




 广告
广告





















































紧耦合激光雷达-视觉-惯性里程计统一的多模型地标跟踪

编者按:在定位导航与实时建图问题中,多源信息的融合是目前流行的解决方案,即综合不同传感器的信息进行处理,并得到融合定位结果,常用有全球卫星导航系统、惯性里程计、激光雷达、摄像头等。而因子图(Factor Graph)优化是近年来使用频繁的后端优化方法。因子图是种用于描述事物关系的有效模型,基于该模型的优化方法能够从全局的定位结果进行优化。本篇文章基于激光雷达、视觉信息以及惯性里程计,运用因子图进行信息融合,实现高效精准的SLAM算法,同时提出“点、线、面”等不同的地标追踪因子,提升SLAM算法的精度,具有极高的现代性与前瞻性。
本文译自:
《Unified Multi-Modal Landmark Tracking for Tightly Coupled Lidar-Visual-Inertial Odometry》
文章来源:
IEEE Robotics and Automation Letters, 2021, 6(2): 1004-1011.
作者:
David Wisth,Marco Camurri,Sandipan Das,Maurice Fallon
原文链接:
https://ieeexplore.ieee.org/abstract/document/9345356
摘要:我们提出了一个有效的多传感器里程测量系统的移动平台,联合优化视觉,激光雷达和惯性信息在一个单一的综合因子图。这将使用固定的延迟平滑以全帧率实时运行。为了实现这种紧密集成,提出了一种从激光雷达点云中提取三维线段、平面基元的新方法。该方法克服了典型的帧对帧跟踪方法的缺点,将基元视为地标并通过多次扫描跟踪它们。通过对激光雷达和相机帧进行微妙的被动同步,实现了激光雷达特征与标准视觉特征和IMU的真正集成。3D功能的轻量级形式允许在单个CPU上实时执行。我们提出的系统已经在多种平台和场景中进行了测试,包括使用有腿机器人进行地下勘探和使用动态移动手持设备进行户外扫描,总持续时间为96分钟,行走距离为2.4公里。在这些测试序列中,仅使用一个外部传感器就会导致失败,原因要么是几何约束不足(影响激光雷达),要么是过度光照变化导致的无纹理区域(影响视觉)。在这些条件下,我们的因子图自然地使用了从每个传感器模态获得的最佳信息,而没有任何外部干预与硬性条件判断。
关键词:传感器融合,视觉惯性SLAM,定位
1 引言
多源传感器融合是自动导航系统在现实场景中成功部署的关键能力。可能的应用范围很广,从自主地下探测到室外动态测绘(见图1)。激光雷达硬件的最新进展促进了激光雷达-惯性导航融合[1]-[4]的研究。激光雷达传感器广泛的视场、密度、范围和精度使得它们适合于导航、定位和测绘任务。
然而,在复杂的环境中,如长隧道或开阔空间,光雷达方法可能会失败。由于单独的IMU积分递推不能提供超过几秒钟的可靠姿态估计,系统故障通常是不可恢复的。为了应付这些情况,还需要与更多的传感器,特别是照相机进行融合。虽然过去已经通过松耦合方法[5]实现了视觉-惯性-激光雷达的融合,但像增量平滑这样的紧耦合方法由于其优越的鲁棒性而更受欢迎。
在平滑方法方面,视觉惯性导航系统(VINS)的研究已经成熟,激光惯性导航系统的研究也越来越普遍。然而,三种传感器模式的紧密融合仍然是一个有待解决的研究问题。
