




 广告
广告





















































一种规划控制和仿真的交通预测实时联合概率方法 PredictionNet
2022-01-15 08:46:47· 来源:计算机视觉深度学习和自动驾驶 作者:黄浴

arXiv上2021年9月23日上传的论文“PredictionNet: Real-Time Joint Probabilistic Traffic Prediction for Planning, Control, and Simulation“,作者来自Nvidi
arXiv上2021年9月23日上传的论文“PredictionNet: Real-Time Joint Probabilistic Traffic Prediction for Planning, Control, and Simulation“,作者来自Nvidia美国总部。

预测交通智体的未来运动对于安全高效的自动驾驶至关重要。为此,这里提出PredictionNet,一种深度神经网络 (DNN),可预测所有周围交通智体的运动以及自车的运动。所有预测都是概率性的,允许任意数量智体采用简单的顶视光栅化图像表示。以带车道信息的多层(multi-layer)地图为条件,该网络一次传播计算得到包括自车在内的所有智体共同输出的未来位置、速度和回溯向量(backtrace vector),然后在输出结果中提取轨迹。
该网络可用于模拟真实交通,在流行的基准测试结果具有竞争力。更重要的是,将其与运动规划/控制子系统相结合,已成功控制现实世界车辆驾驶数百公里。该网络在嵌入式 GPU 的运行速度超过实时要求,由于选择了输入表征方法,系统显示出良好的泛化性(跨感知模块及位置)。此外,通过强化学习 (RL) 扩展 DNN,可以更好地处理罕见或不安全的事件,例如激进机动和碰撞现象。
作者想寻求一种系统,可以联合预测所有参与者的运动,不受参与者数量的限制,与输入的感知模式无关,可以实时运行,并能够处理罕见/不安全事件。
如图是PredictionNet在自动驾驶应用的一个简化示意图:
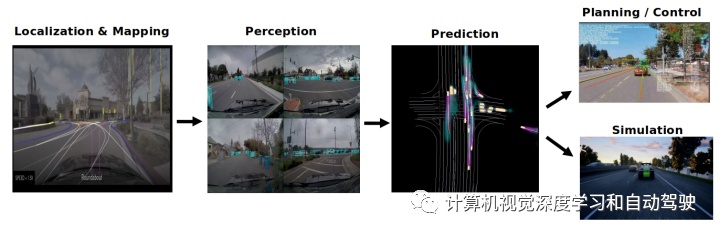
该交通预测方法依赖于单个深度神经网络,将当前交通场景输入转换为包括自车的所有交通智体所预测的未来运动,以及后处理步骤支持提取轨迹,如图所示:
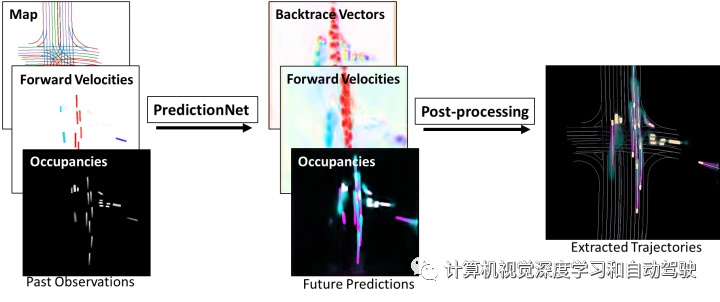
顶视图的光栅交通场景,由单独的系统(摄像头、雷达和/或 LiDAR)感知,得到包括自车和周围所有交通智体的数据以及当前地图(例如车道分隔线)。这种方法使得网络在没有任何额外计算情况下,预测任意数量交通智体的运动。图中速度和矢量使用标准光流彩色图显示,而占用情况和轨迹的可视化及时从洋红色过渡到青色。最右侧的黄色框显示当前车辆。
为了总结过去的观察并通过单次前向传播预测未来,采用一个简单的 2D CNN 编码器 - 解码器,其带有两个 RNN,一个用于处理过去的输入,另一个用于预测未来。
如图是网络架构图:
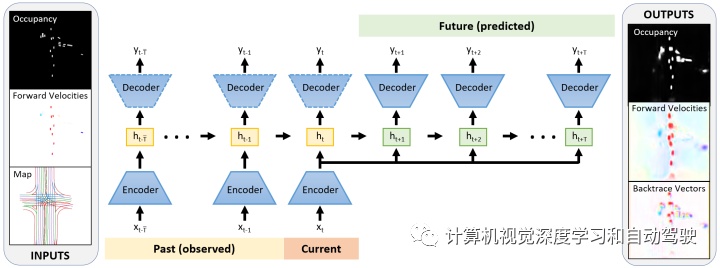
输入表示为图像,并用 CNN 编码到潜空间中,该空间由两个 RNN 序列模型共享。过去的 RNN(黄色)总结观察到的速度、占用情况以及地图。然后,一起推出潜状态与未来RNN的当前编码输入(绿色),估计未来的速度、占用情况以及回溯向量。未来帧的结果序列用于提取所有车辆的轨迹。以前解码器(虚线)结果仅用于训练。
网络训练采用端到端监督学习,其中占用情况采用focal loss,预测的回溯向量和速度采用L2 loss:
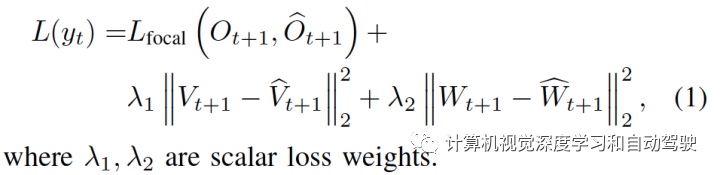
通过输出张量的后处理提取包括自车在内的所有车辆轨迹。从感知系统给定的初始位置和速度开始预测每个轨迹,用预测占用情况的张量作为置信信号,并用回溯向量进行漂移校正,通过对预测的速度张量进行积分,推出后续位置和速度估计。
整个计算公式如下:

采用真实世界数据进行训练后,PredictionNet 可以用作交通仿真模型。用真实数据初始化情节状态,用网络作为一个步进函数推出一个闭环离线模拟交通。通过这种方式,网络当作一个学习的状态转换动态函数,可用于模拟测试规划器,并通过强化学习 (RL) 学习策略。
如图是PredictionNet的RNN潜向量样本,获取过去智体交互和地图集合信息:

PredictionNet加上后处理,即对解码器输出拟合一个独轮车运动模型,然后闭合这个环。如图是PredictionNet的交通仿真例子:

绿框表示自车,蓝框是其他参与者,洋红色线表示预测。PredictionNet 能够在具有不同拓扑结构的不完整地图生成真实的交通结果。
由于 PredictionNet 通过监督学习进行训练,可将其视为一种模仿学习。模仿学习的一个缺点是无法处理训练数据中没有正确捕获的罕见/不安全事件,例如可能导致碰撞的切入和猛烈刹车。为了解决这些问题,用基于模型的 强化学习(RL )框架,将驾驶问题表述为一个 MDP,以 PredictionNet 作为转换模型。训练一个额外的策略头来产生自行动,称为扩展版,即PredictionNet-RL。
网络架构细节如下表所示:
在开源数据INTERACTION的实验结果如下:
这个结果来自内部 LiDAR 感知数据生成的数据集。该数据集是高速公路和城市场景的混合,包含轻载和重载交通,包含 5000 多公里。测试方法优于依赖车道跟随和恒速假设的分析基准。

如图展示的是对上述内部激光雷达数据的Final Displacement Error (FDE)性能:

再将 PredictionNet 系统集成到一个驱动车辆中。用 DNN 预测未来 3 秒,然后用分析预测器外推结果 3 到 5 秒。选择这种组合是准确性和性能之间的权衡:DNN 在 3 秒范围内对重要事件做出反应,而分析外推减少了运行延迟。
为了量化性能,假设好的预测会导致更好的规划避免急刹车或紧急脱离,从而提高驾驶舒适度。这里每条路线都被分成几段,每段计算平均抖动(加速度的导数)。根据人类驾驶员试验的阈值将每段分类为“舒适”或“不舒适”。最终得分是轨迹的“舒适”路段百分比。
该系统用于华盛顿州和加利福尼亚州一共约 530 公里路线的驱动。即使是用激光雷达相关数据进行训练的,该网络消费来自摄像头和雷达的感知输出。没有遇到与网络相关的安全脱离现象。
基于包含随机地图丢失的训练程序,DNN 能够处理现实世界中的非地图区域。与分析基准相比,PredictionNet 将平均舒适度分提高了 15%,并将标准偏差降低了 18%。PredictionNet 的计算效率也非常高。在嵌入的NVIDIA Drive AGX 计算机上,DNN 推理时间约为 5 毫秒,预处理/后处理时间为 3 毫秒。如下表是仿真失败率的比较结果:

而扩展版PredictionNet-RL 使用 Soft Actor Critic (SAC) 算法训练策略和critic头,同时保持 PredictionNet 主干权重保持不变。如下表是10个测试情节的失败率在切入和紧急刹车的策略学习比较结果:

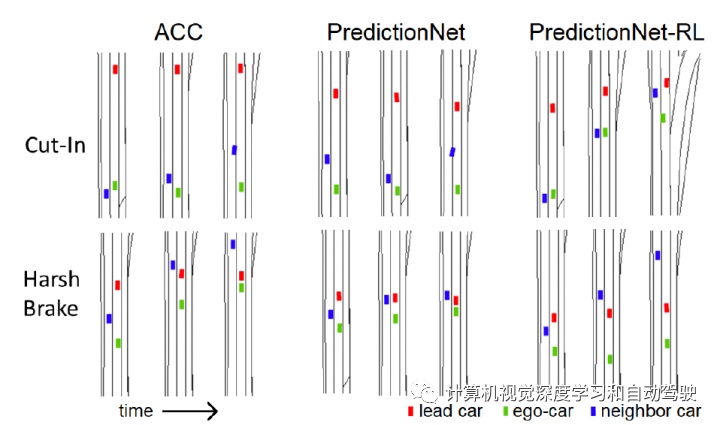
如图是量化结果比较:ACC、PredictionNet-RL 和 PredictionNet。
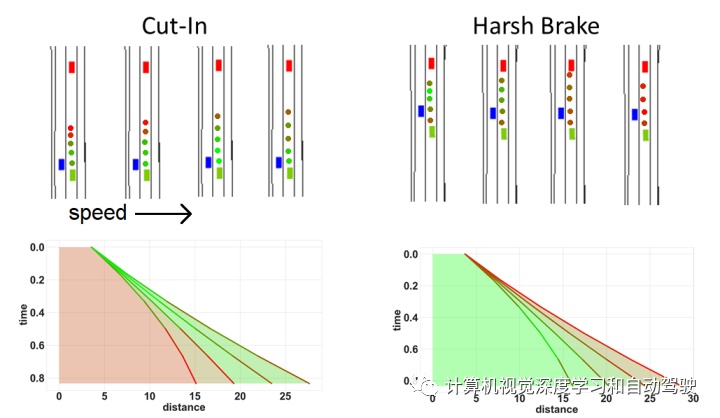
如图是学习的RL价值函数比较:四个可能的速度下。
一个基于机器训练的预测系统提供了一个有效的数据驱动的交通模拟器,其性能明显优于基于启发式的基线。此外,基于 RL 的系统扩展实验表明,对于专家数据未捕获的罕见事件,有显着的改进。
- 下一篇:你需知道的12点振动疲劳知识
- 上一篇:ChaoJi充电详细解读



编辑推荐




最新资讯
-
自动驾驶卡车创企Kodiak 将通过SPAC方式上
2025-04-19 20:36
-
编队行驶卡车仍在奔跑
2025-04-19 20:29
-
全国汽车标准化技术委员会汽车节能分技术委
2025-04-18 17:34
-
我国联合牵头由DC/DC变换器供电的低压电气
2025-04-18 17:33
-
中国汽研牵头的首个ITU-T国际标准正式立项
2025-04-18 17:32
