




 广告
广告





















































ICCV‘21论文:通过概率建模深度检测目标的主动学习法
2022-01-16 09:31:05· 来源:计算机视觉深度学习和自动驾驶 作者:黄浴

ICCV’21论文"Active Learning for Deep Object Detection via Probabilistic Modeling",作者来自Nvidia、韩国首尔大学和德国慕尼黑工大。主动学习旨在选择数据
ICCV’21论文"Active Learning for Deep Object Detection via Probabilistic Modeling",作者来自Nvidia、韩国首尔大学和德国慕尼黑工大。

主动学习旨在选择数据集信息量最大的样本来降低标记成本。现有的工作很少涉及目标检测的主动学习。大多数方法是基于多模型或者是分类方法的直接扩展,因此仅用分类头来估计图像的信息量。本文提出一种用于目标检测的深度主动学习方法,依赖于混合密度网络(mixture density networks),估计每个定位头和分类头输出的概率分布。在单模型的单次前向传递计算,它明确地估计两种不确定性,即aleatoric 和 epistemic。该方法用一个评分函数,将这两种类型的不确定性聚合起来,获得图像的信息量分数。在 PASCAL VOC 和 MS-COCO 数据集,证明了其有效性。
代码开源:GitHub - NVlabs/AL-MDN: Official pytorch implementation of Active Learning for deep object detection via probabilistic modeling (ICCV 2021)
如图所示,是该方法的示意图:

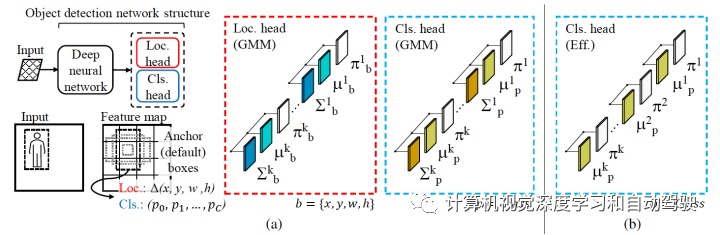
而下图是该目标检测框架的概览:与传统目标检测器的主要区别在于定位头和分类头(两个分支)。a)不具有确定性输出,而是为每个输出学习 K 分量 GMM 的参数:定位头的边框坐标和分类(置信度)头的类密度分布;b) 从 GMM 的分类头中消除方差参数,提高分类头效率。
基于GMM,得到两个不确定性的估计:
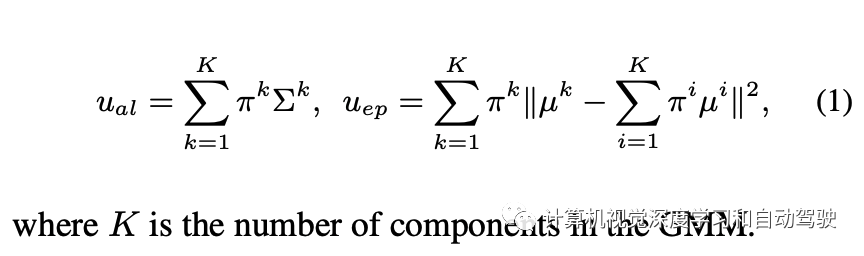
GMM的参数估计如下:
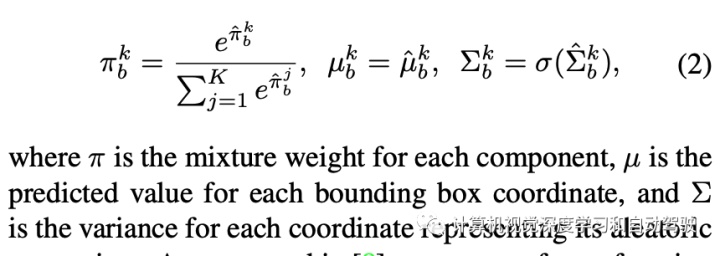
定位损失(回归)函数定义如下:

类概率分布定义为:
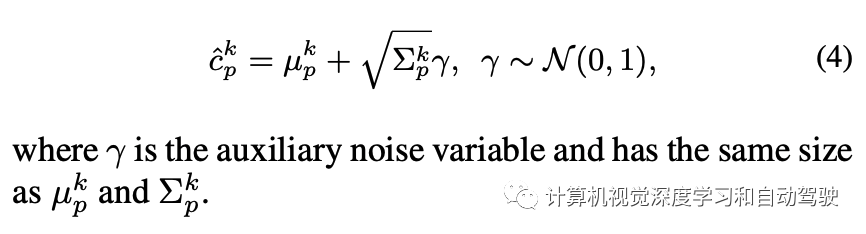
分类损失定义为:

最后,总损失定义为:
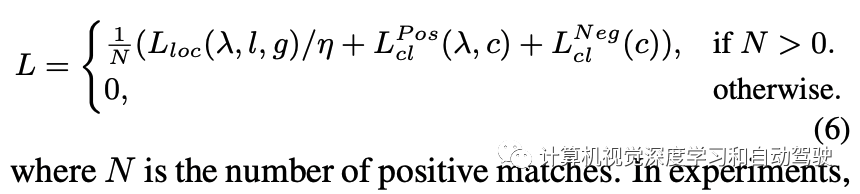
而推理的输出即定位和分类的结果:
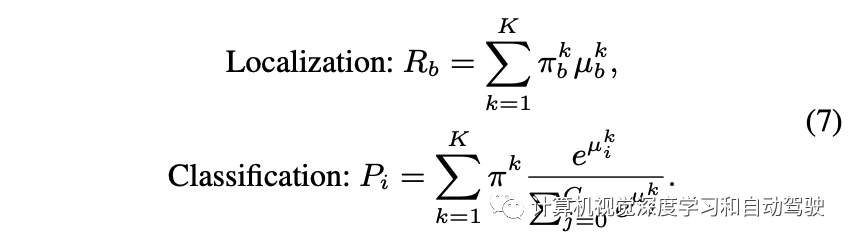
最后,高效的aleatoric uncertainty计算是:

为此修正分类损失函数定义:
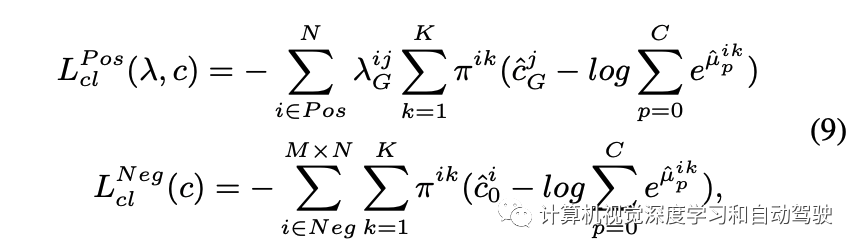
主动学习的评分函数为每个图像提供一个单值表明其信息量。评分函数通过聚合图像中每个检测目标的两种不确定性值来估计图像的信息量。
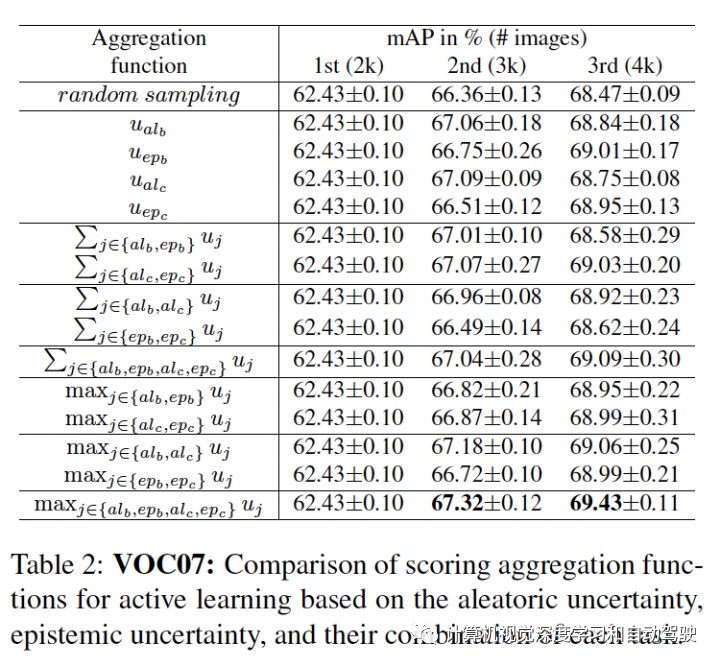
具体来说,让 U = {uij } 是一组图像的不确定性集,其中 uij 是第 i 个图像第 j 个目标的不确定性。对于定位,uij 是 4 个边框输出的最大值。首先,z-score 归一化 (u ̃ij = (uij − μU )/σU ),补偿一个事实:边框的坐标值是无界的,并且图像的每个不确定性可能有不同的范围。然后,对每个图像分配检测目标的最大不确定性 ui = maxj u ̃ij。凭经验发现,在坐标和目标上取最大值比取平均值要好。
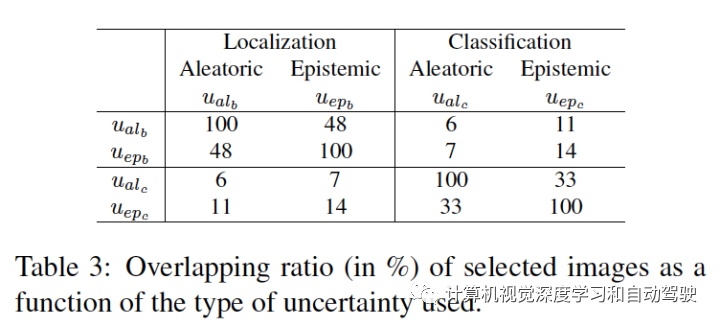
用上述算法,每个图像获得四个不同的归一化不确定性值:用于分类和定位的两个不确定性,分别为 u = {uiepc , uialc , uiepb , uialb }。剩下的部分是将这些分数聚合成一个。聚合这些不确定性评分函数得到不同组合,包括求和或取最大值。正如在实验中展示的那样,取最大值会获得最高评分。
