




 广告
广告





















































一文熟悉视频目标跟踪技术
2021-10-27 21:15:19· 来源:人工智能感知信息处理算法研究院

01 研究背景介绍近年来,随着大数据、云计算、人工智能等领域日新月异的发展及交互融合,智慧电商、智慧交通、智慧城市等概念越发受到关注。随着人们对更智能、
01 研究背景介绍
近年来,随着大数据、云计算、人工智能等领域日新月异的发展及交互融合,智慧电商、智慧交通、智慧城市等概念越发受到关注。随着人们对更智能、更便捷、更高质量生活的向往,同时伴随着重大的学术价值和广阔的商业前景,众多高校、科研机构、政府部门均对相关产业投入了大量的人力、物力和财力。人工智能,被喻为新时代工业革命的引擎,正在悄然渗入到各行各业并改变着我们的生活方式。计算机视觉是人工智能领域的重要分支,旨在研宄如何让计算机像人类视觉系统一样智能地感知、分析、处理现实世界。以图像和视频为信息载体的各项计算机视觉算法,早己渗透到大众的日常生活中,如人脸识别、人机交互、商品检索、智能监控、视觉导航等。视频目标跟踪技术,作为计算机视觉领域中基础的、重要的研宄方向之一,一直是研宄人员的关注热点。
视频目标跟踪要求在已知第一帧感兴趣物体的位置和尺度信息的情况下,对该目标在后续视频帧中进行持续的定位和尺度估计W。广义的目标跟踪通常包含单目标跟踪和多目标跟踪。两者既有差别又有紧密的联系。多目标跟踪算法主要包括目标检测和轨迹关联,以确保同一个物体在视频中获得固定的、唯一的数字标识。多目标跟踪通常限定在目标类别已知的场景中,如多行人、多车辆的视觉跟踪。因此,多目标跟踪算法高度依赖现成的目标检测器。物体检测的质量直接关系到后续的多目标轨迹关联。不同地,单目标跟踪算法要求处理任意类别的物体,即不知道任何关于目标的先验信息。虽然前提条件略有差异,但正如其名,单目标跟踪与多目标跟踪都紧紧围绕着视频中的物体识别与跟踪,因而在外观建模、运动分析、轨迹关联等技术细节上有紧密的关联。如何将单目标跟踪技术应用于多目标跟踪领域也被广泛研宄。因此,研究经典的、通用的单目标跟踪任务对于整个跟踪领域的发展有重要意义
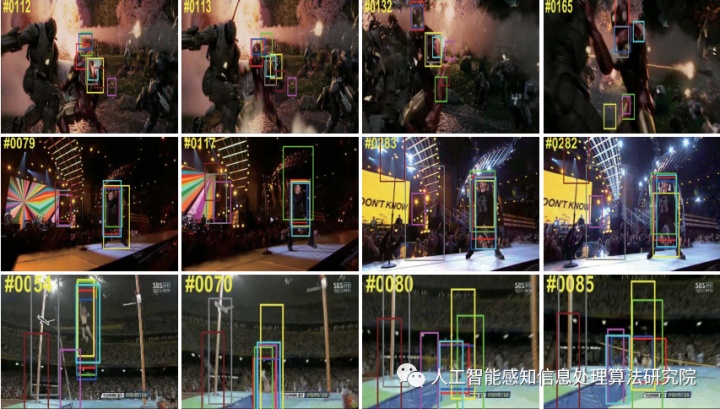
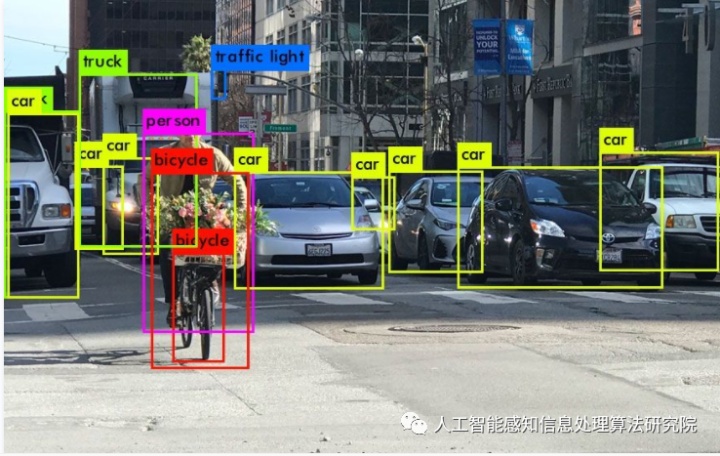
随着计算机运算性能的突飞猛进、高性能摄像终端的广泛普及、以及视频分析需求的与日俱增,目标跟踪算法应用范围愈发广泛,落地需求愈加强烈。实现一个可以精准地、稳健地、快速地执行目标定位的高效视觉跟踪系统是目前不懈努力的技术方向=近年来,在国内外大量学者的努力研宄下,该方向已经取得了突飞猛进的进展,但同时仍存在许多亟需解决的问题,例如如何应对跟踪过程中目标的形变、模糊、旋转、遮挡、超出视野等。随着深度模型如卷积神经网络(Convolutional Neural Network,CNN)等的应用,以及GPU设备带来的计算效率的巨大跃升,目标跟踪技术受益于更鲁棒的特征表达以及端到端的模型训练,已经在速度和精度方面渐渐接近了人们在实际生活中的应用需求。视频目标跟踪作为一个中低层的视觉分析任务,对众多其它视觉任务具有良好的辅助作用,如协助视频目标检测、视频目标分割、视频行人重识别等。在实际应用场景中,如图下图所示,目标跟踪的应用包括但不局限于以下方面:
