




 广告
广告





















































深入了解汽车系统级芯片SoC连载之五:指令集与运算架构

一
指令集
图片来源:互联网
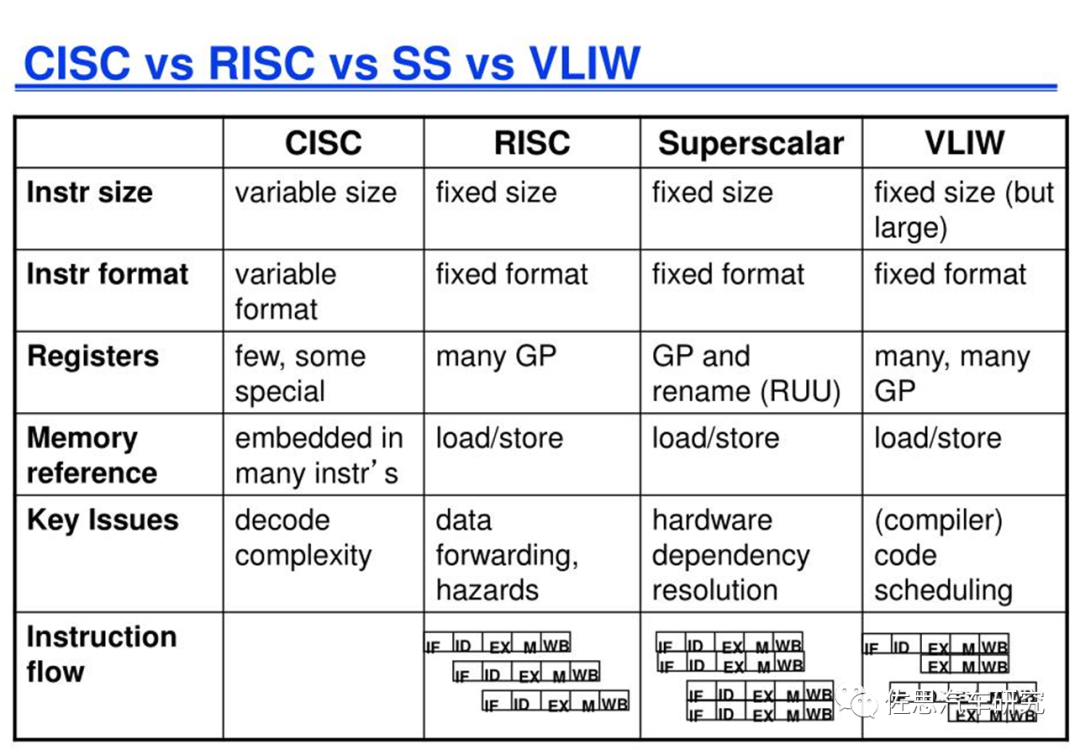
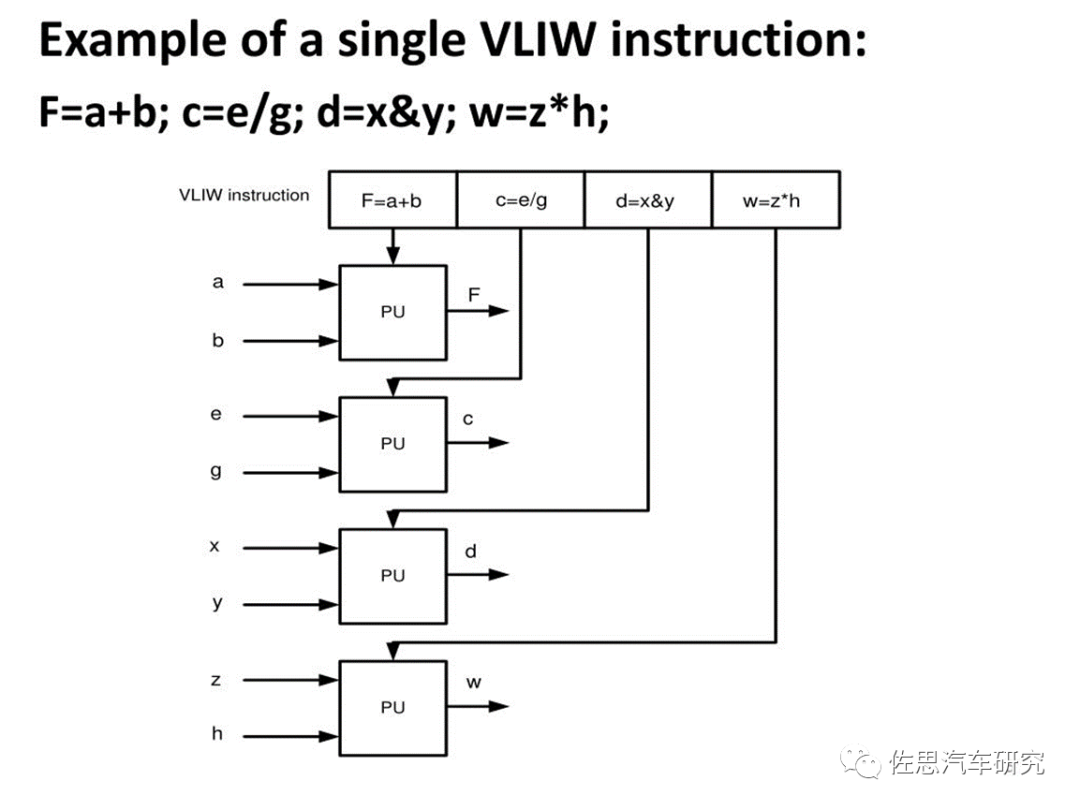
依据指令长度的不同,指令系统可分为复杂指令系统(Complex Instruction Set Computer,简称CISC )、精简指令系统(Reduced Instruction Set Computer,简称 RISC)和超长指令字(Very Long Instruction Word,简称VLIW)指令集三种。CISC中的指令长度可变;RISC中的指令长度比较固定;VLIW本质上来讲是多条同时执行的指令的组合,其“同时执行”的特征由编译器指定,无须硬件进行判断。超标量处理器是动态调度,由硬件发现指令级并行机会并负责正确调度,VLIW是静态调度,由编译器发现指令级并行机会并负责正确调度。 VLIW结构的最初思想是最大限度利用指令级并行(Instruction Level Parallelism,简称ILP),VLIW的一个超长指令字由多个互相不存在相关性(控制相关、数据相关等)的指令组成,可并行进行处理。VLIW可显著简化硬件实现,但增加了编译器的设计难度。由于AI和DSP领域,数据基本上是数据流,没有跳转,因此特别适合静态的VLIW,近期有不少AI芯片使用VLIW架构。
图片来源:互联网
早期的CPU都采用CISC结构,如IBM的System360、Intel的8080和8086系列、Motorola的68000系列等。这与当时的时代特点有关,早期处理器设备昂贵且处理速度慢,设计者不得不加入越来越多的复杂指令来提高执行效率,部分复杂指令甚至可与高级语言中的操作直接对应。这种设计简化了软件和编译器的设计,但也显著提高了硬件的复杂性。 当硬件复杂度逐渐提高时,CISC结构出现了一系列问题。大量复杂指令在实际中很少用到,典型程序所使用的80%的指令只占指令集总指令数的20%,消耗大量精力的复杂设计只有很少的回报。