




 广告
广告





















































视觉 Transformer 研究的关键问题: 现状及展望

作者:田永林1, 2, , 王雨桐2, , 王建功2, , 王晓2, 3, , 王飞跃2, 3,
/ 导读 /
深度神经网络(Deep neural network, DNN)由于其突出的性能表现, 已经成为人工智能系统的主流模型之一[1-2]. 针对不同的任务, DNN发展出了不同的网络结构和特征学习范式. 其中, 卷积神经网络(Convolutional neural network, CNN)[3-5]通过卷积层和池化层等具备平移不变性的算子处理图像数据; 循环神经网络(Recurrent neural network, RNN)[6-7]通过循环单元处理序列或时序数据. Transformer[8]作为一种新的神经网络结构, 目前已被证实可以应用于自然语言处理(Natural language processing, NLP)、计算机视觉(Computer vision, CV)和多模态等多个领域, 并在各项任务中展现出了极大的潜力.
Transformer[8]兴起于NLP领域, 它的提出解决了循环网络模型, 如长短期记忆(Long short-term memory, LSTM)[6]和门控循环单元(Gate recurrent unit, GRU)[7]等存在的无法并行训练, 同时需要大量的存储资源记忆整个序列信息的问题. Transformer[8]使用一种非循环的网络结构, 通过编码器−解码器以及自注意力机制[9-12]进行并行计算, 大幅缩短了训练时间, 实现了当时最优的机器翻译性能. Transformer模型与循环神经网络以及递归神经网络均具备对序列数据的特征表示能力, 但Transformer打破了序列顺序输入的限制, 以一种并行的方式建立不同词符间的联系. 基于Transformer模型, BERT[13]在无标注的文本上进行了预训练, 最终通过精调输出层, 在11项NLP任务中取得了最优表现. 受BERT启发, 文献[14]预训练了一个名为GPT-3的拥有1 750亿个参数的超大规模Transformer模型, 在不需要进行精调的情况下, 这一模型在多种下游任务中表现出强大的能力. 这些基于Transformer模型的工作, 极大地推动了NLP领域的发展.
Transformer在NLP领域的成功应用, 使得相关学者开始探讨和尝试其在计算机视觉领域的应用[15-16]. 一直以来, 卷积神经网络都被认为是计算机视觉的基础模型. 而Transformer的出现, 为视觉特征学习提供了一种新的可能[17-21]. 基于Transformer的视觉模型在图像分类[15, 22-23]、目标检测[16, 24]、图像分割[25-26]、视频理解[27-28]、图像生成[29]以及点云分析[30-31]等领域取得媲美甚至领先卷积神经网络的效果.
将Transformer应用于视觉任务并非一个自然的过程, 一方面, Transformer网络以序列作为输入形式, 其本身并不直接适用于二维的图像数据[15-16], 将其适配到视觉任务需要经过特殊设计; 另一方面基于全局信息交互的Transformer网络往往具有较大的计算量, 同时对数据量也有较高要求, 因此需要考虑其效率以及训练和优化等问题[32-33]. 此外, Transformer所定义的基于注意力的全局交互机制是否是一种完备的信息提取方式, 来自CNN中的经验和技巧能否帮助Transformer在计算机视觉任务中取得更好的性能也是需要思考的问题[34-35].
同其他Transformer相关的综述文献[17-19]相比, 本文的区别和主要贡献在于我们以视觉Transformer在应用过程中存在的关键问题为角度进行切入, 针对每个关键问题组织并综述了相关文章的解决方案和思路, 而其他文献[17-19]则更多是从技术和方法分类的角度入手. 本文梳理了Transformer在计算机视觉中应用中的若干关键问题, 同时总结了Transformer在计算机视觉的分类、检测和分割任务中的应用和改进. 本文剩余部分组织如下: 第 1 节以ViT[15]为例介绍视觉Transformer的原理和基本组成, 并对比了Transformer与CNN的区别和联系, 同时总结了Transformer的优势和劣势; 第 2 节给出了视觉Transformer的一般性框架; 第 3 节介绍Transformer研究中的关键问题以及对应的研究进展; 第 4 节介绍Transformer在目标检测领域的应用; 第 5 节介绍Transformer在图像分割领域的应用; 第 6 节总结了全文并展望了视觉Transformer的发展趋势.
ViT原理介绍与分析
ViT[15]将Transformer结构完全替代卷积结构完成分类任务, 并在超大规模数据集上取得了超越CNN的效果[36-39]. ViT结构如图1所示, 它首先将输入图像裁剪为固定尺寸的图像块, 并对其进行线性映射后加入位置编码, 输入到标准的Transformer编码器. 为了实现分类任务, 在图像块的嵌入序列中增加一个额外的可学习的类别词符(Class token).
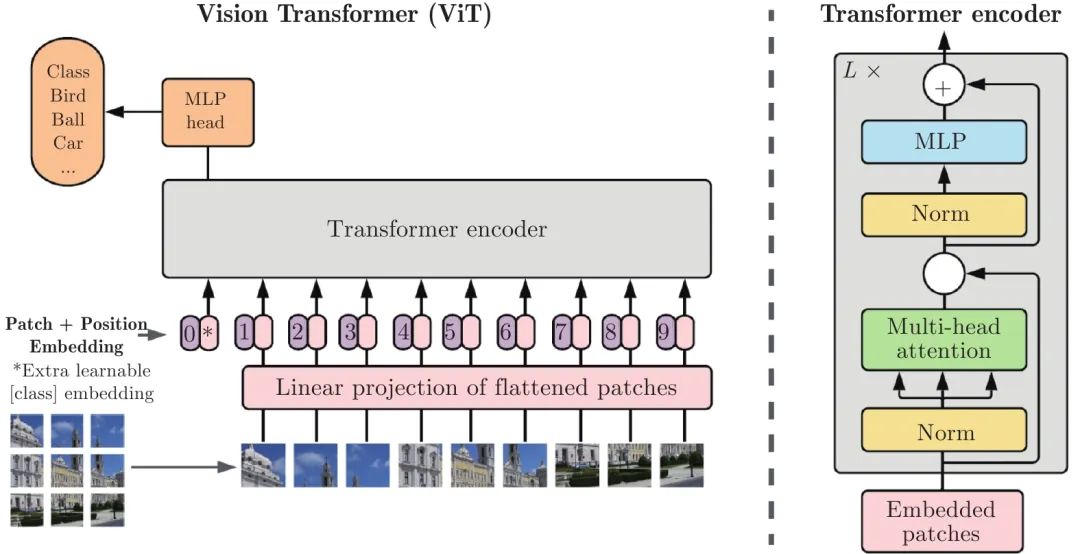
图 1 ViT模型结构[15]Fig. 1 The framework of ViT[15]1.1 图像序列化
对于NLP任务, Transformer的输入是一维的词符嵌入向量, 而视觉任务中, 需要处理的是二维的图像数据. 因此, ViT[15]首先将尺寸为H×W×C的图像x∈RH×W×C裁剪为N=HW/P2个尺寸为P×P×C的图像块, 并将每个图像块展开成一维向量, 最终得到xp∈RN×(P2×C). 记d为Transformer输入嵌入向量的维度, ViT[15]将xp进行线性映射, 并与类别词符一起组成为d维z0, 如式(1)所示, 作为Transformer编码器的输入.
z0=[xclass;x1pE;x2pE;⋯;xNpE]+Epos,E∈R(P2×C)×d,Epos∈R(N+1)×d(1)
其中, z00=xclass是为了实现分类任务加入的可学习的类别词符, E是实现线性映射的矩阵, Epos是位置编码. 类别词符以网络参数的形式定义, 其本身是一种网络权重, 可以通过梯度进行更新. 类别词符z00本身不具备当前输入的特征和信息, 而是在与图像块词符串联后通过自注意力机制实现对图像特征的信息交互或信息聚合, 在编码器最后一层之后, 类别词符z0L作为对图像特征的聚合, 被送入分类头进行类别预测.
1.2 编码器
ViT[15]的编码器由L(ViT[15]中, L= 6)个相同的层堆叠而成, 每个层又由两个子层组成. 其中, 第一个子层是多头自注意力机制(Multi-head self-attention, MSA), 第二个子层是多层感知机(Multi-layer perceptron, MLP). 在数据进入每个子层前, 都使用层归一化(Layer normalization, LN)[40]进行归一化处理, 数据经过每个子层后, 又使用残差连接与输入进行直接融合. 值得注意的是, 为了实现残差连接[5], ViT编码器的每一层的输出维度都设计为d维. 最后, 经过L层网络编码之后, 类别词符z0L被送入到由MLP构成的分类头中, 从而预测得到图像的类别y. 第l层的特征计算过程如下:
z′l=MSA(LN(zl−1))+zl−1,l=1,⋯,L(2)zl=MLP(LN(z′l))+z′l,l=1,⋯,L(3)类别预测结果的产生可表示为:y=LN(z0L)(4)
1.3 注意力机制
注意力机制(Attention)最早应用于NLP任务中[9, 12, 41], 通过引入长距离上下文信息, 解决长序列的遗忘现象. 在视觉任务中, 注意力机制同样被用来建立空间上的长距离依赖, 以解决卷积核感受野有限的问题[42-43].