1安全监控:安全监控需要对特定区域中的行人及物体进行持续的检测和跟踪,以便及时发现行人的异常行为或场景中的安全隐患。安全监控广泛应用于日常生活的各个角落,如学校、银行、超市、火车站、停车场、办公楼以及街道路口等。智能监控通过对可疑行人的识别、跟踪、以及更高层面的语义理解,自动分析并预警,提高效率的同时极大地减轻了人们的工作负担。
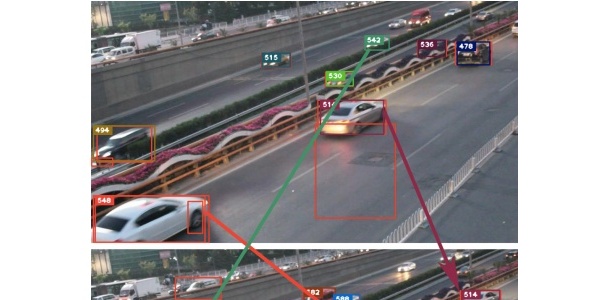
2城市交通:伴随着现代城市巨大的车流量、人流量、遮挡建筑物等,城市交通场景的分析任务复杂且繁重。利用视频目标跟踪技术,对行人轨迹、违章车辆、超速驾驶、车流密度等进行实时监控,为进一步的场景分析、秩序维护、智能调度提供便利,节约人力物力。
3人机交互:随着计算机设备的智能化提升、虚拟现实等技术的成熟,人们不再仅仅满足于传统的机械式人机交互(如使用鼠标、键盘),如何与智能设备更便捷地进行沟通显得愈发重要。摄像头准确、高效地捕捉并持续跟踪用户的眼神、表情、手势以及姿态是人机智能交互的第一步,而这离不开目标跟踪技术的支持。
4军事领域:视觉跟踪技术在现代战争中一直扮演着重要角色。随着现代战争武器的自动化部署,电光火石的交锋已经远远超出了人类感知的极限。视觉跟踪技术在导弹制导、火炮控制、武器观测瞄准、无人机侦察等领域发挥着举足轻重的作用。结合视觉感知并辅以多元信息(如激光和雷达)融合的跟踪技术一直是军事研宄的热点。
5自动驾驶:自动驾驶需要车辆对周围的场景进行实时的感知和分析。毋庸置疑,视觉跟踪技术在其中发挥着重要作用。通过摄像头对周围环境中的目标进行持续的跟踪定位,为无人车的路况分析、智能导航、行驶决策等提供了重要信息,保障交通顺畅,减少事故发生。
6医疗诊断:视觉跟踪技术为智慧医疗提供了坚实的保障并促进其发展。例如,使用跟踪技术标记特定的细胞、蛋白质等,通过对其进行跟踪和轨迹分析,辅助医生进行疾病诊断和医疗救治。通过内窥镜等设备的跟踪和轨迹控制,精准地掌握病人情况。此外,跟踪技术也用于对特定患病部位的持续追踪和对比,为疾病动态检测提供了极大便利。
此外,目标跟踪技术也在视频编辑、三维重建、机器人、机械自动控制等领域发挥着重要作用。

02 模块之-运动模型
运动模型主要对目标在视频中的运动轨迹进行建模和估计。在每一帧中,为较少不必要的运算开销,跟踪算法通常依据运动模型在特定的区域采样候选样本来寻找最可能的目标。跟踪领域中,常见的运动模型包括卡尔曼滤波、粒子滤波、滑窗采样等。
早期的跟踪算法(如基于稀疏表达和SVM的跟踪器)广泛地采用粒子滤波作为运动模型,其基本假设是目标在相邻帧间的运动符合高斯分布。类似地,基于分类网络的跟踪器如MDNET同样在目标前一帧位置处以高斯分布采样大量的候选粒子,并依据观测模型进一步分类。在后续的判别式跟踪算法(如相关滤波器和双路网络)中,最常见的是滑窗式采样,即假设目标在相邻帧间的运动符合均匀分布。
