




 广告
广告





















































BEVSegFormer:一个来自任意摄像头的BEV语义分割方法

2022年3月arXiv论文“BEVSegFormer: Bird’s Eye View Semantic Segmentation From Arbitrary Camera Rigs“,作者主要来自上海的自动驾驶创业公司Nullmax。

BEV的语义分割是自动驾驶的一项重要任务。尽管这项任务已经吸引了大量的研究工作,但灵活处理自动驾驶车辆上安装的任意(单个或多个)摄像头传感器仍然是一个挑战。本文提出一种基于Transformer的BEV语义分割方法,BEVSegFormer。具体来说,该方法首先使用共享主干对来自任意相机的图像特征进行编码。然后,这些图像特征通过基于变形Transformer的编码器进行增强。此外,引入BEV transformer解码模块来解析BEV语义分割结果。设计了一种高效的多摄像机变形注意单元,实现了从BEV到图像视图的转换。最后,根据BEV中网格的布局对查询(queries)进行重塑,并进行上采样,以有监督的方式生成语义分割结果。
在自动驾驶或机器人导航系统中,感知信息BEV表示非常关键,因为它便于规划和控制任务。例如,在无地图导航解决方案中,构建本地BEV地图提供了HD地图的替代方案,对于感知系统的下行任务(包括智体行为预测和运动规划)非常重要。摄像头的BEV语义分割通常被视为构建局部BEV地图的第一步。
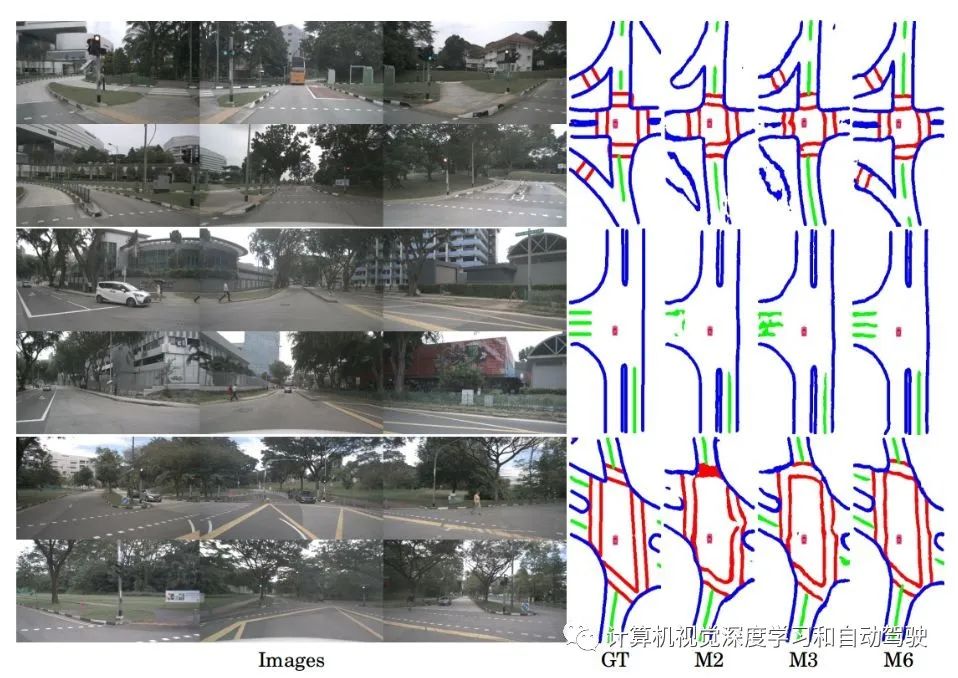
为了从摄像机中获得BEV语义分割,传统方法通常在图像空间中生成分割结果,然后通过IPM(inverse perspective mapping)函数将其转换为BEV空间。虽然IPM是连接图像空间和BEV空间的一种简单而直接的方法,但它需要精确的摄像机内外参数或实时的摄像机姿态估计。因此,它很可能会产生较差视图转换。以车道分割为例,如图所示,使用IPM的传统方法在存在遮挡或距离较远的情况下会产生不准确的结果:(a) 图像空间的车道分割,(b)通过IPM,对(a)做视图变换进行BEV分割,(c)BEV车道分割。

