




 广告
广告





















































无人驾驶AI芯片从设计到制造流程详解
2021-10-29 20:10:51· 来源:北京市高级别自动驾驶示范区 作者:周彦武

所谓AI芯片,就是深度学习加速器,目前所有的人工智能其算法在硬件层面最消耗计算资源的就是乘和累加运算,即卷积,分解到底层就是MAC(Multiply Accumulate)。
所谓AI芯片,就是深度学习加速器,目前所有的人工智能其算法在硬件层面最消耗计算资源的就是乘和累加运算,即卷积,分解到底层就是MAC(Multiply Accumulate)。实际卷积主要用在图像分类或者说识别领域,无人驾驶中的行为预测主要是基于贝叶斯算法,行为决策目前多是决策树算法,预测和决策这两个领域分解到底层都是除法、乘法和加法,顺序不固定。因此AI芯片无法加速,这些都需要高性能CPU才能解决问题。
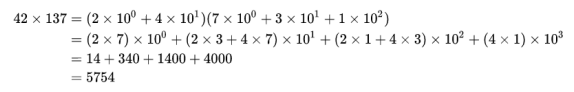
上面就是一个卷积,第二个等号右边每个括号里的系数构成的序列 (14,34,14,4),实际上就是序列 (2,4) 和 (7,3,1) 的卷积。所谓AI算力就是每秒执行多少万亿次指令,这些指令通常就是MAC运算的指令。
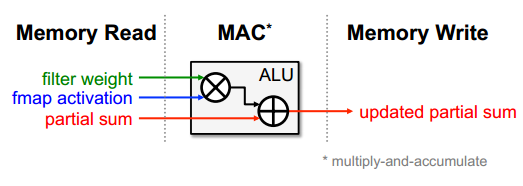
AI芯片的核心就是MAC运算单元,流程就是从内存中读取训练好的模型的滤波权重值和输入数据,两者相乘,然后重复这个流程并将乘积累加,再写入内存。
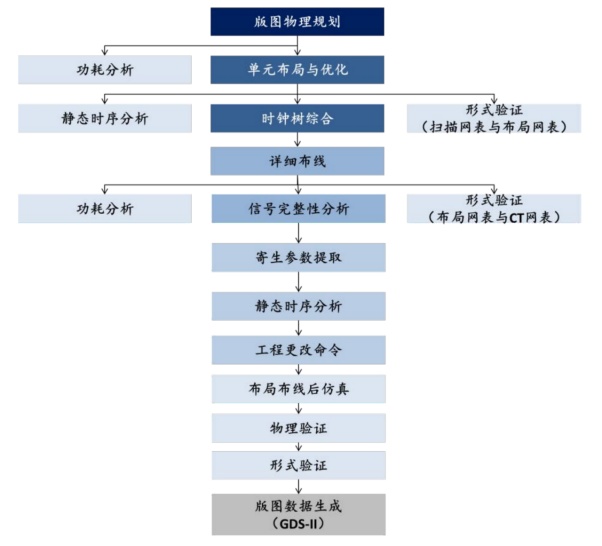
设计一款数字芯片,流程基本上是确定市场定位、确定性能与功能目标即设计规格参数、架构与算法设计、任务划分、购买IP、RTL编码与功能验证即RTL仿真、综合门级仿真、静态时序分析与仿真。这是前端工序,后端是RTL转门级网表文件、数据导入、布局规划、单元布局、时钟综合树、布线、物理验证、版图文件即GDSII交付晶圆代工厂。
前端流程
后端流程
也可以分为三级:
第一级行为级(Behavior Level):通过行为级算法描述数字系统。也就是逻辑构思,人脑的思维流程。这一阶段主要工具为C/C++/Matlab,熟悉这些工具的人很多,很好找;
第二级寄存器传输级(Register Transfer Level):在寄存器传输级,通过寄存器之间的数据传输进行电路功能设计,例如有限状态机。工具是VHDL/Verilog/System Verilog,熟悉这些工具的人很少,这要求既要懂上层的逻辑结构,也要懂下层的电路实现;
第三级门级(Gate level):数字系统按门级(AND,OR,NOT,NAND等)描述。通常不会进行门级设计,门级网表一般是通过逻辑综合的输出。RTL可以用Verilog或VHDL描述。实际上还有更细分的系统级(System Level)或功能模块级(Functional Model Level)。
AI芯片自然是需要先进制程工艺,越先进越好,一般目前都必须选择10纳米以下,这个领域离不开EDA工具,10纳米以下,Synopsys、Cadence和Mentor(Siemens EDA)市场占有率100%,前两家是美国的,西门子自然是德国的,离开这三家,是无法设计出10纳米以下芯片的。这些EDA工具非常昂贵,主要用在后端,对于初创企业来说后端所花的成本远高于前端。
|
工序
|
仿真工具
|
|
