




 广告
广告





















































最近出现的几篇视觉和激光雷达SLAM论文介绍
2022-01-09 21:27:27· 来源:计算机视觉深度学习和自动驾驶 作者:黄浴

介绍最近半年的一些SLAM论文,包括视觉和激光雷达,有传统方法,也有深度学习方法。1 “LT-mapper: A Modular Framework for LiDAR-based Lifelong Mapping“,a
介绍最近半年的一些SLAM论文,包括视觉和激光雷达,有传统方法,也有深度学习方法。
1 “LT-mapper: A Modular framework for LiDAR-based Lifelong Mapping“,arXiv July,2021
是韩国KAIST Department of Civil and Environmental Engineering 发表。
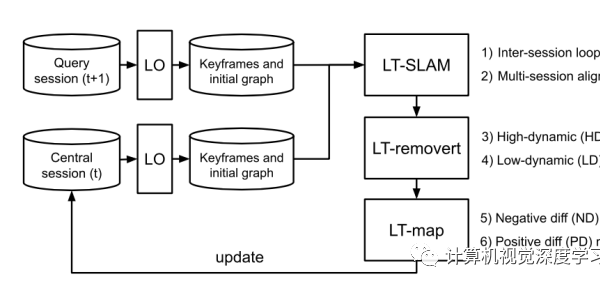
长期的3D地图管理是机器人在非静止现实世界中可靠导航所需的基本能力。本文为城市区域开发了开源、模块化和现成的基于激光雷达的持久地图(lifelong map),称为LT-Mapper(LiDAR-based lifelong mapping)。它将问题划分为序贯子问题:多节SLAM(multi-session SLAM,MSS)、高/低动态变化检测和正/负变化管理。该方法利用MSS,处理潜在的轨迹误差;因此,变化检测不需要良好的初始校准。这个变化管理方案在内存和计算成本方面保持有效性,提供了大规模点云地图自动分离目标的功能。通过对多个时间间隔(从一天到一年)的大量实际实验,验证了该框架的可靠性和适用性。
代码在 https://github.com/gisbi-kim/lt-mapper
-
通过锚节点(anchor node)弹性地处理各节,而子模块 LT- SLAM 可用 LiDAR 在共享帧中拼接多节。
-
子模块 LT-removert 克服了各节之间对齐的多义性,沿空域轴和时域轴调用 remove-then-revert 算法。
-
子模块 LT-map 可以有效地生成最新地图(实时地图)和持久地图(元地图),同时变化存为增量地图(delta map)。通过增量地图,恢复和变化检测操作在内存和计算上成本高效。
-
上述模块打包在单个框架中,其中包含现成的基于控制台命令。此外,提供多个时间间隔(每天)的真实世界实验。
模块流水线如图所示:
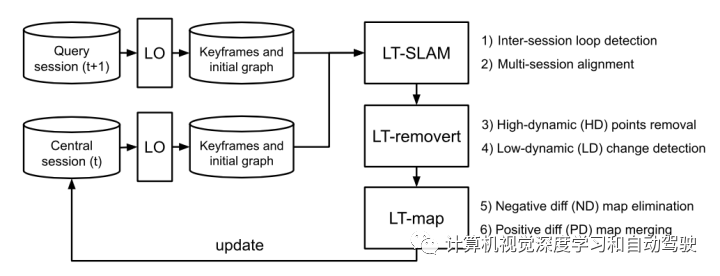
在 LT-SLAM 模块中,用多节 SLAM 共同优化多个节,同时从基于 LiDAR 的全局定位器进行强大的节间闭环检测。在此模块中,查询测量校准到到现有的中心地图。
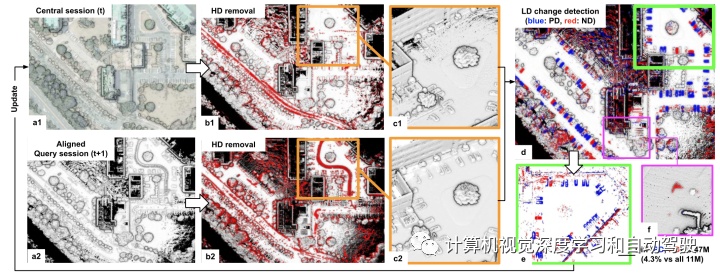
对齐查询和中心节并删除 HD (High Dynamic)点,在查询测量和中心地图之间应用set difference运算检测变化。这个变化称Low Dynamic (LD), 进一步可分成两类: 1)新出现的点,Positive Difference (PD) ;和2)消失的点,Negative Difference (ND)。
鲁棒的节间闭环检测,采用Scan Context (SC) ,因为其具备的长时全局定位能力和轻量计算成本。检测节间闭环后,通过Iterated Closest Point (ICP) 算法计算两个关键帧之间的6D相对约束。
如图是LT-removert可视化的流水线:LT-removert模块把动态点分成HD和 LD 两种,(a) LT-removert 从 LT-SLAM 接收对齐的中心地图和查询地图;(b-c)删除了HD points的清洗地图;(d-e)LD 变化检测(即 PD 和 ND 分割);(f) 通过多节抹去未删除的HD points。
