




 广告
广告





















































机器学习最全知识点汇总

有些应用中已知样本服从的概率分布,但是要估计分布函数的参数
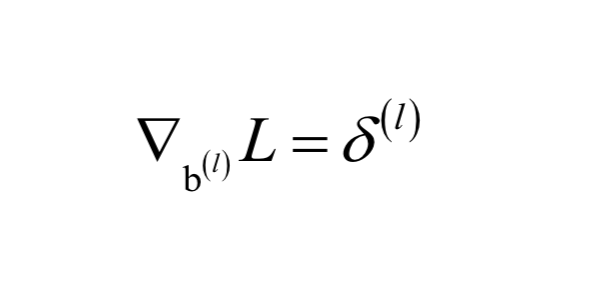
,确定这些参数常用的一种方法是最大似然估计。
最大似然估计构造一个似然函数,通过让似然函数最大化,求解出
。最大似然估计的直观解释是,寻求一组参数,使得给定的样本集出现的概率最大。
假设样本服从的概率密度函数为
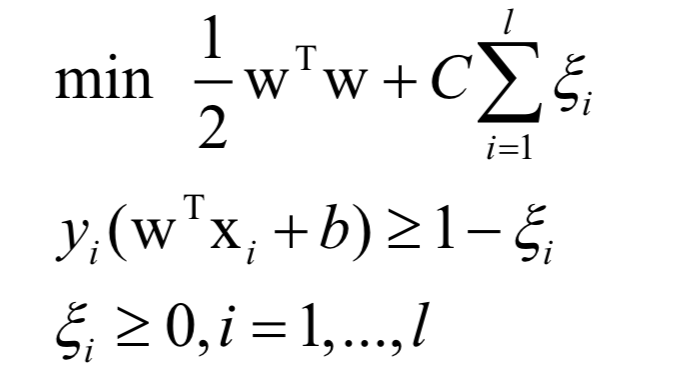
,其中X为随机变量,
为要估计的参数。给定一组样本xi,i =1,...,l,它们都服从这种分布,并且相互独立。最大似然估计构造如下似然函数:
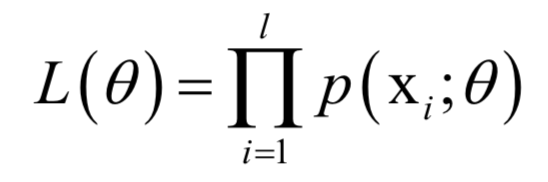
其中xi是已知量,这是一个关于
的函数,我们要让该函数的值最大化,这样做的依据是这组样本发生了,因此应该最大化它们发生的概率,即似然函数。这就是求解如下最优化问题:
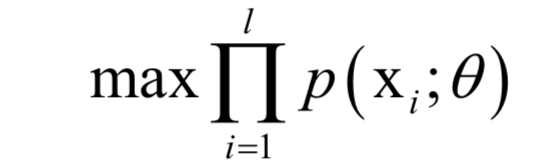
乘积求导不易处理,因此我们对该函数取对数,得到对数似然函数:
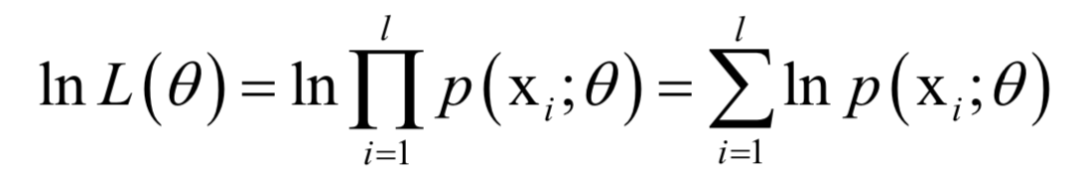
最后要求解的问题为:
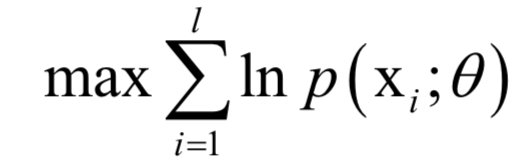
最大似然估计在机器学习中的典型应用包括logistic回归,贝叶斯分类器,隐马尔科夫模型等。
基本概念
1.有监督学习与无监督学习
根据样本数据是否带有标签值,可以将机器学习算法分成有监督学习和无监督学习两类。有监督学习的样本数据带有标签值,它从训练样本中学习得到一个模型,然后用这个模型对新的样本进行预测推断。有监督学习的典型代表是分类问题和回归问题。
无监督学习对没有标签的样本进行分析,发现样本集的结构或者分布规律。无监督学习的典型代表是聚类,表示学习,和数据降维,它们处理的样本都不带有标签值。
2.分类问题与回归问题
在有监督学习中,如果样本的标签是整数,则预测函数是一个向量到整数的映射,这称为分类问题。如果标签值是连续实数,则称为回归问题,此时预测函数是向量到实数的映射。
3.生成模型与判别模型
分类算法可以分成判别模型和生成模型。给定特征向量x与标签值y,生成模型对联合概率p(x,y)建模,判别模型对条件概率p(y|x)进行建模。另外,不使用概率模型的分类器也被归类为判别模型,它直接得到预测函数而不关心样本的概率分布:
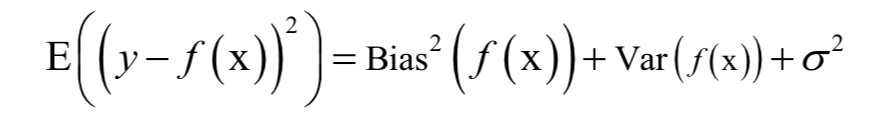
