




 广告
广告





















































激光雷达检测的工作原理
2022-01-17 19:31:49· 来源:汽车ECU开发

简单来说,激光雷达(LiDAR)的原理是通过发射单元发射激光束,遇到障碍物后进行反射,并被接收单元捕获,通过测量每束激光飞行时间(TOF,TimeofFlight)来确定障碍
简单来说,激光雷达(LiDAR)的原理是通过发射单元发射激光束,遇到障碍物后进行反射,并被接收单元捕获,通过测量每束激光飞行时间(TOF,TimeofFlight)来确定障碍物的距离,并且构建点云。

当激光雷达的质量(价格)非常高时,每秒可以发射多达200万激光束,意味着有200多万个点云,点云代表3D世界,因为激光雷达获取的是每撞击点的准确三维坐标(X,Y,Z)。从而构建丰富的环境3D场景。

激光雷达的缺点是什么?
1. 激光雷达不能直接估计速度。他们需要计算两次连续测量之间的差异才能做到这一点。
2. 激光雷达在恶劣的天气条件下无法正常工作。在有雾的情况下,激光可以击中它并混淆场景。类似于雨滴或泥土。
3.激光雷达在尺寸方面很笨重——它们不能像相机或雷达那样隐藏起来。
4. 激光雷达的价格虽然在下降,但仍然很高。
激光雷达有哪些优势?
1.激光雷达可以准确估计障碍物的位置。到目前为止,我们还没有更准确的方法来做到这一点。
2.如果我们看到车辆前面的激光雷达生成的点云,即使障碍物检测系统没有检测到任何东西,我们也可以停下来。
使用 LiDAR 进行“对象检测”有两种主要方法:
1.用无监督机器学习技术
2.使用 3D 深度学习
下面主要介绍第一种方法,该方法主要有4个步骤:
1.点云处理;
2.点云分割;
3.障碍物聚集;
4.编辑框拟合;
01.点云处理——体素网格
体素网格是一个 3D 立方体,通过每个立方体只留下一个点来过滤点云。
