




 广告
广告





















































闲话自动驾驶的工程化落地
2022-02-15 19:11:58· 来源:汽车ECU开发 作者:黄裕

引言大家有一种认知,觉得自动驾驶进入了“下半场”。类似demo或者POC的早期工作已经不是人们关心的,这里所谓“上半场”大多是解决常见的问题,比如感知、定位
引言
大家有一种认知,觉得自动驾驶进入了“下半场”。类似demo或者POC的早期工作已经不是人们关心的,这里所谓“上半场”大多是解决常见的问题,比如感知、定位、预测、规划决策和控制在典型场景(即高速、街道和停车场等)的解决算法和执行方案(线控底盘技术)。
另外,在“上半场”期间,计算平台(AI芯片及其SOC)和传感器技术的研发进程也初现成果,比如英伟达的Xavier和Orin(见附录)、HDR摄像头、固态激光雷达和4D毫米波雷达等。
而“下半场”意味着要解决罕见的“长尾”场景,同时构建数据闭环的持续高效研发框架,也已经成为行业的共识。在这个过程中,如何实现自动驾驶的技术工程化落地才是关键,包括开发标准化和平台化、量产规模化和落地商业化(成本、车规和OTA)的工作。
01.自动驾驶工程化的一些要素
线控底盘
底盘系统约占整车成本的10%,而线控底盘是自动驾驶的关键部件,因为如果不能它的支持,自动驾驶最终输出的控制信号不一定能够真正得到正确执行。
线控(Drive-by-wire 或 X-by-wire),即用电线(电信号)的形式来取代机械、液压或气动等形式的连接,从而不需要依赖驾驶员的力或扭矩输入。
线控底盘主要包括制动系统、转向系统、驱动系统和悬架系统。其具备响应速度快、控制精度高、能量回收强的特点,是实现自动驾驶不可缺少的零部件。
线控底盘技术的安全性对于自动驾驶来说,是最基础最核心的要素。曾经的纯机械式控制虽然效率低,但可靠性高;线控技术虽然适用于自动驾驶,但同时也面临电子软件的故障所带来的隐患。只有实现功能双重甚至多重冗余,才能保证在故障情况下仍可实现其基本功能。
E2A(电子电气架构)
伴随着汽车行业“网联化、智能化、共享化和电动化(CASE)”趋势推动下的智能化发展,促使汽车分布式架构向着集中式架构转变。E2A是整合汽车各类传感器、处理器、电子电气分配系统和软硬件的总布置方案(包括数据中心平台和高性能计算平台)。
通过E2A,可以将动力总成、驱动信息以及娱乐信息等,转化为实际电源分配的物理布局、信号网络、数据网络、诊断、容错、功耗管理等电子电气解决方案。
汽车E2A基本划分为三个时代:分布式多MCU组网架构、功能集群式域控制器(Domain Controller)和区域连接域控制器(Zone Controller)及中央平台计算机(CPC)。
自动驾驶汽车需要使用大量传感器,车内线束也在迅速增长。车内需要传输的数据量激增,同时线束不仅承载的信号更多,而且数据传输速率要求更快。
自动驾驶在新一代E2A平台下,通过标准化API接口实现了软硬件的真正解耦,可以更加获得更强算力的支持,同时数据通信的带宽也得到增强,资源分配和任务调度更加灵活,另外也方便OTA(over-the-air)。
针对智能汽车电子电气架构,Aptiv提出“大脑”与“神经”结合的方案,包括三个部分:中央计算集群、标准电源和数据主干网络以及电源数据中心。这个智能汽车架构关注三大特性:灵活性、生命周期内持续更新性和系统架构相对容错性和鲁棒性。
特斯拉Model3的E2A分为域控制架构和电源电源分配架构。驾驶辅助与娱乐系统AICM控制合并到CCM中央计算模块当中,而电源分配架构则考虑自动驾驶系统所需要的电源冗余要求。
Middleware(中间件)软件平台
