




 广告
广告





















































基于双目视觉的目标检测与追踪方案详解
2021-12-27 09:29:47· 来源:焉知 作者:Aimme

一直想通过计算机视觉的角度好好地把其在自动驾驶视觉检测、追踪及融合上的原理进行详细阐述,对于下一代自动驾驶系统来说,会采用集中式方案进行摄像头的原始感
一直想通过计算机视觉的角度好好地把其在自动驾驶视觉检测、追踪及融合上的原理进行详细阐述,对于下一代自动驾驶系统来说,会采用集中式方案进行摄像头的原始感知信息输入和原始雷达目标的输入。对于纯摄像头的感知方案通常采用针孔相机模型进行相机标定,在本文中,将研究相机配准和雷达传感器融合的整体过程。了解其对于掌握后续关于测量提取和传感器校准的讨论是必要的。
单/双目相机标定基本原理
将相机信息与物理世界相关联,需要描述 3D 世界坐标和图像坐标之间数学关系的模型,计算机视觉中最简单的此类模型是针孔相机模型(如下图)。
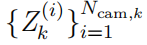
图1 相机模型模型的投影
针孔模型中的图像形成是通过假设一个无限小的孔径来解释的,因此用了针孔这个术语。考虑上图中所有光线会聚在光学中心上,该中心与相机参考系的原点重合,光心到像面上主点c的距离等于焦距f,来自点 p = [x,y,z] 的光线穿过光学中心,从而投影到位于图像平面上的点 p’ = [x’ ,y’ ,z’] 。相似三角形的原理规定,点 [x,y,z] 被映射到图像平面上的点 p’ = [fx/z, fy/z, f] 。忽略深度,该投影由 R3 (三维)到 R2(二维)映射给出,即
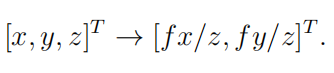
(1)
引入齐次坐标,如上图像点信息可以改写为矩阵形式,其中K表示相机校准矩阵。
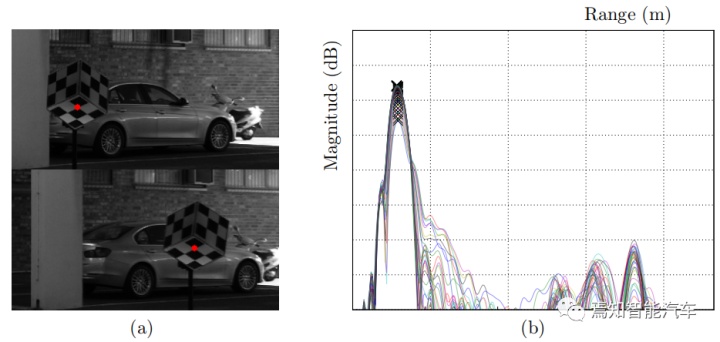
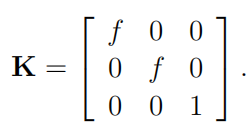
(2)
方程 (2) 提供了将 3D 空间中的点转换为图像坐标的框架。通常,图像平面上的点 p’ 将根据像素坐标来寻找。可以适当缩放相机校准矩阵中的焦距条目,以将 R3 (三维)度量转换为 R2 (二维)像素。在实践中,相机校准矩阵默认为以像素为单位的焦距,并且它包括考虑非理想情况的参数,例如偏移主点或各个维度中每单位长度的像素数量不相等。
相机标定方法旨在估计构成相机标定矩阵的参数,这些量被称为内在参数,校准一般采用张正友的九宫格标定技术,校准过程主要是通过采集不同的九宫格点构造如上方程的多个子式并进行6参数求解。本文讨论将不会深入研究关于相机校准的细节,而是重点讨论关于双目摄像头的感知过程。
当多个摄像机查看同一场景时,可以从图像中提取深度信息。要使用单个摄像机实现相同的目标,需要了解正在记录的场景。考虑下图所示的理想化水平立体声配置,在这种情况下,各个相机的光学中心和图像平面共面。
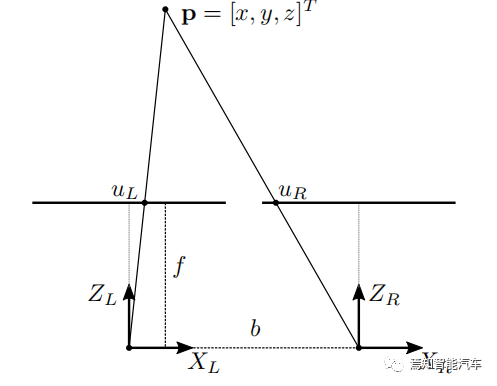
图2 简单的相机视差模型
光学中心也相距一定距离 b,这被称为立体基线,则视差计算方法如下:
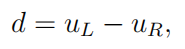
(4)
计算水平和垂直坐标 x 和 y 依赖于与以前相同的原则。然而,深度信息具有唯一确定性,其过程就是求解环境检测点 p 的 z 坐标。其中 uL 和uR 是点 p 投影到相应图像平面上的左右水平坐标。假设坐标系的原点与左相机中心重合,则
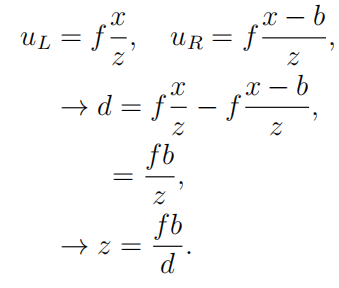
(5)
等式 (5) 给出了理想水平立体配置中校准相机的视差和范围之间的关系,深度计算所需的关键量是视差,确定视差依赖于找到相应的像素在相应的图像中的位置点,对应的方法一般是依靠纹理信息进行帧间匹配。
实际上,通过物理排列来实现完美的相机对准是不可能的。两个相机之间的一般对齐方式如下图所示。点 p 投影到左侧相机图像平面上的点 p’。这个点在右图像平面上的对应关系被限制在平面上绘制的水平基线上。事实上,任何投影到左相机平面绘制线上的点都被限制为与右图像平面上的相应线重合。这些线被称为共轭极线,两幅图像中各自的图像点在该极线上应该满足对极约束条件,它们用于指导立体图像点对应的搜索过程范围。
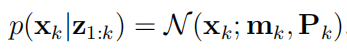
图3 立体视觉测量提取算法示意图
对极约束的数学形式简单明了,我们可以看出,只要我们能够找出两幅图像之间的多组特征点关系,就可以根据对极约束求出两幅图像之间的运动关系。
接下来从数学角度描述一下对极约束。
根据针孔相机模型,我们知道空间位置点P 在相机中的像素位置为p1,p2 。这里 K 为相机内参矩阵,R, t 为两个坐标系的相机运动(如果我们愿意,也可以写成代数形式)。如果使用齐次坐标,我们也可以把上式写成在乘以非零常数下成立的等式:
现在,取:
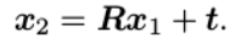
这里的 x1 , x2 是两个像素点的归一化平面上的坐标。代入上式,得:
两边同时乘以t的转置矩阵t^,相当于两侧同时对t做外积:
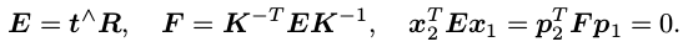
然后,两侧同时乘以

,那么
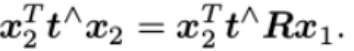
如上等式左侧,t^x2是一个与t和x2都垂直的向量(相当于对t和x2形成的平面做一条法线),把它再和x2做内积时,将得到0,因此,我们得到一个简洁的对极约束式子:
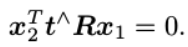
重新带入p1,p2,得到另外一种表示形式

我们把对极约束数学表达式中的中间部分记为两个矩阵:基础矩阵(Fun-damental Matrix)F 和本质矩阵(Essential Matrix)E,可以进一步简化对极约束:
这里需要说明一下,对于多目摄像头对环境信息的探测来说,一般需要考虑两个摄像头必须保持一致的内参信息。其中包括焦距、主点、畸变量等。自动驾驶系统感知过程中,经常会遇到一个比较经典的问题,那就是如果采用两颗单目摄像头,且该两颗摄像头并不是完全相同的,甚至该两颗摄像头一个近焦广角,一个远郊窄角,是否可能在保证单目探测性能的同时实现更多的双目深度探测功能?
