




 广告
广告





















































如何在自动驾驶的视觉感知中检测极端情况?
2022-02-22 09:56:15· 来源:计算机视觉深度学习和自动驾驶 作者:黄浴

一篇来自德国大学的论文:“Corner Cases for Visual Perception in Automated Driving: Some Guidance on Detection Approaches“,在arXiv上2021年2月11日出现
一篇来自德国大学的论文:“Corner Cases for Visual Perception in Automated Driving: Some Guidance on Detection Approaches“,在arXiv上2021年2月11日出现。

极端情况(corner cases)是自动驾驶中很重要的一个问题,本文讨论视觉感知(不包括雷达和激光雷达)如何检测这些corner cases,即出现的未期望或者未知情况。检测corner case的任务对安全十分关键,检测方法对训练数据的选择自动化非常重要,对大众能否接受自动驾驶技术一事也是如此。该文系统性的分析corner cases出现的层次及其检测方法的类别,将二者联系在一起。
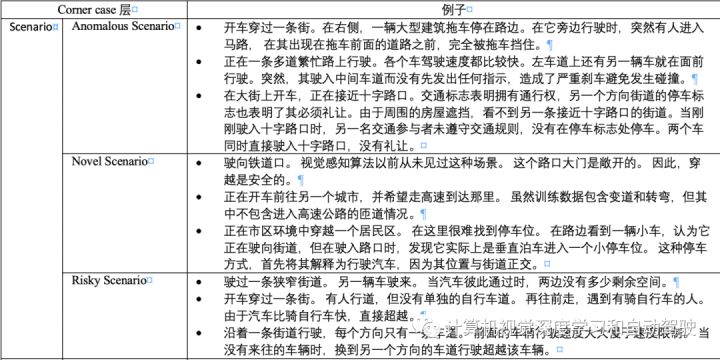
注:上面图显示的是corner cases层次划分【5】。
检测corner cases包括online和offline方法,online情况是可以作为安全监控和警告系统,offline情况是用于实验室开发新的视觉感知算法,选择合适的训练和测试数据。一些不错的工作已经展开,比如障碍物检测【6-7】,新出现的目标【8】。
corner cases 定义为 “there is a non-predictable relevant object/class in a relevant location”【9】。本文分析根据【5】将它们分为以下几个层次:
-
pixel,
-
domain,
-
object,
-
scene,
-
scenario。
具体讲,pixel level 原因分成 global 和local outliers两个;domain-level 是domain shifts 造成的;object level则是single-point anomalies 或者 single-point novelties;scene-level 来源也分成两个,collective anomalies和 contextual anomalies,其中contextual anomalies 是指未知位置的已知目标,比如街中心的树,而collective anomalies 是指数目异常的已知目标,比如demo。最高层的复杂情况是scenario-level, 包括risky scenarios、novel scenarios和anomalous scenarios。
下面表格给出corner cases的各层例子:确实是有趣的corner cases。