IP Level RTL coding
|
Make file;仿真验证工具,Cadence:Incisive,Synopsys:VCS,Mentor:QuestaSim
|
|
Logic Synthesis
|
逻辑综合工具,Cadence:Genus,Synopsys:Design Compiler
|
|
形式验证
|
形式验证工具,Cadence:Conformal,Synopsys:Formality
|
|
STA(静态时序分析)
|
静态时序分析工具,Cadence:Tempus,Synopsys:Prme Time
|
|
PR版图生成,自动布局布线
|
自动布线工具,Cadence:Innovus,Synopsys:IC Compiler
|
|
DRC/LVS
|
物理验证工具,Cadence:Diva/dracula,Synopsys:Hercules,Mentor:Calibre
|
AI芯片大同小异,通常包含四个部分,标量运算、矢量或向量运算、张量运算、存储处理。对于矢量运算和张量运算来说要提高算力就是增加运算单元数量,对芯片来说,这意味着芯片面积的增大,而芯片的主要成本就是晶圆片,与面积成正比,因此需要提高晶体管密度,尽量小的空间内塞下更多的运算单元,也就是晶体管。这两个领域基本上由代工厂决定,台积电在这个领域优势明显,90%的AI芯片都是台积电代工。芯片设计公司能改进的领域主要在标量运算和存储处理这两个领域。
AI芯片有一个特殊之处,那就软硬一体,与软件或者说算法类型捆绑的越紧,性能表现就越优秀,但适用面很窄,换一个算法体系,利用效率就可能大幅度下降90%。如果要争取尽量大的市场,以提高出货量来降低成本,那必须适应各种算法体系,这就肯定会带来性能的下降。大部分纯芯片公司都会增加矢量运算(如求倒数、求平方根)就是如此,争取有更大的应用面,特别是用于推理领域,如果用于训练领域,则无需增加矢量运算单元。无人驾驶领域,矢量运算不可或缺,如简单的图像预处理,AI芯片最好还是加上矢量运算单元。
还有一个关键领域是编译器,这主要是英伟达的阻挠,所有主流深度学习框架都是基于英伟达的CUDA的,框架的角色是连接上层应用和底层各种硬件,它看重的是如何方便而高效地连接底层编译器,选择合适硬件达到最好的性能。而芯片在底层,作为一种硬件,它的角色是应用在多个不同的框架里,提供方便的连接和优异的性能。如果你特别擅长软件,如寒武纪,就独立创作了TVM+NNVM,作为“深度学习到各种硬件的完整优化工具链”,寒武纪在搞芯片的时候当然要最大限度支持自己的深度学习框架,软硬一体,自然算力效率都高,但适用面很窄,一直推广不开。主流深度学习框架对CUDA支持自然最好,没办法,CUDA做得早,当初可没有AI芯片,只有GPU做AI处理,如今生态系统被CUDA一统了,谁都绕不开。
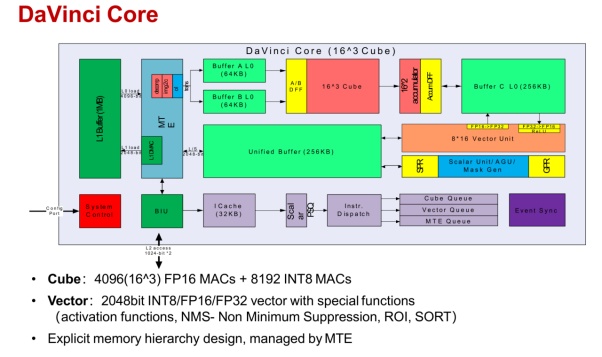
高通AI芯片每个AI核内部框架如上,主要分4个部分,分别是标量处理、向量处理、存储处理和张量处理。
华为的昇腾系列内部框架,与高通AI100基本差不多,昇腾910的MAC数量都和高通AI100一样多,华为把张量换了个说法,叫CUBE。
深度学习中经常出现4种量,标量、向量、矩阵和张量。神经网络最基本的数据结构就是向量和矩阵,神经网络的输入是向量,然后通过每个矩阵对向量进行线性变换,再经过激活函数的非线性变换,通过层层计算最终使得损失函数的最小化,完成模型的训练。