ViT使用的自注意力机制(Self-attention, SA)是一种缩放点积注意力(Scaled dot-product attention), 其计算过程如图2所示. 自注意力层通过查询(Query)与键(Key)-值(Value)对之间的交互实现信息的动态聚合. 对输入序列z∈RN×d, 通过线性映射矩阵UQKV将其投影得到Q、K和V三个向量. 在此基础上, 计算Q和K间的相似度A, 并根据A实现对V进行加权. 自注意力的计算过程如下所示:
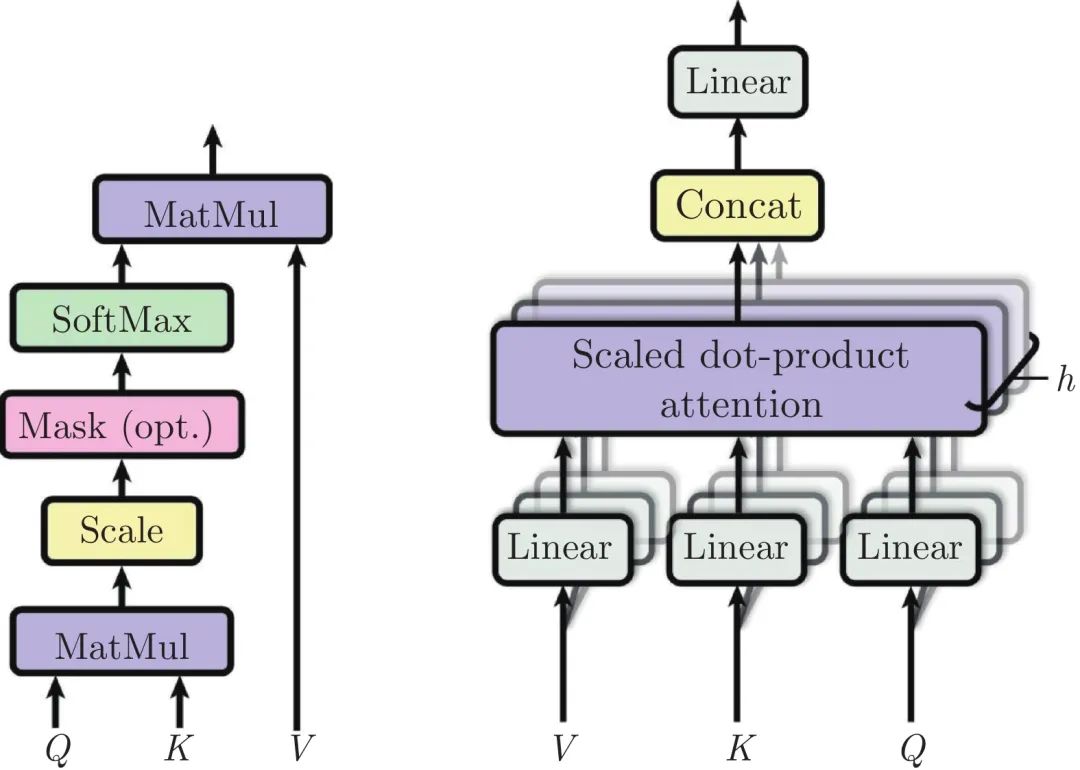
图 2 自注意力[15]与多头自注意力[15]Fig. 2 Self-attention[15]and multi-head self-attention[15]
[Q,K,V]=zUQKV,UQKV∈Rd×3dh(5)A=softmax(QKT/√dh),A∈Rh⋅dh×d(6)加权聚合过程可表示为:SA(z)=AV(7)
1.3.1 多头自注意力
为了提高特征多样性, ViT使用了多头自注意力机制. 多头自注意力层使用多个自注意力头来并行计算, 最后通过将所有注意力头的输出进行拼接得到最终结果. 多头注意力计算过程如下所示:
MSA(z)=[SA1(z);SA2(z);⋯;SAk(z)]Umsa(8)
其中, Umsa∈Rh⋅dh×d为映射矩阵, 用于对拼接后的特征进行聚合, h表示自注意力头的个数, dh为每个自注意力头的输出维度. 为了保证在改变h时模型参数量不变, 一般将dh设置为d/h. 多头自注意力机制中并行使用多个自注意力模块, 可以丰富注意力的多样性, 从而增加模型的表达能力.
1.4 位置编码
ViT使用了绝对位置编码来弥补图像序列化丢失的图像块位置信息. 位置编码信息与特征嵌入相加后被送入编码器进行特征交互. ViT使用的位置编码由不同频率的正弦和余弦函数构成, 其计算过程如下:
PE(pos,2i)=sin(pos/100002i/d)(9)PE(pos,2i+1)=cos(pos/100002i/d)(10)
其中, pos是每个图像块在图像中的位置, i∈[0,⋯,d/2]用于计算通道维度的索引. 对于同一个i, 通道上第2i和2i+1个位置的编码是具有相同角速度的正弦和余弦值. 为了使得位置编码可以与输入嵌入相加, 位置编码需要与嵌入保持相同的维度.
1.5 Transformer同卷积神经网络的区别与联系
本节主要从连接范围[44]、权重动态性[44]和位置表示能力三个方面来阐述Transformer同卷积神经网络的区别与联系.
1.5.1 连接范围
卷积神经网络构建在输入的局部连接之上, 通过不断迭代, 逐渐扩大感受野, 而Transformer则具备全局交互机制, 其有效感受野能够迅速扩大. 图3展示了语义分割任务中, DeepLabv3+[45]和SegFormer[25]在有效感受野上的对比, 可以看到, 相比于卷积神经网络, Transformer网络的有效感受野范围具备明显优势. 虽然卷积核的尺寸可以设置为全图大小, 但这种设置在图像数据处理中并不常见, 因为这将导致参数量的显著增加.
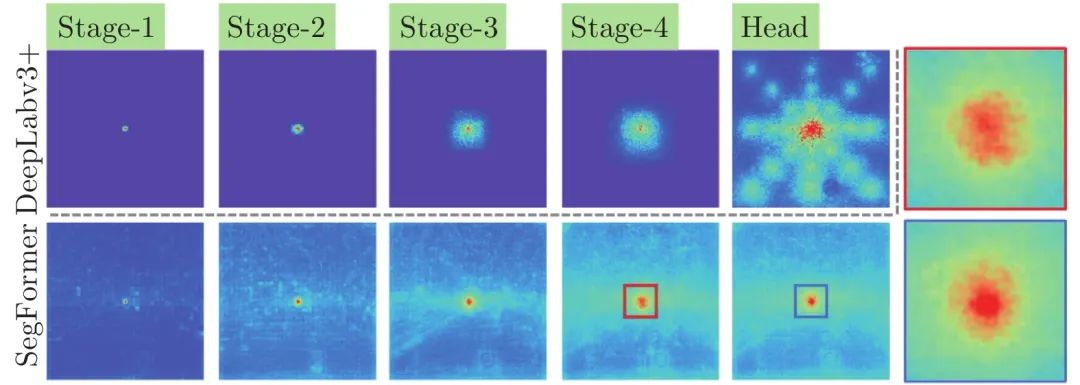
图 3 Transformer与CNN有效感受野对比[25]Fig. 3 The comparison[25] of effective receptive field between Transformer and CNN
1.5.2 权重动态性
传统卷积神经网络在训练完成后, 卷积核权重不随输入或滑动窗口位置变化而改变[46], 而Transformer网络通过相似性度量动态地生成不同节点的权重并进行信息聚合. Transformer的动态性与动态卷积[46]具备相似的效果, 都能响应输入信息的变化.
1.5.3 位置表示能力
Transformer使用序列作为输入形式, 其所使用的自注意力机制和通道级MLP模块均不具备对输入位置的感知能力, 因此Transformer依赖位置编码来实现对位置信息的补充. 相比之下, 卷积神经网络处理二维图像数据, 一方面卷积核中权重的排列方式使其具备了局部相对位置的感知能力, 另一方面, 有研究表明[47], 卷积神经网络使用的零填充(Zero padding)使其具备了绝对位置感知能力, 因此, 卷积神经网络不需要额外的位置编码模块.
1.6 ViT的优劣势分析
ViT[15]模型的优势在于其构建了全局信息交互机制, 有助于建立更为充分的特征表示. 此外, ViT采用了Transformer中标准的数据流形式, 有助于同其他模态数据进行高效融合. ViT存在的问题主要在三个方面, 首先全局注意力机制计算量较大, 尤其是面对一些长序列输入时, 其与输入长度成平方的计算代价极大地限制了其在高分辨率输入和密集预测任务中的应用; 其次, 不同于卷积中的局部归纳偏置, ViT模型从全局关系中挖掘相关性, 对数据的依赖较大, 需要经过大量数据的训练才能具备较好效果; 此外, ViT模型的训练过程不稳定且对参数敏感.
Transformer研究中的关键问题
本节以图像分类这一基本的视觉任务为切入, 着重介绍Transformer在用于视觉模型骨架时的关键研究问题以及对应的研究进展.
2.1 如何降低Transformer的计算代价
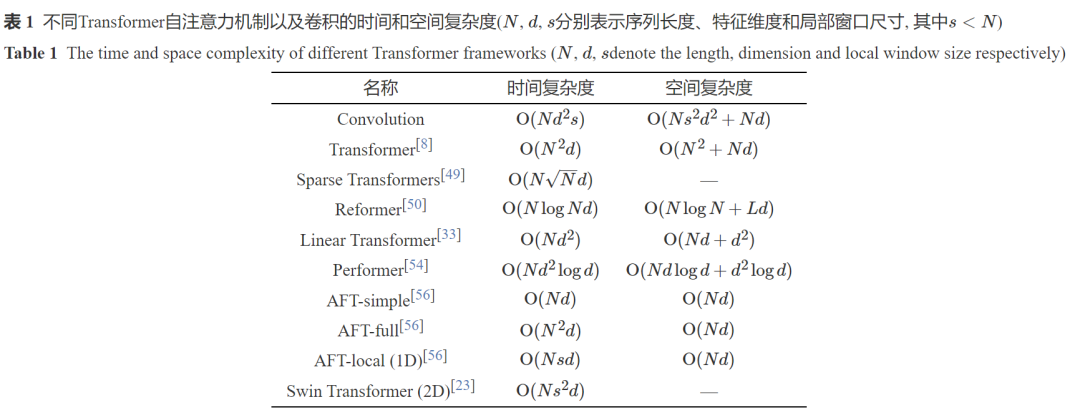
Transformer的设计使其具有全局交互能力, 但同时其全局自注意力机制也带来了较高的时间和空间代价, 如何设计更高效的Transformer机制成为研究热点之一[48]. 原始的Transformer使用了点积注意力机制(Dot-product attention), 其具有二次的时间和空间复杂度, 因此不利于推广到高分辨率图像和特征的处理中. 现有文献主要从输入和注意力设计两个角度来降低Transformer注意力机制的复杂度. 表1总结了多种Transformer模型的自注意力机制的计算复杂度.
2.1.1 受限输入模式
减少输入到注意力层的序列的长度是降低计算量的直接手段, 现有文献主要从输入下采样、输入局部化和输入稀疏化三个角度来限制序列的长度[49].
1) 输入下采样: PVT[22]通过金字塔型的网络设计将图像分辨率层级尺度衰减, 来逐渐降低图像序列的长度. DynamicViT[51]通过输入学习动态的序列稀疏化策略, 以此逐渐降低图像序列长度. 该类方法在维持全局交互的基础上, 以减小分辨率的形式实现对计算量的降低.
2) 输入局部化: 输入局部化旨在限制注意力的作用范围, 通过设计局部的注意力机制降低计算量, 例如Swin Transformer[23]提出了基于窗口的多头注意力机制, 将图像划分成多个窗口, 仅在窗口内部进行交互.
3) 输入稀疏化: 稀疏化通过采样或压缩输入来降低注意力矩阵的尺寸, 例如, CrossFormer[52]提出了对输入进行间隔采样来构建长距离注意力(Long distance attention). Deformable DETR[24]将可形变卷积的设计引入到注意力的计算中, 通过学习采样点的位置信息实现稀疏交互机制, 在减小计算量的同时维持了较大范围的感受野.
