进行汽车以太网接收测试?汽车以太
2025-04-18 17:26
-
产品手册下载 | NI 全新USB数据采集-NI mio
2025-04-18 16:39