这里我们需要注意如果依赖对极约束,实际上是将两个相机的投影矩阵相对于图像点进行了相应的位置约束,而投影矩阵是内参与外参的乘积归一化,所以从理论上讲,无论两个相机内参和外参如何变化都应该满足对极约束。也就是说在其中一个相机中投影点一定能够在另一个相机中找到相应的投影位置,这就使得两个点加上环境点所确定的三角形可以约束整个相机平面点的搜索范围,从而通过三维重建可以完全确定环境点坐标位置。
然而,事实是在自动驾驶动态场景和高精度场景下,该方案无法实现很好的探测能力,因为同步性和一致性不太好。比如曝光起止时间无法做到很好的同步,同时曝光区域也无法做到很好的同步,这就会造成成像尺寸、清晰度、时间不一致。在后期,可以通过微调来大致同步起始曝光时间,但针对多种场景无法保证都可用。比如在通过对极约束解方程时,对大目标(如大货车、大巴车、大卡车等)可以有一定量的深度测量,而对小目标的精细测量却是不可行的。
传感器外参标定
传感器融合的第一步是将来自各个子系统的测量值注册到一个共同的参考框架,传感器之间几何偏移的不准确估计将导致错误配准,从而影响感知性能。一般的,描述传感器之间的对齐参数称为外部参数。本节将描述用于确定传感器外部参数的标定方法。
理想的几何形状意味着独特的对极线对是平行的,并且共轭对不会做垂直偏移,这使得能够在立体图像对的适用行上简单地执行对应搜索。具有这些理想特性的立体图像称为校正。立体校正的过程涉及通过图像处理程序对两个图像进行变换,校正还需要了解两个相机之间的物理排列,即外在参数。与内在相机校准一样,用于计算立体视觉设置的外在参数的标准方法可以参照当前一些文献获得。
首先关键的问题是估计两个摄像头传感器参考系之间的刚体变换,获取描述这种变换的外在参数的最简单方法是通过物理测量几何排列。然而,由于难以准确地确定各个传感器的实际起源,这样的过程可能会导致较差的估计。改进的估计应该来自自动校准方法,其中传感器需要测量相同的目标。然后可以将校准转化为参数优化问题,以求解外部参数。优化过程可通过将摄像头结合雷达探测目标的参数融合校准过程进行。
假设相机对摄像头参考帧CRF中的点p 进行了测量。同样在摄像头参考帧中的测量值由给
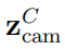
出。此外,结合使用雷达的相位单脉冲,雷达参考帧RRF中相同对象的测量结果表示如下:
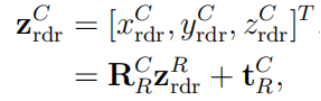
(7)
其中 α 是与视轴的逆时针角度,即方位角。符号用于描述雷达参考帧中的测量深度信息。而摄像头参考帧中相同测量的坐标由下式给出:
(8)
其中RCR、tR分别表示是雷达参考帧相对于摄像头参考帧的旋转矩阵及平移坐标向量。方程 (8) 描述的三维旋转和平移遵循约定,其中旋转被分解为围绕摄像头参考帧的 z、y 和 x 轴的旋转序列,相应的旋转角分别由角度ψ、θ和φ给出。三维变换的欧拉参数化完全由这些角度和平移向量tR = [tx, ty, tz]的元素定义。因此,外部参数的确定简化为ψ、θ、φ、tx、ty和 tz 的求解。
上面的讨论假设影响相应测量值和形成的内在参数是已知的。无需调整现有的用于立体相机内部和外部参数的校准方法。因此,演示将继续假设立体视觉相机经过校准以产生校正图像。对于雷达,天线基线可以被视为一个内在参数。如果基线指定不正确,优化产生的外部雷达到相机参数将是不正确的。因为当不作为测量基线时,而是作为额外的自由参数包括在校准程序中进行估计。
目标参数测量、匹配及提取
对于摄像头和雷达融合的校准过程需要一个对两个传感器子系统都可见的校准目标。为此,通过在面向传感器的三个反射面上应用棋盘格纸图案来增强简单的角反射器。由此产生的校准目标既具有高反射性(高 RCS),又包含尖角,可以在立体图像对中找到精确的对应关系。