同时,复杂的微代码翻译也会增加流水线设计难度,并降低频繁使用的简单指令的执行效率。针对CISC结构的缺点,RISC遵循简化的核心思路。RISC简化了指令功能,单个指令执行周期短;简化了指令编码,使得译码简单;简化了访存类型,访存只能通过load/store指令实现。RISC指令的设计精髓是简化了指令间的关系,有利于实现高效的流水线、多发射等技术,从而提高主频和效率。 RISC指令系统的最本质特征是通过load/store结构简化了指令间关系,即所有运算指令都是对寄存器运算,所有访存都通过专用的访存指令(load/store)进行。这样,CPU只要通过寄存器的比较就能判断运算指令之间以及运算指令和访存指令之间有没有数据相关性,而较复杂的访存指令相关判断(需要对访存的物理地址进行比较)则只在执行load/store指令的访存部件上进行,从而大大简化了指令间相关性判断的复杂度,有利于CPU采用指令流水线、多发射、乱序执行等提高性能。因此,RISC不仅是一种指令系统类型,同时也是一种提高CPU性能的技术。X86处理器中将 CISC指令译码为类RISC的内部操作,然后对这些内部操作使用诸如超流水、乱序执行、多发射等高效实现手段。而以PowerPC为例的RISC处理器则包含了许多功能强大的指令。 RISC的设计初衷针对CISC CPU复杂的弊端,选择一些可以在单个CPU周期完成的指令,以降低CPU的复杂度,将复杂性交给编译器。举个例子,CISC提供的乘法指令,调用时可完成内存a和内存b中的两个数相乘,结果存入内存a,需要多个CPU周期才可以完成;而RISC不提供“一站式”的乘法指令,需调用四条单CPU周期指令完成两数相乘:内存a加载到寄存器,内存b加载到寄存器,两个寄存器中数相乘,寄存器结果存入内存a。按此思路,早期设计出的RISC指令集,指令数是比CISC少些,但后来,很多RISC的指令集中指令数反超了CISC,因此,引用指令的复杂度而非数量来区分两种指令集。 CISC指令的格式长短不一,执行时的周期次数也不统一,而RISC结构刚好相反,它是定长的,故适合采用管线处理架构的设计,进而可以达到平均一周期完成一指令的方向努力。