给定检测到的 LD,LT-map 对中心节的每个关键帧执行节间变化更新。与上传/下载整个地图的基于快照方法相比,仅包含差异的增量地图具有优势。
2 “DSP-SLAM: Object Oriented SLAM with Deep Shape Priors“, arXiv,August,2021
作者来自University College London。
DSP-SLAM(Deep Shape Priors-SLAM),这是一种面向目标的SLAM系统,可以为前景目标构建丰富而精确的密集3D模型联合地图,而稀疏的地标点表示背景。DSP-SLAM将基于特征SLAM系统重建的3D点云作为输入,通过对检测物体进行密集重建来增强其稀疏地图的能力。通过语义实例分割来检测目标,并通过一个二阶优化,特定类别(category-specific)的深度形状嵌入作为先验,估计形状和姿势。目标-觉察BA构建一个姿势图,共同优化相机姿势、目标位置和特征点。DSP-SLAM 可以在 3 种不同的输入模式,即单目、立体视觉或立体视觉+LiDAR,以每秒 10 帧速度运行。
项目网页:https://jingwenwang95.github.io/dsp-slam/
如图所示:DSP-SLAM 构建了丰富的目标-觉察地图,提供了检测目标的完整详细形状,同时将背景粗略地作为稀疏特征点发送;在KITTI 00上重建地图和相机轨迹。

如图是DSP- SLAM的系统概览:
采用 DeepSDF(“Deepsdf: Learning continuous signed distance functions for shape representation“,CVPR 2019)作为形状嵌入,输入一个形状码和一个3D查询位置,输出给定点的signed distance function (SDF) 值。ORB-SLAM2 用作跟踪和制图主干网,一个基于特征的SLAM框架,在单目或立体图像静止状态上运行。虽然跟踪线程从对应关系中以帧速率估计相机姿势,但制图线程通过重建 3D 地标来构建稀疏地图。
在每个关键帧执行目标检测,共同推断2D目标边框和分割掩码。此外,通过3D边框检测获得目标姿势估计的初始值。
新检测将关联到现有地图目标,或通过目标级数据关联实例化为新目标。每个检测目标实例由一个 2D 边框、一个 2D 掩码、稀疏 3D 点云的深度观测和初始目标姿势等组成。
新实例化目标通过重构流水线进行重构。DSP-SLAM 采用一组稀疏的 3D 观测值 ,其来自重建的 SLAM 点(单目和立体视觉)或 LiDAR 输入(立体视觉+LiDAR),并选择形状码和目标姿势最小化表面一致性和深度渲染损失。地图中已存在的目标将仅通过姿势优化更新其 6自由度姿势。
点特征(来自SLAM)、目标和摄像机姿势的联合因子图(joint factor graph)通过bundle adjustment(BA)进行优化,以保持一致地图并考虑闭环(loop closure)。新目标作为节点,添加到联合因子图中,其相对姿势估计即相机-目标之间的边缘。
表面项定义为:
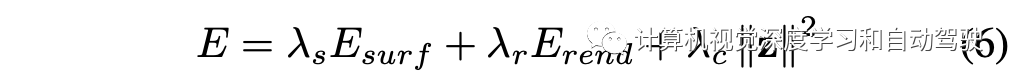
SDF定义为:
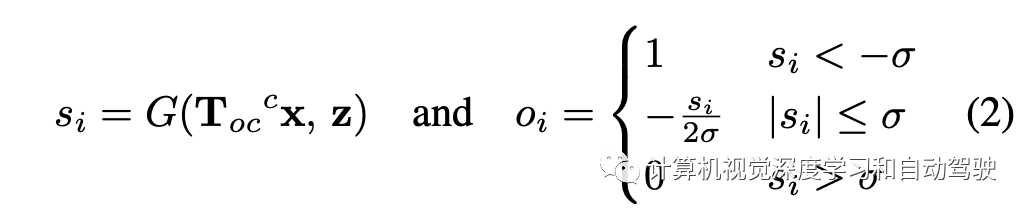
事件概率定义为:

渲染的深度项为:
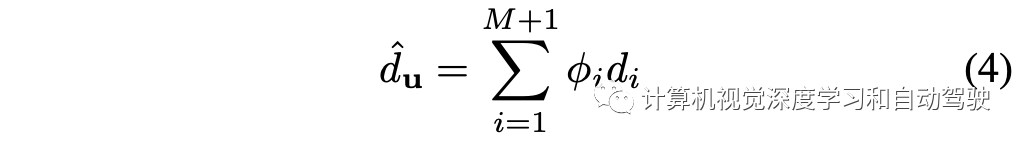
ray-tracing渲染项为:
优化的最终能量函数是表面一致项、渲染项以及形状码正则项的加权和,即
数据相关中目标是将每个检测与其在地图中最近的目标相关联,并根据不同的输入模式采用不同的策略。当LiDAR输入可用时,比较3D边框和重建目标之间的距离。当仅用立体视觉或单目图像作为输入时,计算检测和目标之间匹配的特征点数量。如果多个检测与同一目标相关联,保留最近的一个并拒绝其他目标。与任何现有目标无关的检测,将初始化为新目标,其形状和姿势再进行优化。对于立体视觉和单目输入模式,仅当观察到足够表面点时才会进行重建。对现有目标有关联的检测,运行只有姿势的优化;新相机-目标边缘会添加到联合因子图中来优化姿势。
