




 广告
广告





















































自动驾驶的智体重要性预测:重要性就是我们注意的

2022年4月22日arXiv上传的论文“importance is in your attention: agent importance prediction for autonomous driving“,作者来自Motional(Aptiv和Hyundai的合资公司)。

轨迹预测是自动驾驶中的一项重要任务。最新轨迹预测模型通常使用注意机制来模拟智体之间的交互。这些预测模型通常还包括交互图的自车,以便对其他智体和自车之间的交互进行建模。除了预测未来轨迹之外,这些预测的下游,运动规划模块,也可以从了解另一个智体可能影响自车未来机动的程度受益。有了这些知识,运动规划器模块可以将其计算资源集中在处理更重要的智体上,并可能粗粒度处理重要性较低的智体。
本文展示此类模型的注意信息也可用于衡量每个智体相对于自车未来规划轨迹的重要性。作者提出了一种简单的方法来预测其他智体的重要性得分,无需任何额外的训练标注,因为大多数最新轨迹预测模型已经使用内置的注意机制来模拟智体之间交互。通过一系列实验,发现自车和其他智体之间的注意权重可以自然地代表其他智体对自车预测机动性的影响程度。在Motional公司自己的nuPlans 数据集实验结果表明,该方法可以根据其对自车规划的影响大小来有效地排名周围智体。
这里顺便介绍最近4个相关论文:
-
“Multimodal Motion Prediction with Stacked Transformers“, CVPR 2021
-
“Scene Transformer: A Unified Architecture For Predicting Multiple Agent Trajectories“,ICLR,2022
-
“GOHOME: Graph-Oriented Heatmap Output for future Motion Estimation“,September,2021
-
“THOMAS: Trajectory Heatmap Output With Learned Multi-Agent Sampling“,ICLR,2022
智体重要性预测通常用于自动驾驶,采用人工标注的真值重要性分数来计算。这些标注不仅成本高昂,而且由于主观性,标注质量也难以控制。
轨迹预测任务在给定历史轨迹和地图信息的情况下预测一组智体的未来轨迹。由于智体行为还取决于其他智体的状态,因此轨迹预测模型在预测时,对智体之间交互进行建模是很重要的,而图注意机制(graph attention)是建模的最流行方法。
Uber的LaneGCN,是比较公开的图注意机制建模方法,另外还有改进的GOHOME和THOMAS方法。谷歌WayMo的VectorNet,则采用了Transformer注意机制,后来的改进包括mmTransformer和Scene Transformer。下面简单回顾以下4个最近算法架构。

