




 广告
广告





















































毫末智行「自动驾驶算法」的秘密

Transformer 神经网络
在说 Transformer 之前,要先理解一个概念:「机器翻译、注意力机制」。
机器翻译
机器翻译可以粗暴理解成 「由现代化计算机模拟人类的智能活动,自动进行语言之间的翻译」。
说起翻译,不得不提自然语言处理(NLP)领域的机器翻译应用,简单说就是「输入一句话,输出另一句话」,后者可以是前者的其他语种表达,如「自行车翻译为 Bicycle」;也可以是前者的同语种关键词表达,如「骑行的两轮车」。
而工程师把「翻译」的过程,用数学函数设计了一套模型,这个模型就是大家通常意义上理解的「神经网络」。
在 Transformer 到来之前,大家一般都是使用基于循环神经网络 RNN 的「编码器-解码器」结构来完成序列翻译。
所谓序列翻译,「就是输入一个序列,输出另一个序列」。例如,汉英翻译即输入的序列是汉语表示的一句话,而输出的序列即为对应的英语表达。
基于 RNN 的架构有一个明显弊端就是,RNN 属于序列模型,需要以一个接一个的序列化方式进行信息处理,注意力权重需要等待序列全部输入模型之后才能确定,简单理解就是,需要 RNN 对序列「从头看到尾」。
例如:
面对翻译问题「A magazine is stuck in the gun」,其中的「Magazine」到底应该翻译为「杂志」还是「弹匣」?
当看到「gun」一词时,将「Magazine」翻译为「弹匣」才确认无疑。在基于RNN的机器翻译模型中,需要一步步的顺序处理从 Magazine 到 gun 的所有词语,而当它们相距较远时 RNN 中存储的信息将不断被稀释,翻译效果常常难以尽人意,而且效率非常很低。
这种架构无论是在训练环节还是推理环节,都具有大量的时间开销,并且难以实现并行处理。而这个时候,工程师又想到了一个方案,就是在标准的 RNN 模型中加入一个「注意力机制」。
什么是注意力机制?