显然,在设计上RISC较CISC简单,同时因为CISC的执行步骤过多,闲置的单元电路等待时间增长,不利于平行处理的设计,所以就效能而言RISC较CISC还是站了上风,但RISC因指令精简化后造成应用程式码变大,需要较大的程式存储空间,且存在指令种类较多等等的缺点。 对CPU内核结构的影响X86指令集早期通常只有8个通用寄存器。所以,CISC的CPU执行是大多数时间是在访问存储器中的数据,而不是寄存器中的。这就拖慢了整个系统的速度。RISC系统往往具有非常多的通用寄存器,早期多是27个,并采用了重叠寄存器窗口和寄存器堆等技术使寄存器资源得到充分的利用。 大部分情况下(90%)的时间内处理器都在运行少数的指令,其余的时间则运行各式各样的复杂指令(复杂就意味着较长的运行时间),RISC就是将这些复杂的指令剔除掉,只留下最经常运行的指令(所谓的精简指令集),然而被剔除掉的那些指令虽然实现起来比较麻烦,却在某些领域确实有其价值,RISC的做法就是将这些麻烦都交给软件,CISC的做法则是像现在这样: 由硬件设计完成。因此RISC指令集对编译器要求很高,而CISC则很简单。对编程人员的要求也类似。 因此x86架构通常只需要一个复杂解码器,简单解码器可以将一条x86指令(包括大部分SSE指令在内)翻译为一条微指令(uop),而复杂解码器则将一些特别的(单条)x86指令翻译为1~4 条uops——在极少数的情况下,某些指令需通过额外的可编程microcode解码器解码为更多的uops (有时候甚至可达几百个,因为一些IA指令很复杂,并且可以带有很多的前缀/修改量,当然这种情况很少见)。
二
运算架构
冯诺伊曼架构与哈佛架构
图片来源:互联网
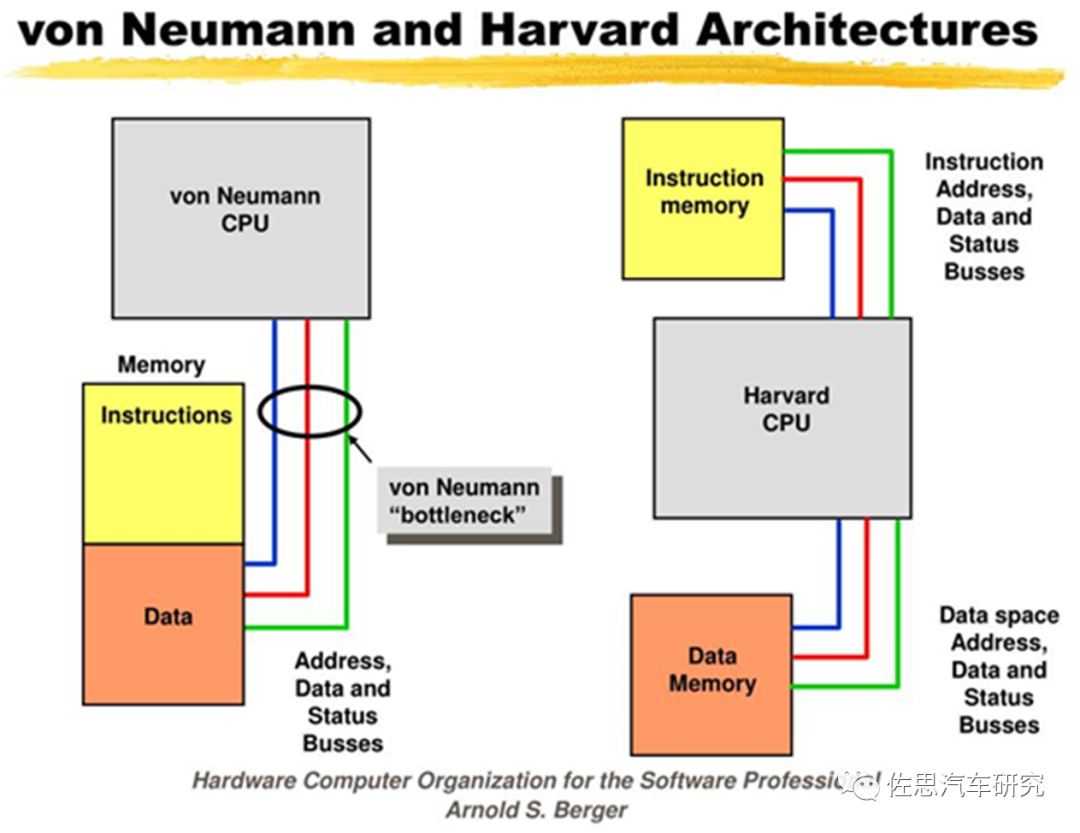
冯诺伊曼架构与哈佛架构最大区别是存储总线,冯诺依曼架构的指令和数据是共用一条总线,也就是说,不能同时读取指令和数据,必须在时间序列上分开。哈佛架构是指令和数据用不同的总线,可以同时读取指令和数据。 早期的计算机设计中,程序和数据是俩个截然不同的概念,数据放在存储器中,而程序作为控制器的一部分,这样的计算机计算效率低,灵活性较差。冯.诺依曼结构中,将程序和数据一样看待,将程序编码为数据,然后与数据一同存放在存储器中,这样计算机就可以调用存储器中的程序来处理数据了。