这是香港大学和商汤的论文,提出了一种用于多模态运动预测的新型Transformer框架,称为 mmTransformer。一种基于堆叠Transformer的新型网络架构,旨在用一组固定的独立提议对特征级的多模态性进行建模。然后一个基于区域的训练策略提出来诱导生成提议的多模态性。在 Argoverse 数据集上的实验表明,所提出的模型在运动预测方面达到了最佳的性能,大大提高了预测轨迹的多样性和准确性。
演示视频和代码在 Multimodal Motion Prediction with Stacked Transformers 获得。
如图所示:mmTransformer聚合了固定轨迹提议的上下文信息,而提议特征解码器进一步通过轨迹生成器和选择器,分别解码每个提议特征,生成轨迹和相应的置信度分数。此外,轨迹生成器和轨迹选择器是两个前馈网络,与Transformer的FFN具有相同的结构。
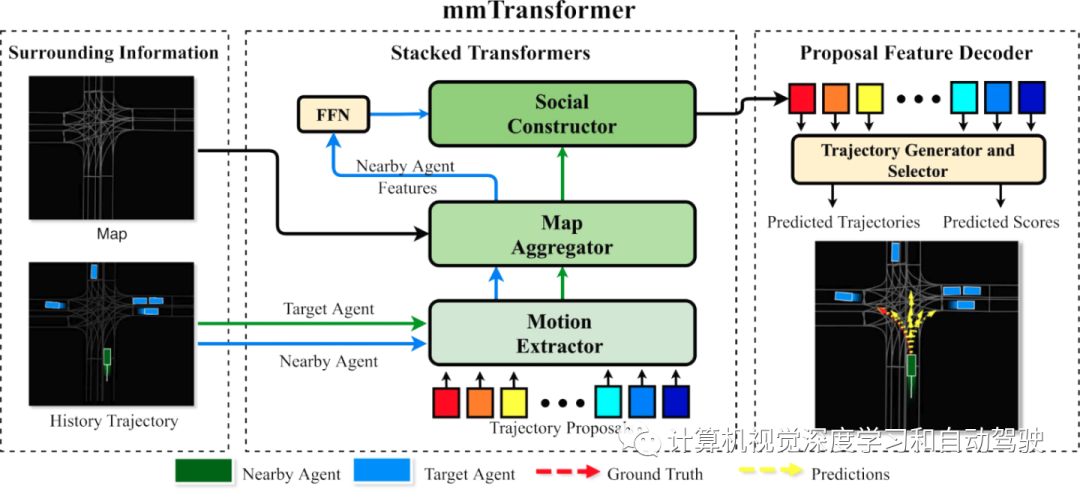
其中Transformer的架构细节如下:
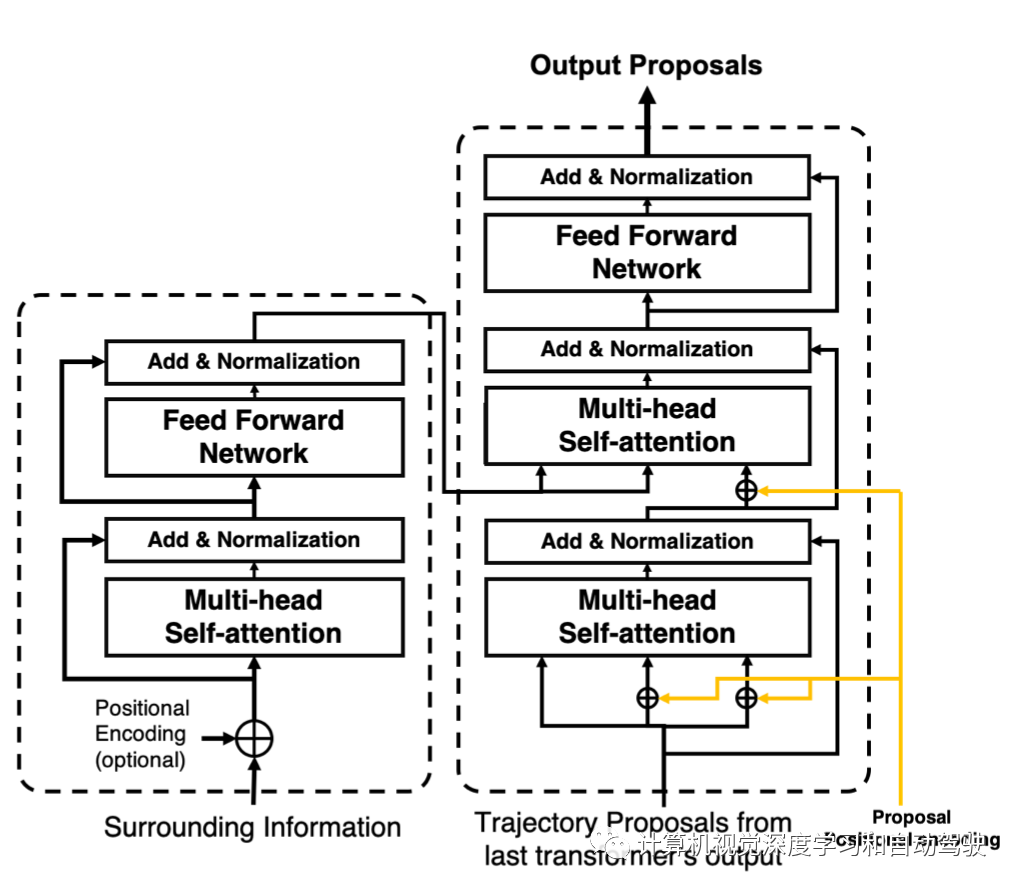
这个设计背后的动机是建立数据内部的内部关系(例如,使用地图编码器提取地图拓扑信息),并渐近地整合来自不同编码器的上下文信息,更新每个提议并突出其预指定的模态。
所有轨迹提议的直接回归导致模式平均问题,这阻碍了模型的多模态性。克服模式平均问题的一种可行解决方案是仅使用具有最小最终位移误差的提议来计算回归损失和分类损失。然而,当提议数量增加以提高多样性时,就会出现模态崩溃问题。
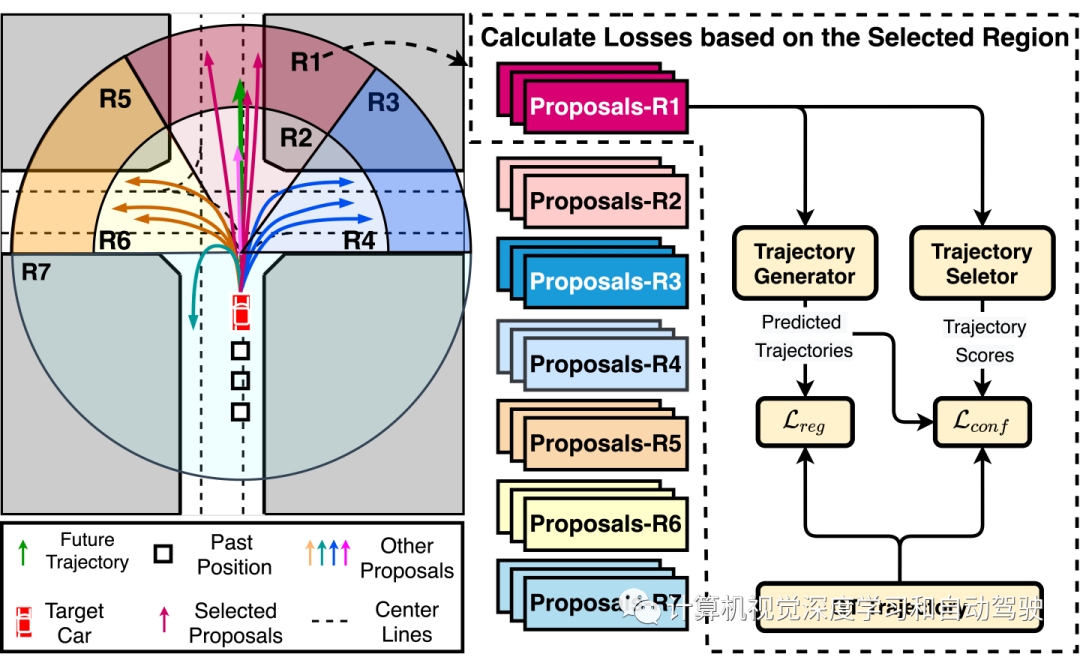
为此提出了一种训练策略,称为基于区域的训练策略(RTS),根据真实端点的空间分布将轨迹提议分到几个空间聚类中,并优化框架以改善每个聚类的预测结果。如图所示:首先将每个提议分发到 M 个区域的一个,这些提议以彩色框显示,通过 mmTransformer 学习相应的提议特征;然后,选择已经分配给真实端点所在区域的提议,生成轨迹以及相关置信度分数,并计算损失。