最后联合BA优化一个联合地图,包括摄像头姿态、目标姿势和地图点:
3 “DROID-SLAM: Deep Visual SLAM for Monocular, Stereo, and RGB-D Cameras” arXiv,August 2021
普林斯顿大学邓加团队发表。
DROID(Differentiable Recurrent Optimization-Inspired Design)-SLAM,是一种基于深度学习的SLAM系统。DROID-SLAM通过dense BA层对摄像机姿势和像素深度进行重复迭代更新。尽管在单目视频方面进行了训练,但采用立体视觉或RGB-D视频的话,在测试时可实现更高性能。
开源代码 https://github.com/princeton-vl/DROID-SLAM
如图是示意图:
它包括recurrent iterative updates,在RAFT optical flow模型(“Raft: Recurrent all-pairs field transforms for optical flow“,ECCV,2020)基础上做了两点改进:
-
采用多帧优化,而不是两帧;
-
更新基于一个可微分的Dense Bundle Adjustment (DBA) 层。
采用一个frame-graph,特征提取主要来自RAFT,同样包括两个:特征网络和上下文网络。特征网络用于构建一组关联体,而上下文特征则在更新操作的每个应用程序注入网络。
SLAM 系统的核心组件是如图所示的学习更新操作:更新操作是具有隐状态 的 3 × 3 ConvGRU,操作在frame- graph的边缘进行,预测映射到深度的流修正(flow revision),并通过DBA层进行姿势更新。
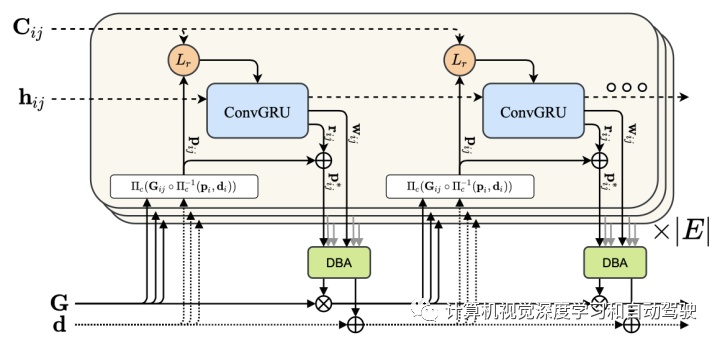
相关特征提供了有关致密流域每个像素位置附近视觉相似性的信息,使网络能够学习对齐视觉相似的图像区域。但是,对应关系有时是模棱两可的。该流提供了一个互补信息源,允许网络利用运动场中的平滑度来获得鲁棒性。
相关特征和流特征在注入GRU之前分别通过两个卷积层进行映射。此外,通过逐元加操作将上下文网络提取的上下文特征注入GRU。
ConvGRU是一个小感受野的局部操作。沿着空间维做隐平均,提取全局上下文,并将此特征向量用作GRU的额外输入。全局上下文在 SLAM 中很重要,因为不正确的对应关系(例如由大型移动目标引起)会降低系统的准确性。对网络来说,识别和拒绝错误对应非常重要。DBA层把流修正集映射成姿态集,并逐元深度更新。如下定义成本函数:

整个系统包含两个异步运行线程。前端线程接收新帧、提取特征、选择关键帧并执行局部BA;后端线程同时对关键帧的整个历史记录执行全局BA。
DROID- SLAM可以泛化到其他数据集,如图所示:
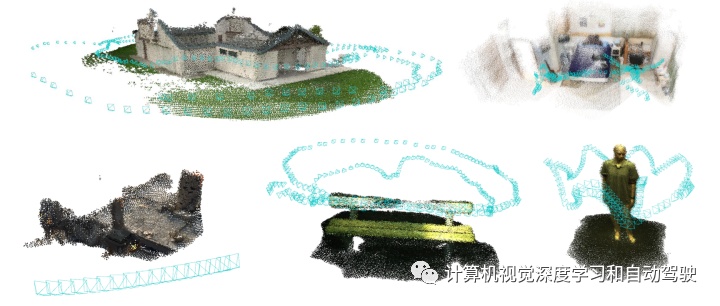
4 “ART-SLAM: Accurate Real-Time 6DoF LiDAR SLAM“,arXiv,September,2021
由意大利一所大学发表。
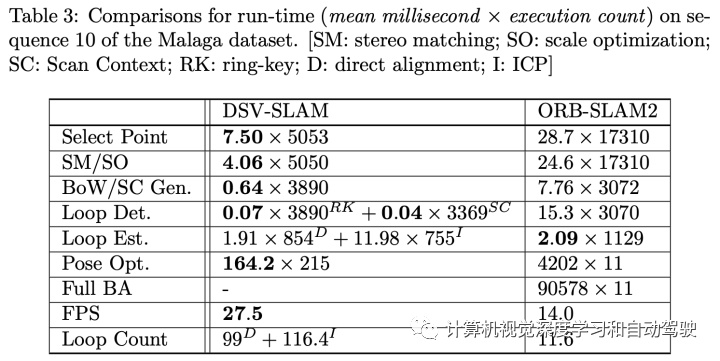
基于地面车辆的实时6-自由度姿态估计是机器人学中的一个重要研究课题,应用如自动驾驶和三维地图。本文提出一种快速、准确和模块化的激光雷达SLAM系统,用于批量和在线估计。首先下采样和出格点去除,滤除噪声并减小输入点云的大小。然后将过滤后点云用于姿态跟踪和地面检测,优化估计的轨迹。与滤波过程并行工作,一个预跟踪器允许获得预计算里程计,在跟踪时用作辅助工具。通过g2o pose graph实现的高效闭环和位姿优化,是该SLAM流水线的最后步骤。系统的性能与当前基于点云的方法(LOAM、LeGO-LOAM、A-LOAM、LeGO-LOAM BOR和HDL)进行了比较,结果表明,系统达到了相同或更好的精度,并且可以轻松地处理无闭环的情况。使用KITTI和Radiante数据集对估算的轨迹位移量进行比较。