检测它们的方法分为以下类别【10】:
-
feature extraction,
-
regression,
-
knowledge-based,
-
signal model,
-
state estimation,
-
clustering,
-
classification methods。
corner cases 检测方法分为下面5个概念:
-
reconstruction,
-
prediction,
-
generative,
-
confidence scores,
-
feature extraction.
Reconstruction 方法 基本上是autoencoder-type networks;Prediction-based 方法 主要是scenario level,比如GAN;Generative 和 reconstruction-based 方法非常相关联;Feature extraction 方法主要采用 deep neural networks。其中 confidence score 类,进一步又分成 三个子类:
-
learned confidence scores
-
Bayesian approaches
-
post-processing
如下表所示是检测方法和复杂层次之间的联系:
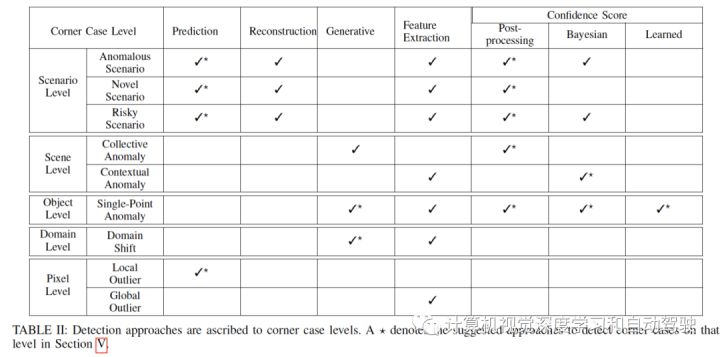
总的来说,可以说由于缺乏包含所有类型corner cases的大规模数据集,以及相关的corner cases检测的open world问题,无监督方法或者仅在正常样本上训练的方法目前看来是最有效获取corner case检测器的方法。依赖于异常训练数据的方法需要更复杂、更专业的训练集,并且冒着集中于样本相关的特定corner cases这种风险,对推理中出现未知corner cases的可能性故意视而不见。
pixel level
在pixel level,只有很少的深度学习方法检测corner cases。但是,对于global outlier而言,检测此类情况时,特征提取方法可提供好的结果,因为是检测影响大部分甚至整个图像的情况。这时候,检测可以被认为是二进制分类问题,并且网络能够为该任务提取足够的特征。可以进行有监督的训练,因为这种类型不会有意外的多样性。然而,由于缺乏带标记的global outlier(例如过度暴露)的自动驾驶数据集,对利用少样本学习或类似技术的方法进行研究可能是有益的。此外,更有兴趣检测多个global outliers,例如,共同检测图像中的过度曝光和曝光不足。在出隧道时,它们甚至可以出现在同一图像中。在以后的工作中考虑联合或多任务学习来研究。
而local outliers仅影响图像的一小部分,如像素坏了。可以在训练数据中模拟这些情况,因此通过监督学习解决。由于具有模拟的可能性,加入另一类,这样通过语义分割方法来处理检测问题。这将导致逐像素标注,给出坏像素的位置。预测性方法(在一个时间跨度)将有利于检测local outliers。可以将,例如,坏像素的预测位置,与实际位置进行比较。理想情况下,实际位置与根据学习的光流进行预测的位置,正好相反。
domain level
要检测domain层的corner cases,不需要使用域适应方法,而是去找到适合domain mismatch的度量。但是,这些措施通常来自域适应方法,并被用作损失函数。通常,这些措施被认为是特征提取方法。虽然训练可能需要来自source domain的正常样本进行监督,但是应该明确排除来自另一个域的数据进行训练。在训练中采用第二个域特定示例的方法存在无法达到第三个域相同性能的危险。还可以考虑将一个数据集视为分布内而将另一个数据集视为分布外(out-of-distribution)的OOD检测方法。这些方法可以从分类扩展到汽车视觉感知,因为它们只需要通过正常样本进行监督训练即可。为了可靠地检测domain level的corner cases,需要使用可靠的domain mismatch度量。
object level
在object level,主要任务是检测未知类别的未知目标。这些是属于新类别的实例,以前在训练中没有见过。在训练过程中提供此类corner cases的示例将使网络推断出仅检测类似的corner cases,这对任务是不利的。object level的corner cases检测属于开放式识别的领域,相关方法通常提供某种类别的confidence scores。理想情况下,对于检测和定位,要求逐像素评分。也存在符合该思想的reconstruction方法和generative方法。然而,reconstruction-based方法往往结果意义不大。
想为输入图像获得语义分割掩码,其中属于未知目标的像素与未知类别标签或高不确定性相关联。考虑到这一衷旨,追求confidence scores和generative检测方法似乎最有成效,并且许多最近出现的方法都符合这种趋势。使用Bayesian置信度得分,求解一个与那些未知目标相关的高不确定性模型。Monte-Carlo dropout 或者deep ensembles的贝叶斯深度学习规模化方法为检测提供了第一步。根据那些single-point anomalies定义的训练中未见实例,可以推测出,有效而可靠的检测方法不能依赖包括corner cases的训练样本。人们不得不诉诸无监督方法,它们只能使用正态样本进行训练。