相关滤波器和双路网络通常以前一帧跟踪位置为中心剪裁出目标的几倍大区域,通常被称为感兴趣区域(Region of Interest),并在该区域内稠密地、滑窗式地搜索目标位置。必要时,这些跟踪算法还会在跟踪响应图上增加汉明窗以惩罚目标相邻帧间运动过远的预测。最新的基于梯度的深度跟踪算法也普遍地采用均匀分布的运动估计。
上述的基于高斯分布或均匀分布的运动估计均没有较好的建模目标的运动信息。在SINT算法中,作者使用光流算法来指导候选样本的采样过程,但在性能提升有限的同时又带来了巨大的运算代价。针对DTB数据集M,作者针对无人机拍摄的跟踪场景提出了有效的运动模型,但是仅局限于特定的情况。
由于跟踪领域的数据集众多且拍摄场景多样、复杂,其中不乏人为制造的相机剧烈抖动、目标无规则运动等因素来增加视频的难度,因此单纯地依赖运动模型很难准确地估计目标的运动轨迹。正因如此,科研人员将主要的研宄精力放在了观测模型的构造和改进上,即依赖观测模型的强大辨别能力来筛选和精炼运动模型产生的大量候选粒子。
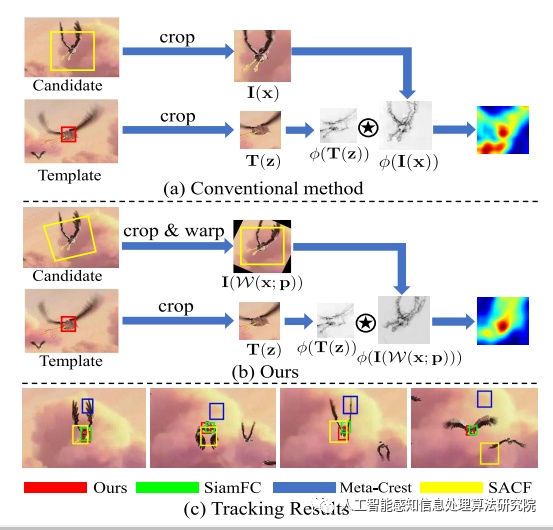
03 模块之-特征提取
依据运动模型确定当前帧的目标搜索范围后,接下来需要对候选区域或候选样本进行特征提取。在跟踪任务中,良好的特征表达不仅需要刻画候选目标丰富的、鲁棒的、具有(旋转、形变、光照等)不变性的外观表达,同时还要凸显出样本间最具有区分力的特征差异以便于正负样本的辨别。视觉跟踪任务的特征表达大体经历了手工特征和深度特征两阶段。
在早期的手工特征阶段,研究人员使用各种人为手工设计的规则将候选样本进行向量化表达。早期的基于稀疏表达的目标跟踪构造关于目标的完备字典,并通过衡量候选样本在字典下的重构误差来预测目标的位置。由于稀疏表达的求解相对耗时,早期的稀疏表达跟踪通常使用维度较低的灰度值特征。在后续工作中,Zhang等人通过在稀疏建模中引入循环矩阵性质并近似得到闭合解,使得稀疏表达跟踪器可以使用更高维度的特征(如HOG)来进一步提升性能。
基于SVM(Support Vector Machine)的目标跟踪同样取得了优异的性能。该类算法通常采用Harr特征。基于颜色直方图的跟踪器也曾经受到了广泛的关注。颜色直方图的统计特性使得这类算法可以更加鲁棒地处理目标形变。最早的相关滤波器MOSSE算法采用单通道的灰度值特征,因而展现了极高的运算速度。在后续的相关滤波器算法中,被证明是最有效、适合于相关滤波器的特征表达,并已经成为这类算法中最常见的两类手工特征。当前众多性能优异的相关滤波器算法都不同程度地使用HOG和ColorNames,如SRDCF、BACF、CSR-DCF、STRCF、ECOHC等。
随着近年来深度学习的流行,视觉跟踪中特征表达逐渐由手工特征转换到深度特征。相比于注重局部的、底层的、纹理和轮廓等信息的手工特征,深度特征无需人工启发式地设计,而是端到端地通过数据驱动来学习,具有高层语义特征表达的能力。早期的工作DLT中,研宄人员将图像预训练的深度特征用于目标跟踪。由于缺乏大规模的训练数据,该时期的深度跟踪算法并没有展现出明显的性能优势。
在2015年,不同的研究团队几乎同时地使用Image Net预训练的CNN网络(如VGG-19、VGG-M)用于跟踪器的特征提取。Ma等人发现CNN网络不同层的特征具有不同层面的表达能力,将多尺度特征进行结合可以进一步提升跟踪性能。此后,深度相关滤波器算法普遍地采用多层CNN特征。然而,该时期的深度相关滤波器算法仅使用现成的CNN网络用于特征提取,并没有充分发挥端到端训练的优势。