图(a)立体图像对中的引导角选择
图(b)雷达范围频谱中的引导局部峰值
确保参数估计所考虑的任何测量都源自校准目标是至关重要的。出于这个原因,原始传感器数据被手动标记。标记雷达数据就像识别距离谱中与校准目标相对应的峰值一样简单。只需要对目标范围的粗略估计,选择加上角反射器极高的雷达截面。提取的数据包括到目标的距离以及两个接收器的信号相位,这些相位用于随后的角度计算。为了提高精度,需要进行24 次扫描,并取得平均距离和角度构成单个雷达校准样本,其结果可以描述在各个脉冲范围谱中发现的局部峰值。
图像测量提取是利用棋盘图案的强梯度来计算视差,角检测算法是被手动引导到其中一幅图像中,并校准目标上的任何角,同时,对另一幅图像中的相同角来重复此操作。上图a中显示了一对角的示例,该信息随后被投影到公制相机框架中。
对于测量

和
的过程中,前面提到校准问题被转换为优化问题,优化程序的任务是通过改变构成外部校准的参数来最小化误差函数。从稀疏特征跟踪框架中获取的时空信息用于识别运动图像区域。外观信息被完全忽略,因此不会产生特定于对象的结果。如下图显示了测量提取算法的基本工作流程,可以概括如下:稀疏特征检测器识别随后跟踪的强候选特征。跟踪器的过滤需要引入平滑策略,实现基本的异常值去除,并为轨迹存储和分析提供框架。可用信息最终在聚类例程中进行处理,该例程需要对相似的特征轨迹进行分组。
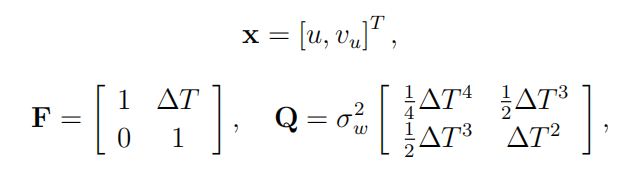
立体视觉测量提取算法示意图
1)特征提取
特征检测通常是使用加速段测试 (FAST) 算法中的特征检测进行的,该检测器在计算复杂性方面明显优于其他替代方案,并且专为一致性高的多视图特征提取而量身定制,这些属性有利于将 FAST 角点检测器用于在实时立体视觉中的应用。
使用稀疏特征检测有一些固有的缺点,其中最值得注意的是无法从低纹理图像区域收集信息,这可能会阻碍最终准确估计目标范围的能力。范围信息应主要从视觉子系统中提取,因为它提供比雷达更高的分辨率。为了减轻可能的负面影响,设置特征检测阈值以产生半密集信息,即分布在视野中的数千个特征被识别为跟踪候选。通过这种方法,可以获得相当准确的范围信息,而计算需求仍然比密集检测方法低得多。
2)特征追踪
算法运行所需的时间数据可通过状态估计器获得,该估计器随时间跟踪检测到相应的特征,由此产生的运动信息对于运动物体分割具有重要价值。本文将详细介绍实现的特征跟踪框架。
①卡尔曼滤波器
检测目标的半密集性要求对后续处理进行仔细考虑,可能数以千计的跟踪特征需要非常有效的状态估计器。为此,引入了卡尔曼滤波器。卡尔曼滤波器是贝叶斯滤波器递归方程的可实现公式,要素不是传播完整的目标状态密度,而是采用高斯分布进行近似,即
(9)
其中 N (x; m, P) 表示在具有均值 m 和协方差 P 的向量 x 上定义的高斯分布。卡尔曼滤波器递归方程的一个重要约束是它必须保留状态分布的高斯结构。这意味着动态和测量模型必须是线性高斯变换。请注意,在传统控制系统中发现的控制输入不包括在预测更新中,因为该数量在目标跟踪中是未知的。对于线性模型,以下方程定义了卡尔曼滤波器的预测正确递归:
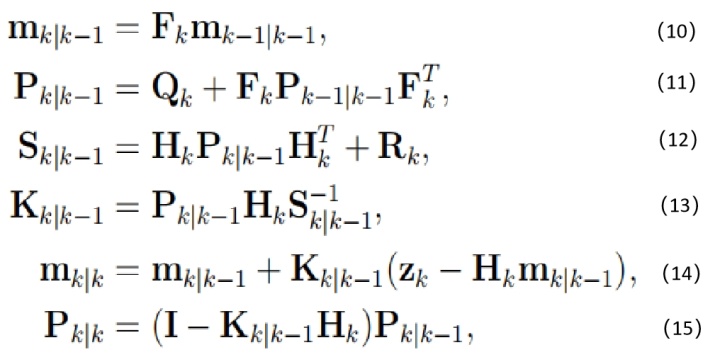
其中 Fk 是状态转移矩阵,Qk 是过程噪声协方差,Hk 是观测矩阵,Rk 是测量噪声协方差。等式(11)和(12)定义了预测更新,而等式(13)到(15)使用相关联的测量zk定义了测量更新日期。预测更新本质上是通过 Fk 和 Qk 描述的线性动态模型对状态分布的变换。转移矩阵描述了 k -1 时刻的状态均值与 k 时刻的先验之间的确定性关系,而过程噪声协方差矩阵则对转移中的不确定性进行建模。在目标跟踪中,这些矩阵来源于目标的运动模型,测量更新结合了观察来改进状态估计,这里的关键量是测量预期测量更新值Hkmk|k-1与实际测量值Zk的差值,更新协方差由矩阵 Sk|k−1 给出。该创新及其协方差通过卡尔曼增益 Kk|k-1 影响方程(15)中的结果更新。