这意味着无论什么程序,最终都是会转换为数据的形式存储在存储器中,要执行相应的程序只需要从存储器中依次取出指令、执行,而无需再从控制器中取出,冯.诺依曼结构的灵魂所在正是这里:这种设计思想导致了硬件和软件的分离,即硬件设计和程序设计可以分开执行。 现代计算架构中,整个计算架构通常都采用冯诺依曼架构,在CPU内部采用类哈佛架构,在现代CPU内部的一级缓存中,指令和数据是分开存储的,但指令和数据的寻址空间address space还是共享的,这不能算严格的哈佛架构,但思路是哈佛架构的思路。
冯诺依曼详细架构
图片来源:互联网
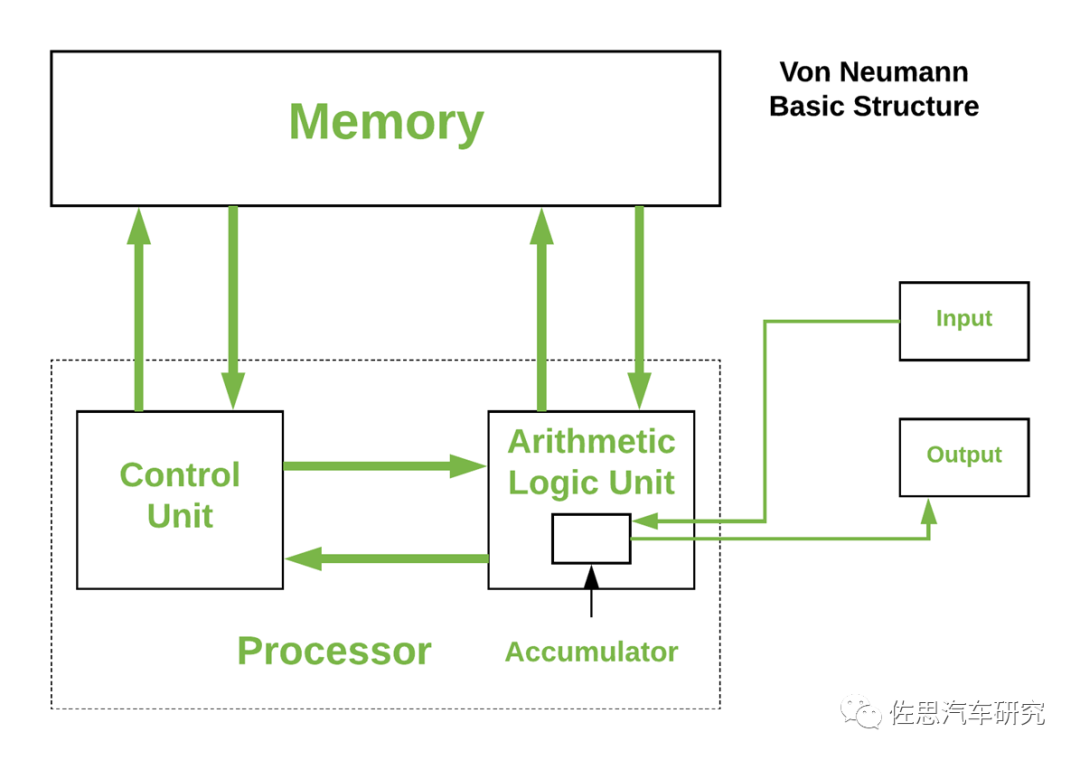
虚线框内再加上多级缓存就是现代意义上的CPU,鼠标键盘是输入设备、显示器是输出设备;手机触摸屏既是输入设备又是输出设备;服务器中网卡既是输入设备又是输出设备;所有的计算机程序都可以抽象为输入设备读取信息,通过CPU来执行存储在存储器中的程序,结果通过输出设备反馈给用户。 算术逻辑单元(Arithmetic Logic Unit,ALU)。ALU的主要功能就是在控制信号的作用下,完成加、减、乘、除等算术运算以及与、或、非、异或等逻辑运算以及移位、补位等运算。控制单元(Control Unit),是计算机的神经中枢和指挥中心,只有在控制器的控制下,整个计算机才能有条不紊地工作、自动执行程序。控制器的工作流程为:从内存中取指令、翻译指令、分析指令,然后根据指令的内存向有关部件发送控制命令,控制相关部件执行指令所包含的操作。 计算机内部,程序和数据都是以二进制代码的形式存储的,均以字节为单位(8位)存储在存储器中,一个字节占用一个存储单元,且每个存储单元都有唯一的地址号。CPU可以直接使用指令对内部存储器按照地址进行读写两种操作,读:将内存中某个存储单元的内容读出,送入CPU的某个寄存器中;写:在控制器的控制下,将CPU中某寄存器内容传到某个存储单元中。要注意,内存中的数据和地址码都是二进制数,但是俩者是不同的,一个地址码可以指向一个存储单元,地址是存储单元的位置,数据是存储单元的内容。地址码的长度由内存单元的个数确定。 