2.1.2 高效注意力机制
核函数方法[33]和低秩分解[53]是用来降低注意力复杂度的主要方法[48]. 表1中总结了不同注意力机制的时间复杂度和空间复杂度, 同时我们给出了卷积算子的复杂度作为参考. 为了方便对比, 我们在卷积复杂度的计算中, 将特征图的长宽乘积等同于Transformer的输入序列长度, 将Transformer的词符特征的维度视为卷积输入与输出通道数, 将局部Transformer的窗口大小s视为卷积核大小.
1) 核函数方法(Kernelization): 核函数方法通过重构注意力计算机制打破归一化函数对Q和K计算的绑定, 来降低注意力计算的时间和空间成本[33, 54-55]. 点积注意力机制可被表示为如下形式:
D(Q,K,V)=ρ(QKT)V(11)
其中, ρ表示激活函数, 在经典Transformer[8]中, 激活函数为Softmax. Efficient attention[32]和Linear Transformer[33]将注意力机制的计算转换为式(12)的形式, 实现对点积注意力的近似.
E(Q,K,V)=ϕ(Q)(ϕ(K)TV)(12)
这种方式避免了对具有O(N2)时间和空间复杂度的注意力图的计算和存储, 提高了注意力的计算效率. AFT[56]采用了类似式(12)的设计, 但使用逐元素相乘代替矩阵的点积运算, 从而进一步降低了计算量.
2) 低秩方法(Low-rank methods): 低秩分解假定了注意力矩阵是低秩的, 因此可以将序列长度进行压缩以减少计算量. 考虑到注意力层输出序列长度只与查询的节点个数有关, 因此通过压缩键和值向量的序列长度, 不会影响最终输入的尺寸. PVT[22]、ResT[53]和CMT[34]利用卷积减少了键和值对应的词符个数以降低计算量. SOFT[57]使用高斯核函数替换Softmax点积相似度, 并通过卷积或池化的方式从序列中采样, 实现对原始注意力矩阵的低秩近似.
2.2 如何提升Transformer的表达能力
本小节主要围绕如何提高Transformer模型的表达能力而展开, 视觉Transformer的研究仍处于起步阶段, 一方面可以借鉴CNN的改进思路, 通过类似多尺度等的方案实现对性能的提升, 另一方面由于Transformer基于全局信息的交互, 使其具有不同于CNN的特征提取范式, 从而为引入CNN设计范式进而提升性能提供了可能. CNN的局部性(Locality)设计范式可以丰富Transformer网络的特征多样性, 同时也有利于改善Transformer特征的过度光滑(Over-smoothing)的问题[59]. 此外, 对Transformer本身机制, 如注意力和位置编码等的改进也有望提高其表达能力. 表2展示了不同Transformer模型在ImageNet[4]上的性能对比.

2.2.1 多尺度序列交互
多尺度特征在CNN中已经获得了较为广泛的应用[62], 利用多尺度信息能够很好地结合高分辨率特征和高语义特征, 实现对不同尺度目标的有效学习. 在视觉Transformer中, CrossViT[63]使用两种尺度分别对图像进行划分并独立编码, 对编码后的多尺度特征利用交互注意层实现两种尺度序列之间的信息交互. CrossFormer[52]则借助金字塔型网络, 在不同层得到不同尺度的特征, 之后融合不同层的特征, 以进行跨尺度的信息交互.
2.2.2 图像块特征多样化
DiversePatch[64]发现了在Transformer的深层网络中, 同层图像块的特征之间的相似性明显增大, 并指出这可能引起Transformer性能的退化, 使其性能无法随深度增加而继续提升. 基于该发现, DiversePatch[64]提出了三种方式来提高特征的多样性. 首先, 对网络最后一层的图像块特征之间计算余弦相似度, 并作为惩罚项加入到损失计算中. 其次, 基于对Transformer网络首层图像块特征多样性较高的观察, DiversePatch提出使用对比损失(Contrastive loss)来最小化同一图像块在首层和尾层对应特征的相似性, 而最大化不同图像块在首层和尾层对应特征的相似性. 最后, 基于CutMix[65]的思想, DiversePatch提出了混合损失(Mixing loss), 通过将来自不同图片的图像块进行混合, 使网络学习每个图像块的类别, 以避免特征同质化.
2.2.3 注意力内容多样化
DeepViT[66]观察到Transformer中的注意力坍塌(Attention collapse)现象, 即随着网络加深, 深层注意力图不同层之间的相似性逐渐增大甚至趋同, 并指出注意力相似性增加和特征图相似性增加有密切关系, 从而导致了Transformer性能随层数增加而快速饱和. 为了避免注意力坍塌现象, DeepViT提出了增加词符的嵌入维度的方法和重注意力(Re-attention)机制. 增加词符的嵌入维度有助于词符编码更多信息, 从而提高注意力的多样性, 但同时会带来参数量的显著增加. 重注意力机制基于层内多头注意力的多样性较大的现象, 通过对多头注意力以可学习的方式进行动态组合来提高不同层注意力的差异. 重注意力机制R可表示为式(13)的形式, 其中Θ∈Rh×h.
R(Q,K,V)=Norm(ΘT(ρ(QKT)))V(13)
Refiner[59]基于类似的思想提出了注意力扩张(Attention expansion)和注意力缩减(Attention reduction)模块, 通过学习多头注意力的组合方式来构建多样化的注意力, 并可灵活拓展注意力的个数. 同时, Refiner提出使用卷积来增强注意力图的局部特征, 从而降低注意力图的光滑程度.
2.2.4 注意力形式多样化
经典Transformer中的注意力机制依赖点对间的交互来计算其注意力, 其基本作用是实现自我对齐, 即确定自身相对于其他节点信息的重要程度[67]. Synthesizer[67]指出这种通过点对交互得到的注意力有用但却并不充分, 通过非点对注意力能够实现对该交互方式的有效补充.
1) 非点对注意力(Unpaired attention): Synthesizer[67]提出了两种新的非点对注意力实现方法, 即基于独立词符和全局任务信息的注意力计算方法. 基于独立词符的注意力, 以每一个词符为输入, 在不经过与其他词符交互的情况下, 学习其他词符相对于当前词符的注意力; 基于全局任务信息的注意力生成方法则完全摆脱注意力对当前输入的依赖, 通过定义可训练参数从全局任务信息中学习注意力. 这两种方式可视为从不同的角度来拓展注意力机制, 实验验证了它们同基于点对的注意力能形成互补关系. VOLO[68]同样提出了基于独立词符的注意力生成方法, 并将注意力的范围限制在局部窗口内, 形成了类似动态卷积的方案.
2.2.5 Transformer与CNN的结合
局部性是CNN的一个典型特征, 它是基于临近像素具有较大相关性的假设而形成的一种归纳偏置(Inductive bias)[69-71]. 相比之下, Transformer的学习过程基于全局信息的交互, 因此在学习方式和特征性质等方面与CNN存在一定差异[72], 将CNN与Transformer进行结合有助于提升Transformer网络对特征的学习和表达能力[23, 58, 73-74]. 本节从机理融合、结构融合和特征融合三个角度介绍CNN与Transformer结合的工作.
1) 机理融合: 该方式通过在Transformer网络的设计中引入CNN的局部性来提高网络表达能力. 以Swin Transformer[23]为代表的Transformer网络通过将注意力限制在局部窗口内, 来显式地进行局部交互. 此外, CeiT[73]在FFN模块中, 引入局部特征学习, 以建模局部关系.
2) 结构融合: 这种融合方法通过组合Transformer和CNN的模块形成新的网络结构. CeiT[73]和ViTc[35]将卷积模块添加到Transformer前实现对底层局部信息的提取. MobileViT[75]将Transformer视为卷积层嵌入到卷积神经网络中, 实现了局部信息和全局信息的交互.
3) 特征融合: 该方式在特征级别实现对CNN特征和Transformer特征的融合. 这类方法往往采用并行的分支结构, 并将中间特征进行融合交互. MobileFormer[74]和ConFormer[76]采用并行的CNN和Transformer分支, 并借助桥接实现特征融合. DeiT[58]借助知识蒸馏的思路, 通过引入蒸馏词符(Distillation token)来将CNN的特征引入到Transformer的学习过程中.
2.2.6 相对位置编码
原始Transformer使用绝对位置编码为输入词符提供位置信息, 只能隐式地度量相对位置信息[77]. 相对位置编码 (Relative position encoding, RPE)则直接对序列的距离进行表示, 能够实现对不同长度的序列的表达不变性, 同时相关关系的显式度量也有利于提升模型性能[78].
为了说明不同编码方式在自注意力层的表现不同, 这里针对式(6)和式(7)对自注意力机制进一步说明. 对包含n个元素 xi∈Rdx 的输入序列x=(x1,⋯,xn), 自注意力的输出序列为z=(z1,⋯,zn), 其中, 每一个输出元素zi∈Rdz是所有输入元素的加权和, 计算过程如下所示:
zi=n∑j=1αij(xjWV)(14)
其中, 每个权重系数αij通过Softmax计算得到:
αij=exp(eij)n∑k=1exp(eik)(15)
其中, eij通过缩放点积比较两个输入元素计算得到:
eij=(xiWQ)(xjWK)T√dz(16)
其中, WQ、WK和WV∈Rdx×dz是参数矩阵. RPE在自注意力机制中加入输入元素间的相对位置信息, 以提升模型表达能力.
Shaw等提出的RPE[78]: 基于自注意力的相对位置编码, 将输入词符建模为有向的全连接图, 任意两个位置i和j间的边为可学习的相对编码向量pVij,pKij. 将编码向量嵌入自注意力机制, 计算过程如下所示:
zi=n∑j=1αij(xjWV+pVij)(17)eij=(xiWQ)(xjWK+pKij)T√dz(18)
其中, pKij,pVij∈Rdz分别为加在键和值上的可学习的权重参数.
Transformer-XL的RPE[79]: 相比Shaw的方法, 该方法加入了全局内容和全局位置偏置, 使得在特定长度序列下训练的模型能够泛化到更长的序列输入上. 计算过程如下所示:
eij=(xiWQ+u)(xjWK)T+(xiWQ+v)(si−jWR)T√dz(19)
其中, u,v∈Rdz替换原始绝对位置信息的可学习向量, si−jWR替换绝对位置信息的相对位置信息. WR∈Rdz×dz是可学习的矩阵, s是正弦编码向量.
Huang等提出的RPE[80]: 相比Shaw的RPE中只建模了键和查询、查询和相对位置编码的交互, 增加了对键和相对位置交互的显式建模, 使其具有更强的表达能力. 计算过程如下所示:
eij=(xiWQ+pij)(xjWK+pij)T−pijpTij√dz(20)
其中, pij∈Rdz是查询和键共享的相对位置编码.
相比NLP任务中输入为一维词符序列的语言模型, 视觉任务中输入为二维图像, 因此需要二维的位置信息.