scene level
在scene level,旨在检测未知数量或位置的已知类。此外,认为未来的工作应该利用实例分割(instance segmentation)来获得分组大小,要计算每个类的实例数量。在这种情况下,需要一个阈值来将集体(collection)定义为异常(anomalous)。可以通过特征提取方法来检测contextual anomalies。但是,在汽车视觉感知,特征提取可能无法捕获整个场景的复杂性。因此,许多现有方法给出confidence scores或reconstruction误差,并区分正常样本和异常样本。建议调查类别先验如何对整个流程产生影响,因为这些先验知识可能有助于发现错位的类别代表。
同样,贝叶斯深度学习得出的置信度得分表明模型的不确定性,因此它们对于异常上下文(unusual context)情况下定位目标可能很有用。scene level的这两种corner cases类型都可以使用常规数据进行监督训练,因为都可以检测到已知类的实例。但是,与object level不同,虽然可能需要视觉感知应用程序的像素级语义分割(semantic segmentation)标签,但另外要求实例级标签告诉目标出现在异常位置,或要求图像级标签告诉目标是否以未知的数量出现。
scenario level
scenario level的corner cases由特定时间段出现的模式所组成,并且单帧可能看起来并不异常。在这里,prediction-based方法的决策取决于预测帧与实际帧之间的比较,从而提供了有益的结果。纯粹的reconstruction方法再一次获得不可靠的corner cases检测分数。可以对prediction方法进行有监督训练,因为它们仅需要正常的训练样本即可在推理过程中检测到corner cases。这对于novel scenarios和anomalous scenarios尤其重要,此时由于数量大以及相应的危险性,无法捕获所有可能性。
此外,包含这些样本实际上可能会损害网络,使其仅检测此类情况。为此,需要定义度量标准来检测这种corner cases。尽管可能仍想知道corner cases在图像的位置,但也需要知道时间点。为此,可以考虑在一定时间段的图像标记。除了对度量进行调查之外,建议使用成本函数给予更高的优先级去检测视野边缘处出现的VRUs(vulnerable road users)。这可以,例如,改善检测从遮挡后面跑到街道的人,因为当帧中仅出现几个人的像素时,已经可以实现检测。这种方法还需要识别由于被遮挡或不在视场范围内而未包括在前一帧的逐帧像素掩码。
这种讨论也是比较罕见的,值得关注以下。另外附上原文引用的几个重要参考文献:
[5] J Breitenstein et al., “Systematization of Corner Cases for Visual Perception in Automated Driving,” IV, 2020.
[6] P. Pinggera et al., “Lost and Found: Detecting Small Road Hazards for Self-Driving Vehicles,” IROS, 2016.
[7] S. Ramos et al., “Detecting Unexpected Obstacles for Self-Driving Cars: Fusing Deep Learning and Geometric Modeling,” IV, 2017.
[8] H. Blum et al., “Fishyscapes: A Benchmark for Safe Semantic Segmentation in Autonomous Driving,” ICCV Workshops, 2019.
[9] J.-A. Bolte et al., “Towards Corner Case Detection for Autonomous Driving,” IV, 2019.
[10] F. Lopez et al., “Categorization of Anomalies in Smart Manufacturing Systems to Support the Selection of Detection Mechanisms,” IEEE Robotics and Automation Letters, 2017.
- 下一篇:寒区环境适应性试验介绍与研究
- 上一篇:全气候电池新能源汽车诞生 极寒天气不怕冷



编辑推荐




最新资讯
-
自动驾驶卡车创企Kodiak 将通过SPAC方式上
2025-04-19 20:36
-
编队行驶卡车仍在奔跑
2025-04-19 20:29
-
全国汽车标准化技术委员会汽车节能分技术委
2025-04-18 17:34
-
我国联合牵头由DC/DC变换器供电的低压电气
2025-04-18 17:33
-
中国汽研牵头的首个ITU-T国际标准正式立项
2025-04-18 17:32