内存的存取速度会直接影响计算机的运算速度,由于CPU是高速器件,但是CPU的速度是受制于内存的存取速度的,所以为解决CPU与内存速度不匹配的问题,在CPU和内存直接设置了一种高速缓冲存储器Cache。Cache是计算机中的一个高速小容量存储器,其中存放的是CPU近期要执行的指令和数据,其存取速度可以和CPU的速度匹配,一般采用静态RAM充当Cache即缓存。 内存按工作方式的不同又可以分为俩部分:RAM:随机存储器,可以被CPU随机读取,一般存放CPU将要执行的程序、数据,断电丢失数据。ROM:只读存储器,只能被CPU读,不能轻易被CPU写,用来存放永久性的程序和数据,比如:系统引导程序、监控程序等。具有掉电非易失性。
哈佛架构
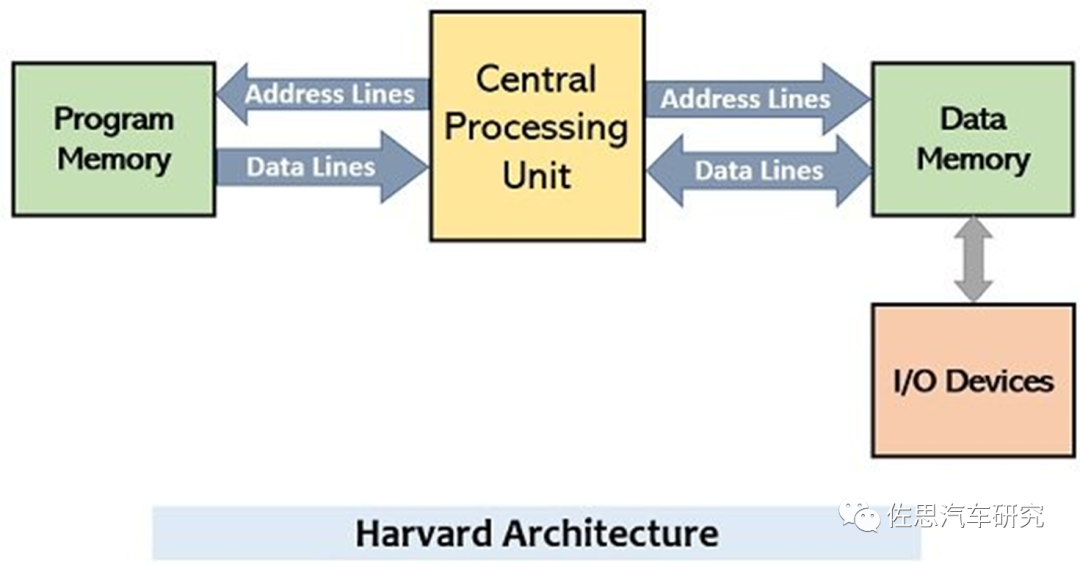
图片来源:互联网
通常哈佛架构有四条总线,处理器与存储器之间有两条总线,一条是寻址,一条是数据,哈佛架构的指令(即编程Program)和数据分开存储,也就是四条总线。 典型的哈佛架构是DSP,通常我们把冯诺依曼架构的处理器叫GPP,即通用型处理器。DSP是为单一密集计算任务如视频编解码、FIR滤波器,这些任务拆解到底层通常是乘法或乘积累加。DSP为了进行这些密集计算任务,添加了一些固定算法指令,比如单周期乘加指令、逆序加减指令(FFT时特别有用,不是ARM的那种逆序),块重复指令(减少跳转延时)等等,甚至将很多常用的由几个操作组成的一个序列专门设计一个指令可以一周期完成(比如一指令作一个乘法,把结果累加,同时将操作数地址逆序加1),极大地提高了信号处理的速度。由于数字处理的读数、回写量非常大,为了提高速度,采用指令、数据空间分开的方式,以两条总线来分别访问两个空间,同时,一般在DSP内部有高速RAM,数据和程序要先加载到高速片内RAM中才能运行。DSP为提高数字计算效率,牺牲了存储器管理的方便性,对多任务的支持要差的多,所以DSP不适合于作多任务控制作用。 像乘积累加计算,早期GPP(通用处理器)处理一般是用加法代替乘法,要n多CPU周期,尽管CPU主频很快,但还是要相当时间,所以早期CPU会特设一个乘法器专门做乘法。