SASA中的RPE[81]: 将二维的相对位置信息分为水平和垂直的两个方向, 在每一个方向进行一维位置编码, 并与特征嵌入相加, 相对位置信息的计算过程如下所示:
eij=(xiWQ)(xjWK+concat(pKδx,pKδy))T√dz(21)
其中, δx=xi−xj和δy=yi−yj分别为x轴和y轴的相对位置偏置, pKδx和pKδy分别为长度为12dz的可学习向量, concat将这两个向量拼接起来组成最终的长度为dz的相对位置编码.
Axial-Deeplab中的RPE[81]: 相比SASA中的RPE只在键上加入偏置, 该方法同时对查询、键和值引入了偏置项. 通过轴向注意力, 将二维的注意力先后沿高度和宽度轴分解为两个一维的注意力.
iRPE (image RPE)[82]: 以往的相对位置编码都依赖于输入嵌入, 为了研究位置编码对输入嵌入的依赖关系, 该方法提出了两种相对位置编码模式, 偏置模式和上下文模式. 偏置模式的相对位置编码不依赖输入嵌入, 上下文模式则考虑了相对位置编码与查询、键和值间的交互. 二者都可以表示为如下形式:
eij=(xiWQ)(xjWK)T+bij√dz(22)
其中, bij∈R是决定偏置和上下文模式的二维相对位置编码. 偏置模式下表示为如下形式:
bij=rij(23)
其中, rij是可学习的标量, 表示位置i和j间的距离. 上下文模式下表示为如下形式:
bij=(xiWQ)rTij(24)
其中, rij∈Rdz是与键相加的可学习偏置向量. 在ImageNet[83]上使用DeiT-S[58]完成分类任务发现, 上下文模式比偏置模式具有更好的表达能力.
同时, 为了研究相对位置的方向性是否有助于视觉任务, 设计了不同的相对位置映射函数以实现无方向性位置编码和有方向性位置编码. 无方向的映射包括欧氏距离法和量化欧氏距离法, 都是通过相对位置坐标(xi−xj,yi−yj)的欧氏距离计算得到:
rij=pI(i,j)(25)I(i,j)=g((√(xi−xj)2+(yi−yj)2))(26)I(i,j))=g(quant(√(xi−xj)2+(yi−yj)2))(27)
其中, 偏置模式下pI(i,j)是可学习的标量, 上下文模式下是向量. g(⋅)是将相对位置映射为权重的分段函数. quant将具有不同相对位置的邻居映射为不同的值.
方向性的映射位置编码包括交叉法和乘积法, 交叉法分别计算横纵方向的位置编码, 并进行相加, 其计算过程如下所示:
rij=pxIx(i,j)+pyIy(i,j)(28)Ix(i,j)=g(xi−xj)(29)Iy(i,j)=g(yi−yj)(30)
乘积法将两个方向上的位置偏移构成索引对, 进而产生位置编码如下所示:
rij=pIx(i,j),Iy(i,j)(31)
实验发现, 方向性位置编码比非方向性位置编码具有更好的表达能力.
2.3 Transformer的训练和优化问题
Transformer的训练过程需要精心设计学习率以及权重衰减等多项参数, 并且对优化器的选择也较为苛刻, 例如其在SGD优化器上效果较差[35]. 文献[35]和CeiT[73]在图像编码前使用卷积层级来解决Transformer的难优化以及参数敏感的问题, 引入卷积后, 模型对学习率和权重衰减等参数的敏感性得到了显著降低, 收敛速度得到加快, 同时在SGD优化器上也可以进行稳定的学习. 关于在早期引入卷积机制使模型性能得到改善的原因, Raghu等[72]给出了解释和分析, 他们利用充足的数据训练视觉Transformer, 发现模型在性能提升的同时, 其在浅层也逐步建立了局部表示. 这表明浅层局部表示对性能提升可能有显著的影响, 同时也为解释在浅层引入具备局部关系建模能力的卷积层从而提升Transformer的训练稳定性和收敛速度的现象提供了一个思路.
2.4 结构设计问题
本节将从整体结构和局部结构两个角度对Transformer方法以及类Transformer方法进行介绍. 其中, 整体结构上, 我们以图像特征尺寸变化情况为依据, 将其分为单尺度的直筒型结构和多尺度的金字塔型结构[84]; 在局部结构上, 我们主要围绕Transformer中基本特征提取单元的结构, 分析卷积以及MLP方法在其中的替代和补充作用以及由此形成的不同局部结构设计.
2.4.1 单尺度和多尺度结构设计
单尺度和多尺度的结构简图如图4所示[84], 其中交互模块表示空间或通道级的信息交互层, 聚合层表示对全局信息进行聚合, 例如全局最大值池化或基于类别词符的查询机制等. 与单尺度结构相比, 多尺度设计的典型特征在于下采样模块的引入. ViT[15]是单尺度直筒型结构的代表, 其在网络不同阶段中使用同等长度或尺寸的图像词符序列; 与之相对应的是以PVT[22]、Swin Transformer[23]以及CrossFromer[52]等为代表的多尺度金字塔型结构. 多尺度方案可以有效降低网络参数和计算量, 从而使得处理高分辨率数据成为可能. 文献[84]对单尺度和多尺度方法进行了对比, 实验表明多尺度方法相比于单尺度在多种框架中均具备稳定的性能优势.
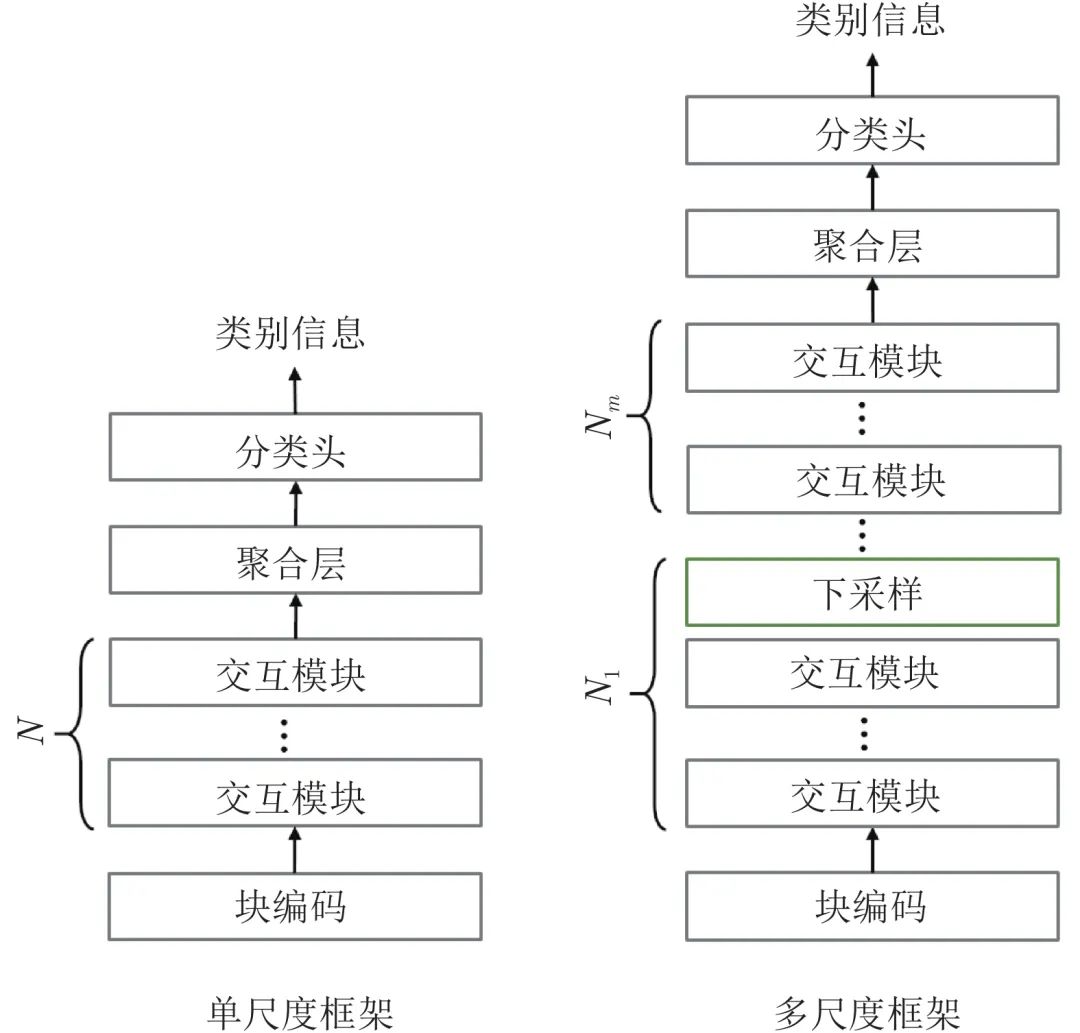
图 4 单尺度与多尺度结构对比Fig. 4 The comparison of single-scale framework and multi-scale framework
2.4.2 交互模块结构设计
如图1所示, 在ViT[15]的编码器结构中, 信息交互模块主要由多头注意力层和MLP层构成, 其中多头自注意力层主要完成空间层级的信息交互, 而MLP主要完成通道级别的信息交互[15]. 当前大多数视觉Transformer的交互模块设计基本都遵循了这一范式, 并以自注意力机制为核心. 同多头注意力机制相比, 虽然卷积以及MLP在原理和运行机制上与之存在差异, 但它们同样具备空间层级信息交互的能力, 因此许多工作通过引入卷积或MLP来替换或增强多头自注意力机制[34, 85-91], 形成了多样的交互模块设计方案. 其中最为典型的是以纯MLP架构为代表的无自注意力方案[85-88], 和引入卷积的增强自注意力的方案[34, 91]. 为了简洁起见, 在本文后续内容中, 我们将在空间层级进行信息交互的MLP称为空间MLP机制(Spatial MLP), 将在通道层级进行信息交互的MLP机制称为通道MLP (Channel MLP). 不同交互模块的结构如图5所示.