在2017年,同时期的CFNET和DCFNet将特征提取网络和相关滤波器进行联合训练,使得深度特征更加适合于相关滤波算法。后续工作中,相关滤波器的建模方式被广泛地应用于跟踪框架中,如CREST、ATOM、DiMP等跟踪器。它们的特征提取网络也从VGG-M渐渐转换到更深的ResNet。
基于分类网络的跟踪器(如MDNet、VITAL)主要采用VGG-M网络进行特征提取并在线地训练全连接层进行样本分类。早期的双路网络跟踪算法主要采用AlexNet网络结构进行端到端的模型训练。
在2019年,研宄人员探索了如何使用更深、更宽的神经网络(如ResNet-50)以进一步提高双路网络的性能。此后,性能顶尖的双路网络基本都采用具有强大特征表达能力的ResNet-50网络。
04 模块之-观测模型
根据观测模型的不同,跟踪算法大体上可以分为生成式和判别式跟踪器。生成式模型仅仅使用前景的目标信息来构造跟踪模型,通过衡量候选样本的重构误差或相似性来挑选最优样本。
常见的生成式跟踪框架包含稀疏表达、子空间学习等。判别式跟踪器同时考虑前景信息和背景信息,以学习到具有区分力的跟踪模型。常见的判别式跟踪器包括随机森林分类器、SVM跟踪器、相关滤波器、分类式神经网络、双路网络等。
由于同时利用了前景和背景信息,判别式模型凭借其优异的区分能力成为跟踪领域的主流,并在性能上远远超过生成式跟踪算法。接下来的内容主要介绍近年来流行的生成式和判别式跟踪器。
1.生成式模型
基于子空间学习的跟踪算法:该类算法的核心思想在于将特征从高维到低维进行映射,从而构造一系列子空间对目标外观进行建模,进一步计算候选样本在子空间下的重构误差或相似性以挑选出最可能的目标。
Black等人最早利用子空间学习搭建视觉跟踪算法,并提出了基于不同视角、光照样本下的子空间学习方案进行外观建模。由于该算法需要大量的先验知识,因而不适合实际应用场景。IVT算法采用了增量主成分分析来更新子空间,以适应目标的外观变化。Yu等人进一步将増量流型子空间算法引入到视觉跟踪领域,以同时保持多个子空间。
基于稀疏表达的跟踪算法:自从稀疏表达算法在人脸识别中大放异彩,基于稀疏表达的目标跟踪受到了广泛关注。Mei等人较早地使用基于l1范数的稀疏表达模型对目标进行建模,通过使用初始帧和后续跟踪得到的正样本构造稀疏表达字典,并衡量候选样本在字典集下的重构误差来选择其中最可能的目标。
由于l1范数的求解过程复杂度很高,后续的研究采用了改进的优化算法如加速近似梯度算法(Accelerated Proximal Gradient,APG)和正交匹配追踪(Orthogonal Matching Pursuit OMP)处理跟踪任务。Jia等人采用基于局部图像块的稀疏表达建模方法,并获得稳健的跟踪结果。Zhong等人将基于局部图像稀疏表达的生成模型和基于前景背景的辨别模型结合起来以达到模型间的优势互补。最近的工作中,Zhang等人通过在稀疏表达框架中引入循环矩阵的性质,从而获得了频域上的高效运算,进一步提高了稀疏表达跟踪的效率。
2.判别式模型