乘法都如此麻烦,乘积累加就更麻烦,通常做一次乘法会发生4次存储器访问,用掉至少四个指令周期。再做加法,再用掉两个指令周期,而DSP只需要一个指令周期。 现在典型的高性能GPP实际上已包含两个片内高速缓存,一个是数据,一个是指令,它们直接连接到处理器核,以加快运行时的访问速度。从物理上说,这种片内的双存储器和总线的结构几乎与哈佛结构的一样了。然而从逻辑上讲,两者还是有重要的区别。GPP使用控制逻辑来决定哪些数据和指令字存储在片内的高速缓存里,其程序员并不加以指定(也可能根本不知道)。与此相反,DSP使用多个片内存储器和多组总线来保证每个指令周期内存储器的多次访问。在使用DSP时,程序员要明确地控制哪些数据和指令要存储在片内存储器中,哪些要放在片外。也就是说GPP的数据和指令程序员无法修改,有时可能出现错误,也会导致效率的下降,不过由于在一个寻址空间内,即便出现错误,带来的后果也只是延迟,效率降低。而DSP不同,它是非常灵活的,可以保证任何状况下效率都是最高,当然缺点是万一数据和指令错误,可能会出现中断乃至系统崩溃,因此DSP只能执行比较简单纯粹的任务。 程序员在写程序时,必须保证处理器能够有效地使用其双总线。此外,DSP处理器几乎都不具备数据高速缓存。这是因为DSP的典型数据是数据流。也就是说,DSP处理器对每个数据样本做计算后,就丢弃了,几乎不再重复使用。 DSP算法的一个共同的特点,即大多数的处理时间是花在执行较小的循环上,也就容易理解,为什么大多数的DSP都有专门的硬件,用于零开销循环。所谓零开销循环是指处理器在执行循环时,不用花时间去检查循环计数器的值、条件转移到循环的顶部、将循环计数器减1。与此相反,GPP的循环使用软件来实现。某些高性能的GPP使用转移预报硬件,几乎达到与硬件支持的零开销循环同样的效果。 GPP的程序通常并不在意处理器的指令集是否容易使用,因为他们一般使用像C或C++等高级语言。而对于DSP的程序员来说,不幸的是主要的DSP应用程序都是用汇编语言写的(至少部分是汇编语言优化的)。这里有两个理由:首先,大多数广泛使用的高级语言,例如C,并不适合于描述典型的DSP算法。其次,DSP结构的复杂性,如多存储器空间、多总线、不规则的指令集、高度专门化的硬件等,使得难于为其编写高效率的编译器。