判别模型直接得到预测函数f(x),或者直接计算概率值p(y|x),比如SVM和logistic回归,softmax回归,判别模型只关心决策面,而不管样本的概率分布的密度。
生成模型计算p(x, y)或者p(x|y) ,通俗来说,生成模型假设每个类的样本服从某种概率分布,对这个概率分布进行建模。
机器学习中常见的生成模型有贝叶斯分类器,高斯混合模型,隐马尔可夫模型,受限玻尔兹曼机,生成对抗网络等。典型的判别模型有决策树,kNN算法,人工神经网络,支持向量机,logistic回归,AdaBoost算法等。
4.交叉验证
交叉验证(cross validation)是一种统计准确率的技术。k折交叉验证将样本随机、均匀的分成k份,轮流用其中的k-1份训练模型,1份用于测试模型的准确率,用k个准确率的均值作为最终的准确率。
5.过拟合与欠拟合
欠拟合也称为欠学习,直观表现是训练得到的模型在训练集上表现差,没有学到数据的规律。引起欠拟合的原因有模型本身过于简单,例如数据本身是非线性的但使用了线性模型;特征数太少无法正确的建立映射关系。
过拟合也称为过学习,直观表现是在训练集上表现好,但在测试集上表现不好,推广泛化性能差。过拟合产生的根本原因是训练数据包含抽样误差,在训练时模型将抽样误差也进行了拟合。所谓抽样误差,是指抽样得到的样本集和整体数据集之间的偏差。引起过拟合的可能原因有:
模型本身过于复杂,拟合了训练样本集中的噪声。此时需要选用更简单的模型,或者对模型进行裁剪。训练样本太少或者缺乏代表性。此时需要增加样本数,或者增加样本的多样性。训练样本噪声的干扰,导致模型拟合了这些噪声,这时需要剔除噪声数据或者改用对噪声不敏感的模型。
6.偏差与方差分解
模型的泛化误差可以分解成偏差和方差。偏差是模型本身导致的误差,即错误的模型假设所导致的误差,它是模型的预测值的数学期望和真实值之间的差距。
方差是由于对训练样本集的小波动敏感而导致的误差。它可以理解为模型预测值的变化范围,即模型预测值的波动程度。
模型的总体误差可以分解为偏差的平方与方差之和:
如果模型过于简单,一般会有大的偏差和小的方差;反之如果模型复杂则会有大的方差但偏差很小。
7.正则化
为了防止过拟合,可以为损失函数加上一个惩罚项,对复杂的模型进行惩罚,强制让模型的参数值尽可能小以使得模型更简单,加入惩罚项之后损失函数为:
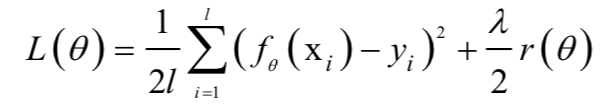
正则化被广泛应用于各种机器学习算法,如岭回归,LASSO回归,logistic回归,神经网络等。除了直接加上正则化项之外,还有其他强制让模型变简单的方法,如决策树的剪枝算法,神经网络训练中的dropout技术,提前终止技术等。
8.维数灾难
为了提高算法的精度,会使用越来越多的特征。当特征向量维数不高时,增加特征确实可以带来精度上的提升;但是当特征向量的维数增加到一定值之后,继续增加特征反而会导致精度的下降,这一问题称为维数灾难。