对于小状态向量维数,卡尔曼滤波器为贝叶斯状态估计提供了一个非常有效的框架,因为它的递归方程仅依赖于简单的矩阵乘法。非线性动态和测量模型可以通过将非线性变换近似为高斯来合并。泰勒级数展开和无迹变换分别表征扩展卡尔曼滤波器和无迹卡尔曼滤波器,其中两个是卡尔曼滤波器最常见的非线性扩展。
②状态空间模型
图像特征的测量在图像坐标中可用,但在惯性坐标中需要 DATMO 上下文中的目标轨迹。使用图像平面测量在惯性空间中进行跟踪将需要非线性近似技术,然而,非线性估计方法的实现将显著增加跟踪器的计算需求。在最优性和速度之间的权衡中,后者被选择用于稀疏特征跟踪,即在图像坐标中跟踪特征,这使得能够使用标准线性卡尔曼滤波器。由于加速坐标系,实际上图像坐标不是惯性坐标可能会导致奇怪的非线性效应,因此线性卡尔曼滤波器是一个近似值。
接下来,布局特征跟踪器的动态和测量模型。每个特征点的运动是根据恒速模型使用线性动力学和高斯噪声建模的
(16)
其中 u 是特征的水平图像坐标,vu 是其速度,σw 是加速度噪声标准偏差,ΔT 是时间步长。对于构成图像坐标的其余轴,即垂直坐标 v 和视差 d,实现了精确解耦跟踪器。因此假设各个图像平面尺寸是完全独立的,由于必须反转的矩阵的维数较小,因此解耦的低阶卡尔曼滤波器更有效,可以通过使用 OpenCV 的立体块匹配密集立体对应算法来合并视差信息。尽管每个特征的差异搜索有望提高效率,但额外的研究工作是不必要的。在这里,差异仅需要作为概念证明。因此,仅从左侧图像中提取特征,并且可以从密集对应算法中获得相应的视差。
特征跟踪测量模型也是线性的,形式为
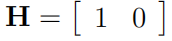
(17)
其中 σu 是水平维度中测量噪声的标准偏差,相同的更新矩阵适用于其他维度,基于创新的异常值拒绝策略被纳入特征跟踪框架,如果创新大于创新协方差平方根的常数因子标准偏差,即
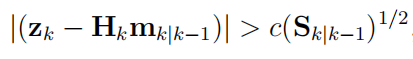
(18)
其中 c 是一个常数,然后删除轨道。此规则在所有三个跟踪维度中都实施,如果有任何未通过测试,则删除该跟踪。请注意,如上方程中的数量减少为长度为 1 的向量和 1 × 1 矩阵,即它们是标量。在除了基于异常值的轨道删除,M/N 逻辑规则也可用于轨道管理。
选择线性图像平面状态空间模型的结果是,由于底层特征的框架和跟踪框架不同,可能会导致加速效应。虽然并不理想,但跟踪器会产生轨道平滑效果并允许简单的异常值去除,同时将计算开销降至最低。
③数据关联
考虑到测量与跟踪的关联性,由于要跟踪的特征数量庞大,实施复杂的数据关联方法(例如多假设跟踪)肯定是不可行的,需要采用不同于传统跟踪方法的跟踪策略。新检测不是将特征检测器的输出视为与现有跟踪实体相关联的测量值,而是简单地将特征标记为跟踪候选。通过使用光流原理主动搜索其对应关系,可以找到任何现有特征轨迹的适当测量。
④聚类
为了从视觉子系统中提取最终测量值,在特征轨迹数据上实施了一个聚类程序。聚类的目的是识别源自同一环境监测对象的特征轨迹。理想情况下,要成功地对特征轨迹进行分组,应该需要有关数据的最少先验知识。例如,任何给定扫描中存在的目标数量是一个未知参数,应由 DATMO 算法使用各车载传感器数据确定。许多流行的聚类算法(例如 k-means 和期望最大化)不适合这种特定应用,因为它们对聚类的确切数量的依赖性和敏感性。在这个项目中,可以选择具有最少先验知识的特征轨迹聚类解决方案是基于密度的噪声应用空间聚类(DBSCAN)算法。DBSCAN 识别和分组空间数据集中的密集区域,同时还提供异常值标记。DBSCAN 只需要两个参数,即一个集群可能适用的最小样本数和一个特殊的距离阈值。