如图显示BevSefFormer方法的概述。它由三部分组成:(1)一个用于处理任意相机和输出特征地图的共享主干网;(2) 使用Transformer编码器增强特征表示;(3)BEV Transformer解码器通过交叉注意机制处理BEV查询,然后把输出查询解析为BEV语义分割。
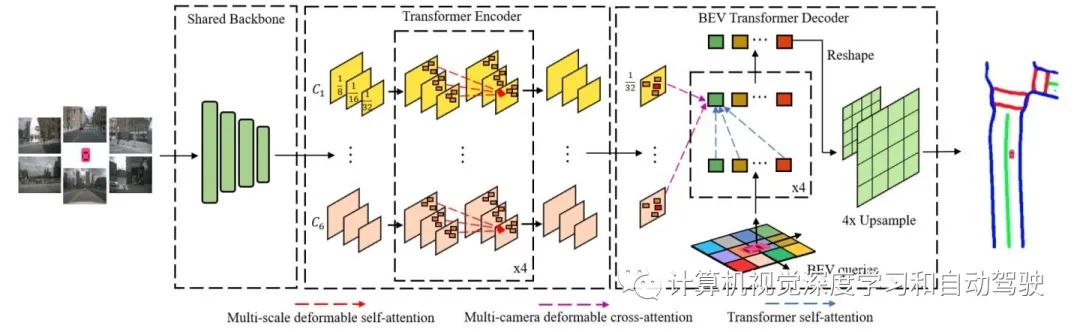
对于单个输入图像,主干接收输入并输出多尺度特征图。对于多个摄像头配置,这些多个图像共享同一主干,并输出相应的特征图。实验中以ResNet为骨干。
在transformer编码器中,首先在共享主干的c3、c4、c5级特征上应用1×1 卷积运算符,以获得多尺度特征。在每个摄像头生成的特征地图上分别应用Deformable Attention模块。它不需要计算致密注意图,只关注参考点附近的一组采样点。transformer编码器为每个摄像头输出增强的多尺度特征。
BEV transformer解码器包括一个transformer解码器,用于计算BEV查询和多摄像头特征图之间的cross attention,以及一个语义解码器,用于将查询解析为BEV分割结果。
在transformer解码器中,在2D BEV空间上构造查询,然后将这些BEV查询视为在cross attention模块的常规查询。只使用多尺度特征图的最小分辨率(原始输入分辨率的1/32)作为transformer解码器的输入。
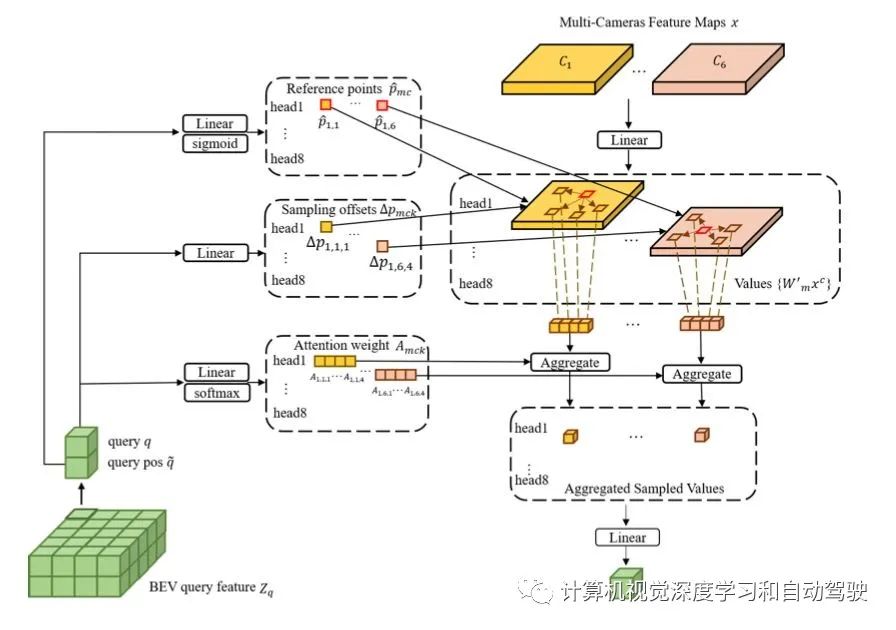
将可变形DETR中的Deformable Cross-Attention 模块调整为多摄像头Deformable Cross-Attention 模块,该模块能够将多摄像头的特征图转换为BEV查询,不需要摄像头的内外参数。
如图是BEV Transformer解码器中的多摄像头Deformable Cross-Attention 模块:
在语义解码器中,对BEV查询特征进行了重塑,即从transformer解码器转换为二维空间特征。二维空间特征由BEV Upsample模块(一个标准语义Upsample模块)处理,计算语义分割结果。BEV Upsample模块的每一级由3×3卷积、1×1卷积和2×双线性插值运算组成。
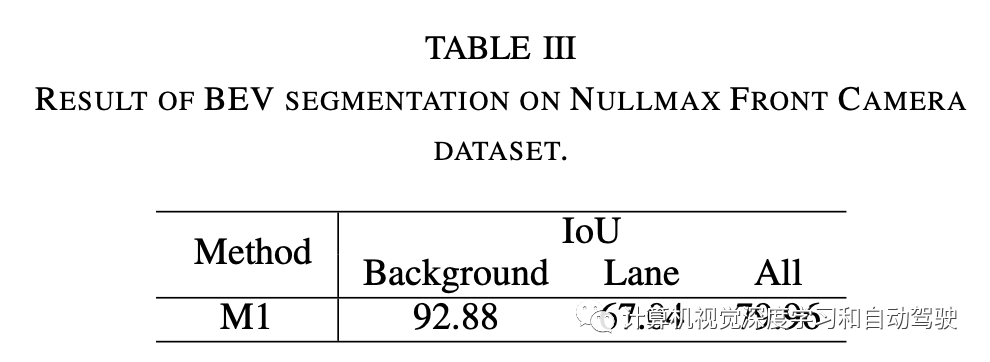
Nullmax除了nuScenes数据集之外,从上海高速公路收集了一个数据集,其中配备前置摄像头。该数据集包括各种场景,如人群交通、进出匝道、阴影、换道和切入。该数据集分为3905张训练图像和976张验证图像。对车道线进行标注进行评估。
