




 广告
广告





















































一篇关于广义OOD检测的最新综述
2022-01-17 19:21:12· 来源:计算机视觉深度学习和自动驾驶 作者:黄浴

arXiv在2021年10月21日上传的论文“Generalized Out-of-Distribution Detection: A Survey“,作者来自新加坡的南洋理工大学(NTU)和美国的威斯康星大学Madison
arXiv在2021年10月21日上传的论文“Generalized Out-of-Distribution Detection: A Survey“,作者来自新加坡的南洋理工大学(NTU)和美国的威斯康星大学Madison分校。

OOD(Out-of-distribution)检测对确保机器学习系统的可靠性和安全性至关重要。例如,在自动驾驶中,希望驾驶系统在检测以前从未见过的异常场景或目标并且无法做出安全决策时,要发出警报并将控制权移交给人(安全员)。
OOD检测已经开发了大量方法,从基于分类的、基于密度的、到基于距离的方法。同时,其他几个问题在动机和方法论方面都与 OOD 检测密切相关。包括异常检测 (AD,anomaly detection)、新颖性检测 (ND,novelty detection)、开放集识别 (OSR,open set recognition) 和异常值检测 (OD,outlier detection)。尽管有不同的定义和问题设置,这些问题经常使大家感到困惑。
该综述提出了一个广义 OOD 检测的通用框架,包含上述五个问题,即 AD、ND、OSR、OOD 检测和 OD。这五个问题,可以看作是该框架的特例或子任务。
现有的机器学习模型大多基于封闭世界假设进行训练,其中假设测试数据是来自与训练数据相同的分布,称为in-distribution (ID)。然而,当模型部署在开放世界场景时,测试样本可能是OOD。分布漂移可能由语义漂移(例如,OOD 样本来自不同类)或covariate shift(例如,来自不同域的 OOD 样本)引起。这里主要讨论语义漂移检测。
综述聚焦于计算机视觉和基于深度学习的方法,基本分成4个类:
-
1) 基于密度的方法
-
2) 基于重建的方法
-
3) 基于分类的方法
-
4) 基于距离的方法
如图是本文提出的广义OOD检测框架:包括 anomaly 检测 (AD), novelty 检测 (ND), open set 识别 (OSR), out-of- distribution 检测 (OOD)和outlier 检测 (OD) 。
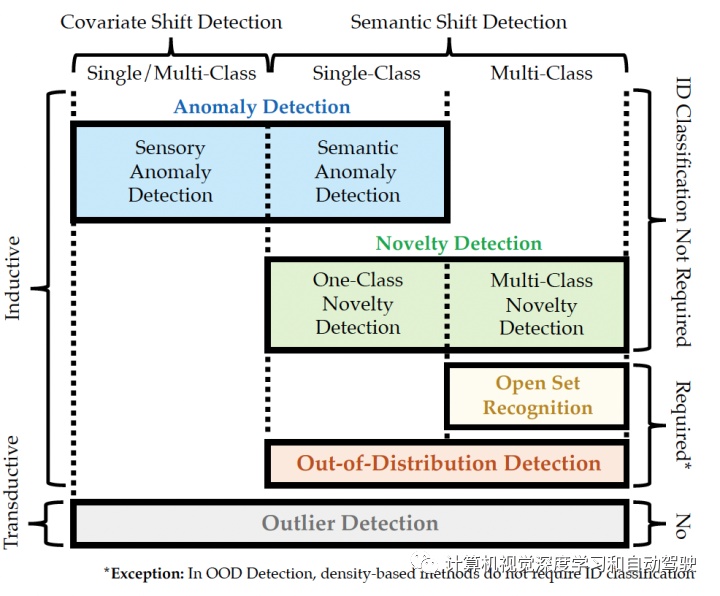
Taxonomy of generalized OOD detection framework
异常检测 (AD)
AD旨在检测在测试期间偏离预定义正态性的任何异常样本。偏差可能由于covariate shift或语义漂移而发生,同时假设其他分布漂移不存在。这带来两个子任务:感官 AD 和语义 AD。
感官AD 检测 covariate shift 的测试样本,基于正态性来自相同协变量分布的假设。语义 AD 检测有标签漂移的测试样本,基于正态性来自相同的语义分布(类别)假设,即正态性应该只属于一个类。