中间件是基础软件的一大类,在操作系统、网络和数据库之上,应用软件的下层,其作用是为应用软件提供运行与开发的环境,便于灵活、高效地开发和集成复杂的应用软件。在不同的技术之间共享资源并管理计算资源和网络通信。
另外中间件的定位不是操作系统,而是一套软件框架,虽然包括了RTOS、MCAL、服务通信层等协议和服务。
中间件的核心是“统一标准、分散实现、集中配置”。其具备如下功能:解决汽车功能的可用性和安全性需求;保持汽车电子系统一定的冗余;移植不同平台;实现标准的基本系统功能;通过网络共享软件功能;集成多个开发商提供的软件模块;在产品生命期内更好地进行软件维护;更充分利用硬件平台处理能力;实现汽车电子软件的更新和升级等。
面向服务的软件架构SOA(Service-Oriented Architecture) 具有松耦合的系统,即有着中立的接口定义,这意味 着应用程序的组件和功能没有被强制绑定,应用程序的不同组件和功能 于结构的联系并不紧密。应用程序服务的内部结构和实现逐渐改变时, 软件架构并不会受到过大的影响。
“接口标准可访问”和“拓展性优秀”的 SOA 使得服务组件的部 署不再依赖于特定的操作系统和编程语言,一定程度上实现软硬件的分 离。SOA 软件架构开发从用户的角度进行功能考虑,以业务为中心,将业务 逻辑进行抽象和封装。
新一代中间件平台支持的自动驾驶软件,通过SOA进行适当颗粒度的功能抽象、软件代码插件化(独立的开发、测试、部署及发布) 、软件功能服务化以及功能之间松耦合。
AI模型压缩和加速
AI模型压缩和加速是两个不同的话题,压缩重点在于减少网络参数量,加速目的在降低计算复杂度、提升并行能力等。
目前压缩和加速AI模型的技术大致分为四种方案如下。
1) 参数修剪和共享:探索模型参数中的冗余,并尝试去除冗余和不重要的参数;
2) 低秩分解:使用矩阵/张量分解来估计深度CNN模型的信息参数;
3) 迁移/紧致卷积滤波器:设计特殊的结构卷积滤波器,以减少参数空间并节省存储/计算;
4) 知识蒸馏:学习蒸馏模型并训练更紧凑的神经网络以再现更大网络的输出。
通常,参数修剪和共享、低秩分解和知识蒸馏方法可以用于具有全联接层和卷积层的深度神经网络模型;另一方面,使用迁移/紧致滤波器的方法仅适用于具有卷积层的模型。低秩分解和基于迁移/紧致滤波器的方法提供了端到端流水线,可在CPU / GPU环境中轻松实现。参数修剪和共享会使用不同的方法,如矢量量化,二进制编码和稀疏约束等。总之,实现压缩和加速需要多个步骤来进行。
至于训练方式,可以从预训练方式中提取基于参数修剪/共享低秩分解的模型,或者从头开始训练(train from scratch)。迁移/紧致卷积滤波器和知识蒸馏模型只能从头开始训练。这些方法是独立设计的,相互补充。例如,可以一起使用迁移网络层以及参数修剪和共享,也可以将模型量化和二值化与低秩分解近似一起使用。
知识蒸馏将深度宽度网络压缩成较浅网络,其中压缩模型模拟了复杂模型所学习的函数。基于蒸馏方法的主要思想是通过学习得到softmax输出的类分布,将知识从大教师模型转变为小学生模型。一种蒸馏框架通过遵循“学生-教师”范式来简化深度网络的训练,其中学生根据教师输出的软版本受到惩罚;该框架将教师网络(teacher network)集成到一个有类似深度的学生网络(student network)中,训练学生预测输出和分类标签。
车载自动驾驶芯片
自动驾驶芯片以及SOC(system on chip),目的是实现高效、低成本、低功耗的自动驾驶计算平台。而工控机实现的自动驾驶平台,是很难实现量产规模化和控制成本的。
一个SOC可能会包括自动驾驶芯片(深度学习模型实现)、CPU/GPU、DSP芯片、ISP芯片和CV(计算机视觉)芯片等。在芯片基础上,还有一个支持深度学习模型实现的编译器需要开发来最大效率地提高芯片的利用率,避免处理器等待或者数据瓶颈堵塞。