A. 出发点
IMU、激光雷达和相机传感融合的两个主要挑战是: 1)在移动平台有限的计算预算下实现实时性; 2)在不同频率和采集方法下实现三种信号的适当同步。
先前的工作通过采用松散耦合的方法[5],[8],[9]或运行两个独立的系统(一个用于激光雷达惯性,另一个用于视觉惯性测程)[10]来解决这两个问题。
相反,我们通过以下方法来解决这些问题:1)提取和跟踪稀疏轻量级基元,2)开发一个相干因子图,利用IMU预积分来动态地将去变形的点云转换为附近摄像机帧的时间戳。前者避免匹配整个点云(如ICP)或跟踪数百个特征点(如LOAM[1])。后者使所有传感器的实时平滑成为可能。
B. 贡献
本篇论文的主要贡献如下:
-
一种新的因子图公式,紧密融合视觉,激光雷达和IMU测量在一个单一的一致的优化过程;
-
一种有效的提取激光雷达特征的方法,然后优化为地标。激光雷达和视觉特征共享一个统一的表示,因为所有的地标都被处理为三维参数流形(即点、线、面)。这种紧凑的表现方式允许我们以名义帧率处理所有的激光雷达扫描;
-
在一系列场景中进行的广泛实验评估表明,与在单个传感器模式失败时困难的更典型的方法相比,该方法具有更好的鲁棒性。
我们的工作建立在我们之前的工作[11],[12]中引入的VILENS估计系统的基础上,增加了激光雷达特征跟踪和激光雷达辅助视觉跟踪。摄像头和激光雷达的结合使便携式设备即使在快速移动时也能使用,因为它可以自然地处理场景中的退化(由于缺乏激光雷达或视觉特征)。

图1:我们使用DARPA SubT挑战赛中的ANYmal四足机器人[6](上图,由苏黎世联邦理工学院提供)和一个位于牛津新学院的手持绘图设备[7](下图)的数据测试了我们的多传感器里程表算法。
2 相关工作
先前的多模态传感器融合工作使用了激光雷达、相机和IMU传感的组合,可以被描述为松散或紧密耦合,如表I所示。松散耦合系统分别处理来自每个传感器的测量数据,并将其融合到一个滤波器中。在那里他们被边缘化以得到当前的状态估计。另外,紧密耦合系统可以联合优化过去和当前的测量数据,以获得完整的轨迹估计。
另一个重要的区别是里程计系统和SLAM系统之间的区别。在后者中,执行回环检测以在访问同一地点两次后保持估计的全局一致性。尽管表格中的一些工作也包括姿态图SLAM后端,但我们在这里主要对高频里程计感兴趣。
A. 松耦合激光雷达-惯性里程计
基于激光雷达的里程测量技术得到了广泛的应用,这要归功于Zhang等人[1]提出的LOAM算法。他们的关键贡献之一是定义边界和平面三维特征点,跟踪帧到帧。两帧之间的运动是线性插值使用IMU运行在高频。该运动先验用于特征的精细匹配和配准,以实现高精度的测程。Shan等人[2]提出了LeGO-LOAM,通过优化地面平面的估计,进一步提高了地面车辆LOAM的实时性。然而,这些算法在无结构环境或退化场景[20](由于激光雷达的范围和分辨率有限,如长高速公路、隧道和开放空间,无法找到约束条件)中将难以稳定运行。
B. 松耦合视觉-惯性-激光雷达里程计
在最近的许多工作中,[5],[8],[9],[15]视觉与激光雷达和IMU以一种松散耦合的方式结合,用于里程估计,以提供互补的传感器模态,既避免退化,又在激光雷达-惯性系统上获得更平滑的估计轨迹。