注:HDL(“A portable 3d lidar-based system for long-term and wide-area people behavior measurement”,IEEE T- HMS,2018)
代码上线:https://github.com/MatteoF94/ARTSLAM
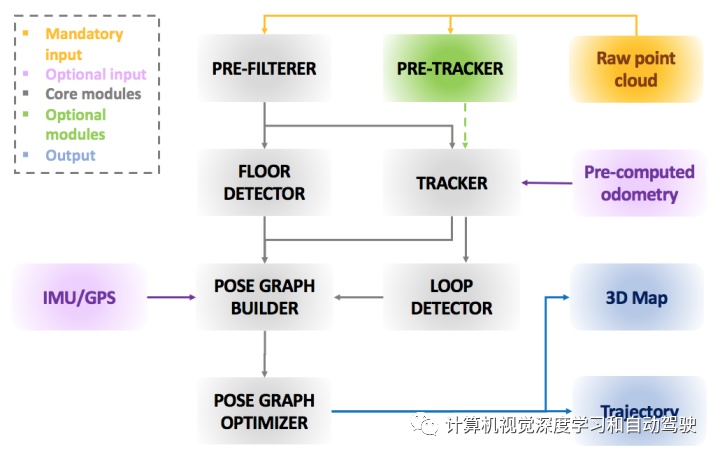
ART(Accurate Real-Time)- SLAM的框架如下:该系统由多个不同模块组成,基本两个主块。第一个块是必需的(灰色),是ART-SLAM的核心,在输入点云上执行SLAM的所有模块(图中为橙色)。其他块是可选的,用于主系统与来自不同传感器数据集成,或和重新处理输入集成。
给定入射激光扫描,第一步是在预滤波器中进行处理,减小其尺寸并去除噪声。过滤后的点云同时发送到两个模块。最重要的模块是跟踪器,与先前滤波的扫描进行scan-to- scan匹配(比如实用方法 ICP, GICP, VGICP 和 NDT),估计机器人当前位移。另一个是地面检测器,发现机器人相对地面的姿势,增加对轨迹的高度和旋转一致性。当前姿势估计连同其对应点云一起发送到闭环检测器(基于SC算法)模块,在新点云和以前点云之间找到闭环,再次执行scan-to- scan匹配。此外,用姿势、闭环和地面系数(由地面检测器模块估计)构建pose graph,表征机器人的轨迹。最后,对pose graph进行优化,以提高姿态估计精度。
IMU和GPS数据(图中粉红色区域)可以集成在pose graph生成器模块,提高估计轨迹的精度。此外,预计算里程计(例如,通过不同的传感器或系统)可以作为scan matching的初始猜测提供给跟踪器。最后,预跟踪器模块(图中绿色区域)执行多级scan-to- scan匹配,在跟踪之前快速估计机器人运动。
每个模块的架构如下:它由一个或多个observers、一个或多个dispatch队列、一个core和一个或多个notifiers组成。此外,ART-SLAM是一种零拷贝软件,允许对大量数据进行完善改进,同时将其保存在内存中。
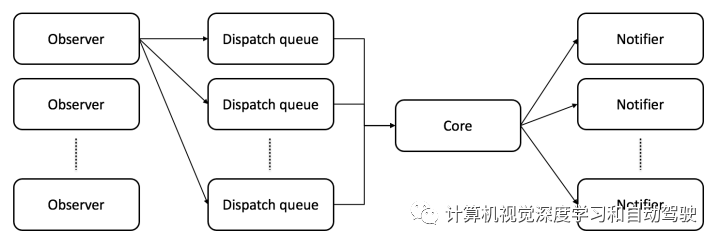
observer允许模块在数据可用时立即捕获数据,与类型无关。由于数据到达速率可能不同于处理所需时间,observer将接收到的数据放入一个或多个dispatch队列,即FIFO结构,避免丢失传入数据。模块中core是主要特点:一次为每个dispatch完善改进一个数据,从相对dispatch队列中提取数据。一旦core完成任务,会将模块的副产品发送给notifier程序,将这些副产品广播给所有需要的模块。使用dispatch队列的优点是,如果不需要时间一致性,可以在多个线程并行执行相同core任务。
pose graph中的每个节点表示机器人的位置和在该位置获取的测量值(点云);此外,每个节点都与相应的关键帧相关联。两个节点之间的边,包含节点对应机器人姿势变换的概率分布。这些变换,要么是跟踪器模块在连续位置之间给出的里程计测量值,要么是通过两个关键帧之间获取的传感器测量值对齐来估计。由于传感器噪声和机器人里程计中的漂移,相关边只表示软约束且不固定。但是,可以插入绝对约束,不做任何方式修改。这些约束的示例包括地面系数、GPS或IMU数据,尽管也可以设置为非绝对约束,因为传感器或测量带有不确定性。此外,当执行闭环检测和进行闭合的时候,可以在图中的非连续节点之间添加新边。
以下图例是实验的算法结果比较:
Sequence 07 KITTI
Sequence 05 KITTI
5 “A Biologically Inspired Simultaneous Localization and Mapping System based on LiDAR Sensor“,September,2021