「深度学习中的注意力机制,源自于人脑的注意力机制,当人的大脑接受外部信息时,如视觉信息,听觉信息时,往往不会对全部信息处理和理解,而只会将注意力集中在部分显著或者感兴趣的信息上,这样有利于滤除不重要的信息,而提升的信息处理效率。」
加入注意力机制的模型会一次性的「看见」所有输入的词汇,利用注意力机制将距离不同的单词进行结合,为序列中每个元素提供全局的上下文。
谷歌团队赋予新模型一个大名鼎鼎的名字:「Transformer」。
Transformer 与处理序列数据常用的循环神经网络(RNN)不同,Transformer 中的注意力机制并不会按照顺序来处理数据,也就是说,每个元素和序列中的所有元素都会产生联系,这样就保证了不管在时序上相距多远,元素之间的相关性都可以被很好地保留。
而这种长时相关性对于自然语言处理的任务来说通常都是非常重要。比如下图中,句子中的「it」所指的是「The animal」,但是这两个元素之间相距较远,如果用 RNN 来顺序处理的话很难建立起两者之间的联系。
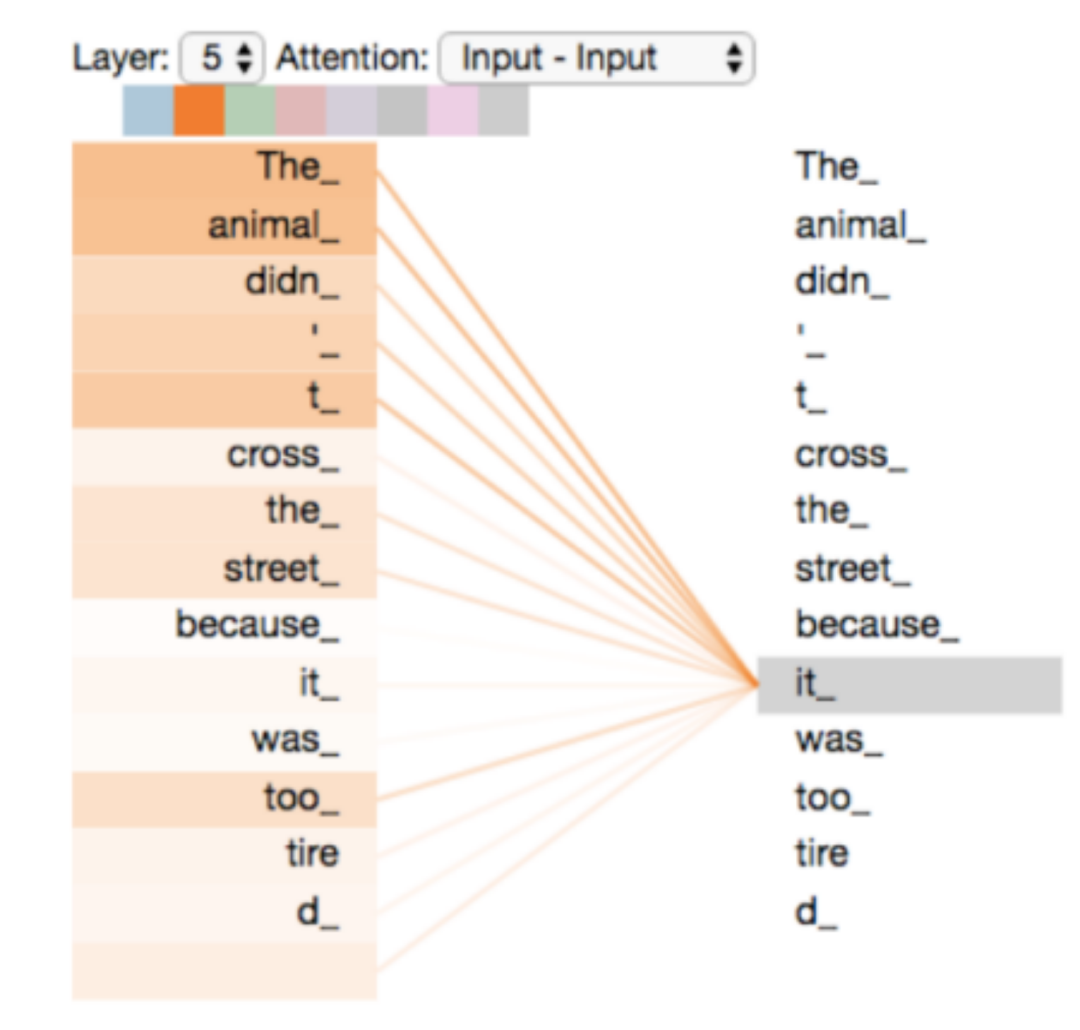
一个句子中各个单词之间的相关性
Transformer 并不关心顺序,在计算相关性时,每个元素的重要性是根据数据本身的语义信息计算出来的。因此,可以轻松地提取任意距离元素之间的相关性。
为什么要说这些?
因为在视觉任务图像分类和物体检测上,通过带有注意力机制的 Transformer 模型其结果出乎意料的好。
为什么源自自然语言领域的算法,在视觉上同样适用呢?
原因主要有两点:
虽然图像本身不是时间序列数据,但可以看作空间上的序列,视觉任务一个关键的步骤就是要提取像素之间的相关性,普通的 CNN 是通过卷积核来提取局部的相关性(也称为:局部感受野)。与 CNN 的局部感受野不同,Transformer 可以提供全局的感受野。因此,特征学习能力相比 CNN 要高很多。
如果进一步考虑视频输入数据的话,那么这本身就是时序数据,因此,更加适合Transformer 的处理。
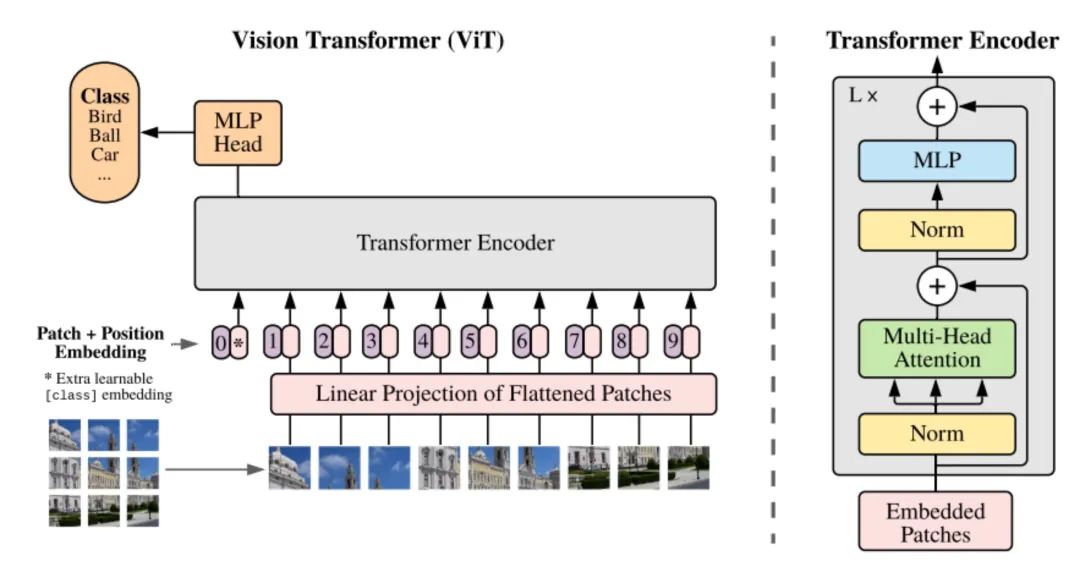