基于SVM的跟踪算法:早在2001年,Avidan将支持向量机(Support Vector Machine,SVM)用于视频目标跟踪,通过SVM学习的分类器模型来区分正负样本。
随后,各种改进的SVM跟踪器不断涌现。Supancic等人提出了基于自步学习(Self-paced learning)的SVM跟踪器。Hare等人提出了结构化输出的SVM跟踪算法Struck,在当时取得了令人印象深刻的性能。Zhang等人在2014年提出了基于熵最小化原则的集成式SVM跟踪框架,达到了十分鲁棒的预测结果。随着深度学习的兴起,将神经网络和SVM算法结合的CNN-SVM跟踪器大幅度超越了之前采用手工特征的SVM跟踪器。
基于相关滤波器的跟踪算法:相关滤波器(Correlation Filter,CF)通过学习一个具有区分力的滤波器来处理待跟踪图片,其输出结果为一个响应图,表示目标在后续帧中不同位置的置信度。
相关滤波器通过利用循环样本和循环矩阵的性质求解岭回归问题,得到了频域上的高效闭合解,计算效率十分出色。但由于相关滤波器的学习过程中引入了循环样本,这些样本不可避免地带来了边界效应,因此传统的相关滤波器算法在如何抑制边界效应上开展了大量的研宄,典型的工作包括SRDCF、BACF等。此外,许多先进的技术也融入在相关滤波器算法中,如结合多种核函数和粒子滤波器结合适用于长时跟踪的重检测、集成学习等。
随着深度学习的日益发展,深度学习和相关滤波器的结合受到了广泛的关注。早期的工作中,研究人员探索如何将离线训练好的深度特征和相关滤波器进行结合。典型的工作HCF提出将不同层的深度特征分别训练相关滤波器并进行由粗到精(coarse to fine)的融合。
在后续的工作中,如何更加充分地利用深度特征被进一步探索,如HDT算法研究了如何自适应地改变各尺度特征下跟踪响应的权重。在深度相关滤波器的基础上,代表性工作C-COT和ECO取得了当时优异的性能。
C-COT算法重点研究了不同层深度特征的分辨率不同而导致的响应图融合问题,并提出了连续性插值和滤波器联合优化的方法,取得了良好的效果。ECO在C-COT的基础上,研宄了自适应的相关滤波器选取、目标样本的聚类、稀疏的目标更新,获得了速度和存储上的进一步优化并轻微提升了性能。
在UPDT中,作者详细分析了深度相关滤波器算法的性能瓶颈,并提出了适合深度相关滤波器的数据增广、滤波器带宽、融合权重优化等细节,使得相关滤波器在采用更深的神经网络后可以得到持续的性能提升。
随着研究的深入,研究人员发现离线训练的深度特征可能并不是相关滤波器的最优选择。得益于相关滤波器的闭合解,研究人员尝试将滤波器和特征提取网络进行联合训练,经典的工作包括CFNet和DCFNet。CFNet将相关滤波器嵌入在双路网络中进行端到端的学习,在获得相关滤波器辨别能力的情况下,同时保证了极高的运行效率。但是,具有边界效应抑制能力的一系列工作(如SRDCF、BACF)和其它优化算法(如C-COT、ECO)破坏了经典相关滤波器的闭合解,通常需要使用交替方向乘子法(Alternating Direction Method of Multipliers,ADMM)进行优化,为端到端训练带来挑战。