受啮齿动物的海马模型(rodent hippocampus)启发,本文提出一种基于激光雷达传感器的生物启发SLAM系统,用海马模型构建认知地图(cognitive map)并估计机器人在室内环境中的姿势。基于生物启发模型,SLAM系统用激光雷达传感器的点云数据,用来自激光雷达里程计的自运动线索和来自激光雷达局部视图单元(local view cells)的局部视图线索来构建认知地图和估计机器人姿势。
整个SLAM系统架构如下:包括激光雷达里程计,激光雷达局部视图单元和姿态单元网络(pose cell network)。
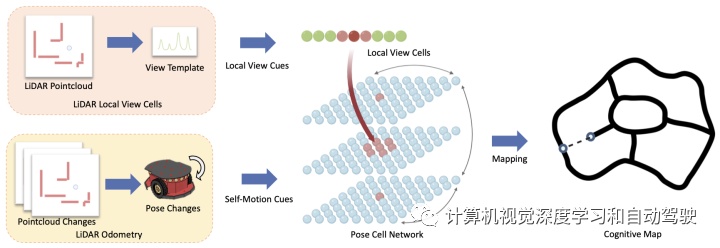
“激光雷达里程计“为机器人生成运动数据起着重要作用。“激光雷达局部视图单元”模块提供基于激光雷达观测处理和集成局部视图线索。”姿态单元网络“,根据”激光雷达里程计“的自运动数据和”激光雷达局部视图单元“模块的局部视图线索,通过路径积分和闭环,估计机器人的3-DoF姿态。
“激光雷达局部视图单元“模块,将激光雷达观测结果处理为视图模板(view templates),表示场景的特征信息。“激光雷达局部视图”模板用于维护局部视图,并向“姿势单元网络”提供局部视图线索信息。实时激光雷达观测输入与学习的局部视图进行比较,要么在成功找到匹配视图时生成一个姿势标定活动,要么在没有匹配视图时将其添加到学习的局部视图中,学习新局部视图。
一个局部视角的两步匹配(two-stage matching)算法如下:

该文由RatSLAM(“Ratslam: a hippocampal model for simultaneous localization and mapping,” IEEE ICRA’04)启发,提出姿势单元网络来保持姿势表征,集成来自激光雷达里程计的自运动线索和来自激光雷达局部视图单元的局部视图线索,旨在减少里程计漂移、解决制图过程中的局部视图多义性问题。利用姿势单元网络,SLAM系统能够基于自运动线索做路径积分来构建认知地图。此外,借助激光雷达视图线索,姿势单元网络执行闭环来标定估计的姿势和在线认知地图,以减少激光雷达里程计累积误差和漂移。
姿势单元网络是一个3D连续吸引网络,即3D-CAN(“Path integration and cognitive mapping in a continuous attractor neural network model,” Journal of Neuroscience, 1997),表征为活动的3D矩阵。姿势单元网络的每个姿势单元,通过兴奋性(excitatory)和抑制性(inhibitory)连接,与其相邻单元相连,以3-D形式围绕在网络的边界,这样姿势单元网络能够表征有限数量姿势单元的无界空间(unbounded space)。
姿势单元网络,加入基于3-D高斯分布的局部兴奋和全局抑制活动,随时间自更新姿势单元网络动力学。作为激活细胞聚集的姿势单元网络稳定状态,如OpenRatSLAM(“Openratslam: an open source brain-based slam system,” Autonomous Robots, 2013),姿势估计则编码为活动包(activity packet)质心。
给定来自局部视图单元的激光雷达局部视图线索,一个标定活动会注入姿势单元网络,执行进一步的闭环和重定位。为解决局部视图的多义性,当连续局部视图的更新超过阈值,让姿态单元的主活动包可以移动。
在制图过程中,激光雷达里程计、激光雷达局部视图单元和姿势单元网络的信息,组合和累积在一起估计机器人姿势,并构建认知地图作为机器人运动经验的拓扑图。当观察学习的局部视图检测到闭环时,在两个现有经验节点之间建立新的转换(transition),在认知图中带来新循环。
6 “Learning Efficient Multi-agent CooperativeVisual Exploration“,arXiv,October,2021
由清华大学和上海期智研究院发表。
任务是视觉多智体室内探索,其中智体用尽可能少的步骤合作探索整个室内。传统的基于规划方法,通常在每个推理步骤都会遭遇特别昂贵的计算以及协作策略有限的表现力。相比之下,强化学习(RL)具备任意复杂策略的建模能力和最小推理开销,所以成为应对这一挑战的一种趋势典范。
