




 广告
广告





















































毫末智行「自动驾驶算法」的秘密

04
毫末智行的 MANA 系统解读

依托长城汽车,毫末智行可以获得海量的真实路测数据,对于数据的处理问题,毫末智行也提出将 Transformer 引入到其数据智能体系 MANA 中,并逐步应用到实际的道路感知问题,比如障碍物检测、车道线检测、可行驶区域分割、交通标志检测等等。
从这一点上就可以看出,量产车企在有了超大数据集作为支撑以后,其技术路线正在走向趋同。
在自动驾驶技术百花齐放的时代,选择一条正确的赛道,确立自身技术的优势,无论对于特斯拉还是毫末智行来说,都是极其重要的。
在自动驾驶技术的发展中,一直就对采用何种传感器存在争论。目前争论的焦点在于是走纯视觉路线还是激光雷达路线。
特斯拉采用纯视觉方案,这也是基于其百万量级的车队和百亿公里级别的真实路况数据做出的选择。
而采用激光雷达,主要有两方面的考虑:
-
数据规模方面的差距其他自动驾驶公司很难填补,要获得竞争优势就必须增加传感器的感知能力。目前,半固态的激光雷达成本已经降低到几百美元的级别,基本可以满足量产车型的需求。
-
从目前的技术发展来看,基于纯视觉的技术可以满足 L2/L2+ 级别的应用,但是对L3/4级的应用(比如RoboTaxi)来说,激光雷达还是必不可少的。
在这种背景下,谁能够既拥有海量数据,又能同时支持视觉和激光雷达两种传感器,那么无疑会在竞争中占据先发的优势。显然,毫末智行在这个方向上已经占据了先机。
根据毫末智行 CEO 顾维灏的在 AI Day 上的介绍,MANA 系统采用 Transformer 在底层融合视觉和激光雷达数据,进而实现空间、时间、传感器三位一体的深层次感知。
下面我就来详细解读一下 MANA 系统,尤其是与特斯拉 FSD 的差异之处。
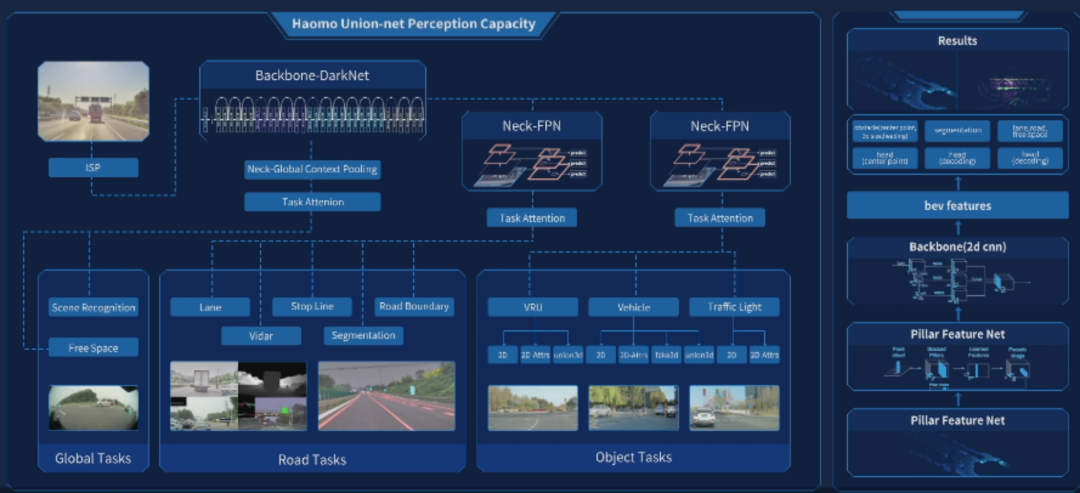
视觉感知模块
相机获取原始数据之后,要经过 ISP(Image Signal Process)数字处理过程后,才能提供给后端的神经网络使用。
ISP 的功能一般来说是为了获得更好的视觉效果,但是神经网络其实并不需要真正的「看到」数据,视觉效果只是为人类设计的。
因此,将 ISP 作为神经网络的一层,让神经网络根据后端的任务来决定 ISP 的参数并对相机进行校准,这有利于最大程度上保留原始的图像信息,也保证采集到的图像与神经网络的训练图像在参数上尽可能的一致。
处理过后的图像数据被送入主干网络 Backbone,毫末采用的 DarkNet 类似于多层的卷积残差网络(ResNet),这也是业界最常用的主干网络结构。
主干网络输出的特征再送到不同的头(Head)来完成不同的任务。
这里的任务分为三大类:全局任务(Global Task)、道路任务(Road Tasks)和目标任务(Object Tasks)。