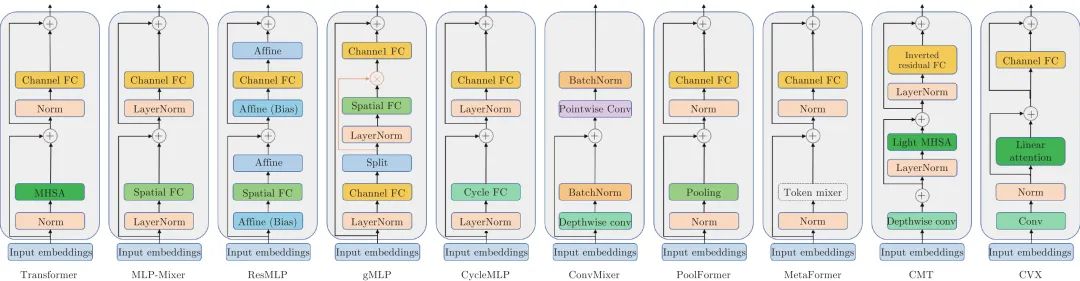
图 5 类Transformer方法的交互模块结构对比(Transformer[8], MLP-Mixer[85], ResMLP[86], gMLP[87], CycleMLP[88], ConvMixer[89], PoolFormer[90], metaFormer[90], CMT[34], CVX[91])Fig. 5 The comparison of mixing blocks of Transformer-like methods (Transformer[8], MLP-Mixer[85], ResMLP[86], gMLP[87], CycleMLP[88], ConvMixer[89], PoolFormer[90], metaFormer[90], CMT[34], CVX[91])
1) 无自注意力交互模块: MLP-Mixer[85]引入了空间MLP来替换多头自注意力机制, 成为基于纯MLP的类Transformer架构的早期代表. 在对图像块序列的特征提取中, MLP-Mixer在每一层的开始首先将图像块序列转置, 从而实现利用MLP进行不同词符之间的交互, 之后经过反转置, 再利用MLP进行通道层级的信息交互. 相比于自注意力机制, MLP的方案实现了类似的词符间信息聚合功能且同样具备全局交互能力; 此外, 由于MLP每层的神经元的顺序固定, 因此其具备位置感知能力, 从而不再需要位置编码环节. MLP-Mixer彻底去除了自注意力机制, 仅依靠纯MLP组合取得了与ViT相媲美的性能. ResMLP[86]同样是完全基于MLP的架构, 同时其指出纯MLP设计相比于基于自注意力的Transformer方法在训练稳定性上具备优势, 并提出通过使用简单的仿射变换(Affine transformation)来代替层归一化等规范化方法. gMLP[87]提出一种基于空间MLP的门控机制以替代自注意力, 并使用了通道MLP-空间门控MLP-通道MLP的组合构建了交互单元. 为了应对MLP无法处理变长输入的问题, CycleMLP[88]提出一种基于循环采样的MLP机制, 其在类似卷积核的窗口内部, 按照空间顺序采样该位置的某一通道上的元素, 且不同空间位置的采样元素对应的通道也不同, 从而构建了一种不依赖输入尺寸的空间交互方法, 同时也具备通道交互能力.
基于卷积也可以实现空间信息交互, 从而同样具备取代自注意力的可能, ConvMixer[89]使用了逐深度卷积(Depthwise convolution)和逐点卷积(Pointwise convolution)来进行空间和通道信息交互, 从而打造了一个基于纯卷积的类Transformer网络. PoolFormer[90]则使用了更为简单的Pooling操作来进行空间信息交互, 并进一步提出了更为一般的交互模块方案metaFormer[90]. ConNeXt[92]将Swin Transformer[23]网络的特点迁移到卷积神经网络的设计中, 通过调整不同卷积块的比例、卷积核大小、激活函数以及正则化函数等, 使卷积神经网络的结构尽可能趋近Swin Transformer, 从而在相似计算量下, 实现下超越Swin Transformer的性能. RepLKNet[93]指出在图像处理中, Transformer的优势可能来源于较大的感受野. 基于这个观点, RepLKNet通过扩大卷积核, 加入旁路连接和重参数化机制, 来改造卷积神经网络从而取得了媲美Swin Transformer的效果.
总的来说, 无论是使用MLP还是卷积或者Pooling等具备空间交互能力的算子, 在Transformer的基本框架下, 替换自注意力模块后依然能够达到与Transformer类似的性能. 这也表明, 或许自注意力机制并不是Transformer必需的设计, Transformer的性能可能更多来自于整体的架构[90]以及全局交互给感受野带来的优势[93].
2) 引入卷积的自注意力交互模块: 卷积所具备的局部空间交互性和通道交互性能够有效地与自注意力机制形成互补[84], 通过卷积来增强交互模块的设计在CMT[34]以及CVX[91]等工作中均进行了尝试并取得了超越基准Transformer的效果. 其中CMT[34]在自注意力前引入卷积增强局部特性建模, 并在通道MLP中加入了卷积增强空间特性建模能力. CVX[91]使用了Performer[54]等线性自注意力机制, 并借助卷积本身的归纳偏置去除了位置编码和类别词符.
视觉Transformer的一般性框架
视觉Transformer结构的设计是一个活跃的研究方向, 无论是ViT[15]还是后续的改进方法, 都很好地拓展了视觉Transformer的设计思路. 但目前仍然缺乏对视觉Transformer通用设计方案的讨论. 本节以底层视觉分类任务为例, 给出视觉Transformer的一般性框架VTA (Vision Transformers architecture), 如图6所示. VTA给出的视觉Transformer一般性框架包含七层: 输入层、序列化层、位置编码层、交互层、采样层、聚合层以及输出层. 其中输入层和输出层分别完成对输入的读取和结果的产生, 下面将对剩余各层进行简要介绍.
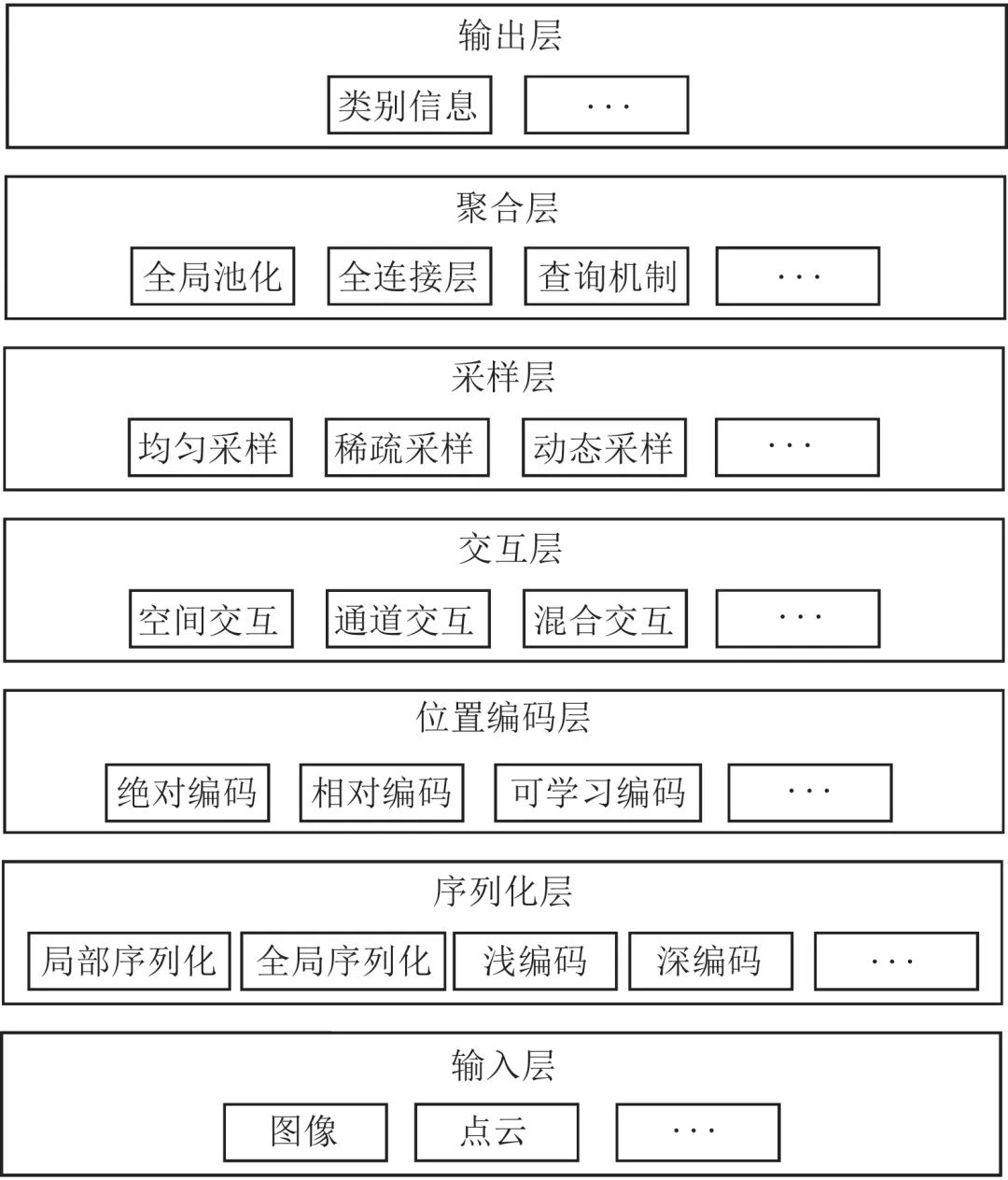
图 6 视觉Transformer的一般性框架Fig. 6 Vision Transformers architecture
3.1 序列化层序列化层的功能在于将输入划分为词符序列的形式, 并进行序列编码. 其中, 序列划分方式可以分为局部序列划分和全局序列划分. 局部序列划分将序列分组, 位于同一组的词符可在后续环节进行交互, 典型的局部序列划分方法有Swin Transformer[23]所使用的局部窗口机制等. 全局序列划分则是更一般的序列划分方法, 这种方式下, 全部词符均可以进行直接交互. 对编码方式而言, 主要有浅编码和深编码两种方式, 相对于浅编码方案, 深度编码利用更多的卷积层对图像或划分后的序列进行处理, 更有利于视觉Transformer的训练和优化[73].
3.2 位置编码层
对不具备位置感知能力的视觉Transformer方案, 位置编码层被用来显式地提取位置信息. 位置编码方案主要包括绝对位置编码、相对位置编码以及可学习位置编码. 绝对位置编码仅考虑词符在序列中的位置信息, 相对位置编码则考虑词符对之间的相对位置信息, 更有利于提高模型的表达能力[78]. 此外, 位置编码还可以可学习的方式进行[16], 以建立更为一般的位置编码信息.
3.3 交互层
交互层旨在对词符序列中的特征进行交互, 主要可分为空间交互、通道交互和混合交互模式. 原始的Transformer方案[15]将空间交互和通道交互分离, 并使用基于自注意力机制实现空间交互功能. 其通过计算词符对之间的相似性来进行加权信息聚合. 基于注意力机制的空间交互是早期Transformer方法的典型特质. 但随着更多相关工作的开展, 研究人员发现, 自注意力机制也仅是空间交互功能的一种实现方式, 其可以被卷积或空间MLP所替代. 通道信息交互常用的方法是通道MLP. 混合交互机制则打破了空间和通道独立的限制, 利用包括卷积在内的算子, 同时建立词符在空间和通道中的关系[73, 89-90].
3.4 采样层
采样层旨在对词符序列进行采样或合并, 以减少序列中词符个数, 从而降低计算量. 常见的采样方式包括均匀采样、稀疏采样以及动态采样. 其中, 均匀采样[22]通过池化层或卷积层对相邻词符进行合并; 稀疏采样[24, 52]则在更大的范围内进行词符的选择或合并, 有利于提高感受野范围. 动态采样[51]是一种更为一般性的采样方案, 其往往通过可学习的过程从输入的词符序列中自适应地选择一些数量的词符, 作为后续网络的输入.