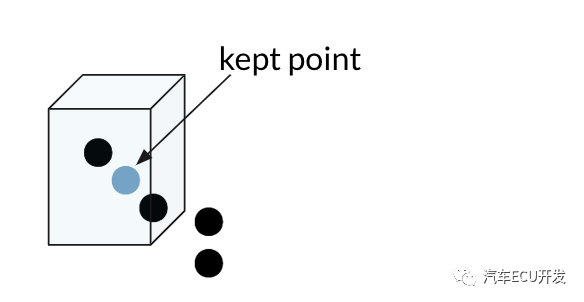
立方体越大,点云的最终分辨率越低。
最后,我们可以将云的采样从 100000点降低到只有几千点。
对点云就行采样处理完后,就可以进行分割、聚类和边界框的实现。
02.激3D分割——RANSAC
点云分割的任务是将障碍物从场景中区分出来。
RANSAC
一种非常流行的用于分割的方法称为RANSAC(随机抽样一致性算法),该算法的目标是识别一组点中的异常值。
点云的输出一般代表一些形状。有些形状代表障碍物,有些则简单地代表地面上的倒影。RANSAC 的目标是识别这些点并通过拟合平面或线将它们与其他点分开。
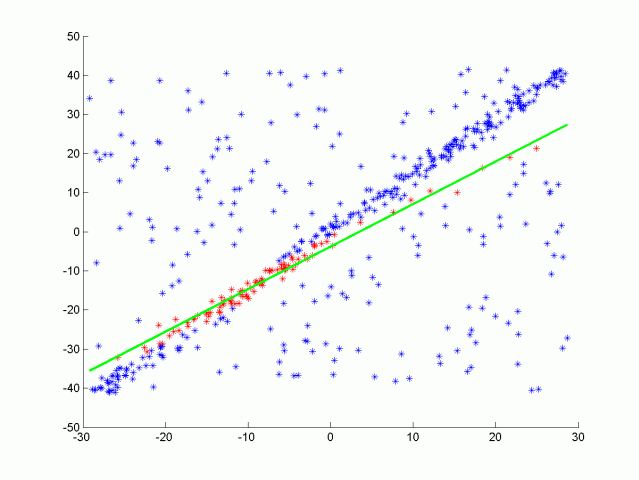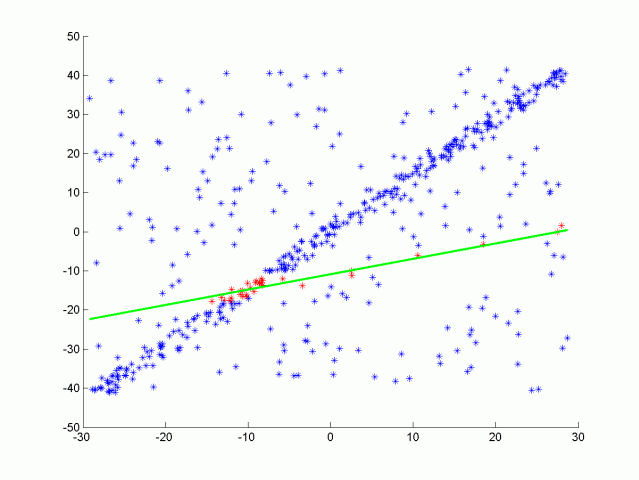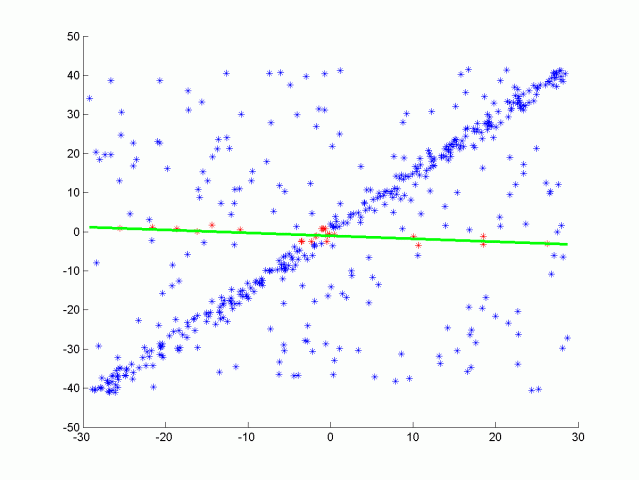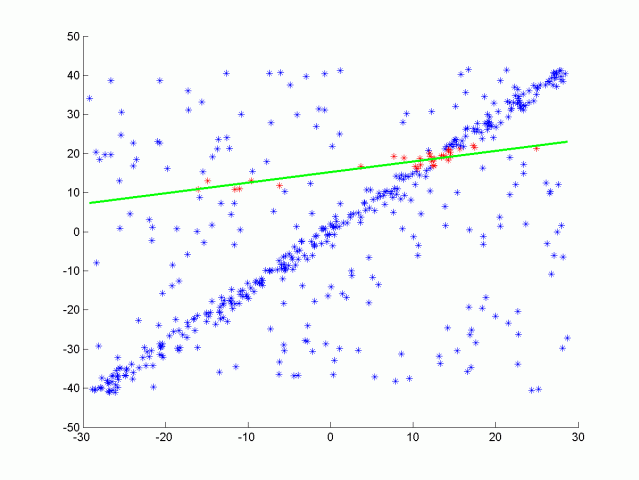
为了拟合一条线,我们可以考虑线性回归。但是有这么多的异常值,回归会试图平均结果并错过这条线。与线性回归相反,这里的算法将识别这些异常值。
我们可以将这条线视为场景的目标路径(即道路),将异常值视为障碍物。
它是如何工作的?
过程如下:
1、随机选择2个点
2、将线性模型拟合到这些点
3、计算每隔一个点到拟合线的距离。如果距离在定义的距离容差范围内,我们将该点添加到内层列表中。
因此它需要一个参数:距离容差。
最后,选择内层数最多的迭代作为模型;其余的都是异常值。这样,我们就可以把每一个内线都看作是道路的一部分,把每一个异常值都看作是障碍的一部分。
RANSAC 也适用于 3D。在这种情况下,3 点之间的平面是算法的基础。然后计算点到平面的距离。
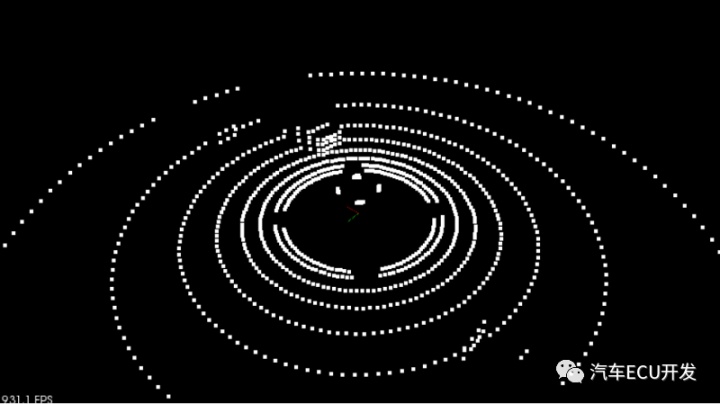
下图是点云上的 RANSAC 算法的结果。红色区域代表车辆,而地面为绿色。