感官AD 仅关注具有相同或相似语义的目标,并识别其表面的观测差异。具有感官差异的样品被识别为感官异常。示例应用包括对抗防卫、biometrics和艺术品的伪造识别、图像取证、工业检查等。一种流行的现实世界 AD 基准是用于工业检测的 MVTec。
与感觉 AD 相比,语义 AD 只关注语义漂移,不存在covariate shift。实际应用的一个例子是犯罪监控。特定类的活跃图像爬虫也需要语义 AD 方法来确保收集的图像纯度。
新颖性检测(ND)
ND旨在检测不属于任何训练类别的任意测试样本。检测的新样本通常是为未来的建设性程序准备,例如更专业的分析,或模型本身的步进学习(incremental learning)。根据训练类数目,ND 包含两种不同的设置:1)只一个类的新颖性检测(one-class ND);2)多个类新颖性检测(multi-class ND)。值得注意的是,尽管有很多in-distribution(ID)类,但多个类 ND 的目标只是将新样本与in-distribution区分开来。一个类ND和多个类 ND 都被表述为二元分类问题。
真实世界的 ND 应用包括视频监控、行星探索和步进学习。
开放集识别 (OSR,open set recognition)
OSR 要求多类分类器:(1)同时准确分类来自“已知的已知类”的测试样本,以及(2)同时检测来自“未知的未知类”的测试样本。
OSR 通常支持真实世界图像分类器的稳健部署,其拒绝开放世界的未知样本。
OOD(Out-of-distribution)检测
OOD检测旨在检测相对训练数据不重叠标签的测试样本。形式上,OOD 检测设置中的测试样本来自in-distribution(ID)语义漂移的分布。这个in-distribution(ID)数据可以包含单个类或多个类。当训练中存在多个类时,OOD 检测不应损害其in-distribution(ID)数据分类能力。
OOD检测的应用通常属于安全-紧要情况,例如自动驾驶。在构建算法基准时,OOD 数据集不应与in-distribution(ID)数据集有标签重叠。
异常值检测(OD)
OD旨在检测由于covariate shift或语义漂移与给定观察集中其他样本明显不同的样本。
虽然OD主要应用于数据挖掘任务,但也用于现实世界的计算机视觉应用,如视频监控和数据集清理。数据集清理的应用,OD通常用作主要任务的预处理步骤,例如从开放集噪声标签中学习、微监督学习(webly supervised learning)和开放集半监督学习。
如图是广义OOD检测框架的实例问题设置概览:
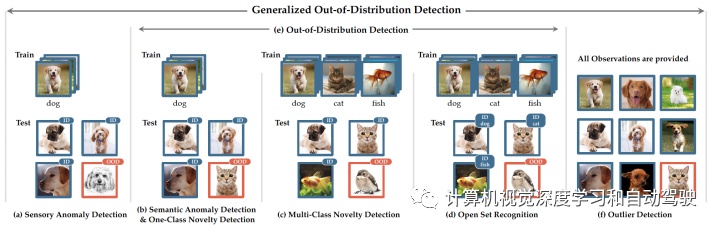
Exemplar problem settings for tasks under generalized OOD detection framework
尽管 OSR 和实际使用具有关联性,但仍然存在一些限制,比如在训练期间不允许额外的数据,以及对理论开放风险界限的必要保证。这些限制排除了更注重有效性改进但可能违反 OSR 约束的方法。另一方面,OOD 检测包含更广泛的学习任务和解决方案空间。
有趣的是,异常值检测(OD)任务可以被视为广义 OOD 检测框架中的异常值,因为异常值检测器(OD)是给定所有观察值,而不是遵循训练-测试方案。此外,在最近的深度学习领域很少看到这个主题的文章发表。然而,从直观上讲异常值也属于一种OOD。