即便用编译器将C源代码编译成为DSP的汇编代码,优化的任务仍然很重。典型的DSP应用都具有大量计算的要求,并有严格的开销限制,使得程序的优化必不可少(至少是对程序的最关键部分)。因此,考虑选用DSP的一个关键因素是,是否存在足够的能够较好地适应DSP处理器指令集的程序员。 除DSP外,MCU一般也是哈佛架构,因为MCU所需要的数据和指令体积都很小,分开存储也不会增加多少成本。MCU的运算能力一般较弱,运行频率较低,一般只有几十MHz到300MHz,因此运算需要高效率,冯诺依曼架构不适合。再有就是MCU一般是嵌入式系统,电池供电,对功耗要求高,需要低功耗,需要高效率的哈佛架构。
三
FPGA
大部分FPGA器件采用了查找表(Look Up Table,LUT)结构。查找表的原理类似于ROM,其物理结构是静态存储器(SRAM),N个输入项的逻辑函数能够由一个2^N位容量的SRAM实现, 函数值存放在SRAM中,SRAM的地址线起输入线的作用,地址即输入变量值,SRAM的输出为逻辑函数值。由连线开关实现与其它功能块的连接。 RAM基本的作用就是存储代码和数据供CPU在需要的时候调用。可是这些数据并非像用袋子盛米那么简单。更像是图书馆中用有格子的书架存放书籍一样。不但要放进去还要可以在需要的时候准确地调用出来。尽管都是书可是每本书是不同的。对于RAM等存储器来说也是一样的,尽管存储的都是代表0和1的代码,可是不同的组合就是不同的数据。让我们又一次回到书和书架上来,假设有一个书架上有10行和10列格子(每行和每列都有0-9的编号),有100本书要存放在里面,那么我们使用一个行的编号+一个列的编号就能确定某一本书的位置。假设已知这本书的编号87,那么我们首先锁定第8行。然后找到第7列就能准确的找到这本书了。 在RAM存储器中也是利用了相似的原理。如今让我们回到RAM存储器上,对于RAM存储器而言数据总线是用来传入数据或者传出数据的。由于存储器中的存储空间是假设前面提到的存放图书的书架一样通过一定的规则定义的,所以我们能够通过这个规则来把数据存放到存储器上相应的位置。而进行这样的定位的工作就要依靠地址总线来实现了。对于CPU来说,RAM就像是一条长长的有非常多空格的细线。