RANSAC 是一种非常强大且简单的点云分割算法。它试图找到属于同一形状的点,以及不属于同一形状的点。然后,它可以分离云。
03.聚类-欧氏与KD树
RANSAC的输出是一个障碍点列表,一个道路点列表。由此,我们可以为每个障碍定义独立的簇。
聚类是一种根据点的距离将一组点分开的技术。考虑到上面的图像,我们有一些可见的障碍,我们需要算法本身来理解实际上有多辆车,并为每个障碍设置一种颜色。
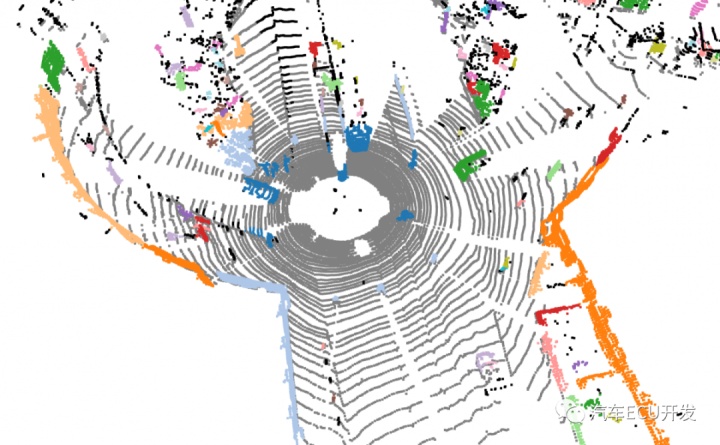
它是如何工作的?
聚类是一系列机器学习算法,包括:k-means(最流行的)、DBScan、HDBScan 等
我们可以简单地使用欧几里得聚类并计算点之间的欧几里得距离。
过程如下:
1、选择 2 个点,一个目标和一个当前点
2、如果目标与当前点之间的距离在距离容差范围内,则将当前点添加到集群中。
3、如果没有,请选择另一个当前点并重复。
聚类算法将距离容差、最小聚类大小和最大聚类大小作为输入。这样,我们可以过滤“幽灵障碍物”(无缘无故地在空间中的一点上的一个点云)并定义封闭障碍物的距离。
计算和 KD 树
上述技术的问题在于,一个 LiDAR 传感器可以输出 100,000 个点云。这将意味着 100,000 次欧几里得距离计算。为了避免计算每个点的距离,我们可以使用 KD 树。
KD树是一种搜索算法,它将根据点在树中的XY位置进行排序。一般的想法是,如果一个点不在一个定义的距离公差内,那么其x或y更大的点肯定不会在这个距离内。这样,我们就不用计算所有的点。

以上面的这种情况为例,底部的橙色点不低于距离容差阈值。我们可以删除这个橙色点右侧的每个点,因为我们确信它们也不会在容差阈值内。然后我们可以取另一个点,计算距离,然后依次重复。
KD 树非常适合计算——欧几里得使得计算量大大减少。再加上聚类算法,它们是有效获取独立障碍物的强大工具。
04.边界框
最终目标是在每个集群周围创建一个 3D 边界框。
这部分不是特别难,但它对障碍物的大小做出了假设。由于我们没有进行任何分类,我们必须将边界框与点相匹配。
一种可以帮助拟合边界框的算法是主成分分析 (PCA)。使用 PCA,我们可以绘制一个与点云完全对应的边界框。
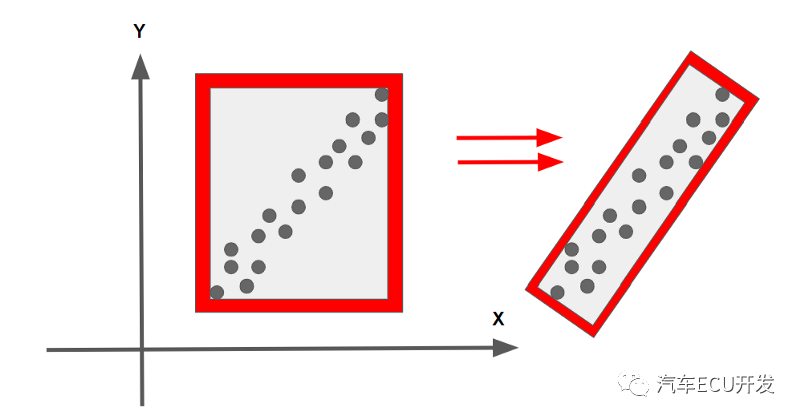
通过结合上面讨论的所有 3 种技术,我们有一个基于 LiDAR 点云的障碍物检测算法!其结果如下所示。


LiDAR是一种非常强大且可靠的传感器,在机器人技术中得到了广泛应用。
一段时间以来,LiDAR技术因其笨重的尺寸和价格而饱受诟病,使其成为精英传感器。
随着价格的下降,甚至独立开发者也可以使用它。
随着 LiDAR 的可用性,获得使用该传感器的技能将成为工程师的真正优势!传感器融合也是一个引人入胜的话题,只有掌握了 LiDAR + 摄像头或 LiDAR + RADAR 检测才有意义。



编辑推荐




最新资讯
-
自动驾驶卡车创企Kodiak 将通过SPAC方式上
2025-04-19 20:36
-
编队行驶卡车仍在奔跑
2025-04-19 20:29
-
全国汽车标准化技术委员会汽车节能分技术委
2025-04-18 17:34
-
我国联合牵头由DC/DC变换器供电的低压电气
2025-04-18 17:33
-
中国汽研牵头的首个ITU-T国际标准正式立项
2025-04-18 17:32