其中算法的适配性(模块和进程分解)、自动驾驶软件的高效运行(包括进程数据通信、深度学习模型加速、任务调度和资源管理等)及其安全(功能安全/预期功能安全)保障,都是需要很多工程性的艰苦努力和必要付出的代价(比如系统冗余)。
数据闭环平台
AI的最挑战应用之一,自动驾驶,是一个长尾效应的典型。大量少见的极端情况(corner case)往往是缺乏搜集的训练数据,这样要求我们在一个闭环中不断地发现这些有价值的数据,标注后放入训练集中,同时也放入我们的测试集或者仿真场景库;在NN模型得到迭代升级后,会再交付到自动驾驶车进入新的循环,即数据闭环。
如图就是特斯拉的数据闭环框架:确认模型误差、数据标注和清洗、模型训练和重新部署/交付。
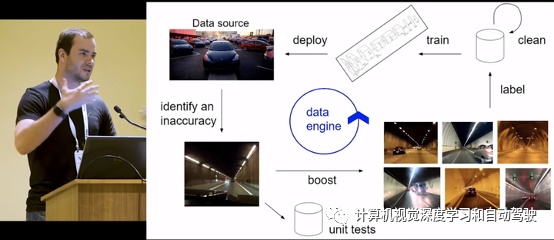
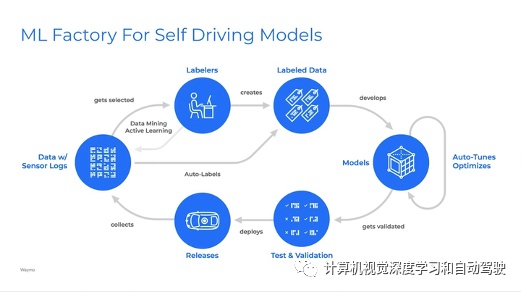
如图是谷歌waymo的数据闭环平台:数据挖掘、主动学习、自动标注、自动化模型调试优化、测试校验和部署发布。
数据闭环需要一个云计算/边缘计算平台和大数据的处理技术,这个不可能在单车或单机实现的。大数据云计算发展多年,在数据批处理/流处理、工作流管理、分布式计算、状态监控和数据库存储等方面提供了数据闭环的基础设施支持。
模型训练平台,主要是机器学习(深度学习)而言,开源的最早有Caffe,目前最流行的是Tensorflow和Pytorch(Caffe2并入)。在云平台部署深度学习模型训练,一般采用分布式。按照并行方式,分布式训练一般分为数据并行和模型并行两种。当然,也可采用数据并行和模型并行的混合。
-
模型并行:不同GPU负责网络模型的不同部分。例如,不同网络层被分配到不同的GPU,或者同一层不同参数被分配到不同GPU。
-
数据并行:不同GPU有模型的多个副本,每个GPU分配不同的数据,将所有GPU计算结果按照某种方式合并。
模型并行不常用,而数据并行涉及各个GPU之间如何同步模型参数,分为同步更新和异步更新。同步更新等所有GPU的梯度计算完成,再计算新权值,同步新值后,再进行下一轮计算。异步更新是每个GPU梯度计算完无需等待,立即更新权值,然后同步新值进行下一轮计算。
分布式训练系统包括两种架构:Parameter Server Architecture(PS,参数服务器)和Ring -AllReduce Architecture(环-全归约)。
主动学习(active learning)的目标是找到有效的方法从无标记数据池中选择要标记的数据,最大限度地提高准确性。主动学习通常是一个迭代过程,在每次迭代中学习模型,使用一些启发式方法从未标记数据池中选择一组数据进行标记。因此,有必要在每次迭代中为了大子集查询所需标签,这样即使对大小适中的子集,也会产生相关样本。
机器学习模型往往会在out-of-distribution(OOD) 数据上失败。检测OOD是确定不确定性(Uncertainty)的手段,既可以安全报警,也可以发现有价值的数据样本。
不确定性有两种来源:任意(aleatoric)不确定性和认知(epistemic)不确定性。导致预测不确定性的数据不可减(Irreducible)不确定性,是一种任意不确定性(也称为数据不确定性)。另一类不确定性是由于知识和数据不适当造成的认知不确定性(也称为知识/模型不确定性)。
最常用的不确定性估计方法是贝叶斯近似(Bayesian approximation)法和集成学习(ensemble learning)法。