3.5 聚合层
对分类任务而言, 聚合层主要完成对词符特征全局信息的聚合. 全局池化、全连接层是常见的全局信息聚合方式. 这两种方式都属于静态聚合方案, 其聚合方式不随输入内容变化而改变. ViT[15]使用了基于类别词符的查询机制, 通过定义可学习和更新的类别词符变量, 并与输入词符序列进行互注意力实现对信息的动态聚合.
基于Transformer的目标检测模型
基于卷积神经网络的目标检测模型训练流程主要由特征表示, 区域估计和真值匹配三部分组成:
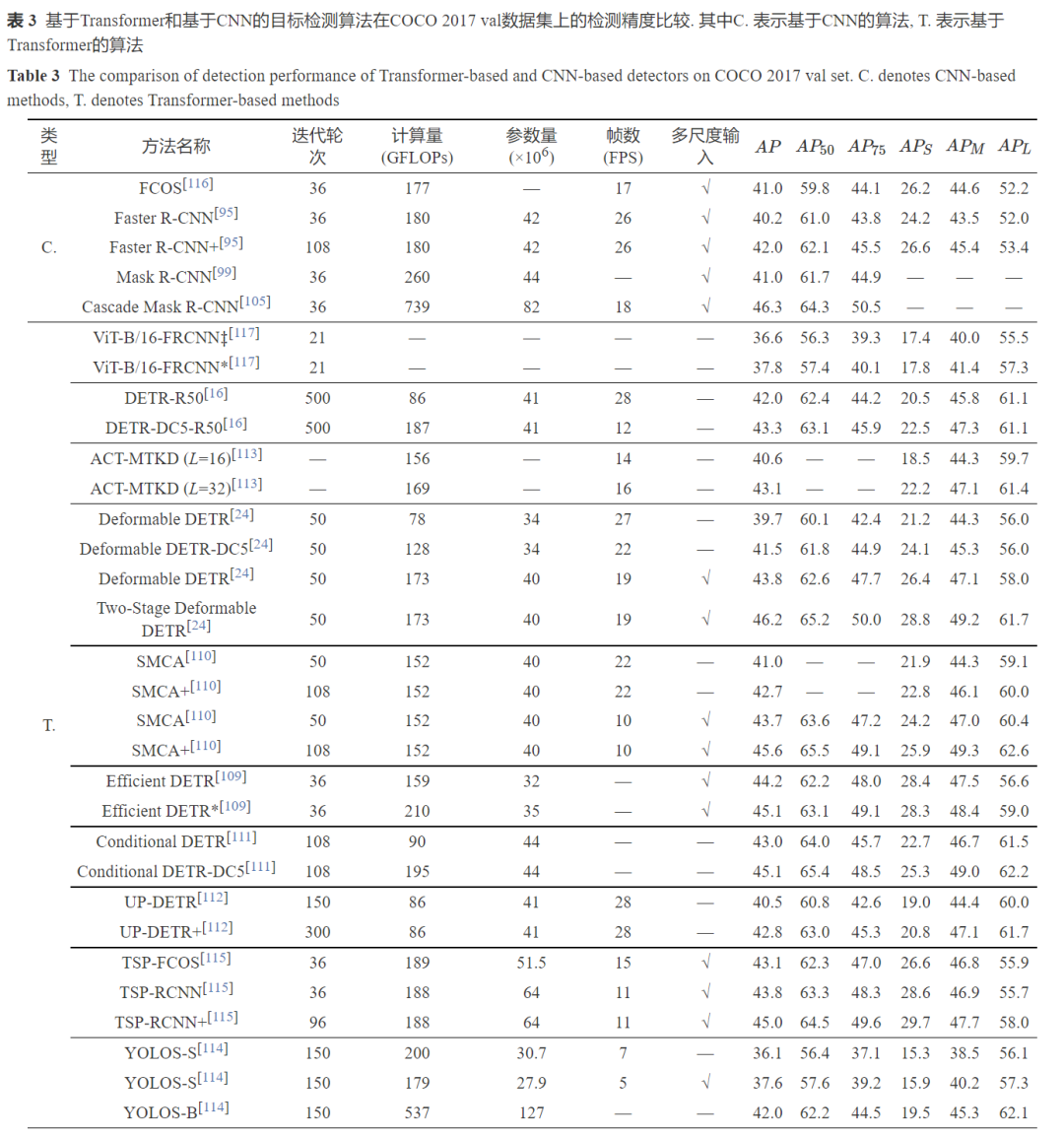
1) 特征表示: 特征表示基于卷积神经网络来提取输入的语义特征[5, 94].2) 区域估计: 区域估计通过区域特征提取算子, 如卷积、裁剪、感兴趣区域池化(RoI pooling)[95]或感兴趣区域对齐(RoI align)[99]等, 获得局部特征, 并对局部输入的类别和位置等信息进行估计和优化.3) 真值匹配: 基于卷积神经网络的真值匹配往往通过具备位置先验的匹配策略, 如重叠度(IoU)、距离等, 进行标注框同锚点框[95, 100]、关键点[101]或中心点[102]等参考信息之间的匹配, 建立参考信息的真值, 以此作为网络学习的监督信息.基于Transformer的目标检测模型拓展了以上三个过程的实现方式. 在特征学习方面, 基于Tranformer的特征构建方式可以取代卷积神经网络的角色[23]; 在区域估计方面, 基于编码器−解码器的区域估计方式也被大量尝试和验证[16]; 在真值匹配方面, DETR[16]提出了基于二分匹配(Bipartite matching)的真值分配方式, 该方法事先不依赖于位置先验信息, 而是将预测结果产生后将预测值同真实值进行匹配. 本节将从以上三个角度对基于Transformer的工作进行介绍. 表3总结了不同基于Transformer的目标检测模型在COCO[103]数据集上的性能对比.
4.1 利用Transformer进行目标检测网络的特征学习
作为特征提取器, Transformer网络具有比CNN更大的感受野和更灵活的表达方式, 因此也有望取得更好的性能以为下游任务提供高质量输入. 考虑到特征学习属于Transformer网络的基础功能,并已在第 2 节中进行了详细梳理, 因此本节将简要介绍其设计, 而更多地关注此类方法在目标检测器中的应用.
基于层级结构设计的PVT[22]、基于卷积和Transformer融合的CMT[34]、基于局部−整体交互的Cross Former[52]、Conformer[76]以及基于局部窗口设计的Swin Transformer[23]均被成功应用到了RetinaNet[104]、Mask R-CNN[99]、Cascade R-CNN[105]、ATSS[106]、RepPoints-v2[107]和Sparse RCNN[108]等典型目标检测网络中, 相比于ResNet等卷积神经网络取得了更好的效果. 这类方法基于典型的目标检测流程, 将Transformer作为一种新的特征学习器, 替代原有的卷积神经网络骨架, 从而完成目标检测任务.
4.2 利用Transformer进行目标信息估计
不同于CNN利用卷积实现对区域信息的估计和预测, 基于Transformer的目标检测网络使用了查询机制, 通过查询与特征图的注意力交互实现对目标位置、类别等信息的估计. 本小节将以DETR[16]中的目标查询机制为例介绍查询机制的作用, 并总结目前存在的问题以及解决方案. DETR的基本结构如图7所示.
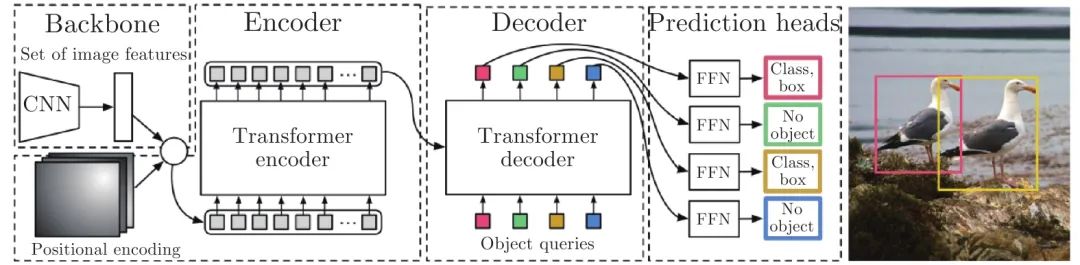
图 7 DETR的结构图[16]Fig. 7 The framework of DETR[16]
4.2.1 DETR中的目标查询机制
DETR[16]首先通过编码器提取图像特征, 之后利用随机初始化的目标查询机制来与图像特征进行交互, 以互注意力的机制进行目标级别信息的提取, 经过多层交互之后, 利用全连接层从每个目标查询中预测目标的信息, 形成检测结果.
目标查询向量包含了潜在目标的位置信息和特征信息, 其与图像特征进行交互的过程实现了从全局信息中对潜在目标特征的抽取, 同时完成了对预测位置的更新. 多个查询层的堆叠构建了一种类似Cascade RCNN[105]的迭代网络[109], 以更新目标查询的方式实现对位置和特征信息的优化. 为了清楚地介绍Transformer的设计机制, 本文将目标查询所表示的内容分成两部分, 一部分是与特征内容有关的, 记为内容嵌入(Content embedding), 一部分是与位置有关的, 记作位置嵌入(Positional embedding).
这种目标查询的方式实现了较为有效的目标检测功能, 但同时存在着收敛速度较慢[24, 110-111] (DETR需要500个轮次的训练才能收敛)、小目标检测效果不佳[24]以及查询存在冗余[113]等问题. 其中, 针对小目标检测效果差的问题, 现有文献的主要做法是利用多尺度特征[24], 通过在不同分辨率特征图上进行目标查询, 增加对小目标物体的信息表示, 以提高小目标的准确率. 针对目标查询存在冗余的现象, ACT[113]提出使用局部性敏感哈希(Locality sensitivity hashing, LSH)算法实现自适应聚类, 以压缩目标查询的个数, 从而实现更为高效的目标查询. 本小节将主要针对以DETR[16]为代表的网络收敛速度慢的问题, 分析其原因并总结提升训练速度的方案.
4.2.2 收敛速度提升
图8展示了DETR[16]以及其改进方法与基于CNN的检测器的收敛速度对比, 可以看到DETR需要长达500个轮次的训练才能得到较为稳定的效果. 其收敛较慢的主要原因在于目标查询机制的设计[24, 110-111], 本节从查询初始化、参考点估计和目标分布三个方面分析DETR的设计并总结了提升收敛速度的方法.
