




 广告
广告





















































机器学习最全知识点汇总

AdaBoost算法也是一种集成学习算法,用于二分类问题,是Boosting算法的一种实现。它用多个弱分类器的线性组合来预测,训练时重点关注错分的样本,准确率高的弱分类器权重大。AdaBoost算法的全称是自适应,它用弱分类器的线性组合来构造强分类器。弱分类器的性能不用太好,仅比随机猜测强,依靠它们可以构造出一个非常准确的强分类器。强分类器的计算公式为:
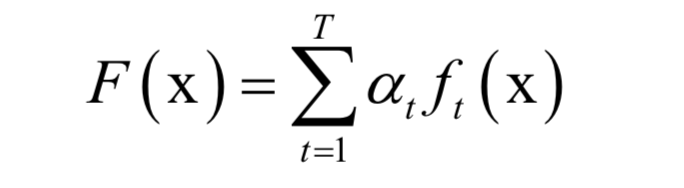
其中x是输入向量,F(x)是强分类器,ft(x)是弱分类器,at是弱分类器的权重,T为弱分类器的数量,弱分类器的输出值为+1或-1,分别对应正样本和负样本。分类时的判定规则为:
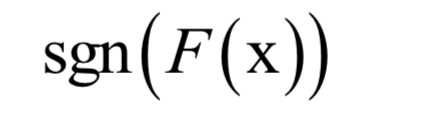
强分类器的输出值也为+1或-1,同样对应于正样本和负样本。
训练时,依次训练每一个若分类器,并得到它们的权重值。训练样本带有权重值,初始时所有样本的权重相等,在训练过程中,被前面的弱分类器错分的样本会加大权重,反之会减小权重,这样接下来的弱分类器会更加关注这些难分的样本。弱分类器的权重值根据它的准确率构造,精度越高的弱分类器权重越大。
给定l个训练样本(xi,yi ),其中xi是特征向量,yi为类别标签,其值为+1或-1。训练算法的流程为:

根据计算公式,错误率低的弱分类器权重大,它是准确率的增函数。AdaBoost算法在训练样本集上的错误率会随着弱分类器数量的增加而指数级降低。它能有效的降低模型的偏差。
AdaBoost算法从广义加法模型导出,训练时求解的是指数损失函数的极小值:
求解时采用了分阶段优化,先得到弱分类器,然后确定弱分类器的权重值,这就是弱分类器,弱分类器权重的来历。除了离散型AdaBoost之外,从广义加法模型还可以导出其他几种AdaBoost算法,分别是实数型AdaBoost,Gentle型AdaBoost,Logit型AdaBoost,它们使用了不同的损失函数和最优化算法。
标准的AdaBoost算法是一种判别模型,只能支持二分类问题。它的改进型可以处理多分类问题。
主成分分析
主成分分析是一种数据降维和去除相关性的方法,它通过线性变换将向量投影到低维空间。对向量进行投影就是对向量左乘一个矩阵,得到结果向量:y = Wx结果向量的维数小于原始向量的维数。降维要确保的是在低维空间中的投影能很好的近似表达原始向量,即重构误差最小化:
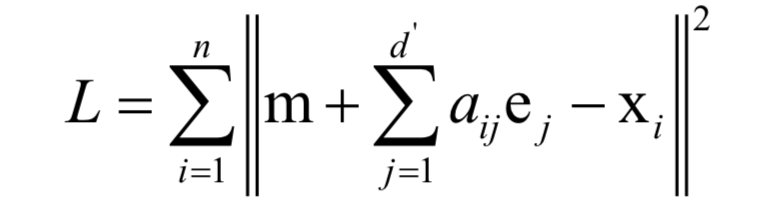
其中e为投影后空间的基向量,是标准正交基;a为重构系数,也是投影到低维空间后的坐标。如果定义如下的散布矩阵:
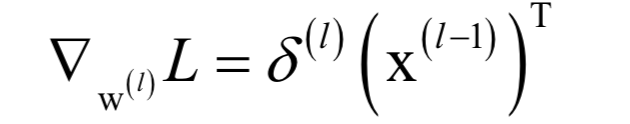
其中m和
为所有样本的均值向量。则上面的重构误差最小化等价于求解如下问题:
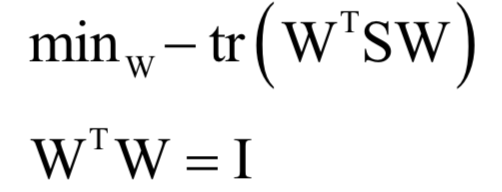
通过拉格朗日乘数法可以证明,使得该函数取最小值的ej为散度矩阵最大的d'个特征值对应的单位长度特征向量。矩阵W的列ej是我们要求解的基向量,由它们构成投影矩阵。计算时,先计算散布矩阵(或者协方差矩阵),再对该进行进行特征值分解,找到最大的一部分特征值和对应的特征向量,构成投影矩阵。可以证明,协方差矩阵或散布矩阵是实对称半正定矩阵,因此所有特征值非负。进行降维时,先将输入向量减掉均值向量,然后左乘投影矩阵,即可得到投影后的向量。
主成分分析一种无监督学习算法,也是一种线性方法。
线性判别分析
线性判别分析向最大化类间差异、最小化类内差异的方向线性投影。其基本思想是通过线性投影来最小化同类样本间的差异,最大化不同类样本间的差异。具体做法是寻找一个向低维空间的投影矩阵W,样本的特征向量x经过投影之后得到的新向量:y = Wx同一类样投影后的结果向量差异尽可能小,不同类的样本差异尽可能大。简单的说,就是经过这个投影之后同一类的样本进来聚集在一起,不同类的样本尽可能离得远。这种最大化类间差异,最小化类内差异的做法,在机器学习的很多地方都有使用。
类内散布矩阵定义为:
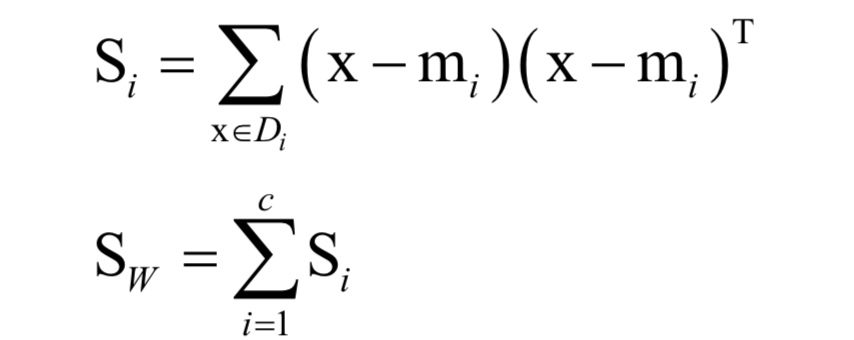
它衡量的内类样本的发散程度。其中mi为每个类的均值向量,m为所有样本的均值向量。类间散布矩阵定义为:
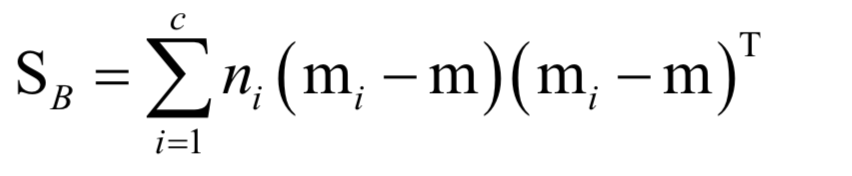
它衡量的了各类样本之间的差异。训练时的优化目标是类间差异与类内差异的比值:
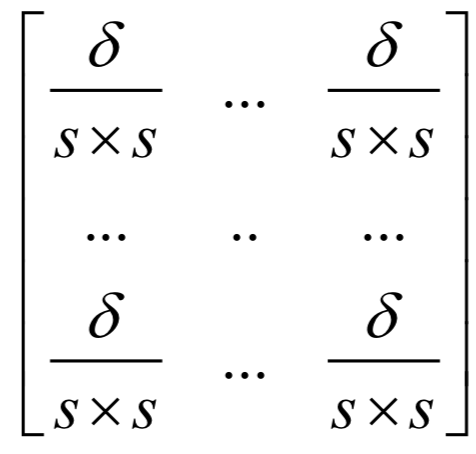
上面的问题带有冗余,如果w是最优解,将其乘以一个不为0的系数之后还是最优解。为了消掉冗余,加上如下约束:
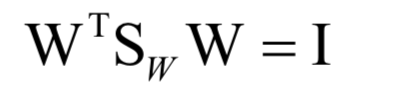
然后使用拉格朗日乘数法,最后归结于求解矩阵的特征值与特征向量:
LDA是有监督的学习算法,在计算过程中利用了样本标签值,是线性模型。LDA也不能直接用于分类和回归问题,要对降维后的向量进行分类还需要借助其他算法。
