




 广告
广告





















































毫末智行「自动驾驶算法」的秘密

处理多层神经网络的技术趋势
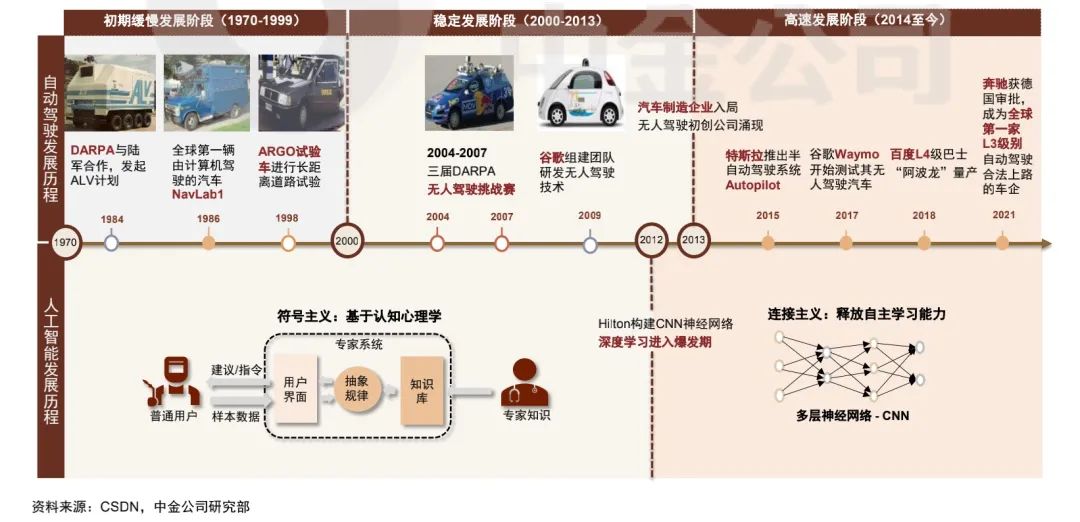
视觉感知的技术突破,进一步推动了其他传感器(比如激光雷达和毫米波雷达)的感知算法以及多传感器融合算法的进步。另一方面,深度学习中的强化学习算法也在决策系统中起到了非常重要的作用。
对于深度学习算法来说,除了算法本身的能力以外,高质量,大规模的训练数据也是算法取得成功的关键因素。因此,如何高效地采集和标注数据对于每一家自动驾驶公司来说都是非常现实的课题。
在数据采集方面,面向量产的公司有着先天的优势。路面上行驶的数十万,甚至上百万的车辆,每一辆都可以源源不断地提供丰富的路况数据,加在一起就是一个海量的自动驾驶数据库。
相比之下,面向 L4 级别的公司只能依靠有限的测试车辆来采集数据。目前路测规模最大的 Waymo 也只有几百辆测试车,数据采集的规模自然不可同日而语。
有了海量数据是不是问题就解决了呢?
显然没有那么简单。
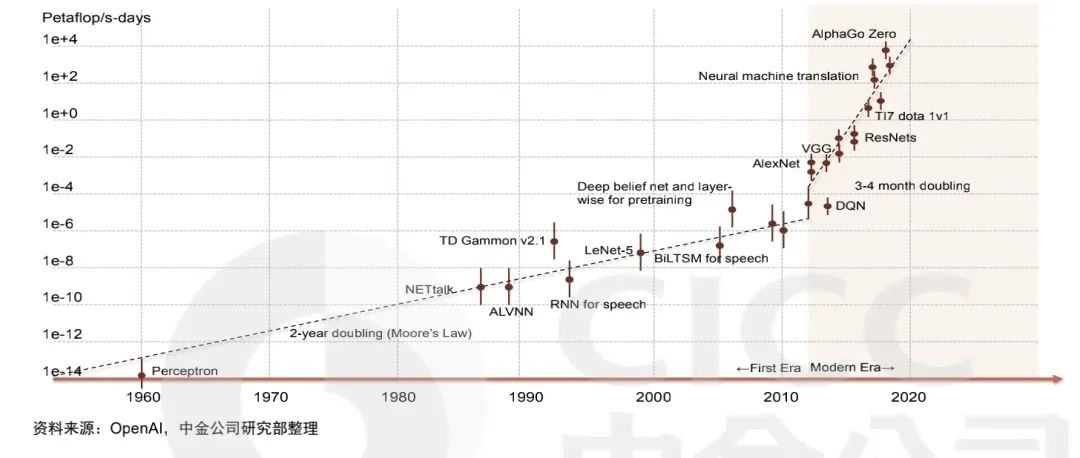
虽然说深度神经网络依赖于大数据,但是不同网络结构学习海量数据的能力还是有很大差别的。最早出现的多层感知机结构网络只有几层,只需要很少的数据就可以使网络的学习能力达到饱和。
近些年来提出的卷积神经网络(CNN),深度从十几层增加到上百层,甚至上千层,这时就需要大规模的训练数据来保证网络训练的质量。
但是简单的堆积层数也是行不通的,这时深度学习领域一个非常关键的技术 ResNet(深度残差网络)出现了,它提出通过增加额外的连接,使得信息可以从浅层直接传输到深层,减少信息在网络层之间传输时的损失。通过这个技术,卷积神经网络才能拥有更深的结构,从而更好地利用大规模数据。
虽然有了 ResNet 技术,深度卷积神经网络在数据规模增加到一定程度之后,其性能的提升也变得非常有限,也就是说存在饱和的趋势,这说明神经网络的学习能力还是存在着一定的瓶颈。
大约从 2017 年开始,一种新型的神经网络结构开始引起研究人员的广泛关注,那就是大名鼎鼎的基于注意力机制的 Transformer 网络。
Transformer 首先被应用在自然语言处理领域(NLP),用来处理序列文本数据。
谷歌团队提出的用于生成词向量的 BERT 算法在 NLP 的 11 项任务中均取得了大幅的效果提升,而 BERT 算法中最重要的部分便是 Transformer。