标量(scalar):一个标量就是一个单独的数(整数或实数),不同于线性代数中研究的其他大部分对象(通常是多个数的数组)。标量通常用斜体的小写字母来表示,标量就相当于Python中定义的x=1。
向量(Vector):一个向量表示一组有序排列的数,通过次序中的索引我们能够找到每个单独的数,向量通常用粗体的小写字母表示,向量中的每个元素就是一个标量,向量相当于Python中的一维数组。
矩阵(matrix):矩阵是一个二维数组,其中的每一个元素由两个索引来决定,矩阵通常用加粗斜体的大写字母表示,我们可以将矩阵看做是一个二维的数据表,矩阵的每一行表示一个对象,每一列表示一个特征。
张量(Tensor):超过二维的数组,一般来说,一个数组中的元素分布在若干维坐标的规则网格中,被称为张量。如果一个张量是三维数组,那么我们就需要三个索引来决定元素的位置,张量通常用加粗的大写字母表示。
不太严谨地说,标量是0维空间中的一个点,向量是一维空间中的一条线,矩阵是二维空间的一个面,三维张量是三维空间中的一个体。也就是说,向量是由标量组成的,矩阵是向量组成的,张量是矩阵组成的。
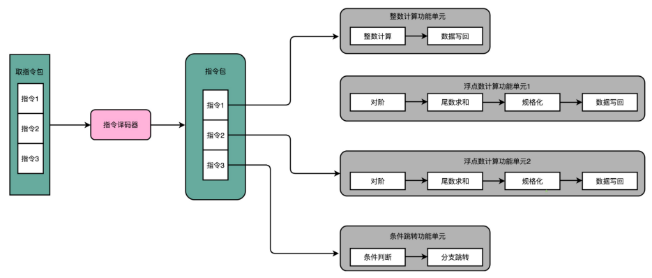
AI芯片的工作流程,从存储器取出指令,如果是标量指令,立即执行,如果是非标量指令,则根据指令类型划分为向量、张量(即矩阵)、存储移动三个类型,分别送到不同的运算单元。
如果只考虑一种算法类型,标量处理器也不可缺少,因为人工智能运算中除了卷积部分,还有很多非矩阵运算,常见的CNN为例,流程是INPUT(输入层)-CONV(卷积层)-RELU(激活函数)-POOL(池化层)-FC(全连接层),AI芯片只擅长处理卷积,遇到其他类型的需求效率会大幅度下降。标量处理器就是一个CPU,完成整个程序的循环控制、分支判断、矩阵/向量等指令的地址和参数计算以及基本的算术运算等。
这是AI芯片最能差异化的地方,CPU厂家也最擅长。目前AI芯片优化标量处理器的主要手段是VLIW。
VLIW是目前比较优秀的,卷积层运算密集、算法单一稳定,固定时间内存访问。为了实现较大规模的运算单元和功耗控制,需要简化内存和总线结构,通常采取权重常驻,数据通过DMA搬运的模式,使用TCM作为片上缓存,这样也就具备了固定访问时间的特点。这样VLIW结构就可以很好的匹配深度学习算法的特点。同时由于基本算子的固定性,只需要向DSP那样手动实现各个运算库的支持,连编译器静态调度都可以做的简单。这样一方面简化硬件,利于大规模的堆叠算力资源,一方面简化编译设计,缩短软件开发周期和难度。因此VLIW在深度学习领域大放异彩也就不难理解。
VLIW就是超标量运算,超长指令集,在乱序执行和超标量的CPU架构里,指令的前后依赖关系,是由CPU内部的硬件电路来检测的,到了超长指令集的架构里面,该工作交给了编译器来实现,编译器把没有依赖关系的代码位置进行交换,然后把多条连续的指令打包成一个指令包,CPU运行时,不再是取一条指令,而是取出一个指令包,译码解析整个指令包,解析出多条指令直接并行运行,使用超长指令字架构的CPU,同样采用的是流水线架构,一组指令,仍然要经历多个时钟周期,流水线停顿这件事情在超长指令字架构里面,很多时候也是由编译器实现的。
VLIW对应多种运算单元
对VLIW最熟悉的莫过于英特尔,不过它和x86指令集不兼容,后来放弃了,再有就是DSP玩家,如高通和德州仪器。英特尔后来花20亿美元收购以色列的Habana Labs,也是VLIW。