在最新的工作中,研究者采用梯度优化的方法来端到端地优化基于相关滤波器算法的深度框架。在CREST算法中,深度学习中常见的随机梯度下降算法(Stochastic Gradient Descent,SGD)被用于优化正则化最小二乘损失(即岭回归),来学习一个类似于相关滤波器的、具备前景背景区分能力的卷积核。此卷积核与搜索图的特征图进行卷积,生成目标跟踪响应图。在CREST跟踪器中shrink loss,作者进一步引入残差项来弥补目标外观的快速变化,取得了进一步的性能提升。在DLST算法中,作者引入了收缩式损失,极大地抑制了冗余的、容易分类的负样本的权重,使得学习到的滤波器更加具有区分力且学习的速度更快。
上述的随机梯度下降方案通常需要数十次甚至上百次迭代才能较好地收敛,因而一定程度抑制了跟踪器的效率。在最近的工作中,研宄人员转向更加快速的梯度下降方法。在最近的ATOM算法中,作者采用共轭梯度策略结合深度学习框架进行快速优化。该研宄团队在工作DiMp中进一步将该思想扩展到了端到端的学习中,并通过神经网络学习跟踪模型所需的各种参数。由于端到端地估计梯度下降的优化步长,使得模型可以在少数几次迭代中快速收敛,保持了岭回归损失的区分能力同时保证了跟踪效率。该算法在数个跟踪数据集上都刷新了当时的性能记录。
基于分类网络的跟踪算法:基于分类的深度跟踪方法将视频目标跟踪视为前景(目标)和背景的二分类任务,并借鉴流行的目标检测算法R-CNNM训练跟踪器。该深度跟踪网络包含一系列卷积层以提取候选样本的鲁棒特征表达,并通过后续的全连接层对样本进行二分类。该方法利用初始帧中的标注样本进行模型微调,并在跟踪过程中不断更新网络,因而效率较低。
MDNet方法%最早使用分类式网络进行目标跟踪,并针对待跟踪物体在不同视频中引发的歧义问题,即该视频中的目标可能成为其它视频中的背景物体,从而引入了多数据域的训练框架。在MDNet的训练过程中,网络的共享层由训练集中所有视频共同训练以学习鲁棒的通用特征表达。对每个视频,MDNet又分别训练独立的分类层(最后一个全连接层)用于区分当前视频域中的目标和背景。经过离线训练阶段,在跟踪时,利用第一帧的标注信息快速微调一个新的全连接层用于辨别当前视频的目标和背景。
后续的一系列工作围绕该分类式模型展开。BmnchOut算法在l0的基础上引入了模型集成的思想,在线地学习并更新多个全连接层,并逐帧挑选最具判别力的全连接层进行跟踪。VITAL方法在MDNet的基础上引入了生成对抗式网络,通过在训练时遮挡目标的不同区域以增强网络的特征表达能力以及预测的鲁棒性。
分类式跟踪方法的主要弊端在于速度很慢,在GPU中仅能达到1FPS,其主要原因在于大量的候选样本需要重复的特征提取。后续的实时MDNet算法(RT-MDNet)在分类式网络借鉴Fast RCNN的思想,对搜索区域进行共享特征提取,然后再使用ROI-Align裁剪出候选样本特征,使得精度仅有轻微影响的情况下跟踪速度提高25倍以上。
基于双路网络的跟踪算法:双路网络将目标跟踪视为模板匹配任务,通过寻找和第一帧模板最相似的候选进行目标定位。由于双路网络的前景、背景判别能力是通过离线阶段大量数据训练得到的,不需要模型的在线更新,因而展示了极为出色的跟踪效率。SINT算法通过衡量候选样本和初始帧模板的相似度进行跟踪。同时期,Bertinetto等人間提出了全卷积的双路网络框架SiamFC,此方法利用共享权重的卷积网络提取目标模板和搜索区域的特征,然后通过相关操作生成搜索区域的响应图进行目标定位。