LOAM的作者扩展了他们的算法,将V -LOAM[8]中的单目摄像机的特征跟踪与IMU相结合,从而为激光雷达扫描匹配生成视觉惯性测程先验。然而,操作仍然是逐帧执行,并没有保持全局一致性。为了提高一致性,Wang等人引入了视觉-惯性-激光雷达SLAM系统。[9]使用基于V-LOAM的方法进行里程估计,并通过维护关键帧数据库实现全局位姿图优化。Khattak等人[15]提出了另一种类似于V-LOAM的松散耦合方法,利用视觉/热红外惯性先验进行激光雷达扫描匹配。为了克服简并,作者使用视觉和热红外惯性里程计,以便在没有照明的长隧道中操作。在Pronto[5]中,作者使用视觉-惯性腿里程计作为激光雷达里程计系统的运动先验,并将视觉和激光雷达里程计的姿态修正集成在一起,以一种松散耦合的方式纠正姿态漂移。
C. 紧耦合惯性雷达里程计
早期的激光雷达和IMU紧密融合方法之一是在LIPS[3]中提出的,这是一种基于图的优化框架,它优化了由最近点到平面表示和预集成IMU测量得到的三维平面因子。Y等人[4]以类似的方式提出了LIOM,一种联合最小化激光雷达特征损失方程和预积分IMU测量的方法,在快速移动的情况下,这导致了比LOAM更好的里程表估计。Shan等人提出了LIO-SAM, LIO-SAM通过引入局部尺度而不是全局尺度的扫描匹配来适应LOAM框架。这允许新的关键帧被注册到先前“子关键帧”的滑动窗口合并成一个体素贴图。该系统在手持设备、地面和漂浮车辆上进行了广泛的测试,突出了SLAM系统重建的质量。对于长时间航行,他们还使用了闭环因子和GPS因子来消除漂移。
但是,由于缺乏视觉,上述算法可能难以在退化场景下稳健执行。
D. 紧耦合视觉雷达里程计
为了避免退化和使系统更鲁棒,多模态传感能力(视觉、激光雷达和IMU)的紧密集成在最近的一些工作[10],[16]-[19]中进行了探索。在LIMO[16]中,作者提出了一种基于束调整的视觉里程表系统。他们通过将激光雷达测量的深度重新投射到图像空间,并将其与视觉特征联系起来,从而帮助保持精确的尺度。Shao等人引入了VIL-SLAM,他们将VIO和基于激光雷达的里程表作为单独的子系统来组合不同的传感器模式,而不是进行联合优化。
为了进行联合状态优化,许多方法[17]-[19]使用了多状态约束卡尔曼滤波(MSCKF)框架[21]。[17]将3.5m范围内RGB-D传感器的平面特征与使用MSCKF的视觉和IMU测量的点特征紧密结合。为了限制状态向量的大小,大部分点特征被视为MSCKF特征并被线性边缘化,而只有少数强制平面点约束的点特征被保留在状态向量中作为SLAM特征。Zuo等人提出的LIC-Fusion[18]将IMU测量数据紧密结合,利用MSCKF融合框架提取激光雷达边缘特征,以及稀疏的视觉特征。然而,在最近的一项后续工作LIC-Fusion 2.0[19]中,作者引入了一种基于滑动窗口的平面特征跟踪方法,用于高效处理三维激光雷达点云。
与之前的工作相比,我们在一个单一的、一致的因子图优化框架中联合优化了上述三种传感器模式。为了实时处理激光雷达数据,我们直接从激光雷达点云中提取并跟踪线、面等三维基元,而不是执行“点对面”或“点对线”的成本函数。这允许以类似于视觉跟踪的方式在多帧上进行自然跟踪,并在退化场景中限制运动。
3 问题描述
我们的目标是估计一个移动平台(在我们的实验中,一个腿式机器人或一个手持传感器负载)的位置、方向和线速度,该平台装备有IMU、激光雷达和一个具有低延迟和全传感器率的单目或立体声摄像机。
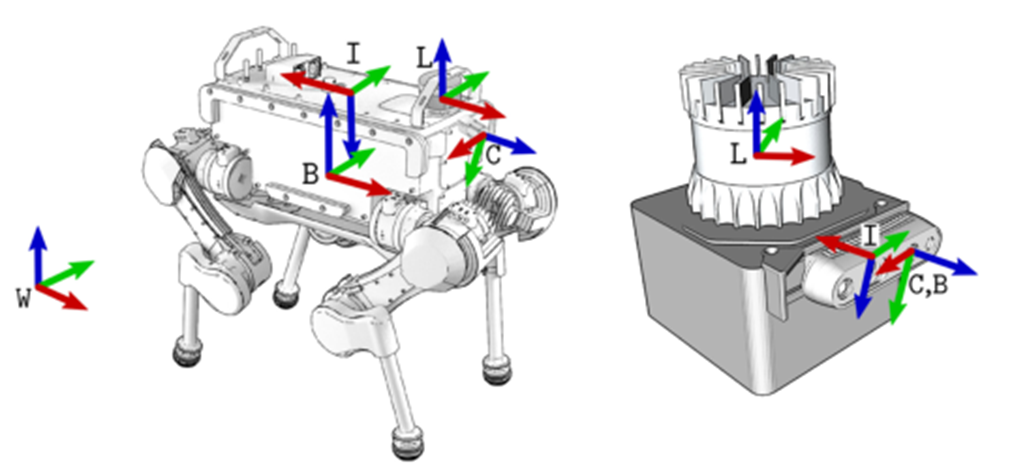
