




 广告
广告





















































机器学习最全知识点汇总

1.列举常用的最优化方法
梯度下降法
牛顿法,
拟牛顿法
坐标下降法
梯度下降法的改进型如AdaDelta,AdaGrad,Adam,NAG等。
2.梯度下降法的关键点
梯度下降法沿着梯度的反方向进行搜索,利用了函数的一阶导数信息。梯度下降法的迭代公式为:
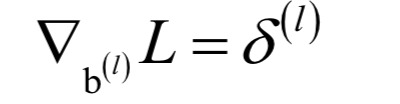
根据函数的一阶泰勒展开,在负梯度方向,函数值是下降的。只要学习率设置的足够小,并且没有到达梯度为0的点处,每次迭代时函数值一定会下降。需要设置学习率为一个非常小的正数的原因是要保证迭代之后的xk+1位于迭代之前的值xk的邻域内,从而可以忽略泰勒展开中的高次项,保证迭代时函数值下降。
梯度下降法只能保证找到梯度为0的点,不能保证找到极小值点。迭代终止的判定依据是梯度值充分接近于0,或者达到最大指定迭代次数。
梯度下降法在机器学习中应用广泛,尤其是在深度学习中。AdaDelta,AdaGrad,Adam,NAG等改进的梯度下降法都是用梯度构造更新项,区别在于更新项的构造方式不同。对梯度下降法更全面的介绍可以阅读SIGAI之前的公众号文章“理解梯度下降法”。
3.牛顿法的关键点
牛顿法利用了函数的一阶和二阶导数信息,直接寻找梯度为0的点。牛顿法的迭代公式为:
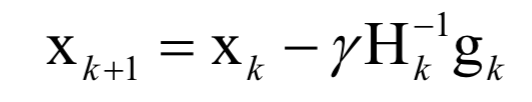
其中H为Hessian矩阵,g为梯度向量。牛顿法不能保证每次迭代时函数值下降,也不能保证收敛到极小值点。在实现时,也需要设置学习率,原因和梯度下降法相同,是为了能够忽略泰勒展开中的高阶项。学习率的设置通常采用直线搜索(line search)技术。
在实现时,一般不直接求Hessian矩阵的逆矩阵,而是求解下面的线性方程组:
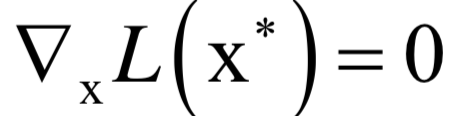
其解d称为牛顿方向。迭代终止的判定依据是梯度值充分接近于0,或者达到最大指定迭代次数。
牛顿法比梯度下降法有更快的收敛速度,但每次迭代时需要计算Hessian矩阵,并求解一个线性方程组,运算量大。另外,如果Hessian矩阵不可逆,则这种方法失效。
4.拉格朗日乘数法
拉格朗日乘数法是一个理论结果,用于求解带有等式约束的函数极值。对于如下问题:
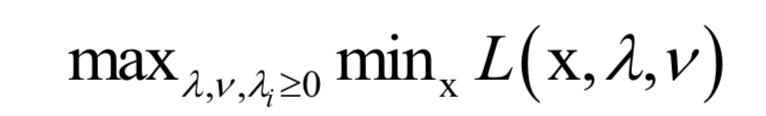
构造拉格朗日乘子函数:
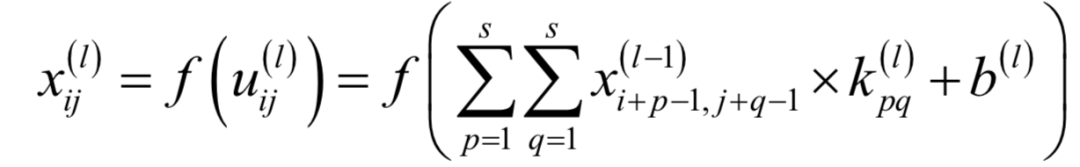
在最优点处对x和乘子变量的导数都必须为0:
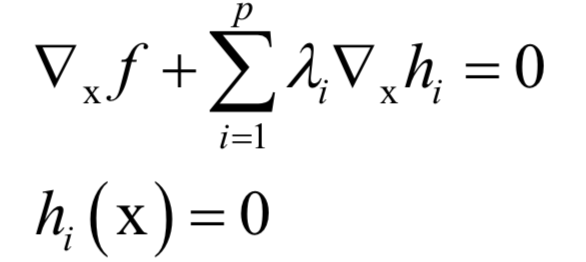
- 下一篇:新能源乘用车产业现状及发展趋势
- 上一篇:量产主控芯片的网络安全设计



编辑推荐




最新资讯
-
ESI 全新BM-Stamp软件在汽车行业冲压仿真精
2025-04-02 09:27
-
车辆软件测试工程师的工作内容---解读GBT德
2025-04-02 08:41
-
浅谈机动车检测行业合规经营与检验人员职业
2025-04-02 08:40
-
NOA该允许驾驶员脱手么?
2025-04-02 08:37
-
联合国最新汽车法规清单(到R176)
2025-04-02 08:31