对于矩阵(张量)运算阵列,也就是MAC阵列。MAC阵列越多,算力就越高。当然也不是这么简单,MAC阵列的分布有两种,即时间架构(temporal architecture)与空间架构(spatial architecture)两种高度并行化的计算架构。
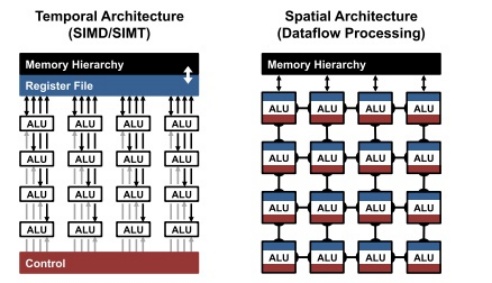
SIMD/SIMT这种时间序列型并行处理架构一般是CPU/GPU/DSP用的,空间并行处理架构也叫数据流架构,如谷歌的脉动阵列,一般是专用AI芯片用的。两种架构各有优缺点。
时间序列并行是通用的架构,可以映射任意的数据流图,但是数据流动,是通过把数据读写全局寄存器,以及存储器来实现的。所以数据流图的映射来看,一个数据流图上的计算,是需要多个周期来连接起来的,而空间并行则是通过ALU之间的通路来实现的,每个ALU都包含了存储、寄存器和控制逻辑,这样的ALU又叫PE,这是纯物理实现。每个MAC都需要三次内存读与一次内存写操作。其中三次内存读操作分别为读取输入数据、权值数据与部分和数据(partial sum),一次内存写操作为更新部分和数据。频繁地内存数据搬迁,是AI芯片能量消耗的主要来源,空间并行大大减少数据搬迁的距离。因此空间并行架构的计算密度远高于时间并行架构,功耗也比较低。
但是空间并行也有缺点,那就是如果数据特殊,如智能驾驶中的图像数据,这种数据包含大量无用的0值,就是天空或背景,这种稀疏网络会让空间并行架构的ALU利用率大大降低。即便不是稀疏网络,也需要完美对应空间并行架构的算法模型才能最大限度发挥ALU的利用率,除非高度捆绑算法模型,都无法达到空间并行架构的理论算力值。当然对时间并行架构也是个麻烦,不过相对好处理。通常推理用AI芯片一般会经常遇到稀疏网络,因此推理领域用时间并行架构最终实际的算力密度比空间并行架构相差不算多。
空间并行架构的另一个缺点是每个ALU都需要有自己的控制逻辑和本地存储,为了保证性能,每个ALU都需要On-Die SRAM。SRAM速度最快,缺点是6个晶体管才能存储1比特,密度太低,这就意味着die的面积会暴涨,成本自然也暴涨,对于比较在乎价格的推理用AI芯片,这显然不太合适。当然也有人不在乎成本,如阿里平头哥的含光800,采用全SRAM设计,仅仅依靠台积电12纳米工艺就取得825TOPS@int8的惊人算力,这也是目前性能最强的推理用AI芯片,但芯片die面积也达到了725平方毫米,这已经是训练用AI芯片的面积了。

考虑到成本关系,需要多级缓存,减少内层存储访问,减少外层存储访问。但是如果深度学习模型太大,SRAM无法完全以此读入,需要多次多层次读入,这就失去了空间并行架构的优点。
MAC阵列的上一级是核心,通常AI芯片都需要至少8个以上内核,16-32个最为常见。核心与核心之间则需要NoC。
在NoC出现之前,传统的片上互联方法包括Bus总线和Crossbar两种。Bus总线的互联方式即所有数据主从模块都连接在同一个互联矩阵上,当有多个模块同时需要使用总线传输数据时,则采用仲裁的方法来确定谁能使用总线,在仲裁中获得总线使用权限的设备则在完成数据读写后释放总线。ARM著名的AXI、AHB、APB等互联协议就是典型的总线型片上互联。
除了总线互联之外,另一种方法是Crossbar互联。总线互联同时只能有一对主从设备使用总线传输数据,因此对于需要较大带宽的架构来说不一定够用。除此之外,在一些系统架构中,一个主设备的数据往往会需要同时广播给多个从设备。在这种情况下,Crossbar就是更好的选择。Crossbar的主要特性是可以同时实现多个主从设备的数据传输,同时能实现一个主设备对多个从设备进行数据广播。然而,Crossbar的主要问题是互联线很复杂,给数字后端设计带来了较大的挑战,版图无法优化,die面积会增加。