研究人员针对SiamFC框架,提出一系列改进算法,包括集成学习引入互补的双路网络分支、引入注意力机制、图卷积神经网络、采用强化学习来调整模型参数等。此外,考虑到SiamFC对目标的尺度回归仍采用传统的金字塔形式,不能准确地获得目标的尺度信息,Li等人提出SiamRPN。
此方法将目标检测中的RPN结构引入到SiamFC中,利用参数共享的模块提取特征,然后分别经过分类支路获得目标的位置以及回归支路获得目标尺度的精确估计。相比于SiamFC中采用传统的图像金字塔方式来估计目标尺寸,SiamRPN的推理速度更快,可以达到160FPS。
此后Li等人进一步对SiamRPN进行拓展并提出DaSiamRPN,在训练阶段通过挖掘负样本对提高了双路网络的辨别能力。为了使双路算法充分利用现有的深层神经网络,Li等人将ResNet网络引入到双路跟踪并提出SiamRPN++算法。
SiamRPN++—方面随机平移目标在搜索区域内的位置以解决CNN的边界填充对双路网络平移不变性的破坏,另一方面采用了高层、中层、低层特征融合的方式获得更好的目标特征表达。SiamRPN++在多个目标跟踪数据集上获得了当时最优的性能。

05 模块之-模型更新
为了适应目标的外观变化,视觉跟踪算法普遍采用模型更新技术。例如,稀疏表达跟踪器利用新收集的正样本来更新稀疏字典;基于SVM的跟踪算法使用后续帧中收集的正、负样本来更新决策平面;相关滤波器将后续桢中得到的滤波器以指数型滑动平均(exponential moving average)的策略更新初始滤波器;基于分类网络的跟踪器不断收集新的正、负样本来在线微调分类网络。
然而,由于目标遮挡、形变、跟踪漂移等因素,跟踪过程中收集的受污染正样本可能导致模型退化。针对这个问题,SRDCFdecon提出了样本权重优化的方式来抑制不可靠正样本的权重。Wang等人提出了APCE(Average Peak-to-Correlation Energy)评估准则来衡量跟踪结果的可靠性。另一方面,跟踪过程中存在大量的无意义负样本,严重影响了判别式分类器的区分力。MDNet算法W通过挖掘困难负样本(hard negative mining)来増强算法的鲁棒性。DSLT算法通过设计损失函数来抑制冗余的负样本。在最新的判别式跟踪算法如ATOM和DiMP中,模型更新时重点关注困难负样本己经成为了算法标配。
不同于多数跟踪算法,早期的双路网络通常不使用模型更新策略。为了更好地适应目标外观变化,MemTrack算法利用LSTM(Long Short Term Memory)结构挖掘历史帧的模板信息以更新当前帧的模板。UpdateNet算法训练一个独立的卷积网络并利用历史模板在下一帧预测一个最优的模板特征。GradNet算法通过梯度信息更新模板,一定程度上可以抑制模板中的背景信息。

06 视频跟踪数据集