在nuScenes数据集上使用相同的HDMapNet设置进行实验。利用高清地图自车定位来确定BEV的区域。在周视摄像头,将BEV设置为车辆周围[-30m,30m]×[-15m,15m]区域。只有前视摄像头的情况下,BEV区域才会设置为[0m,60m]×[-15m,15m]。道路结构表示为5像素宽的线段。真实数据掩码设置为400×200。按照STSU(“Structured bird’s-eye-view traffic scene understanding from onboard images, ICCV‘2021)做法,采用448×800大小图像作为网络的输入。同样,Nullmax前置摄像头数据集中的BEV区域设置为[0m,80m]×[-10m,10m]。真实数据掩码为512×128,而车道宽度为3像素。Nullmax数据集上的输入图像大小为384×640。
遵循可变形DETR的方法做网络设计。实验中使用了[1,15,15,15]的加权交叉熵损失。M=8和K=16是为BEV transformer解码器的多摄像头deformable attention所设置。所有transformer模块中的嵌入尺寸设置为256,FFN模块的特征尺寸设置为512。
应用数据增强方法,包括随机水平翻转、随机亮度、随机对比度、随机色调和随机交换通道。网络由AdamW优化器优化,权重衰减为10e−4。主干和transformer的初始学习率设置为10e−5, 10e−4,在第100 epoch减少到10e−6和10e−5。在4个RTX 3090 GPU上训练模型,每个GPUbatch size为1。所有模型都从零开始训练,共有120 epochs。
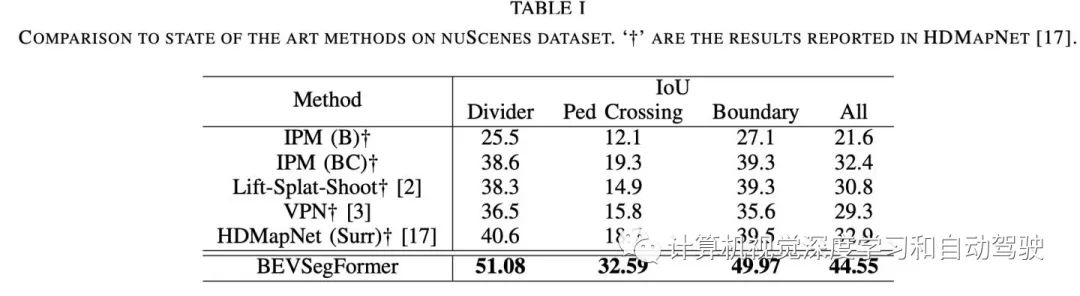
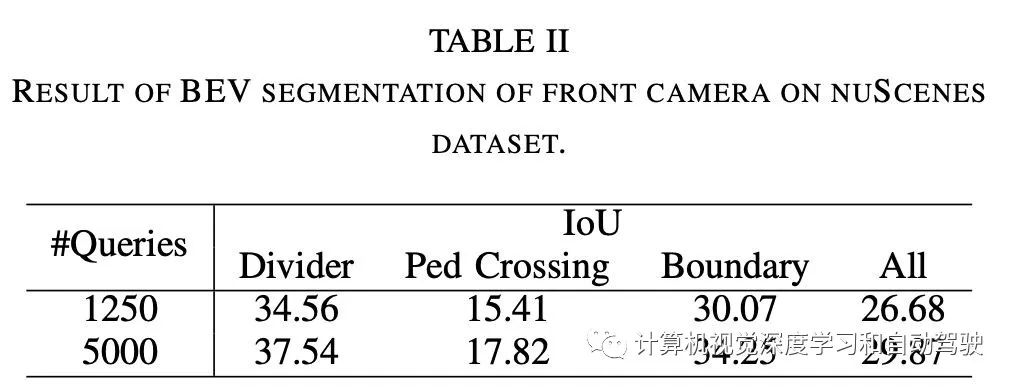
实验结果如下:




编辑推荐




最新资讯
-
全国汽车标准化技术委员会汽车节能分技术委
2025-04-18 17:34
-
我国联合牵头由DC/DC变换器供电的低压电气
2025-04-18 17:33
-
中国汽研牵头的首个ITU-T国际标准正式立项
2025-04-18 17:32
-
为什么要进行汽车以太网接收测试?汽车以太
2025-04-18 17:26
-
产品手册下载 | NI 全新USB数据采集-NI mio
2025-04-18 16:39