kNN算法
kNN算法将样本分到离它最相似的样本所属的类。算法本质上使用了模板匹配的思想。要确定一个样本的类别,可以计算它与所有训练样本的距离,然后找出和该样本最接近的k个样本,统计这些样本的类别进行投票,票数最多的那个类就是分类结果。
由于需要计算样本间的距离,因此需要依赖距离定义,常用的有欧氏距离,Mahalanobis距离,Bhattacharyya距离。另外,还可以通过学习得到距离函数,这就是距离度量学习。
kNN算法是一种判别模型,即支持分类问题,也支持回归问题,是一种非线性模型。它天然的支持多分类问题。kNN算法没有训练过程,是一种基于实例的算法。
人工神经网络
人工神经网络是一种仿生的方法,参考了动物的神经元结构。从本质上看,它是一个多层复合函数。对于多层前馈型神经网络,即权连接网络,每一层实现的变换为:
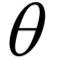
其中W为权重矩阵,b为偏置向量,f为激活函数。正向传播时反复用上上对每一层的输出值进行计算,得到最终的输出。使用激活函数是为了保证非线性,对于激活函数更深入全面的介绍请参考SIGAI之前的公众号文章“理解神经网络的激活函数”,“神经网络的激活函数总结”。万能逼近定理保证了神经网络可以比较闭区间上任意一个连续函数。
权重和偏置通过训练得到,采用的是反向传播算法。反向传播算法从复合函数求导的链式法则导出,用于计算损失函数对权重,偏置的梯度值。算法从最外层的导数值算起,依次递推的计算更内层的导数值,这对应于从神经网络的输出层算起,反向计算每个隐含层参数的导数值。其核心是误差项的定义,定义误差项为损失函数对临时变量u的梯度:
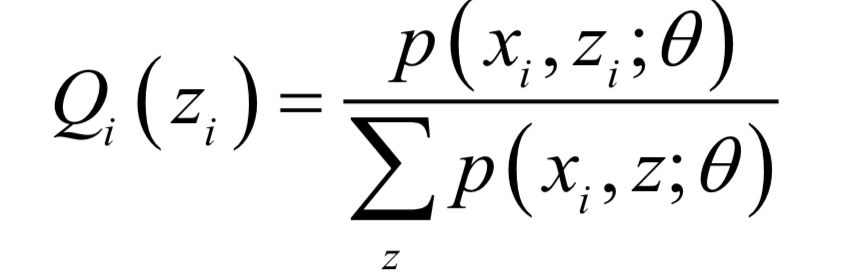
其中,nl是神经网络的层数。最后一个层的误差项可以直接求出,其他层的误差项根据上面的递推公式进行计算。根据误差项,可以计算出损失函数对每一层权重矩阵的梯度值:
以及对偏置向量的梯度值:
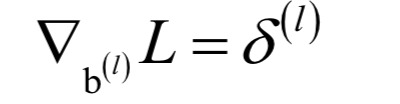
然后用梯度下降法对它们的值进行更新。参数初始化一般采用随机数,而不是简单的初始化为0。为了加快收敛速度,还可以使用动量项,它积累了之前的梯度信息。
神经网络训练时的损失函数不是凸函数,因此有陷入局部极值,鞍点的风险。另外,随着层数的增加,会导致梯度消失问题,这是因为每次计算误差项时都需要乘以激活函数的导数值,如果其绝对值小于1,多次连乘之后导致误差项趋向于0,从而使得计算出来的参数梯度值接近于0,参数无法有效的更新。
如果对反传播算法的推导细节感兴趣,可以阅读SIGAI之前的公众号文章“反向传播算法推导-全连接神经网络”。神经网络的训练算法可以总结为:复合函数求导 + 梯度下降法
标准的神经网络是一种有监督的学习算法,它是一种非线性模型,它既可以用于分类问题,也可以用于回归问题,并且支持多分类问题。
- 下一篇:新能源乘用车产业现状及发展趋势
- 上一篇:量产主控芯片的网络安全设计



编辑推荐




最新资讯
-
中汽中心工程院能量流测试设备上线全新专家
2025-04-03 08:46
-
上新|AutoHawk Extreme 横空出世-新一代实
2025-04-03 08:42
-
「智能座椅」东风日产N7为何敢称“百万级大
2025-04-03 08:31
-
基于加速度计补偿的俯仰角和路面坡度角估计
2025-04-03 08:30
-
《北京市自动驾驶汽车条例》正式实施 L3级
2025-04-02 20:23