图2:ANYmal平台和手持设备的参考框架约定。世界坐标系W为固定架,底座坐标系B、光学相机坐标系C、IMU坐标系、I、激光雷达坐标系L分别安装在移动机器人的底盘或设备上。为简单起见,C和B在手持设备上是一致的。
相关的参考坐标系在图2中指定,并且包括机器人固定的基准坐标系B、左摄像机坐标系C、IMU坐标系I和激光雷达坐标系L。我们希望估计相对于固定的世界坐标系W的基准帧的位置。
除非另有说明,否则基础的位置wPWB方向RWB (以

为对应的齐次变换)以世界坐标表示;速度
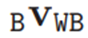
、
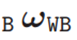
以基础坐标系表示,IMU偏移bg和ba以IMU坐标系表示。
A. 状态量定义
在时间
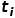
的移动平台状态定义如下:
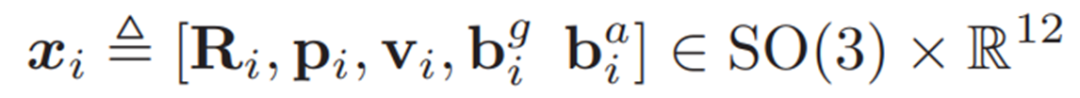
其中:Ri是方位,pi是位置,vi是线速度,最后两个元素是通常的IMU陀螺仪和加速度计偏差。
除了状态之外,我们还关注了三个n维流形的参数:点、线和面。点地标ml是视觉特征,而直线ll和平面pl地标是从激光雷达中提取的。我们估计的目标是截至当前时间i的所有可见状态和地标:
其中Xk,Mk,Pk,Lk是在固定滞后平滑窗口内跟踪的所有状态和地标的列表。
B. 测量定义
来自单目或立体摄像机C、IMU I、和激光雷达L的测量在不同的时间和频率被接收。我们将zk定义为在平滑窗口内接收的全套测量值。第V-B1节解释了如何将测量结果集成到因子图中,以便在固定频率下执行优化。
C. 最大后验估计
我们根据给定的历史状态Xk中最大化测量Zk的可能性:
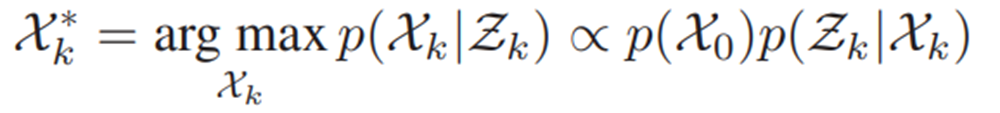
这些测量值被表示为有条件地独立并且受到高斯白噪声的影响。因此,公式(3)可以表示为以下最小二乘最小化问题[22]:
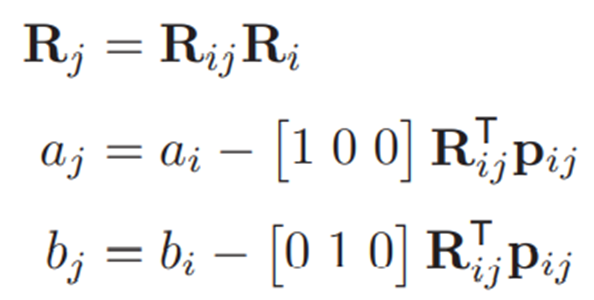
其中Iij是ti和tj之间的IMU测量值,并且Kk是tk之前的所有关键帧索引。每一项都是与一种因子类型相关的残差,由其协方差矩阵的倒数加权。残差包括:IMU、激光雷达平面和线特征、视觉地标和先验状态。
4 因子图公式
现在我们描述图中各因子的测量值、残差和协方差,如图3所示。为方便起见,我们在第IV-A节中总结了IMU因子;然后,我们在第IV-B和IV-C节中介绍了视觉-激光雷达地标因子,而第IV-D节描述了我们新的平面和线状地标因子。
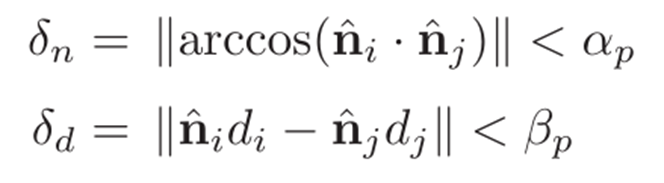
图3:VILENS滑动窗口因子图结构,显示先验的、视觉的、平面的、线的和预集成的IMU因子。随着时间的推移跟踪地标,通过允许新的测量来提高过去状态的准确性,从而提高了估计的准确性。
A. IMU预积分因子
我们遵循现在标准的IMU测量预积分方式[23]来约束图中两个连续节点之间的姿态、速度和偏差,并在节点之间提供高频状态更新。残差的形式为:
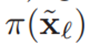
有关残差的定义,请参见[23]。
B. 使用激光雷达深度的单目地标因子