不同的任务共用主干网络的特征,每个任务自己拥有独立的 Neck 网络,用来提取针对不同任务的特征。这与特斯拉 HydraNet 的思路是基本一致的。
但是 MANA 感知系统的特点在于 「为全局任务设计了一个提取全局信息的 Neck 网络」。
这一点其实是非常重要的,因为全局任务(比如可行驶道路的检测)非常依赖于对场景的理解,而对场景的理解又依赖于全局信息的提取。
MANA 系统的视觉和激光雷达感知模块
激光雷达感知模块
激光雷达感知采用的是 PointPillar 算法,这也是业界常用的一个基于点云的三维物体检测算法。这个算法的特点在于:「将三维信息投影到二维(俯视视图),在二维数据上进行类似于视觉任务中的特征提取和物体检测」。
这种做法的优点在于避免了计算量非常大的三维卷积操作,因此,算法的整体速度非常快。PointPillar 也是在点云物体检测领域第一个能够达到实时处理要求的算法。
在 MANA 之前的版本中,视觉数据和激光雷达数据是分别处理的,融合过程在各自输出结果的层面上完成,也就是自动驾驶领域常说的 「后融合」。
这样做可以尽可能地保证两个系统之间的独立性,并为彼此提供安全冗余。但后融合也导致神经网络无法充分利用两个异构传感器之间数据的互补性,来学习最有价值的特征。
融合感知模块
前面提到了一个三位一体融合的概念,这也是 MANA 感知系统区别于其他感知系统的关键之处。正如毫末智行 CEO 顾维灏在 AI Day 上所说:目前大部分的感知系统都存在「时间上的感知不连续、空间上的感知碎片化」的问题。
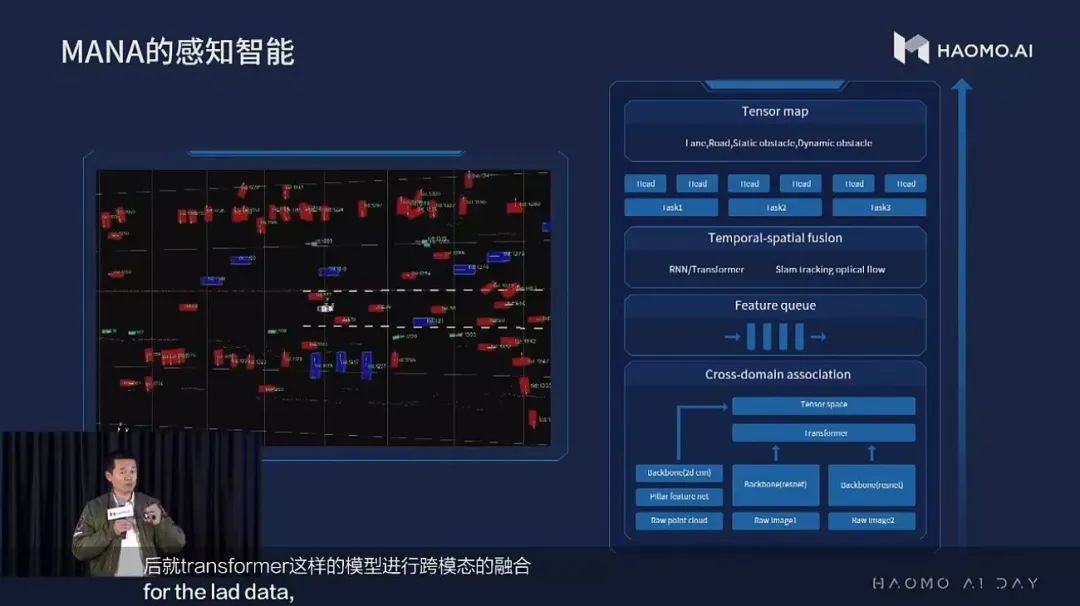
MANA 系统的融合感知模块
时间上的不连续:是由于系统按照帧为单位进行处理,而两帧之间的时间间隔可能会有几十毫秒,系统更多地关注单帧的处理结果,将时间上的融合作为后处理的步骤。
比如,采用单独的物体跟踪模块将单帧的物体检测结果串联起来,这也是一种后融合策略,因此无法充分利用时序上的有用信息。
空间上的碎片化:是由多个同构或异构传感器所在的不同空间坐标系导致的。
对于同构传感器(比如多个摄像头)来说,由于安装位置和角度不同,导致其可视范围(FOV)也不尽相同。每个传感器的 FOV 都是有限的,需要把多个传感器的数据融合在一起,才可以得到车身周围 360 度的感知能力,这对于 L2 以上级别的自动驾驶系统来说是非常重要的。
对于异构传感器(比如摄像头和激光雷达)来说,由于数据采集的方式不同,不同传感器得到的数据信息和形式都有很大差别。
摄像头采集到的是图像数据,具有丰富的纹理和语义信息,适合用于物体分类和场景理解;而激光雷达采集到的是点云数据,其空间位置信息非常精确,适合用于感知物体的三维信息和检测障碍物。
如果系统对每个传感器进行单独处理,并在处理结果上进行后融合,那么就无法利用多个传感器的数据中包含的互补信息。
如何解决这两个问题呢?