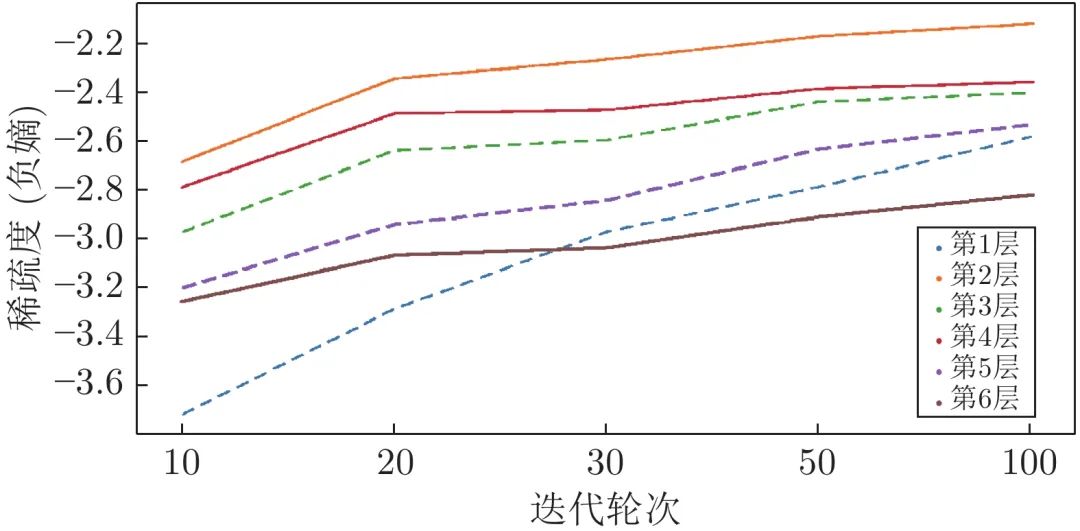
图 8 基于Transformer和CNN的目标检测器的收敛速度对比(DETR-DC5[16], TSP-FCOS[115], TSP-RCNN[115], SMCA[110], Deformable DETR[24], Conditional DETR-DC5-R50[111], RetinaNet[104], Faster R-CNN[95], Sparse R-CNN[108])Fig. 8 The comparison of converge speed among object detectors based on Transformer and CNN (DETR-DC5[16], TSP-FCOS[115], TSP-RCNN[115], SMCA[110], Deformable DETR[24], Conditional DETR-DC5-R50[111], RetinaNet[104], Faster R-CNN[95], Sparse R-CNN[108])
1) 输入依赖的目标查询初始化: DETR[16]对目标查询使用了随机初始化的方法, 通过训练时的梯度更新来实现对目标查询输入的优化, 以学习输入数据集中的物体的统计分布规律. 这种方式需要较长的过程才能实现对物体位置分布的学习, 其可视化表现为交叉注意图(Cross-attention map)的稀疏程度需要较长的训练轮次才能收敛[115] (如图9所示). 此外, 关于目标分布的统计信息属于一种数据集层面的特征, 无法实现对具体输入的针对性初始化, 也影响了模型的收敛速度.
图 9 DETR交叉注意力稀疏性变化Fig. 9 The change of sparsity of cross-attention map in DETR
为了改善由于初始化而造成的收敛速度慢的问题, TSP[115]和Efficient DETR[109]等工作提出了输入依赖的查询初始化方法, 从输入图像特征中预测潜在目标的位置和尺寸等信息, 作为初始的目标查询输入到编码器或解码器网络, 进而得到最终的目标检测结果. 其中, TSP[115]使用了CNN网络作为产生初始目标查询的途径, 借鉴FCOS[116]和RCNN[118]的思路, 分别提出了TSP-FCOS和TSP-RCNN进行图像中目标信息的估计, 并借助Transformer编码器实现对目标估计的优化; Efficient DETR[109]使用基于Transformer的编码器网络学习到的词符特征进行密集预测, 得到相应位置可能的目标的位置、尺寸和类别信息, 并选择置信度较高的结果作为目标查询的初始状态, 然后利用解码器进行稀疏预测, 得到最终结果.
TSP[115]和Efficient DETR[109]所提出的目标查询初始化方法一方面够根据不同输入得到不同的目标查询初始化结果, 是一种输入依赖的初始化方式; 另一方面, 实现了目标查询所包含的内容嵌入和位置嵌入的显式对齐, 从而较好地加速了目标检测器的收敛.
2) 输入依赖的位置嵌入更新: DETR位置嵌入的弱定位能力也是影响DETR模型收敛的主要原因之一. 在DETR[16]解码器中的多层网络中, 目标查询的内容嵌入通过交叉注意力实现对自身信息的更新, 但位置嵌入并不在层之间进行更新. 这种方式一方面导致了位置嵌入与内容嵌入的不匹配, 另一方面还导致位置嵌入难以准确表达潜在目标的准确位置信息, 使得获取位置信息的任务转移到内容嵌入中[111]. Conditional DETR[111]通过对比实验发现, 去掉解码器中第2层之后的位置嵌入信息, DETR的平均准确率仅下降0.9%, 从而说明了在原始的DETR的解码器中的位置嵌入所发挥的作用很小.
Deformable DETR[24]、SMCA[110]和Conditional DETR[111]等方法从每层输入信息中学习位置嵌入信息的更新, 能够较好地弥补DETR设计中位置嵌入定位能力不足的缺陷. 其中, Deformable DETR[24]和SMCA[110]从目标查询中预测了每个查询对应的参考点坐标, 来提高定位能力; Conditional DETR[111]利用目标查询预测二维坐标信息, 并利用内容嵌入学习对坐标嵌入信息的变换, 使位置嵌入和内容嵌入在统一空间, 进而使得目标查询和键值在统一空间, 从而提高相似性判别和定位能力.
3) 显式目标分布建模: DETR[16]使用了信息相似性度量来实现在全局范围内的目标嵌入的信息聚合, 这种方式有助于更完全地获取目标的信息, 但同时也可能引入较多的噪声干扰[24], 从而影响学习过程, 而且, 从全局信息中收敛到潜在目标的局部空间也需要较长的训练过程.
建立对潜在目标分布空间的建模机制有助于加速目标检测过程, 减少训练时间, 同时减少噪声的引入[24, 110]. 矩形分布假设是基于CNN的目标检测器的常用设计之一[95, 100], 在基于Transformer的目标检测器中, 虽然图片以序列的方式进行编码和解码, 但仍可以借助逆序列化获取二维的图片结构的数据. 并在此基础上,实现类似CNN网络中的感兴趣区域池化等操作, 以此实现对目标空间的建模. 现有对Transformer目标分布进行显式建模的方法主要有两种: 散点分布[24]和高斯分布[110].
散点分布: Deformable DETR[24]利用了散点采样实现对目标空间分布的建模. 针对每一个目标查询, Deformable DETR首先从中学习目标的参考点坐标、采样点坐标和采样点权重, 然后在若干采样点之间计算局部范围内的注意力, 并进行信息聚合. 这种方式大大减少了计算量, 同时可以较灵活地模拟目标的空间分布, 实现对于与目标查询有关联的点的聚合, 从而加速了网络的收敛过程.
高斯分布: SMCA[110]提出了一种利用高斯函数建模目标空间分布, 实现局部信息聚合的方法. SMCA首先从目标查询中学习潜在目标的位置和尺寸信息, 之后, 根据预测得到的位置和物体尺寸信息建立二维高斯分布函数, 来对近距离特征赋予较高权重, 对远距离特征赋予较低权重.
4.3 基于Transformer的目标检测模型的真值匹配
DETR[16]将目标检测建模为集合预测的问题, 并使用了二分匹配(Bipartite Matching)来为目标查询赋予对应的真值. 二分匹配利用匈牙利算法来进行快速实现. 定义: σ表示匹配策略, yi=(ci,bi)表示真实值, ci表示真实类别, bi表示标注框的值, ˆyσ(i)=(ˆpσ(i),ˆbσ(i))表示第σ(i)个预测值. 则yi与ˆyσ(i)的匹配损失为:
Lmatch(yi,ˆyσ(i))=−1{ci≠∅}ˆpσ(i)(ci)+1{ci≠∅}Lbox(bi,ˆbσ(i))(32)
最佳匹配定义为:
ˆσ=argminσ∈SNN∑iLmatch(yi,ˆyσ(i))(33)
不同于CNN中基于锚点框或关键点的真值匹配方式, 二分匹配是在得到预测结果后进行, 基本上是一种不确定性策略, 且容易受到训练过程的干扰[115], 进而导致训练过程(尤其是训练过程的早期)收敛速度较慢. 针对这个问题TSP[115]基于FCOS提出了一种新的匹配策略, 仅将落在真实标注框内的预测值或与标注框有一定重合的预测值与该真实值进行匹配, 从而加速收敛速度.
基于Transformer的图像分割模型
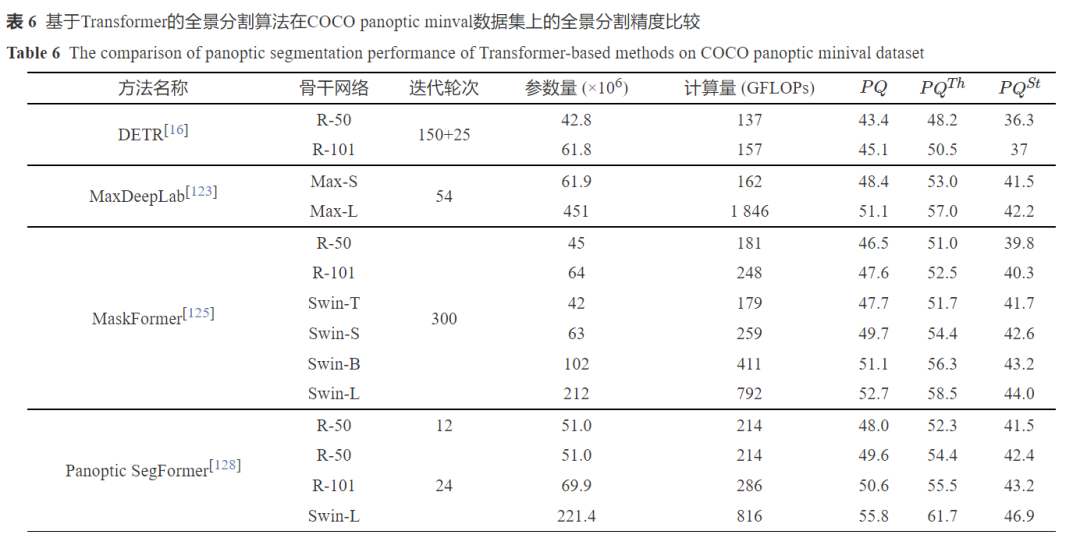
图像分割主要包括语义分割, 实例分割和全景分割[119], 近些年, 以FCN[120]、DeepLab[45]、Mask RCNN[99]等方法为代表的图像分割方法已经取得了较好的效果, 但这种基于卷积神经网络的图像分割方法在建立远程依赖上依旧存在不足. 相比之下, Transformer网络所具备的全局信息交互能力能够帮助特征提取器快速建立全局感受野, 从而实现更准确的场景理解[121]. 表4、表5和表6分别展示了基于Transformer的语义分割、实例分割和全景分割方法的结果以及其与经典CNN方法的对比. 本节将主要从特征提取、分割结果生成两个方面介绍Transformer在图像分割中的应用.