一类 OOD 识别方法基于贝叶斯神经网络推理,包括基于 dropout 变分推理(variational inference)法、马尔可夫链蒙特卡罗 (MCMC) 和蒙特卡罗 dropout法等。另一类OOD识别方法包括 (1) 辅助损失或NN 架构修改等训练方法,以及 (2) 事后统计(post hoc statistics)方法。
数据样本中有偏离正常的意外情况,即所谓的极端情况(corner case)。在线检测可以用作安全监控和警告系统,在corner case情况发生时进行识别。线下检测可应用于大量收集的数据,选择合适的训练和相关测试数据。
DevOps
DevOps,简单地来说,就是更好的优化开发(DEV)、测试(QA)、运维(OPS)的流程,开发运维一体化,通过高度自动化工具与流程,使得软件构建、测试、发布更加快捷、频繁和可靠。
DevOps 是一个完整面向IT运维的工作流,IT 自动化以及持续集成(CI)/持续部署(CD)作为基础,来优化程式开发、测试、系统运维等所有环节。
主干开发是CI前提,自动化以及代码集中管理是实施CI的必要条件。DevOps是CI思想的延伸,CD/CI是 DevOps 的技术核心。
MLOps
MLOps的核心目标是使得AI模型从训练到布署的整条端到端链路能够稳定,高效地运行在生产环境中,满足客户的终端业务需求。
为了达到这个目标,其对AI系统核心技术也提出了相应的需求。比如布署自动化,对AI框架的前端设计会提出明确的需求,如果AI框架的前端设计不利于导出完整的模型文件,会使得大量的下游不得不在布署环节引入针对各自业务场景需求的”补丁”。
布署自动化的需求,也会催生一些围绕AI核心系统的软件组件,比如模型推理布署优化、模型训练预测结果的可复现性和AI生产的系统可伸缩性。
场景库建设和测试
基于场景的自动驾驶汽车测试方法是实现加速测试、加速评价的有效途径。
“场景作为行驶环境与汽车驾驶情景的一种综合体现,描述了车辆外部行驶环境的道路场地、周边交通、气象(天气和光照)和车辆自身的驾驶任务和状态等信息,是影响和判定智能驾驶功能与性能因素集合的一种抽象与映射,具有高度的不确定、不可重复、不可预测和不可穷尽等特征”。
测试场景的分类方法有所不同:
1)按照场景的抽象程度,可分为功能场景、逻辑场景、具体场景;
2)按照测试场景数据来源,可分为自然驾驶场景、危险工况场景、标准法规场景和参数重组场景。
一个场景库的维度包括:
-
场景:静态部分和动态部分
-
交通:驾驶行为和VRU(行人、自行车)等非机动行为
-
天气:传感器(摄像头、雷达、激光雷达)和干扰
场景库建设,基本上基于真实、虚拟以及专家数据等不同的数据源,通过场景挖掘、场景分类、场景演绎等方式分层构建成一个完整的体系。
德国PEGASUS项目(2016~2019年5月)聚焦于高速公路场景的研究和分析,基于事故以及自然驾驶数据建立场景数据库,以场景数据库为基础对系统进行验证。
该研究定义了场景(scenario)“功能—逻辑—具体”(functional-logical-concrete)三级分层体系,以及面向概念—开发—测试—标定 (concept-development-testing-calibration) 的场景库构建流程及智能驾驶测试方法。
PEGASUS通过开发OpenScenario接口试图建立可用于模拟仿真、试验场和真实环境中测试和试验高级智能驾驶系统的标准化流程。
该项目分四个阶段:1)场景分析&质量评估,定义一种系统的场景生成方法以及场景文件的的语法结构,计算场景的KPI,定义一套基于专家经验的场景困难(危险)程度评价方法;2)实施流程,以安全为基础,设计一套足够灵活的、鲁棒性强的适用于自动驾驶功能的设计实施流程;3)测试,输出为一套用于实验室(仿真软件,台架等)以及真实交通场景的方法和工具链;4)结果验证&集成,对前三个阶段的结果进行分析。