本文引入一种基于RL全局目标规划器,即空间协调规划器(Spatial Coordination Planner,SCP),将单智体RL解决方案,即主动神经SLAM(Active Neural SLAM,ANS),扩展到多智体环境,以端到端的方式,利用每个智体的空间信息有效地引导智体,以高探索效率对不同的空间目标导航。
SCP组成包括两个:一个基于transformer的relation encoder用于捕获智体内交互,和一个spatial action decoder生成准确目标。此外,实现一些多智体增强功能,处理来自每个智体的局部信息,实现对齐的空间表征和更精确的规划方案。最终的解决方案,即多智体主动神经SLAM(Multi-Agent Active Neural SLAM,MAANS),结合所有这些技术,在视觉逼真的物理试验台Habitat中,进行实验。
基于规划的解决方案已被广泛应用于单智体和多智体场景中的机器人导航问题。基于规划的方法只需要很少的训练,可以直接应用于不同的场景。然而,这些方法通常在协调策略上的表现力有限,需要对每个测试场景进行不同寻常的超参数调整,由于在每个决策步骤重复重规划,因此特别耗时。
相比之下,强化学习(RL),对一些决策问题而言,包括各种视觉导航任务,是一种很有前途的方案。基于RL的智体通常被参数化为深度神经网络,并根据原始传感器信号直接生成动作。一旦策略通过RL算法得到很好的训练,机器人就可以捕获任意复杂的策略,并通过高效的推理计算(即神经网络的单次前传)生成实时决策。然而,训练有效的RL政策可能特别具有挑战性。因此,大多数现有的机器人探索问题,其RL方法集中在单智体设置上,而大多数多智体RL方法,仅在迷宫(maze)或网格世界等简单场景下进行评估。
如图是原ANS的框架:根据传入的RGB观测和传感器数据,预测地图和智体姿势估计。全局策略使用该地图和姿势输出长期目标(long-term goal),用分析路径规划器转换为短期目标(short-term goal)。训练一个局部策略,实现这一短期目标。
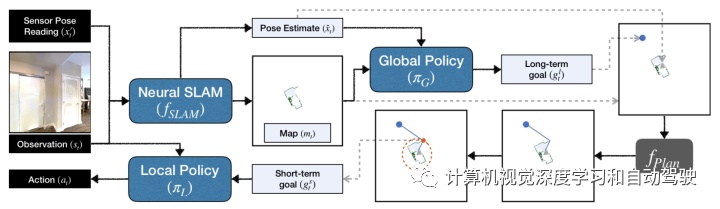
这里全局规划器采用增强的以智体为中心的局部地图作为输入,包括指示已探测区域、未探测区域及障碍和历史轨迹的通道,从长期目标坐标的两个高斯分布中输出两个实数。该全局规划器被参数化为CNN策略,并通过PPO算法进行训练。
而局部规划器在智体为中心的局部地图执行经典规划,即FMM(Fast Marching Method)算法,实现给定的长期目标,并输出短期子目标的轨迹。最后,局部策略生成给定RGB图像和子目标的动作,并通过模仿学习进行训练。
如图是ANS中Neural SLAM架构:该模块通过监督学习进行训练,以RGB图像、姿势感知信号及其过去的输出作为输入,并输出更新的2D重建地图和当前姿势估计。

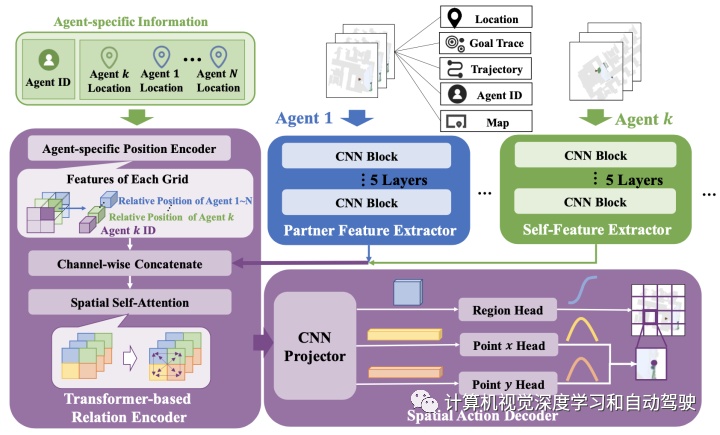
如图是本文提出的MA-ANS新框架:
每个智体首先将其姿态感知信号和RGB图像传递给NeuralSLAM模块,获得智体为中心的局部地图和姿态估计。地图细化(map refiner)对每个局部地图进行规范化,并与其他特定于智体的信息结合,作为空间协调规划器(SCP)的输入全局地图。对ID=k的每个智体,SCP接收ID信息,在所有输入地图的提取特征应用基于transformer的关系编码器(relation encoder),并通过智体k的空间动作解码器(spatial action decoder)生成全局目标。局部规划器在合并的全局地图上为全局目标执行轨迹规划。最后,由局部策略生成一个动作。
如图是SCP模块示意图:包括N个CNN-based feature extractors, 一个relation encoder 和一个 spatial action decoder。
如图是地图细化(map refiner)和地图合并(map merger)的计算工作流:

“地图细化“,首先合成所有以前以智体为中心的局部地图,恢复以智体为中心的全局地图。然后,基于姿势估计变换坐标系,规范化来自同一坐标系的所有智体全局地图。相应地规范化的全局地图,包含围绕实际可探测室内区域的无法探测的大边界。为了确保SCP的特征提取只关注可实现部分,并导致更集中的空间动作空间,裁剪归一化地图的不可解释边界,并放大室内区域作为最终的细化地图。
在“地图细化”获得N个放大的全局地图后,“地图合并”对每个像素位置应用max-pooling操作简单地集成这些地图。也就是说,对于合并的全局地图的每个像素,成为障碍的概率是,在所有放大的全局地图中该像素位置的最大值。人工合并的全局地图仅用于局部规划器,而不用于全局规划器SCP。
7 “MegBA: A High-Performance and Distributed Library for Large-Scale Bundle Adjustment“,arXiv December,2021
旷视科技和爱丁堡大学发表。
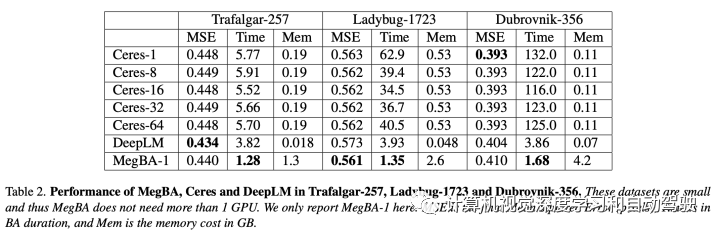
大规模BA是3D视觉应用的关键(例如,SfM和SLAM)。尽管重要,但现有BA库(如Ceres和g2o)对大规模BA的支持较差。这些库未充分利用加速器(即GPU),并且缺乏有效分配BA计算的算法,因此限制了BA问题的规模。本文提出MegBA,一个用于大规模BA的高性能分布式库。MegBA有一种端到端矢量化BA算法,可以在GPU上完全释放大量并行核,从而加快整个BA计算。它还具有一种精确分布式BA算法,可以自动划分BA问题,并用分布式GPU解决BA子问题。GPU用网络高效的集体通信(collective communication)同步中间求解状态,并且设计同步最小化通信成本。MegBA有一个内存高效的GPU运行,并公开了和g2o兼容的API。实验表明,在公共大型BA基准测试中,MegBA的性能比最先进的BA库(即Ceres和DeepLM)分别高出47.6倍和6.4倍。
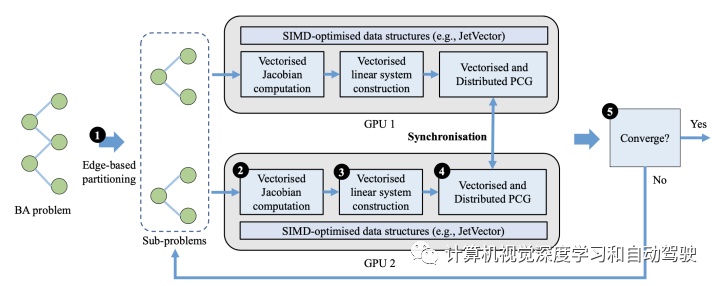
MegBA概览如图所示5步:(1) MegBA基于边划分BA问题;BA子问题的大小相同,调遣到分布式GPU;(2)在每个GPU用矢量化运算计算雅可比矩阵;(3) 采用矢量化运算构造线性系统;(4)采用矢量化分布式PCG算法求解线性系统,并通过集体通信同步中间PCG状态。迭代执行步骤(2)-(3)-(4),直到满足(5)收敛标准。
一个BA问题定义:
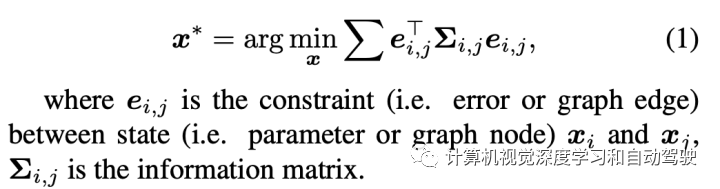
求解BA,经常利用Schur Complement (SC) ,即

求解该问题相当于一个等价方程求解,即
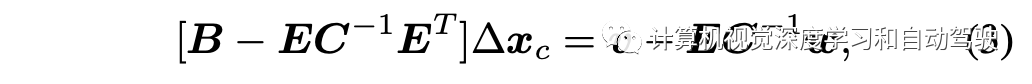
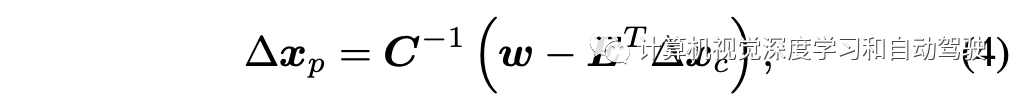
SIMD-optimised Vectorised BA的算法如下:

SIMD-optimised vertorised PCG的算法如下:
在高层看,MegBA分布式BA算法有两个主要组成部分:(i)一种可以将BA问题划分为子问题的方法,这些子问题可以由并行矢量化PCG解决;(ii)一种可以同步并行PCG状态的算法,以便可以共同解决原始全局BA问题。
distributed PCG算法如下所示:

在Nvidia GPU上实现MegBA,整个实现基于两项技术优化内存效率:
(i) 预测BA内存缓冲区使用,最小化内存分配;
(ii)在GPU线程之间共享内存。
与g2o和Ceres完全兼容的方式实现MegBA的API,MegBA API包含两个主要组件:
-
声明BA问题;
-
选择BA求解器。
性能比较结果见表:
8 “Fast Direct Stereo Visual SLAM“, arXiv,December,2021
作者来自美国明尼苏达大学。