为了充分利用视觉和激光雷达传感模式的融合,我们跟踪单目视觉特征,但使用激光雷达的重叠视场来提供深度估计,如[16]所示。为了匹配分别工作在10 Hz和30 Hz的激光雷达和相机的测量结果,我们使用了第V-B1节中描述的方法。
设
是欧氏空间中的一个视觉地标,
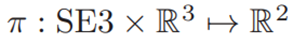
函数在给定平台姿态Ti的情况下将一个地标投影到图像平面上(为简单起见,我们省略了底座、激光雷达和照相机之间的固定变换),以及
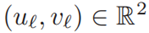
在图像平面上检测ml (图4中的黄点,右)。我们首先用
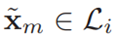
将激光雷达在时间ti和ti+1之间获取的所有点
(图4中的绿点,右图中的绿点)投影到像平面上。然后,我们求出投影点
。最接近(ul,vl)。在3个像素的邻域内的图像平面上。最后,残差计算为:

当我们无法将激光雷达深度与视觉特征相关联时(由于激光雷达和相机传感器的分辨率不同),或者如果它不稳定(即,当帧之间的深度由于动态障碍物或噪声而变化大于0.5m时),我们将恢复到立体匹配,如下一节所述。
C. 立体地标因子
地标ml在状态xi的残差为[12]:
其中(uL,v),(uR,v)是检测到的地标的像素位置,并且根据0.5像素的不确定性计算Σm最后,如果只有单目摄像机可用,则只使用公式7中的第一个和最后一个元素。
D. 平面地标因子
我们使用黑森范式将无限平面
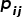
参数化为单位法线
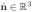
和表示其到原点的距离的标量d:
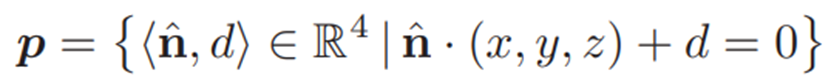
设⊗是对平面p上的所有点应用齐次变换T的算子,并且⊖将两个平面(pi,pj)之间的误差定义为:
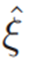
其中
是
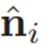
的切线空间的基,
定义如下[24]:
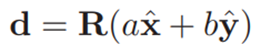
当平面
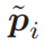
在时间ti测量时,相应的残差是p与转换到局部参考帧的估计平面pl之间的差:
E. 线地标因子
使用文[25]中的方法,无限直线可以由旋转矩阵R∈SO3和两个标量a,b∈R参数化,使得
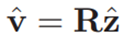
是直线的方向,
是直线和原点之间的最近点。因此,行l可以定义为:
⊠是一种运算符,代表了一种变换Tij=(Rij,pij)应用于某条线li上所有点到某条线上lj,例如:
在两条线li,lj之间的运算符被定义为
给定上面两式,一根被测量的线li和它的预测之间的残差如下所示:
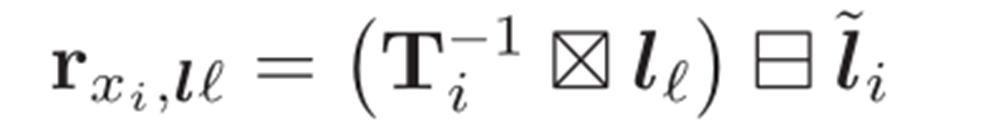
我们使用方程的数值导数。(11)和(15)在优化中,使用对称差分法。
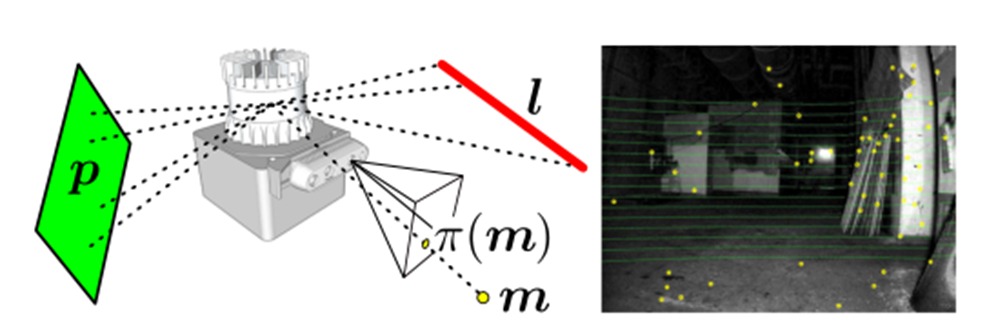