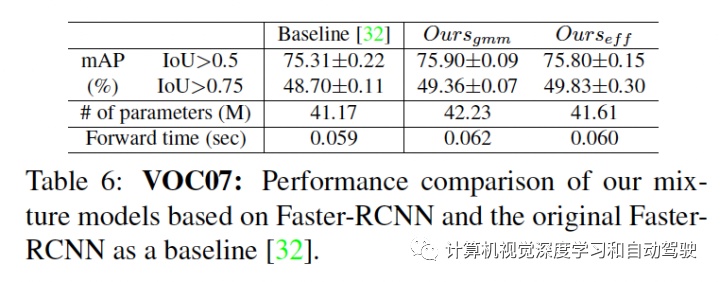
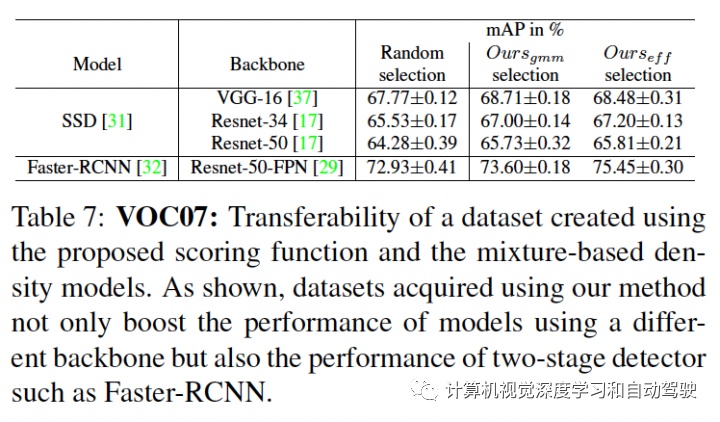
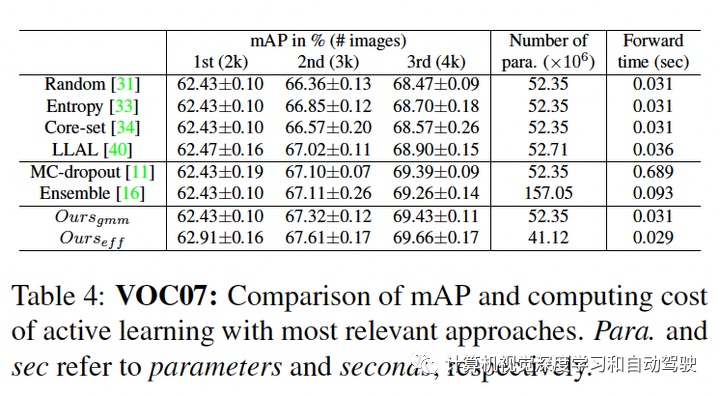
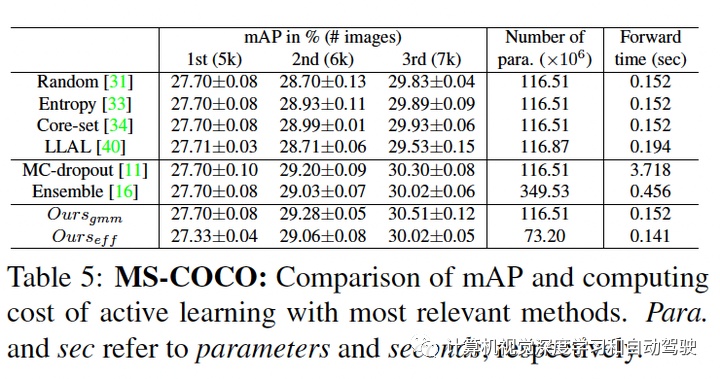
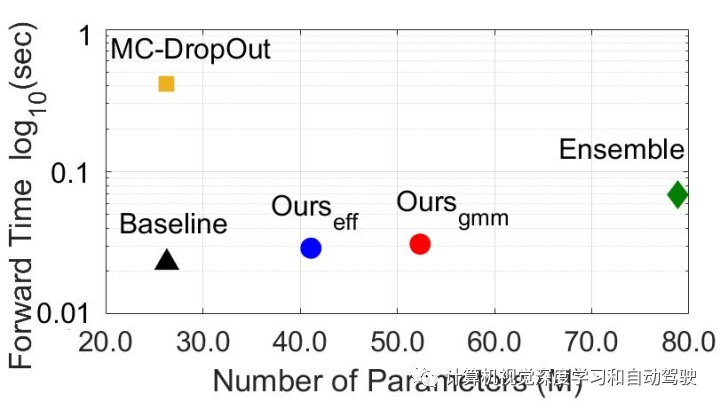
实验结果如下:采用SSD方法和Faster RCNN做检测
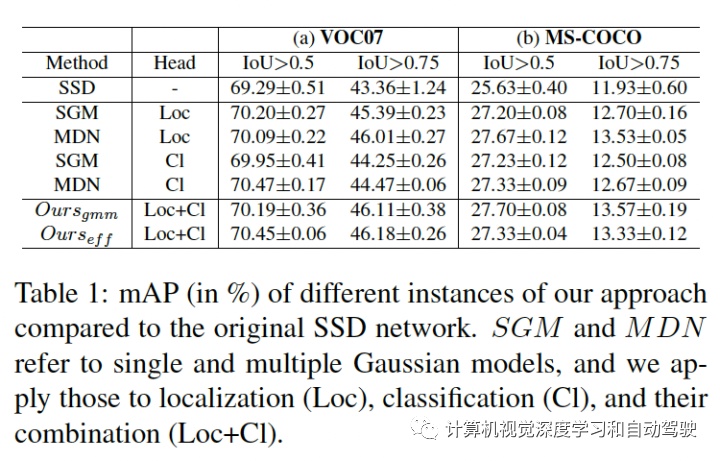
比较多模型方法:ensemble和MC-dropout。

- 下一篇:天津检验中心新能力:侧碰滑台系统试验能力
- 上一篇:电动汽车电机及控制器性能测试系统



编辑推荐




最新资讯
-
全球首次!IVISTA 2023版修订版引入带灯光
2025-04-28 09:59
-
我国首批5G毫米波行业标准送审稿审查通过
2025-04-28 08:56
-
5/16 厦门- 新能源汽车电驱测试技术的创新
2025-04-28 08:53
-
国内首个汽车电磁防护技术验证体系EMTA正式
2025-04-28 08:49
-
一文带你了解滤波器
2025-04-28 08:35