相关的研究题目有以下5个领域:
-
带拒绝的学习
-
域自适应和域泛化
-
新颖性发现
-
零样本学习
-
开放世界识别(持续学习)
如下表是综述所选文献的广义OOD检测方法类别:
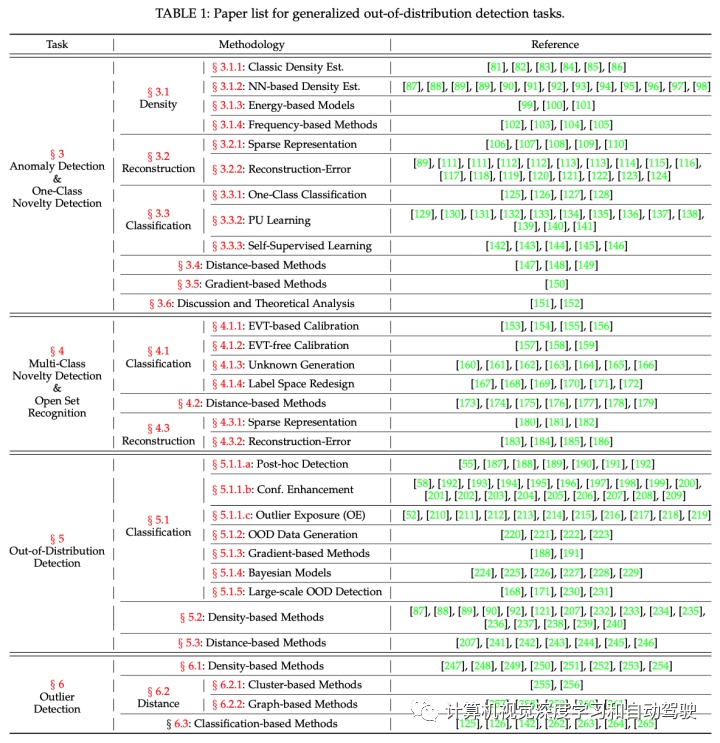
1 异常检测 (AD) 和单类新颖性检测(ND)
基于密度的方法试图对正常数据分布 (ID) 进行建模,并假设异常测试数据有低似然,而估计密度模型下的正常数据有高似然。其方法可细分成经典密度估计、深度生成模型的密度估计、基于能量的方法和基于频率的方法。
基于重构方法的核心思想是,在 ID 数据上训练的编码器-解码器框架通常会为 ID 和 OOD 样本产生不同的结果。模型性能的差异可以用作检测异常的指标。模型性能的差异可以在特征空间或通过重构误差来衡量。
基于分类的方法包括单类分类、正-无标注(PU)学习和自监督学习。异常检测(AD )和单类 新颖性检测(ND )通常被表述为一个无监督学习问题,其中整个 ID 数据属于一个类。分类器边界的想法已成功实现并标记为单类分类任务。PU学习是引入未标记数据进行训练的半监督异常检测(AD) 。自监督学习方法从两个方面解决 异常检测(AD )和单类新颖性检测(ND) 问题:(1)特征质量的增强可提高 AD 性能;(2) 一些设计良好的代理任务可以帮助揭示正常样本的异常数据。
基于距离的方法通过计算目标样本与许多内部存储样本或原型之间的距离来检测异常。这些方法通常需要内存训练数据。代表性方法包括 K-nearest Neighbors、基于原型的方法,以及基于聚类的方法和基于图的方法。
基于梯度的方法属于元学习或学习如何学习,根据学到的经验或元数据,系统地观察所学习任务或模型的内部机制。为了解决异常检测(AD )任务,一些方法观察在重构任务中正常和异常数据之间训练梯度的不同模式,因此基于梯度的表征可以描述异常数据。
2 多个类新颖性检测(ND) 和 开放集识别(OSR)
由于多个类 ND 和 OSR 在训练期间考虑多个类,因此大多数方法都是基于分类。替代方法可以是基于 ID 原型(距离)和基于重构,还有少量基于密度的方法。
基于分类的OSR方法,最初展示的是One-class SVM 和binary SVM。后来One-vs-Set SVM 处理开放集的风险是通过求解双平面优化问题而不是经典二元线性分类器的半空间。除了限制 ID 风险之外,还应该限制开放集空间。
基于距离的OSR方法要求原型是类条件的,即允许保持 ID 分类性能。基于类别的聚类和原型设计,往往是基于分类器提取的视觉特征。OOD样本计算相对聚类群的距离来检测。一些方法还利用对比学习为已知类学习更紧凑的聚类群,这也扩大了 ID样本 和 OOD 样本之间的距离。
基于重建的方法期望 ID 与 OOD 样本的重建行为不同。可在1)潜特征空间或2)重建图像的像素空间捕获差异。
注:由于仅限于用 ID 数据进行训练的限制,OSR 方法没有实现背景类别或异常值的暴露。
3 OOD检测
基于分类的OOD检测起源于一个简单的基线方法,即最大softmax概率作为ID数据指标得分。早期的 OOD 检测方法侧重于根据神经网络的输出得出改进的 OOD 分数。
基于密度OOD检测方法使用一些概率模型明确地对分布进行建模,并将低密度区域的测试数据标记为 OOD。尽管 OOD 检测与异常检测(AD)的不同之处在于分布中有多个类,但用于AD 的密度估计方法将 ID 数据统一为整体直接适用于OOD检测。当 ID 包含多个类时,类条件高斯分布可以显式地对ID进行建模,这样根据似然去识别OOD 样本。