这是谷歌Waymo的论文,制定了一个模型来联合预测所有智体行为,产生一致未来解释智体之间的交互。受最近语言建模方法的启发,作者用掩码(masking)策略对模型查询,用单个模型以多种方式预测智体行为,例如,自动驾驶车的目标,或完整的未来轨迹,或者环境中其他智体的行为。该模型架构采用注意机制来组合道路元素、智体之间交互和时间步长等特征。
产生联合未来预测的一种简单方法是考虑边际化智体预测的组合指数量。许多组合并不一致,尤其是当几个智体会具有重叠轨迹。而谷歌提出的一个统一模型,能自然地捕获智体之间的交互,并且可以作为一个联合模型进行训练,所有智体产生场景级的一致预测。
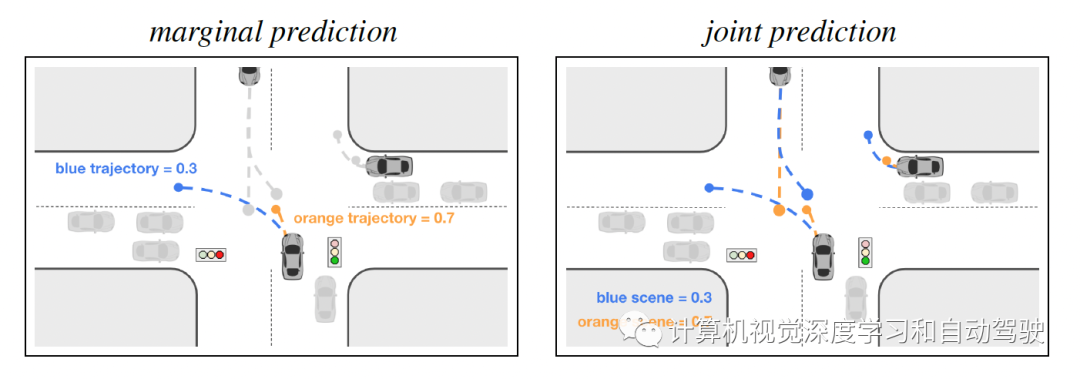
如图是边际化(marginal)运动预测和联合(joint)运动预测之间差异,每种颜色代表一个不同的预测。左:底部中心车辆的边际化预测,分数表示轨迹的似然(注:预测独立于其他车辆轨迹);右:三辆感兴趣车辆的联合预测,分数表示三辆车轨迹构成整个场景的似然。
该模型对所有智体使用以场景为中心的表征,允许扩展到密集环境的大量智体。其采用一种简单的自注意变型,其中注意机制沿着智体-时间轴有效分解。由此产生的架构,只是在表示时间的维度和场景的智体之间交替注意,从而产生计算效率高、统一且可扩展的架构。其记作Scene Transformer。
Scene Transformer 模型分为三个阶段:(i)将智体和路图嵌入高维空间,(ii)用基于注意的网络来编码智体和路图之间交互,(iii)用基于注意的网络解码多个未来预测。该模型将每个智体在每个时间步的特征作为输入,并预测每个智体在每个时间步的输出。其采用关联掩码(associated mask),其中每个智体时间步长都有一个关联indicator 为 1(隐藏)或 0(可见),指示输入特征是否在模型中被隐藏(即移除)。这种方法反映了 BERT 等掩码语言模型的方法。该方法非常灵活,能够同时训练一个运动预测 (MP) 模型,条件运动预测(CMP)和目标条件预测 (GCP) ,只需更改给模型显示的数据。
如图所示是用于多个运动预测任务的单一模型架构。左图:不同的掩码策略定义不同的任务,左列(column)代表当前时间,顶行(row)代表指示做自动驾驶车 (AV) 的智体。通过将掩码策略与每个预测任务相匹配,可以针对与运动预测、条件运动预测和目标导向预测等相关的数据去训练单个模型。右图:用于联合场景建模的基于注意编码器-解码器架构。架构沿时间轴和智体轴采用分解注意来利用数据的依赖关系,并使用交叉注意注入辅助信息。