贝叶斯分类器
贝叶斯分类器将样本判定为后验概率最大的类,它直接用贝叶斯公式解决分类问题。假设样本的特征向量为x,类别标签为y,根据贝叶斯公式,样本属于每个类的条件概率(后验概率)为:
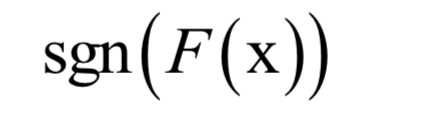
分母p(x)对所有类都是相同的,分类的规则是将样本归到后验概率最大的那个类,不需要计算准确的概率值,只需要知道属于哪个类的概率最大即可,这样可以忽略掉分母。分类器的判别函数为:
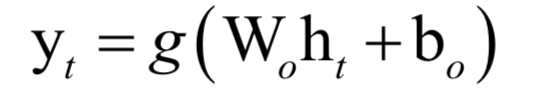
在实现贝叶斯分类器时,需要知道每个类的条件概率分布p(x|y)即先验概率。一般假设样本服从正态分布。训练时确定先验概率分布的参数,一般用最大似然估计,即最大化对数似然函数。
如果假设特征向量的各个分量之间相互独立,则称为朴素贝叶斯分类器,此时的分类判别函数为:
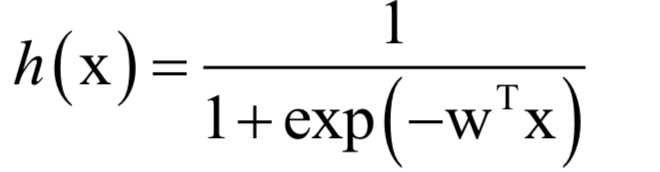
实现时可以分为特征分量是离散变量和连续变量两种情况。贝叶斯分分类器是一种生成模型,可以处理多分类问题,是一种非线性模型。
决策树
决策树是一种基于规则的方法,它用一组嵌套的规则进行预测。在树的每个决策节点处,根据判断结果进入一个分支,反复执行这种操作直到到达叶子节点,得到预测结果。这些规则通过训练得到,而不是人工制定的。
决策树既可以用于分类问题,也可以用于回归问题。分类树的映射函数是多维空间的分段线性划分,用平行于各坐标轴的超平面对空间进行切分;回归树的映射函数是分段常数函数。决策树是分段线性函数而不是线性函数。只要划分的足够细,分段常数函数可以逼近闭区间上任意函数到任意指定精度,因此决策树在理论上可以对任意复杂度的数据进行拟合。对于分类问题,如果决策树深度够大,它可以将训练样本集的所有样本正确分类。
决策树的训练算法是一个递归的过程,首先创建根节点,然后递归的建立左子树和右子树。如果练样本集为D,训练算法的流程为:
1.用样本集D建立根节点,找到一个判定规则,将样本集分裂成D1和D2两部分,同时为根节点设置判定规则。
2.用样本集D1递归建立左子树。
3.用样本集D2递归建立右子树。
4.如果不能再进行分裂,则把节点标记为叶子节点,同时为它赋值。
对于分类树,如果采用Gini系数作为度量准则,决策树在训练时寻找最佳分裂的依据为让Gini不纯度最小化,这等价于让下面的值最大化:
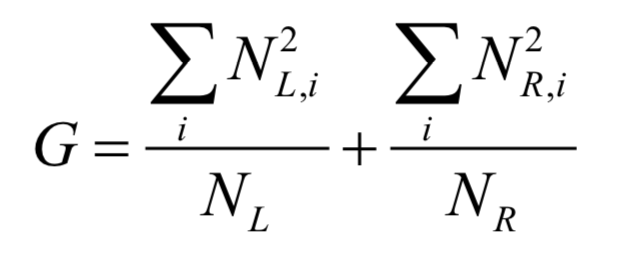
寻找最佳分裂时需要计算用每个阈值对样本集进行分裂后的纯度值,寻找该值最大时对应的分裂,它就是最佳分裂。如果是数值型特征,对于每个特征将l个训练样本按照该特征的值从小到大排序,假设排序后的值为:

接下来从x1开始,依次用每个xi作为阈值,将样本分成左右两部分,计算上面的纯度值,该值最大的那个分裂阈值就是此特征的最佳分裂阈值。在计算出每个特征的最佳分裂阈值和上面的纯度值后,比较所有这些分裂的纯度值大小,该值最大的分裂为所有特征的最佳分裂。
决策树可以处理属性缺失问题,采用的方法是使用替代分裂规则。为了防止过拟合,可以对树进行剪枝,让模型变得更简单。如果想要更详细的了解决策树的原理,请阅读SIGAI之前的公众号文章“理解决策树”,在SIGAI云端实验室有决策树训练算法的原理实验,此功能免费,网址为:www.sigai.cn
决策树是一种判别模型,既支持分类问题,也支持回归问题,是一种非线性模型,它支持多分类问题。
随机森林
随机森林是一种集成学习算法,是Bagging算法的具体实现。集成学习是机器学习中的一种思想,而不是某一具体算法,它通过多个模型的组合形成一个精度更高的模型,参与组合的模型称为弱学习器。在预测时使用这些弱学习器模型联合进行预测,训练时需要依次训练出这些弱学习器。
随机森林用有放回抽样(Bootstrap抽样)构成出的样本集训练多棵决策树,训练决策树的每个节点时只使用了随机抽样的部分特征。预测时,对于分类问题,一个测试样本会送到每一棵决策树中进行预测,然后投票,得票最多的类为最终分类结果。对于回归问题,随机森林的预测输出是所有决策树输出的均值。
假设有n个训练样本。训练每一棵树时,从样本集中有放回的抽取n个样本,每个样本可能会被抽中多次,也可能一次都没抽中。如果样本量很大,在整个抽样过程中每个样本有0.368的概率不被抽中。由于样本集中各个样本是相互独立的,在整个抽样中所有样本大约有36.8%没有被抽中。这部分样本称为包外(Out Of Bag,简称OOB)数据。
用这个抽样的样本集训练一棵决策树,训练时,每次寻找最佳分裂时,还要对特征向量的分量采样,即只考虑部分特征分量。由于使用了随机抽样,随机森林泛化性能一般比较好,可以有效的降低模型的方差。
如果想更详细的了解随机森林的原理,请阅读SIGAI之前的公众号文章“随机森林概述”。随机森林是一种判别模型,既支持分类问题,也支持回归问题,并且支持多分类问题,这是一种非线性模型。
- 下一篇:新能源乘用车产业现状及发展趋势
- 上一篇:量产主控芯片的网络安全设计



编辑推荐




最新资讯
-
中汽中心工程院能量流测试设备上线全新专家
2025-04-03 08:46
-
上新|AutoHawk Extreme 横空出世-新一代实
2025-04-03 08:42
-
「智能座椅」东风日产N7为何敢称“百万级大
2025-04-03 08:31
-
基于加速度计补偿的俯仰角和路面坡度角估计
2025-04-03 08:30
-
《北京市自动驾驶汽车条例》正式实施 L3级
2025-04-02 20:23