图4:左:视觉FAST特征m(黄色);激光雷达线l:(红色)和平面基元(绿色)由我们的方法跟踪。右图:激光雷达数据(绿色)和视觉特征(黄色)投射到图像框架中,有助于将深度与视觉特征关联起来。
5 系统运行
系统架构如图5所示。使用四个并行线程进行传感器处理和优化,系统以相机关键帧频率(通常为15Hz)输出因子图估计的状态,并以IMU频率(通常为100Hz)输出IMU转发传播状态,分别用于导航/映射和控制。
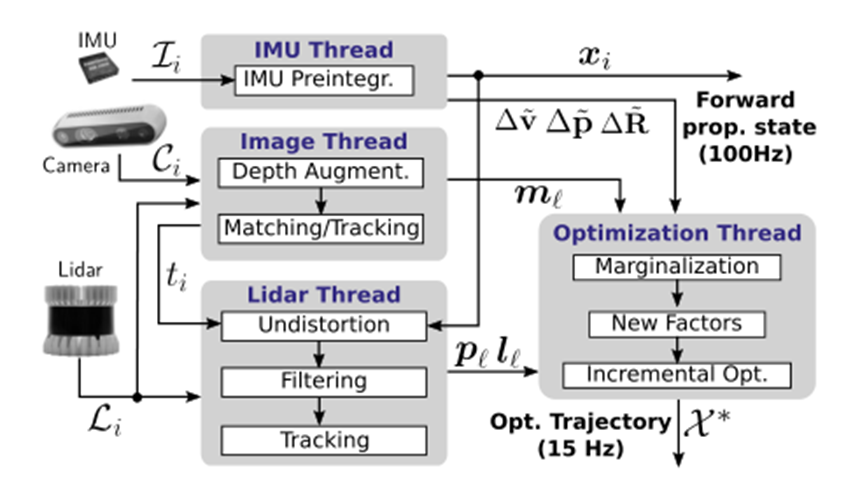
图5:VILENS系统架构概述。输入由每个前端测量处理程序在单独的线程中处理。后端既产生高频前向传播输出,又产生低频优化输出。这种并行体系结构允许根据平台的不同进行不同的测量输入。
使用GTSAM库[22],使用基于高效增量优化解算器ISAM2的固定滞后平滑框架来求解因子图。对于这些实验,我们使用5到10秒的滞后时间。使用动态协方差缩放(DCS)[26]稳健的成本函数将所有视觉和激光雷达因子添加到图表中,以减少离群值的影响。
A. 视觉特征追踪
我们使用快速角点检测器检测特征,并使用KLT特征跟踪器跟踪连续帧之间的特征,并使用RANSAC拒绝离群值。由于并行架构和增量优化,每隔一帧用作关键帧,实现15Hz额定输出。
B. 激光雷达处理和特征跟踪
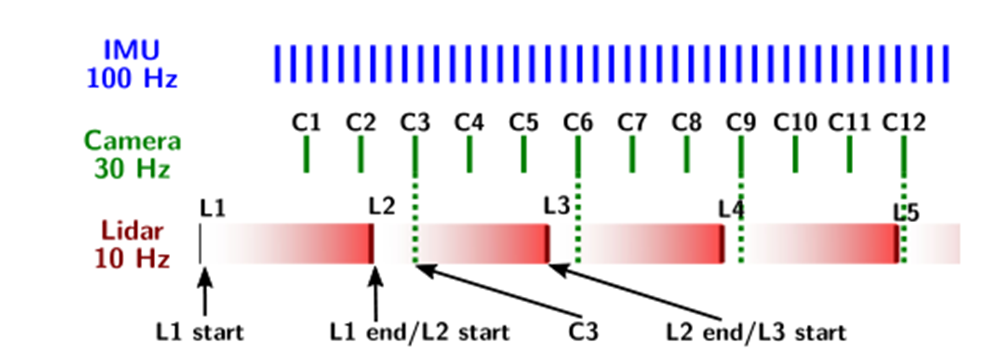
该算法的一个关键特点是从与摄像机帧同时表示的激光雷达点云中提取特征基元,从而可以一次对所有传感器执行优化。处理流水线包括以下步骤:点云去失真与同步、滤波、基元提取与跟踪、因子生成。
1)不失真和同步:图6比较了我们传感器的不同输出频率。当IMU和相机样本被即时捕获时,激光雷达在其内部绕着z轴旋转的同时不断地捕获点。一旦完全旋转完成,累积的激光回波就会转换成点云,然后立即开始新的扫描。
由于激光回波是在移动时捕获的,因此点云需要在唯一的任意时间戳(通常是扫描开始[27])之前的运动中保持不失真。这种方法意味着相机和激光雷达的测量具有不同的时间戳,从而分离出不同的图形节点。
图6:IMU、相机和激光雷达之间输出频率和同步的示例。IMU和相机信号被瞬间捕获,而激光雷达点被捕获并积累0.1s,然后作为扫描发送。当接收到扫描L2时,它与相机帧C3保持一致,并与相机添加到相同的图节点中。
取而代之的是,我们选择在扫描开始后将激光雷达测量结果不失真到最接近的相机时间戳。例如,在图6中,扫描L2未失真到关键帧C3的时间戳。给定来自IMU模块的前向传播状态,使用与云的每个点相关联的时间戳来线性外推运动先验(为简单起见,我们避免了高斯过程内插[28]或具有时间偏移量的状态扩充[29])。由于云现在与C3相关联,因此激光雷达地标连接到与C3相同的节点,而不是创建新节点。
这一微妙的细节不仅保证了图形优化中添加了一致数量的新节点和因子,而且还确保了IMU、相机和激光雷达输入之间的优化是联合进行的。这也确保了固定的输出频率,即相机帧率或激光雷达帧率(当相机不可用时),但不是两者的混合。
2)过滤:一旦点云没有失真,我们从[30]开始进行分割,将点分成簇。较小的群集(小于5点)被标记为异常值并被丢弃,因为它们可能会有噪声。
然后,利用文献[2]的方法计算预滤波云中每个点的局部曲率。具有最低曲率和最高曲率的点分别被分配给平面候选集合Cp和线候选集合CL。
分割和基于曲率的过滤通常将点云中的点数减少90%,从而在后续的平面和线处理中提供显著的计算节省。