基于流的方法也可用于概率建模。虽然直接估计似然似乎自然,但一些工作发现概率模型有时会为 OOD 样本分配更高的似然。总体而言,生成模型的训练和优化可能具有极高的挑战性,并且性能通常落后于基于分类的方法。
基于距离方法的基本思想是测试 OOD 样本应该远离ID类的质心或原型。
4 异常点检测(OD)
异常值检测需要观察所有样本,旨在检测那些显著偏离大多数分布的样本。OD 方法通常是transductive,而不是归纳(inductive)。虽然深度学习方法很少直接解决 OD 问题,但数据清理过程是从开放集噪声数据中学习,而开放集的半监督学习正在解决 OD 任务。
基于密度的OD,其基本思想将整个数据集建模为高斯分布,并标记出与平均值至少有三个标准偏差(three standard deviations)的样本。其他参数概率方法利用马氏距离和混合高斯分布来模拟数据密度。与“三个标准偏差”规则类似,四分位距(interquartile range)也可用于识别异常值,形成经典的非参数概率方法。局部异常值因子 (LOF,Local outlier factor) 通过自身及其邻域局部可达之比估计给定点的密度。
RANSAC迭代估计数学模型参数拟合数据并找到对估计贡献较小的样本作为异常值。通常,用于AD 的经典密度方法,例如核密度估计也适用于 OD。尽管这些方法受到维度灾难(curse of dimensionality)的影响,但可以通过降维方法和基于 NN 的密度方法来缓解。
基于距离检测异常值,一种简单方法是计算特定半径内的邻域样本数量,或测量第 k 个最近的邻域样本距离,包括基于聚类群的方法和基于图的方法。
AD 方法(例如孤立森林和OC-SVM)也适用于 OD 的设置。当数据集有多类时,深度学习模型——用异常值训练——仍然可以显示强大的预测能力并识别异常值。使用大型预训练模型进行数据清理在行业中也很常见。增强模型鲁棒性和特征泛化性的技术可用于此任务,例如集成法、协同训练和蒸馏等。
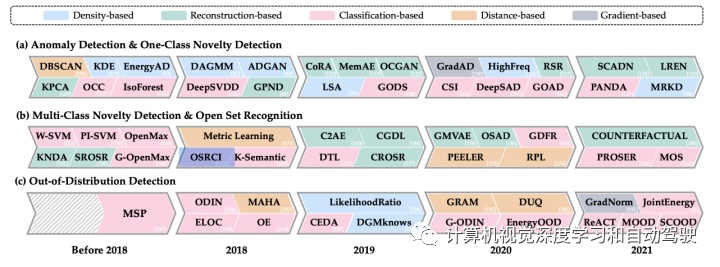
各种方法发表时间表如图所示:(a)异常检测(OD)和单类新颖性检测的代表性方法;(b)多个类新颖性检测和开放集识别;(c)OOD 检测。不同的颜色表示不同类别的方法论。每个方法在右下角都有其对应的参考文献(不显眼的白色)。由于深度学习时代计算机视觉方面的工作数量有限,没有在该图列出异常值检测(OD)方法。
最后说说广义OOD检测的挑战和未来研究方向。
挑战有几点:
-
合适的评估和基准
-
无异常点的OOD检测
-
分类和OOD检测的权衡
-
真实世界基准和评估
未来方向包括:
-
跨各子任务的方法论
-
OO D检测和泛化
-
OOD检测和开发集含噪标注
-
理论分析



编辑推荐




最新资讯
-
最高精度超过 350 公里
2025-04-16 09:34
-
直播 | 利用在环技术(XiL)优化转向系统
2025-04-16 09:29
-
奇石乐董事会任命两位新成员
2025-04-16 09:27
-
中汽中心工程院推出车载音频测试系统
2025-04-16 09:14
-
R171.01对DCAS的要求③
2025-04-16 09:09