⑤匹配库数据扫描
在 DBSCAN 算法中构成集群的形式化依赖于一些定义。首先,点 p 的邻域 N(p) 是距离 p 小于或等于 p 的所有点的集合。如果点的邻域包含至少最少数量的点,则点被标记为核心点。核心点 q 的邻域中的任何点 p 都被称为从核心点直接密度可达。如果存在一系列点 p1,则任何点 p 都是从核心点 q 密度可达的. . , pn, p1 = q, pn = p 使得 pi+1 可直接从 pi 密度可达。密度可达条件的对称变体是密度连通的,两个点 p 和 q 是密度连通的,如果它们存在一个点 o,那么这两个点都是密度可达的。一个簇被定义为所有密度连接的点,从集群内的任何点密度可达的点也包括在内,而无法到达的点被标记为异常值。
下图以图形方式显示了不同的可达性定义:

最小样本参数等于 4 点的 DBSCAN 可达性说明:上图中蓝色圆圈是核心点,因为它们的邻域至少包含最少数量的点。图(a)中点 p1 是从 q 密度可达的,图(b) 中 p1 和 p2 通过核心点 q 彼此密度连接,黑点被标记为异常值。
DBSCAN 聚类呈现出有利的特征,因为它几乎不需要对数据集进行假设。不必指定簇的数量,可以找到任意形状的簇。此外,异常值是固有地检测到的。该算法的一个缺点是它无法对密度不同的数据集进行聚类。
为了在跟踪点上应用 DBSCAN 聚类算法,数据被组织成一个
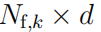
聚类矩阵 C,其中 Nf,k 是在时间 k 跟踪的特征点的数量,d是包含在聚类中的维数。预计源自单个物体的轨迹将表现出类似的时间行为,同时以欧几里德距离紧密间隔。鉴于此,聚类矩阵的每一行都是一个形式为
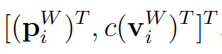
的表达式。其中 pi 表示世界参考系中跟踪点 pi 的平均值,vi 是该点在过去有限数量的时间步长内的平均速度。常数 c 是衡量速度分量贡献的加权因子。该实现有利于速度维度的比例为 3:1,即 c = 3。在聚类过程中,普通欧几里得距离用作相异度量。由如上方程的特征向量产生的集群预测会包含表象中的相似空间和时间行为的点。
一个标签,表明 DBSCAN 程序产生的集群和异常值的组成,离群点被立即丢弃。为了从视觉系统获得最终的测量结果,内部集群对其平均速度进行了阈值处理。
每个输出集群都应包含源自同一移动对象的点。在数学方面,集群测量可以写成一组点,即
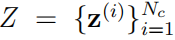
,其中 Nc 是特定点的数量簇。可以在任何给定的时间步长提取大量集群,建议从视觉系统中提取的测量值的一组表示,即
,其中 Ncam,k 是数字在时间 k 的集群测量。请注意,如上方程的聚类特征向量的形式导致世界坐标系下参考帧的输出测量。
特别是,使用了特征跟踪器的金字塔式实现,其输出被视为特征的“测量”。随后使用卡尔曼滤波器的测量更新方程处理该测量,视差是通过查询密集深度图像获得的,生成的特征轨迹为具有足够纹理的图像区域并提供了相应的速度信息,而这些速度的术语是一种场景流,它是具有深度信息的二维光流的扩展。



编辑推荐




最新资讯
-
imc/GRAS/AP首次联袂亮相ATE India 盛会
2025-04-11 13:49
-
GB/T 31486-2024 与 GB/T 31484-2015 修改
2025-04-11 13:48
-
标准介绍丨ASAM ARTI 运行实时接口
2025-04-11 10:29
-
自动驾驶中基于深度学习的雷达与视觉融合用
2025-04-11 10:25
-
标准研究丨《汽车开闭件性能要求和试验方法
2025-04-11 10:24