答案是:用 Transformer 做空间和时间上的前融合。
先说空间的前融合
与 Transformer 在一般的视觉任务(比如图像分类和物体检测)中扮演的角色不同,Transformer 在空间前融合中的主要作用并不是提取特征,而是进行坐标系的变换。
这与特斯拉所采用的技术有异曲同工之处,但是毫末进一步增加了激光雷达,进行多传感器(跨模态)的前融合,也就是图 8 中的 Cross-Domain Association 模块。
上面介绍了 Transformer 的基本工作原理,简单来说就是 「计算输入数据各个元素之间的相关性,利用该相关性进行特征提取」。
坐标系转换也可以形式化为类似的流程。
比如,将来自多个摄像头的图像转换到与激光雷达点云一致的三维空间坐标系,那么系统需要做的是找到三维坐标系中每个点与图像像素的对应关系。传统的基于几何变换的方法会将三维坐标系中的一个点映射到图像坐标系中的一个点,并利用该图像点周围一个小的邻域(比如 3x3 像素)来计算三维点的像素值。
而 Transformer 则会建立三维点到每个图像点的联系,并通过自注意力机制,也就是相关性计算来决定哪些图像点会被用来进行三维点的像素值。
如图 9 所示,Transformer 首先编码图像特征,然后将其解码到三维空间,而坐标系变换已经被嵌入到了自注意力的计算过程中。
这种思路打破的传统方法中对邻域的约束,算法可以看到场景中更大的范围,通过对场景的理解来进行坐标变换。同时,坐标变换的过程在神经网络中进行,可以由后端所接的具体任务来自动调整变换的参数。
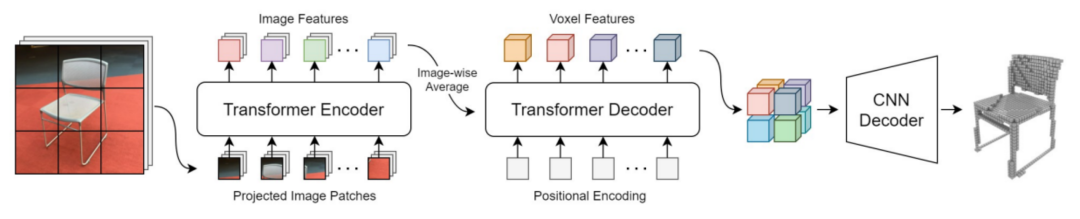
采用 Transformer 进行图像坐标系到三维空间坐标系的转换
因此,这个变换过程是完全由数据驱动的,也是任务相关的。在拥有超大数据集的前提下,基于 Transformer 来进行空间坐标系变换是完全可行的。
再说时间上的前融合
这个比空间上的前融合更容易理解一些,因为 Transformer 在设计之初就是为了处理时序数据的。