NoC有两个优势,一个是复杂度,因为NoC使用了类似计算机网络的OSI 7层架构,因此可以更好地支持多个互联模块,同时可以轻松地加入更多互联模块——这和我们把一台新的电脑接入互联网而几乎不会对互联网造成影响一样。同时这种网络模型节点数再多(一般核心数不超过64)也不会增加路由阻塞。这就可以提升核心的运算频率,提高性能。
另一个优势来自于其物理层、传输层和接口是分开的。拿传统的总线为例,ARM的AXI接口在不同的版本定义了不同的信号,因此在使用不同版本的AXI时候,一方面模块的接口逻辑要重写,另一方面AXI矩阵的逻辑、物理实现和接口也要重写,因此造成了IP复用和向后兼容上的麻烦。而NoC中,传输层、物理层和接口是分开的,因此用户可以在传输层方便地自定义传输规则,而无需修改模块接口,而另一方面传输层的更改对于物理层互联的影响也不大,因此不用担心修改了传输层之后对于NoC的时钟频率造成显著的影响。
核心数越多,NoC的优势就越明显,不过NoC门槛颇高,全球主要有3家,且都已被大厂收购。分别是2013年11月被高通收购的Arteris,英特尔收购的NetSpeed,Facebook收购的Sonics,后两起收购都是2019年。Arteris的NoC具体产品叫FlexNoc,每个IP授权大约200-300万美元,国内大量采用,包括瑞芯微、华为、天数智芯、百度昆仑芯片、国民技术、灵汐科技、辰芯科技、地平线、黑芝麻(2021年6月8日)、四维图新旗下杰发科技(2021年6月底才刚刚购买)。地平线不止买了FlexNoc,还买了Netspeed的NoC IP。
至此,行为级设计基本完成,这时候进行功能仿真,或者叫行为级仿真,检查代码中的语法错误以及代码行为的正确性,其中不包括延时信息。如果没有实例化一些与器件相关的特殊底层元件的话,这个阶段的仿真也可以做到与器件无关。然后是综合后门级功能仿真。绝大多数的综合工具除了可以输出一个标准网表文件以外,还可以输出Verilog或者VHDL网表,其中标准网表文件是用来在各个工具之间传递设计数据的,并不能用来做仿真使用,而输出的Verilog或者VHDL网表可以用来仿真,之所以叫门级仿真是因为综合工具给出的仿真网表已经是与生产厂家的器件的底层元件模型对应起来了,所以为了进行综合后仿真必须在仿真过程中加入厂家的器件库,对仿真器进行一些必要的配置,不然仿真器并不认识其中的底层元件,无法进行仿真。在设计流程中的最后一个仿真是时序仿真。在设计布局布线完成以后可以提供一个时序仿真模型,这种模型中也包括了器件的一些信息,同时还会提供一个SDF时序标注文件(Standard Delay format Timing Anotation)。SDF时序标注最初使用在Verilog语言的设计中,现在VHDL语言的设计中也引用了这个概念。对于一般的设计者来说并不需知道SDF文件的详细细节,因为这个文件一般由器件厂家提供给设计者。前端设计至此完成。
行为级设计通常都是总架构师和算法工程师完成,普通的集成电路工程师的工作集中在RTL级。
寄存器传输级(RTL,Register Transfer Level)指:不关注寄存器和组合逻辑的细节(如使用了多少逻辑门,逻辑门之间的连接拓扑结构等),通过描述寄存器到寄存器之间的逻辑功能描述电路的 HDL 层次。RTL 级是比门级更高的抽象层次,使用RTL级语言描述硬件电路一般比门级描述电路简单、高效得多。