Transformer 在图像分类中的应用
在图 3 的例子中,Transformer 被用来进行图像分类的任务。图像被均匀地分成若干小块,按照空间排列的顺序组成了一个图像块的序列。每个图像块的像素值(或者其他特征)组成了该图像块的特征向量,经过 Transformer 编码在进行拼接后就得到整幅图像的特征。
上图的右侧,给出了编码器的具体结构,其关键部分是一个 「多头注意力模块」。
简单来说,多头注意力其实就是多个注意力机制模块的集成,这些模块各自独立的进行编码,提取不同方面的特征,在增加编码能力的同时,也可以非常高效的在计算芯片上实现并行处理。
综上所述,这也就是中金《人工智能十年展望(三):AI 视角下的自动驾驶行业全解析》这份报告里说的:
由于 Transformer 可以很好地在 「空间-时序」 维度上进行建模,目前特斯拉和毫末智行等行业龙头通过 Transformer 在感知端提升模型效果。
特斯拉从安装在汽车周围的八个摄像头的视频中用传统的 ResNet 提取图像特征,并使用 Transformer CNN、3D 卷积中的一种或者多种组合完成跨时间的图像融合,实现基于 2D 图像形成具有 3D 信息输出。
毫末智行的 AI 团队正在逐步将基于 Transformer 的感知算法应用到实际的道路感知问题,如车道线检测、障碍物检测、可行驶区域分割、红绿灯检测&识别、道路交通标志检测、点云检测&分割等。
- 下一篇:电动汽车热泵空调系统
- 上一篇:张工聊测量 | 电池可拆卸性的测试与分析



编辑推荐




最新资讯
-
中汽中心工程院能量流测试设备上线全新专家
2025-04-03 08:46
-
上新|AutoHawk Extreme 横空出世-新一代实
2025-04-03 08:42
-
「智能座椅」东风日产N7为何敢称“百万级大
2025-04-03 08:31
-
基于加速度计补偿的俯仰角和路面坡度角估计
2025-04-03 08:30
-
《北京市自动驾驶汽车条例》正式实施 L3级
2025-04-02 20:23