OTB:OTB数据集包含OTB-2013和OTB-2015两个版本。其中OTB-2013包含51个以往跟踪领域的常用测试视频。同时作者还提出了一系列的评估准则。该数据集及评价标准为跟踪算法提供了统一的测试与评估环境,极大地促进了早期视觉跟踪领域的发展。OTB-2015数据集是OTB-2013的扩充,共包含100个挑战性视频。此外,该数据集还对视频标出了遮挡、形变、快速运动、光照变化、模糊等11个视频属性,便于分析跟踪器应对不同场景的能力。
TempleColor:Liang等人于2015年提出此数据集。针对OTB数据集中存在大量的灰度视频,不利于实际场景的算法评估,TempleColor数据集收集了128个彩色视频,包含27个物体类别。其中部分视频来源于OTB-2015。
NFS:该数据集包含100个视频,包含17个物体类别。不同于常规数据集的每秒30帧的视频采样频率,NFS中的视频帧率达到240FPS。更高的视频帧率对跟踪性能有明显的提升。在该数据集上,传统跟踪算法和最新跟踪器之间的性能差距大幅度缩小。
UAV123:此数据集包含123个视频,共具有9个物体类别。不同于以往的针对通用目标的跟踪数据集,UAV123针对特定的无人机跟踪场景,其视频往往由高空俯视角度拍摄,物体通常更小且视角变化较多。
VOT:单目标视觉跟踪竞赛(Visual Object Tracking,VOT)自2013年首次举办,每年一期,发展至今。VOT竞赛采用的数据集主要针对短时目标跟踪,近些年也会评价算法的实时性以及长时目标跟踪的性能。不同于以上数据集,跟踪器在VOT上测试时,失败时会被复位到正确位置。最终根据失败次数以及成功帧的准确度综合成统一的指标来评价跟踪器的性能。
LaSOT:LaSOT是近年来Fan等人提出的大规模跟踪数据集,共含1400个人工标注的高质量视频。其分为训练集与测试集,且两者没有重叠。该数据集包含70个物体类别,视频平均长度在2500帧左右,十分具有挑战性。
OxUvA:此数据集包含366个视频,总时长超过14个小时。OxUvA专门针对长时间目标跟踪的场景。长时跟踪,由于目标频繁地被遮挡及超出视野,对跟踪器的鲁棒性有更高要求。与此同时,作者还提出了评价长时跟踪性能的评估指标,有助于长时跟踪领域的发展。
GOT-10K:此数据集包含1万个视频,共560个目标类别。值得说明的是,该数据集的训练视频和测试视频中的物体类别没有重合,目的在于更加贴近通用目标跟踪的任务设定,即跟踪算法不依赖于特定物体类别或数据集,也没有任何关于待跟踪目标的先验知识,可以更好地验证算法的泛化性。
TrackingNet:此数据集包含超过3万个视频,共有27个目标类别,其视频数量和标注数量比以往的跟踪数据集更大。同时该数据集也进行了训练集和测试集的划分。该数据集提供的大规模训练视频能够有效地缓解当前跟踪领域的训练数据不足的问题。




编辑推荐




最新资讯
-
中汽中心工程院能量流测试设备上线全新专家
2025-04-03 08:46
-
上新|AutoHawk Extreme 横空出世-新一代实
2025-04-03 08:42
-
「智能座椅」东风日产N7为何敢称“百万级大
2025-04-03 08:31
-
基于加速度计补偿的俯仰角和路面坡度角估计
2025-04-03 08:30
-
《北京市自动驾驶汽车条例》正式实施 L3级
2025-04-02 20:23