典型的 RTL 设计包含以下3个部分:
时钟域描述,描述设计所使用的所有时钟,时钟之间的主从与派生关系,时钟域之间的转换。
时序逻辑描述(寄存器描述),根据时钟沿的变换,描述寄存器之间的数据传输方式。
组合逻辑描述,描述电平敏感信号的逻辑组合方式与逻辑功能。
在硬件描述语言中,设计人员只需要声明寄存器(就像在计算机编程语言中声明变量一样),然后使用类似编程语言中的条件(if...then...else)、选择(case)等运算符来描述组合逻辑的功能。我们把上述这样级别的设计称为寄存器传输级的设计。这个术语主要是指我们的关注点为讯号在寄存器之间的流动。如果寄存器的输出端和输入端存在环路,这样的电路被称为“状态机”,常被归类到时序逻辑电路中。如果寄存器之间有连接,而没有上述的“回环”,则这样的电路结构被称为“流水线结构”。RTL级最后输出RTL网表文件。再下来就是RTL级转门级。
数据导入是指导入综合后的网表和时序约束的脚本文件,以及代工厂提供的库文件。布局规划是指在芯片上规划输入/输出单元,宏单元及其他主要模块位置的过程。单元布局是根据网表和时序约束自动放置标准单元的过程。时钟树综合是指插入时钟缓冲器,生成时钟网络,最小化时钟延迟和偏差的过程。布线是指在满足布线层数限制,线宽、线间距等约束条件下,根据电路关系自动连接各个单元的过程。物理验证(Physical Verificaiton)通常包括版图设计规则检查(DRC),版图原理图一致性检查(LVS)和电气规则检查(ERC)等。最后得到GDSII文件,设计公司的任务就完成了。
接下来就是找合适的晶圆代工厂流片,流片即tapeout,但往往在实验性生产和验证性生产中才用流片这个词,一般来说tapeout的模式有2大类,一种是多家拼一起的MPW,另一种是专用的全晶圆流片。前者因为成本低,一般实验流片用,后者成本高,一般用于批量生产。流片的主要成本是光罩成本,这是一次性成本,主要与光罩的精密度有关,因为光刻机太贵了,40纳米中芯国际流片光罩成本大约50万美元,台积电12纳米费用大约500-800万美元,6纳米1500万美元,7纳米则需要大约2-3千万美元,5纳米需要5千万到1亿美元,3纳米3亿美元。流片不成功的话,就需要再来一次,费用一点没变化,尽管目前EDA工具很完善,但也不能保证100%流片成功,因此风险是很高的。
AI芯片只有台积电和三星两个代工厂可选,台积电价格高,因为台积电产能不足,在台积电那里需要排队等待,等多长时间未知,三星则产能比较充足,但性能比较差。尽管知道在台积电需要等档期,但是几乎没有人选择三星,只有百度昆仑选择了三星。芯片制造完成后,还需要封装和测试,最终可以拿到芯片。从确定市场定位到最终量产,数字类芯片大概周期要3-4年,用在车上都要是5-6年后了,AI芯片比较简单,快的两年甚至1年半也可以搞定。所以一开始的市场定位需要考虑到4-10年后的市场需求,而市场需求通常很难预测,把握市场环境与动态从而立项芯片设计规划也是芯片公司们最重要的工作之一。



编辑推荐




最新资讯
-
推荐性国家标准《乘/商用车电子机械制动卡
2025-04-30 11:13
-
载荷分解
2025-04-30 10:46
-
布雷博在上海开设亚洲首个灵感实验室
2025-04-30 10:25
-
组分性能对锂离子电池卷芯挤压力学响应的影
2025-04-30 09:00
-
美国发布自动驾驶新框架,放宽报告要求+扩
2025-04-30 08:59