本文提出一种不依赖于特征检测和匹配的快速、准确的立体视觉SLAM方法,DSV(direct-stereo-vision)-SLAM。将单目DSO(Direct Sparse Odometry)方法扩展到立体视觉系统,通过优化3D点尺度来最小化立体视觉的光度(photometric)误差;与传统的立体匹配相比,这是一种计算效率高且鲁棒的方法。进一步扩展到有闭环的完全SLAM系统,减少累积误差。在假设摄像机向前运动的情况下,从视觉里程计获得3D点,模拟激光雷达扫描,用激光雷达点云描述子进行位置识别,更有效地检测闭环。然后,用直接对齐法(direct alignment)估计相对姿态,最小化潜在闭环的光度误差。可选地是,用ICP(Iterative Closest Point)算法对直接对齐方法进一步改进。最后,优化一个pose graph,提高全局SLAM精度。因为避免SLAM系统的特征检测或匹配,确保较高的计算效率和鲁棒性。对公共数据集的彻底实验,验证表明其有效性。
代码开源:https: //github.com/IRVLab/direct_stereo_slam
如图是该方法DSV-SLAM的概览:将尺度优化和基于激光雷达描述子的位置识别方法结合到直接立体视觉SLAM系统中,(1) 从Cam0开始,单目VO估计摄像机姿势并生成3D点;(2) Scale Optimization模块用3D点估计并保持VO尺度;(3) 闭环检测(loop closure detection)模块基于VO的3D点检测闭环;(4) 对于潜在闭环,Loop Correction模块估计闭环的相对姿势,并全局性优化姿势。
尺度优化方法取自作者论文(“Extending Monocular Visual Odometry to Stereo Camera Systems by Scale Optimization”. IROS, 2019),优化的主要思想是将Cam0的单目VO点投影到Cam1,找到使光度误差最小的最佳尺度。
而基于激光雷达描述子的闭环检测取自作者论文(“A Fast and Robust Place Recognition Approach for Stereo Visual Odometry Using LiDAR Descriptors“. IROS, 2020)。从VO局部累积3D点,获得一组局部点,然后围绕当前姿势生成一组Spherical Points,模拟激光雷达扫描。
SC算法的主要思想是使用城市区域(例如建筑物)的高度分布来描述激光雷达生成的点云。原始SC将点云相对于 IMU 重力方向对齐。由于不希望引入额外的传感器(即IMU)到视觉SLAM系统中,因此用PCA来对齐点云。水平面(PCA 平面)根据半径和方位角划分为多个bins。每个bin的最大高度连接起来,形成当前位置的签名(signature)。在SC算法之前用ring-key进行快速初步搜索,SC编码半径确定每个ring的occupancy ratio 。
如图所示即模拟激光雷达扫描ring-key和SC描述子的简化图(假设建筑物和树木的高度分别为10米和3米):
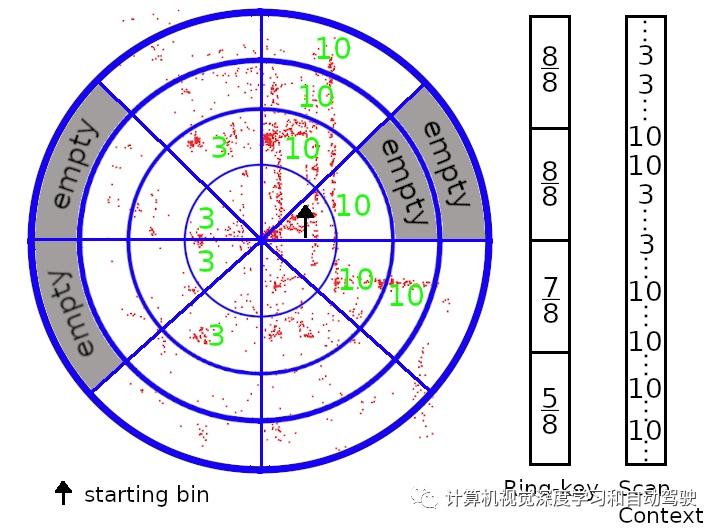
系统中,对于立体视觉VO的每个关键帧,该方法模拟激光雷达扫描,并用修改SC描述子生成位置签名。然后,在签名数据库(signature database)搜索潜在的闭环。首先通过ring-key进行搜索,其操作速度快,但不易区分,因此我们选择前三位候选做SC,这样再做出最终决定。
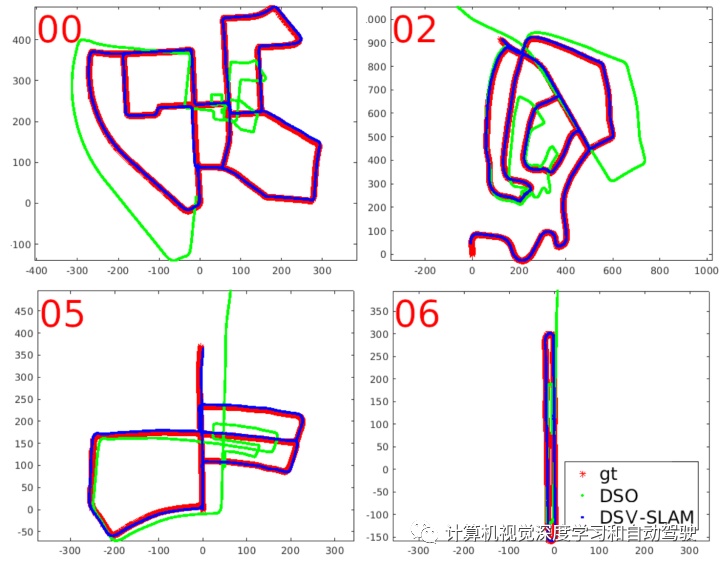
一些实验结果比较如下:



编辑推荐



最新资讯
-
漫说信息智能 · 电动车防晕车大作战
2025-04-27 16:28
-
R171.01对DCAS的要求⑨
2025-04-27 15:29
-
智驾标准法规体系大全
2025-04-27 15:28
-
国内最大汽车创作者大会开幕,懂车帝投入5
2025-04-27 13:18
-
大卓智能端到端直播实测,16公里复杂路段挑
2025-04-25 17:16