3)平面和直线的提取和跟踪:随着时间的推移,我们跟踪各个候选集合Cp和CL中的平面和直线。这是以类似于局部视觉特征跟踪方法的方式来完成的,其中特征在其预测位置的局部附近被跟踪。
首先,我们从上一次扫描中获取被跟踪的平面和线,pi-1和li-1,并使用IMU递推来预测它们在当前扫描中的位置,预测值pi和li。然后,为了辅助局部跟踪,我们使用最大点到模型距离来分割预测的特征位置周围的Cp和CL。然后,我们进行欧几里德聚类(对平面特征进行法向滤波)来去除离群点。然后,我们使用PROSAC[31]鲁棒拟合算法将模型拟合到分割的点云。
最后,我们检查预测的地标和检测到的地标是否足够相似。当两个平面(
和
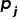
)的法线和到原点的距离之差小于阈值时,它们被认为是匹配的:
如果两条直线的方向和中心距离小于阈值,则认为它们匹配:
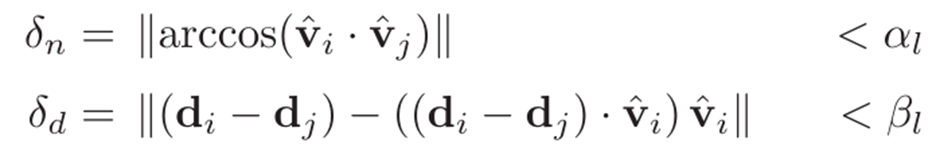
在我们使用中,αp=αl=0.35rad, βp=βl=0.5m
跟踪要素后,将从相应的候选集合中删除该要素的内嵌对象,并对剩余的地标重复此过程。
跟踪完成后,我们在剩余的候选云中检测到新的地标。首先对线使用欧几里德聚类,对平面使用基于法线的区域生长来划分点云。然后,我们使用与地标跟踪相同的方法在每个集群中检测新的地标。
只有在连续扫描次数最少的情况下对点云要素进行跟踪后,才会将其包括在优化中。请注意,首先跟踪最旧的要素,以确保尽可能长的要素轨迹。
C. 零速更新因子
为了限制平台静止时的漂移和因子图增长,当三个模态中的两个(相机、激光雷达、IMU)的更新报告没有运动时,我们向图形添加零速度约束。
6 试验结果
我们在两个对比鲜明的数据集中对我们的算法在各种室内和室外环境中进行了评估:较新的大学数据集[7]和DARPA SubT挑战赛(城市)。这些环境的概述如图7所示。
A. 数据集
较新的学院数据集(NC)[7]是使用配备了OS1-64 Gen1激光雷达传感器、RealSense D435i立体红外摄像机和Intel NUC PC的便携式设备收集的。嵌入在激光雷达中的手机级IMU用于惯性测量。这个装置是由一个在户外行走的人携带的,周围有建筑物、大片空地和茂密的树叶。数据集包括具有挑战性的序列,在这些序列中,设备被猛烈摇晃以测试跟踪的极限。
SubT数据集(ST)包括SubT竞赛的两个最重要的运行(Alpha-2和Beta-2),收集自配备了Flir BFS-U3-16S2C-CS单目摄像头和工业级Xsens MTI-100 IMU的ANYmal B300四足机器人[6],这两个数据通过专用电路板进行硬件同步[32]。Velodyne VLP-16也是可用的,但通过软件进行同步。机器人在一座未完工的核反应堆的地下内部导航。由于存在长而直的走廊和极其黑暗的环境,这一数据集具有挑战性。请注意,此工作中未使用机器人的腿部运动学。
具体实验命名如下:
NC-1:在开放的大学环境中漫步(1134米,17分钟)。
NC-2:在强光照度变化(480m,6分钟)下以高动态运动行走。
NC-3:以极高的角速度摇晃传感器装置,最高可达3.37弧度/秒(91米,2分钟)。
ST-A:四足动物机器人在黑暗的地下反应堆设施中小跑(167米,11分钟)。
ST-B:一个不同的动物机器人,在反应堆的一部分,包含一条长而直的走廊(490米,60分钟)。