PEGASUS建立三种测试场景格式标准,即OpenCRG、OpenDRIVE和OpenSCENARIO,定义了测试场景的六层模型:道路层、交通基础设施、前两层的临时操作(如道路施工现场)、对象、环境和数字信息。
02.结束语
自动驾驶进入一个工程化落地的时期,这里提到了一些必要的工程化要素,如线控底盘、电子电气架构、中间件软件平台、模型压缩加速、车载自动驾驶芯片(计算平台)、数据闭环、DevOps/MLOps和场景库建设及其测试等。
另外,这里还有没提到的工程问题,比如传感器清洗、计算平台的内存/指令优化和安全冗余设计等等。
附录A:自动驾驶工程化举例
Pony AI(小马科技)
2021 年 2 月,小马宣布最新一代的自动驾驶车辆从一套标准化产线正式下线,开启全天候自动驾驶的公开道路测试,并加入到各地的 Robotaxi 车队中做规模化的运营。
这批车辆从设计、开发到产线生产、标定和验证,经历非常严格的标准化流程。整个流程里面大概涉及 40 多道工序(如摄像头和激光雷达清洗、震动和防水等)200多项质检项目,尽可能保证整个系统的一致性。
比起以前的系统,在硬件稳定性方面大概有 30 倍到 50 倍提升的效果,整个自动驾驶系统的生产效率和前一年相比大概能够提升 6 倍。
AutoX(安途)
2021年12月22日,AutoX(安途)对外揭晓AutoX RoboTaxi超级工厂的内部视频。该超级工厂由Auto X独立设计、投建。而RoboTaxi则是AutoX与克莱斯勒FCA集成合作打造,具备车规级冗余线控,支持量产。
AutoX无人车零部件进入仓库后,先进行质量检测,通过检测的零件走上部装线,进行局部集成。
总装线由半自动化滑板传输线和吊装输送线组成,采用ABB 7轴机器人。电控系统与传动系统则是由西门子、欧姆龙、施耐德、飞利浦、三菱、SEW等提供。从车内操作界面可以对系统的全部软硬件模块进行质检。
下线时,车间内自动化多传感器在转盘、四轮定位等方面进行标定,并在厂内完成恒温房、喷淋房等车规级检测,在出厂时即可进入无人驾驶状态。
附录B:英伟达自动驾驶芯片
Xavier
Xavier被NVIDIA称作为“世界上最强大的SoC(片上系统)”,有高达 32 TOPS的峰值计算能力和 750 Gbps 的高速 I/O 性能。
Xavier SoC基于台积电12nm工艺, CPU采用NVIDIA自研8核ARM64架构(代号Carmel),GPU采用512颗CUDA的Volta,支持FP32/FP16/INT8,20W功耗下单精度浮点性能1.3TFLOPS,Tensor核心性能20TOPs,解锁到30W后可达30TOPs。
Xavier 内有六种不同的处理器:Volta TensorCore GPU,八核ARM64 CPU,双NVDLA 深度学习加速器(DLA),图像处理器,视觉处理器和视频处理器。
Orin
和Xavier相比,Orin的算力提升到接近7倍,从30TOPS提升到了200TOPS。CPU部分从ARM Cortex A57到A78。Xavier的功耗大概30W,Orin功耗仅为45W左右。
Orin多芯片方案版本用两个Orin + 两个7nmA100 GPU,算力达到2000TOPS。Orin 系统级芯片集成NVIDIA 新GPU 架构Ampere、Arm Hercules CPU 内核、新深度学习加速器(DLA)和计算机视觉加速器(PVA),每秒运行200万亿次计算。
DRIVE AGX系列推出一款新型Orin SoC。其功率仅为5瓦,但性能却可达到10 TOPS。
Hyperion
NVIDIA 构建并开放 DRIVE Hyperion 平台。该平台配置高性能计算机和传感器架构,满足自动驾驶汽车的安全要求。DRIVE Hyperion 采用适用于软件定义汽车的冗余 NVIDIA DRIVE Orin 系统级芯片,持续改善和创建各种基于软件和服务的新业务模式。