5.1 基于Transformer进行分割网络的特征学习
Transformer网络以一定尺寸的图像块作为最小特征单元, 其编码后的特征经过上采样操作就可以集成到现有的图像分割框架中. Transformer以其全局感受野和动态交互能力, 使得图像分割模型能够对图像中的上下文关系进行充分表示和建模, 从而取得更好的效果[22-23, 34, 52-53, 72, 76].
除了将Transformer集成到现有分割框架以替换CNN之外, 近期的一些工作还针对Transformer设计了新的分割框架以充分利用其在有效感受野等方面的优势[25, 121]. 其中, SETR[121]以序列学习的视角提出了基于ViT[15]的完全由自注意力机制构成的特征编码网络, 并在此基础上提出了三种解码方案(简单上采样解码器、渐进式解码器和多尺度融合解码器)产生分割结果, 打破了语义分割任务基于编码器−解码器的FCN范式, 其结构如图10所示. SegFormer[25]针对SETR柱状编码方式计算量较大以及固定位置编码不利于拓展等问题, 提出了使用具备层次结构的Transformer网络以保留粗粒度和细粒度两种特征, 并通过在自注意力中引入卷积机制来去除位置编码提高了网络灵活性. SegFormer同时指出, 基于Transformer的图像分割网络可以在仅使用较为简单的解码器的情况下,实现不错的效果, 并提出了一种仅包含数个线性层的解码器方案.
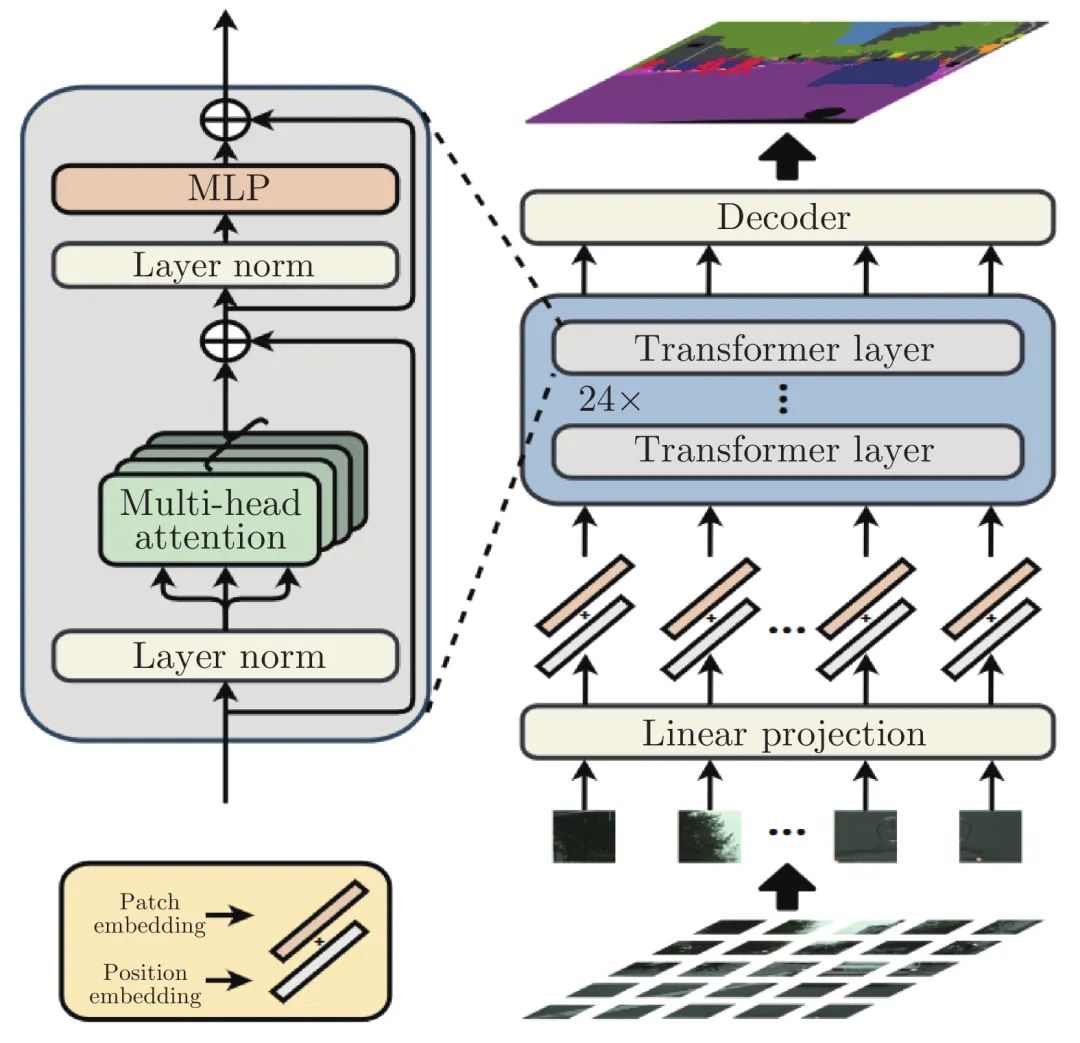
图 10 SETR的结构图[121]Fig. 10 The framework of SETR[121]
5.2 利用Transformer产生图像分割结果
像素分割和实例分割是图像分割中的两个基本任务, 在基于卷积神经网络的方法中, 前者往往基于解码器−编码器的结构产生, 后者则通常借助RCNN实现对目标级别信息的输出[119]. Transformer的出现, 尤其是其目标查询机制, 为解决图像分割提供了一种新的思路, 而且有望以一种统一的方式实现像素和实例级别的分割. Transformer的查询机制可以用来表示多种信息, 既可以表示类别信息[124]、位置信息[26, 125]同时也可以表示其他特征信息[126], 这种具备通用性的表示形式为实现统一形式的图像分割提供了基础. 本节将主要从基于目标查询的语义分割和实例分割两方面介绍Transformer给图像分割领域带来的启发和改变, 并结合全景分割, 总结以统一的方式进行图像分割的工作.
5.2.1 基于查询的语义分割方法
按照产生结果的形式, 基于查询的语义分割方法可以分为像素级预测[124]和掩码级预测[125], 前者为每一个像素输出一个类别信息, 后者则对掩码内的像素统一预测一个类别信息. 在语义分割任务中, 查询以随机初始化的方式产生, 之后通过与图像特征的交互实现对类别信息的提取, 并最终用于产生分割结果.
1) 像素级语义分割: Segmenter[124]利用类别嵌入(Class embedding)建立目标查询, 通过交叉注意力与图像序列进行信息交互, 最终利用类别嵌入与图像序列之间的注意力图进行图像块的逐像素分割结果预测.
2) 掩码级语义分割: MaskFormer[125]借鉴了DETR[16]中的集合预测思想, 提出了掩码级的语义分割思路, 其使用了Transformer和CNN两种解码器, 其中Transformer解码器基于随机初始化的查询实现对类别信息的预测, CNN解码器则通过常规卷积实现对二进制掩码信息的预测, 最后通过融合类别预测和掩码预测得到语义分割结果. 这种掩码级的语义分割结果生成方式一方面简化了语义分割任务, 另一方面能够与实例分割实现较好的统一. 在性能上, MaskFormer也验证了在类别数目较多的情况下, 基于掩码的语义分割相比于像素级分割方式在性能上更具优势.
Mask2Former[26]进一步提升了掩码级语义分割的性能和训练速度, 其基于MaskFormer[125]提出了利用多尺度特征来增强对小目标的分割能力, 同时使用了掩码注意力来关注目标局部信息, 从而加速Transformer网络的收敛速度.
5.2.2 基于目标查询的实例分割和全景分割方法
在基于Transformer的语义分割方法中[26, 125], 查询通常与类别信息相关, 而在实例分割中, 查询则往往与前景目标的位置和特征相关[126-128], 这与基于Transformer的目标检测网络中的查询机制所表示的信息基本一致[16]. 根据目标信息预测和掩码生成的顺序, 本小节将基于目标查询的实例/全景分割方法分为基于检测的分割方法和检测分割并行的方法.
1) 基于检测的实例/全景分割方法: DETR[16]在目标检测结果的基础上生成检测框嵌入, 通过与图像编码特征进行交互提取目标特征, 之后基于查询与图像特征的注意力图进行目标和背景掩码的预测. 不同于DETR[16]中将目标和背景均表示为检测框的方式, Panoptic SegFormer[128]提出区分前景目标和背景信息更有利于产生准确的背景预测. 在解码阶段, Panoptic SegFormer首先使用位置解码器针对前景目标提取目标信息, 在此基础上引入背景查询, 并利用掩码解码器产生掩码结果.
2) 检测分割并行的实例分割方法: 基于Sparse RCNN[108], QueryInst[126]和ISTR[127]提出了检测分割并行的实例分割方法. 其中, QueryInst[126]基于随机初始化的目标位置从图像中获取区域信息, 同时以随机初始化的方式生成目标特征信息, 之后通过不断地迭代, 优化查询的学习以及对目标的信息提取. 目标特征信息用于学习动态卷积的参数以实现对区域特征的动态处理, 在此基础上并行产生包围框和掩码预测. ISTR[127]同样采用了随机初始化的查询来表示目标的包围框信息, 但采用了图像特征作为产生动态卷积参数的输入. QueryInst[126]和ISTR[127]这种基于查询的迭代式预测方式降低了对目标包围框预测的要求, 使得随机初始化的目标信息依然能够在几轮迭代之后建立对目标的准确描述.
总结与展望
本文介绍了视觉Transformer模型基本原理和结构, 以图像分类为切入点总结了Transformer作为骨干网络的关键研究问题和最新进展, 并提出了视觉Transformer的一般性框架, 同时以目标检测和图像分割为例介绍了视觉Transformer模型在上层视觉任务中的应用情况. 视觉Transformer网络作为一种新的视觉特征学习网络, 在连接范围、权重动态性以及位置表示能力等方面与CNN网络有着较大的差异. 其远距离建模能力和动态的响应特质使之具备了更为强大的特征学习能力, 但同时也带来了严重的数据依赖和算力资源依赖等问题. 对视觉Transformer的效率和能力的研究仍将是未来的主要研究方向之一, 此外, Transformer模型为多模态数据特征学习和多任务处理提供了一种统一的解决思路, 基于Transformer的视觉模型有望实现更好的信息融合和任务融合.



编辑推荐




最新资讯
-
自动驾驶卡车创企Kodiak 将通过SPAC方式上
2025-04-19 20:36
-
编队行驶卡车仍在奔跑
2025-04-19 20:29
-
全国汽车标准化技术委员会汽车节能分技术委
2025-04-18 17:34
-
我国联合牵头由DC/DC变换器供电的低压电气
2025-04-18 17:33
-
中国汽研牵头的首个ITU-T国际标准正式立项
2025-04-18 17:32