图 8 中的 Feature Queue 就是空间融合模块在时序上的输出,可以理解为一个句子中的多个单词,这样就可以自然的采用 Transformer 来提取时序特征。相比特斯拉采用 RNN 来进行时序融合的方案,Transformer 的方案特征提取能力更强,但是在运行效率上会低一些。
毫末的方案中也提到了 RNN,相信目前也在进行两种方案的对比,甚至是进行某种程度的结合,以充分利用两者的优势。
除此之外,由于激光雷达的加持,毫末采用了 SLAM 跟踪以及光流算法,可以快速的完成自身定位和场景感知,更好的保证时序上的连贯性。
认知模块
除了感知模块以外,毫末在认知模块,也就是路径规划部分也有一些特别的设计。
顾维灏在 AI Day 上介绍到,认知模块与感知模块最大的不同在于,认知模块没有确定的「尺子」来衡量其性能的优劣,而且认知模块需要考虑的因素比较多,比如安全,舒适和高效,这无疑也增加了认知模块设计的难度。
针对这些问题,毫末的解决方案是场景数字化和大规模强化学习。
场景数字化,就是将行驶道路上的不同场景进行参数化的表示。参数化的好处在于可以对场景进行有效地分类,从而进行差异化的处理。
按照不同的粒度,场景参数分为宏观和微观两种:宏观的场景参数包括天气,光照,路况等;微观的场景参数则刻画了自车的行驶速度,与周围障碍物的关系等。
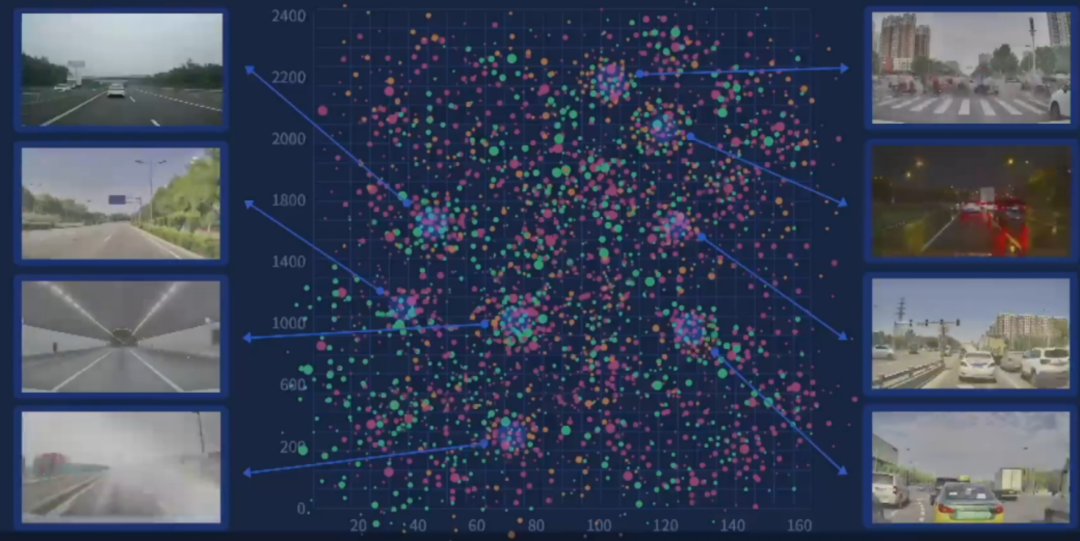
MANA 系统中的宏观场景聚类
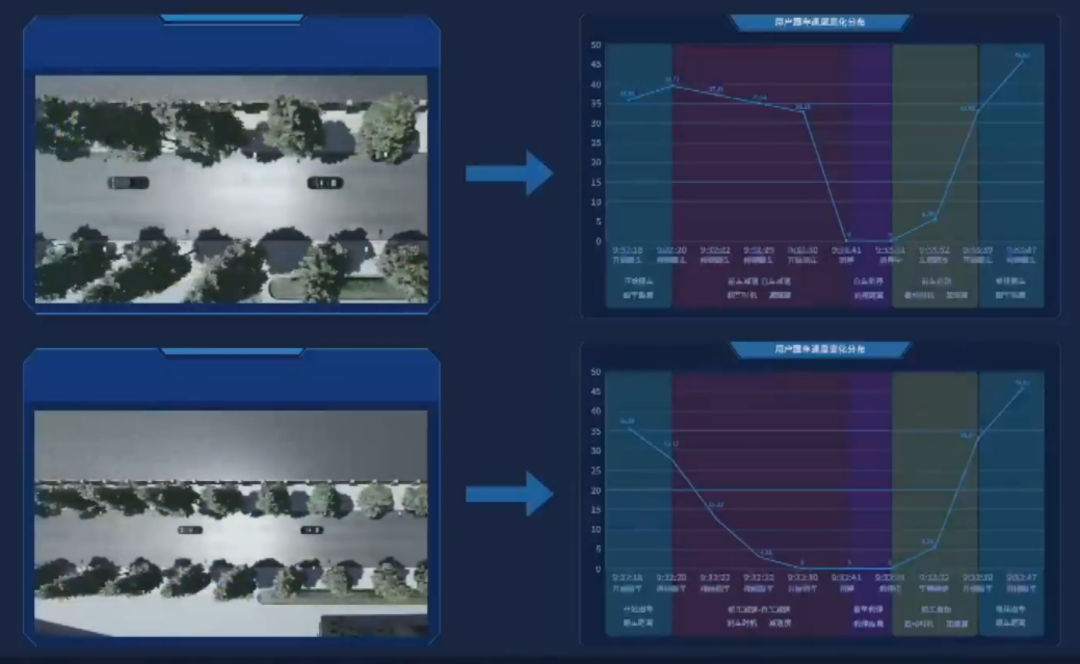
MANA 系统中的微观场景(例子是跟车场景)
在将各种场景数字化了以后,就可以采用人工智能的算法来进行学习。一般情况下,强化学习是完成这个任务的一个比较好的选择。
强化学习就是著名的 AlphaGo 中采用的方法,但是与围棋不同,自动驾驶任务的评价标准不是输和赢,而是驾驶的合理性和安全性。
如何对每一次的驾驶行为进行正确地评价,是认知系统中强化学习算法设计的关键。毫末采取的策略是模拟人类司机的行为,这也是最快速有效的方法。
当然,只有几个司机的数据是远远不够的,采用这种策略的基础也是海量的人工驾驶数据,而这恰恰又是毫末的优势所在,这就是基于长城汽车,毫末在智能驾驶系统上的交付能力会远远领先其他对手,而这背后的核心则是数据的收集能力,基于海量的数据,毫末可以快速迭代算法交付覆盖更多场景的自动驾驶系统。