为了生成地面真相,ICP被用来将当前的激光雷达扫描与使用商业激光测绘系统收集的详细先前地图对准。有关地面真相生成的深入讨论,读者请参阅[7]。
B. 结果
表II总结了以下算法在10米距离上的平均相对位姿误差(RPE):
VILENS-LI:仅带IMU和激光雷达的VILENS;
VILENS-LVI:具有IMU、视觉(具有激光雷达深度)和激光雷达特征的VILENS;
LOAM:在SubT比赛中使用的LOAM[1]映射模块的输出。
LeGO-LOAM:LeGO-LOAM [2]建图模块的输出。
应该注意的是,没有执行任何回环,并且与LOAM和LeGO-LOAM方法相比,我们不执行任何建图。
对于SubT数据集,VILENS-LVI的平移/旋转性能平均比LOAM高38%/21%,VILENS-LI的平移/旋转性能比VILENS-LI高46%/21%。图8显示了全局性能的一个例子,它描述了ST-A数据集上的估计和地面真实轨迹。VILENS-L VI能够实现非常慢的漂移率,即使没有测绘系统或环路关闭。
对于最不动态的NC数据集NC-1,VILENS-L VI实现了与LeGO-LOAM相当的性能。然而,对于更动态的数据集(高达3.37rad/s),NC-2和NC-3,VILENS方法的性能明显优于LeGO-LOAM。这一性能的关键是激光雷达云到相机时间戳的不失真,允许精确的视觉特征与激光雷达的深度,同时最大限度地减少计算量。
总体而言,性能最好的算法是VILENS-LVI,显示了视觉和激光雷达功能的紧密集成如何使我们能够避免在纯激光雷达惯性方法中可能出现的故障模式。
C. 多传感器融合
互补传感器模式的紧密融合带来的一个关键好处是对传感器退化具有自然的鲁棒性。虽然很大比例的数据为激光雷达和视觉特征跟踪提供了有利条件,但在许多情况下,紧密融合增强了对单个传感器故障模式的鲁棒性。
图9显示了NC-2的一个例子,当走出明亮的阳光进入阴影时,相机的自动曝光功能需要大约3秒的时间来调整。在此期间,视觉特征的数量从大约30个下降到不到5个(都聚集在图像的一个角落)。这将导致估计器不稳定。通过激光雷达的紧密融合,我们可以使用少量的视觉特征和激光雷达特征,而不会造成任何性能退化。这与[5]、[15]等方法相反,[5]、[15]等方法使用单独的视觉-惯性子系统和激光雷达-惯性子系统意味着必须显式地处理退化情况。
类似地,在激光雷达地标不足以完全约束估计(或接近退化)的情况下,视觉特征的紧密融合允许优化利用激光雷达约束,同时避免退化问题。
D. 分析
在优化中使用轻量级点云原语的一个关键好处是提高了效率。上述数据集的平均计算时间是用于视觉特征跟踪的约10ms,用于点云特征跟踪的约50ms,以及用于消费级笔记本电脑上的优化的约20ms。这使得系统能够在仅使用雷达-惯性测量时以10hz(激光雷达帧率)输出,在融合视觉、激光雷达和惯性测量时以15hz(相机关键帧率)输出。
参考文献







编辑推荐




最新资讯
-
大卓智能端到端直播实测,16公里复杂路段挑
2025-04-25 17:16
-
《汽车轮胎耐撞击性能试验方法-车辆法》等
2025-04-25 11:45
-
“真实”而精确的能量流测试:电动汽车能效
2025-04-25 11:44
-
GRAS助力中国高校科研升级
2025-04-25 10:25
-
梅赛德斯-AMG使用VI-CarRealTime开发其控制
2025-04-25 10:21