新平台采用 12 个环绕摄像头、12 个超声波模块、9 个普通雷达、3 个内部感知摄像头和 1 个前置激光雷达打造。是有功能安全的架构设计,具备故障备份。
不少汽车制造商、卡车制造商、一级供应商和无人驾驶出租车服务公司采用了此 DRIVE Hyperion 架构。
附录C:车载中间件AUTOSAR
AUTOSAR (AUTomotive Open System ARchitecture) 由各大整车厂商和零部件厂商联合制定软件的标准化接口,由BMW、BOSCH、Continental、DAIMLER、Ford、OPEL、PSA、TOYOTA、VW等共同制定,俗称AUTOSAR Classic (CP),基本上做为MCU/ECU的标准,包 括发动机控制机和电机控制器。
CP主要包含微控制器层(Microcontroller)、基础软件层(Basic Software)、中间件层(Runtime Environment,RTE)以及应用层(Application)。基础软件层再分为服务层(Services Layer)、ECU抽象层(ECU Abstraction Layer)、微控制器抽象层(Microcontroller Abstraction Layer)和复杂驱动(Complex Device Drivers)。
具体讲,服务层主要提供各类维持系统运行的基础服务,如监控,诊断,通信,以及实时操作系统等;ECU抽象层主要功能是封装微处理器及其外围设备;微处理器抽象层主要功能是对微控制器进行分装,例如I/O、ADC、SPI等;复杂驱动用于那些不能进行统一封装的复杂硬件,为上层RTE访问硬件提供支持。
AUTOSAR Adaptive platform (AP),更多的应用于 ADAS 和自动驾驶等对于计算能力和带宽通信要求更高的领域中,尽可能从其他领域 (如消费电子产品) 的发展中获益,同时仍然考虑汽车的特定要求,如功能安全。
AP平台主要提供高性能计算与通讯机制,并且提供灵活的软件配置,例如软件远程更新(OTA)等,包括如下主要部分:(1)用户应用,一个应用可以为其他应用提供服务,这样的服务称为非平台服务;(2)支持用户应用的AUTOSAR Runtime(ARA,Autosar Runtime for Adaptive Application),其由功能集群提供的一系列应用接口组成,其中有两种类型的功能集群,即自适应平台基础功能和自适应平台服务;(3)硬件视作机器(Machine),可以通过各种管理程序相关技术虚拟化,并且可以实现一致的平台视图。
AP需要支持E2A的两个关键特征:异构软件平台的集成和面向服务的通信。AP组件封装面向服务SOA软件底层的通讯细节 (包括SOME/IP协议,IPC等),同时提供代理(Proxy)-骨架(Skeleton)模型,方便应用开发人员调用标准服务接口(API)进行开发。
AP选择POSIX PSE 51作为OS要求,避免底层OS过于复杂,上层应用限制使用一些复杂功能,避免overspec。
作者 | 计算机视觉深度学习和自动驾驶



编辑推荐




最新资讯
-
中汽中心工程院能量流测试设备上线全新专家
2025-04-03 08:46
-
上新|AutoHawk Extreme 横空出世-新一代实
2025-04-03 08:42
-
「智能座椅」东风日产N7为何敢称“百万级大
2025-04-03 08:31
-
基于加速度计补偿的俯仰角和路面坡度角估计
2025-04-03 08:30
-
《北京市自动驾驶汽车条例》正式实施 L3级
2025-04-02 20:23