写在最后
随着自动驾驶技术的快速发展和落地,越来越多的量产车型上开始搭载支持不同级别自动驾驶系统的软件和硬件。在逐渐向商业化迈进的同时,量产车型的规模效应也可以为自动驾驶系统的迭代提供海量的数据支持。这也是业界普遍认可的通向高阶自动驾驶的必经之路。
在这种背景下,拥有潜在数据优势的量产车的企业该如何切入,特斯拉和依托长城汽车的毫末智行率先给出了方案。两者的方案既有宏观的神似之处,也有很多具体策略上的差异,既体现了共识,也展现了个性。
共识之处在于,两家公司都采用了 Transformer 神经网络结构来提升在超大数据集上的学习能力,同时两家公司也都认为数据的采集和自动标注是整个算法迭代的重要环节,并为此进行了巨大的投入。
个性方面,特斯拉采用纯视觉的方案,而毫末采用视觉加激光雷达的方案。在激光雷达量产成本不断降低的背景下,毫末的方案是具有发展潜力的。此外,毫末在 Transformer 的应用上更加深入。
除了融合空间信息以外,Transformer 在 MANA 系统中还被用来融合时序和多模态信息,将系统采集的各种离散数据统一起来,形成连贯的数据流,以更好地支持后端的不同应用。
不管采用何种实现方案,特斯拉和毫末智行在海量数据上进行的尝试对于自动驾驶技术的发展和最终落地实现都是意义重大的。
也希望未来会有更多的企业加入进来,尝试更多不同的可能性,互通有无,互相学习,甚至共享技术和数据,让自动驾驶能够更好更快地为大众服务。
- 下一篇:电动汽车热泵空调系统
- 上一篇:张工聊测量 | 电池可拆卸性的测试与分析



编辑推荐




最新资讯
-
大卓智能端到端直播实测,16公里复杂路段挑
2025-04-25 17:16
-
《汽车轮胎耐撞击性能试验方法-车辆法》等
2025-04-25 11:45
-
“真实”而精确的能量流测试:电动汽车能效
2025-04-25 11:44
-
GRAS助力中国高校科研升级
2025-04-25 10:25
-
梅赛德斯-AMG使用VI-CarRealTime开发其控制
2025-04-25 10:21