每一个空格都有一个唯一的地址与之相应。假设CPU想要从RAM中调用数据,首先需要给地址总线发送地址数据定位要存取的数据,然后等待若干个时钟周期之后,数据总线就会把传输数据给CPU。 FPGA是基于逻辑门和触发器的,它是并行执行方式,没有取指到执行这种操作。简单而言,就是通过烧写文件去配置查找表的内容,从而在相同的电路情况下实现了不同的逻辑功能,数字电路中所有逻辑门和触发器均可以实现,适合真正意义上的并行任务处理。FPGA程序在编译后实际上是转换为内部的连线表,相当于FPGA内部提供了大量的与非门、或非门、触发器等基本数字逻辑器件,编程决定了有多少器件被使用以及它们之间的连接方式。通过编程,用户可对FPGA内部的逻辑模块和I/O模块重新配置,以实现用户的逻辑。它还具有静态可重复编程和动态在系统重新配置的特性,使得硬件的功能可以像软件一样通过编程来修改。只要FPGA规模够大,这些数字器件理论上能形成一切数字系统,包括MCU,甚至CPU。因FPGA是纯数字电路,在抗干扰和速度性能上有很大优势。 FPGA没有取指到执行这种操作,效率极高,功耗很低,又是天生的并行计算结构。但是FPGA采用的是统计型连线结构。这类器件具有较复杂的可编程布线资源,内部包含多种长度的金属连线,从而使片内互连十分灵活。因此每次编程后的连线可不尽相同。但是这些布线资源消耗了很大一部分芯片面积,而ASIC只需要选用最短长度的布线即可,面积大大缩小,同样密度,ASIC大约可以缩小40%的面积,这就意味着FPGA比ASIC要贵40%左右,FPGA的算力达到一定程度后,再增加算力,价格会飞速增长。
- 下一篇:仿真是正向设计的核心
- 上一篇:整车结构路噪及其控制原则



编辑推荐




最新资讯
-
中汽中心工程院能量流测试设备上线全新专家
2025-04-03 08:46
-
上新|AutoHawk Extreme 横空出世-新一代实
2025-04-03 08:42
-
「智能座椅」东风日产N7为何敢称“百万级大
2025-04-03 08:31
-
基于加速度计补偿的俯仰角和路面坡度角估计
2025-04-03 08:30
-
《北京市自动驾驶汽车条例》正式实施 L3级
2025-04-02 20:23