在自然语言处理领域取得广泛应用后,Transformer 也被成功移植到了很多视觉任务上,比如「图像分类,物体检测」等,并同样取得了不错的效果。Transformer 在海量数据上可以获得更大的性能提升,也就是说学习能力的饱和区间更大。
有研究表明,当训练数据集增大到包含 1 亿张图像时,Transformer 的性能开始超过 CNN。而当图像数量增加到 10 亿张时,两者的性能差距变得更大。
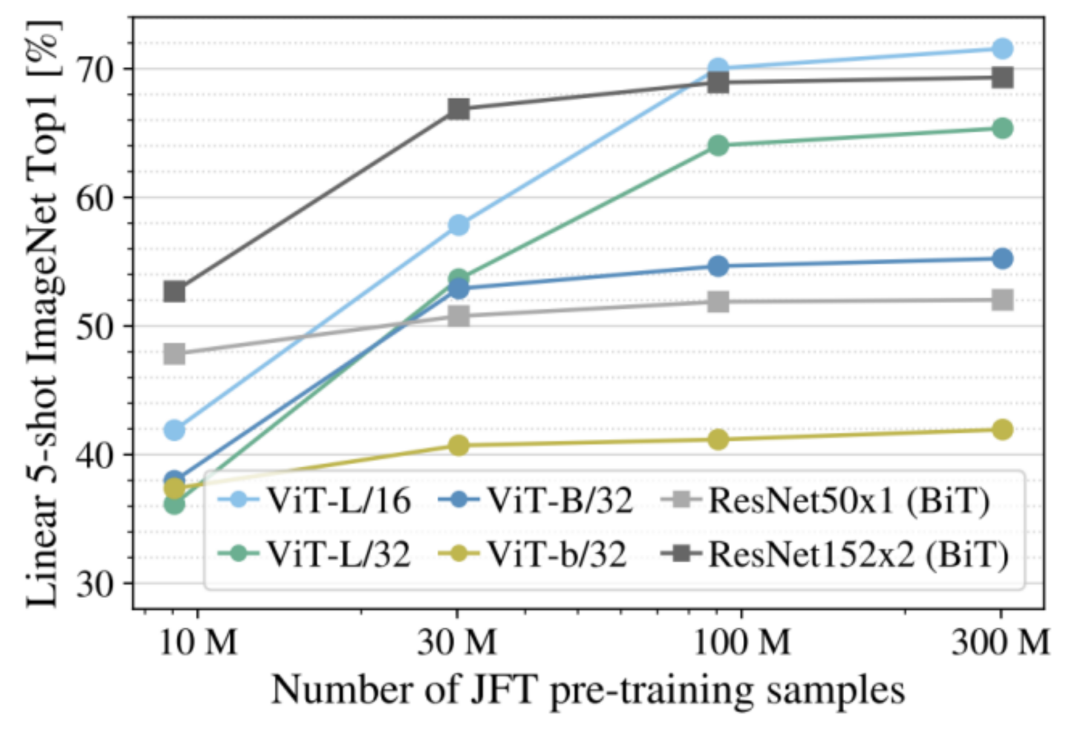
上面是 ResNet(CNN)和 ViT(Transformer)在不同大小训练集上达到的图像分类正确率。数据量为 1000 万时,Transformer 的正确率远低于 CNN,但是当数据量增加到 1 亿时,Transformer 就开始超过 CNN。
此外,CNN 网络在数据量超过 1 亿以后呈现饱和趋势,而 Transformer 的准确率还在继续增加。
简单理解就是,Transformer 在海量数据的处理能力上具有巨大冗余优势。
正是因为看到了这一点,面向量产的自动驾驶公司在拥有数据收集优势的情况下,自然就会倾向于选择 Transformer 作为其感知算法的主体。
2021 年夏天,特斯拉的自动驾驶技术负责人 Andrej Karpathy 博士在 AI Day 上,公开了 FSD 自动驾驶系统中采用的算法,而 Transformer 则是其中最核心的模块之一。在国内方面,毫末智行也同样提出将 Transformer 神经网络与海量数据进行有效的融合。
在 2021 年底,毫末智行 CEO 顾维灏在毫末 AI Day 上介绍了 MANA(雪湖)数据智能体系。除了视觉数据以外,MANA 系统还包含了激光雷达数据。
并基于 Transformer 神经网络模型来进行空间、时间、传感器三个维度的融合,从而去提升感知算法的准确率。
了解了目前自动驾驶技术发展的趋势以后,文章接下来的部分会首先简单介绍一下 Transformer 的设计动机和工作机制,然后详细解读特斯拉和毫末智行的技术方案。
- 下一篇:电动汽车热泵空调系统
- 上一篇:张工聊测量 | 电池可拆卸性的测试与分析



编辑推荐




最新资讯
-
中汽中心工程院能量流测试设备上线全新专家
2025-04-03 08:46
-
上新|AutoHawk Extreme 横空出世-新一代实
2025-04-03 08:42
-
「智能座椅」东风日产N7为何敢称“百万级大
2025-04-03 08:31
-
基于加速度计补偿的俯仰角和路面坡度角估计
2025-04-03 08:30
-
《北京市自动驾驶汽车条例》正式实施 L3级
2025-04-02 20:23