该文来自法国华为和一所高校MINES ParisTech,GOHOME是一种利用高清地图的图表征和稀疏投影生成热图输出的方法,该输出表示给定智体在交通场景中的未来位置概率分布。该热图输出产生智体未来可能位置的无约束2-D网格表示,允许固有的多模态性和预测不确定性度量。这种面向图的模型避免了两方面带来的高计算负载:1)周围上下文表示为平方图像;2)经典 CNN 处理。而是只关注智体在不久将来可能所在的最可能车道。
作者之前的工作是HOME,其使用概率热图作为模型输出进行轨迹预测,但用全卷积模型,并且仅限于有限的图像大小。GOHOME对此进行迭代,提出一个仅基于图操作优化的运动预测框架,用高清地图矢量化形式有效地提供不确定性的热图。热图输出适用于模型集成,没有模式崩溃的风险。
如图是GOHOME流水线:从高清地图中提取的Lane Graph通过图编码器进行处理,然后每个车道生成一个局部曲线栅格,该栅格被组合成一个预测概率分布的热图。
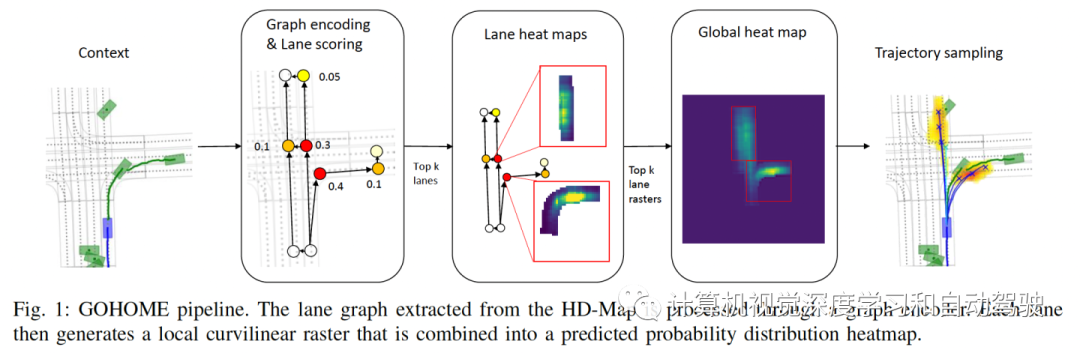
局部HD Map 是 L 个LaneNet的图。Lanelet 代表道路的宏观路段(平均 10 到 20 米),因为目标是在宏观级别(车道段)而不是微观级别(每米)对连通性进行编码。每个lanelet 被定义为一系列中心线(centerline)点,并连接到它的前任、后继和左右邻居(如果存在)。将每个lanelet 编码为一个道路图,其表征了几何和连接信息。模型为每个LaneNet一个分数,用于识别最可能的车道。然后,为排名靠前的lanenet生成一个部分热图,并将其投影到全局热图。之后,从热图中采样一组端点,并为每个端点重建一个轨迹。
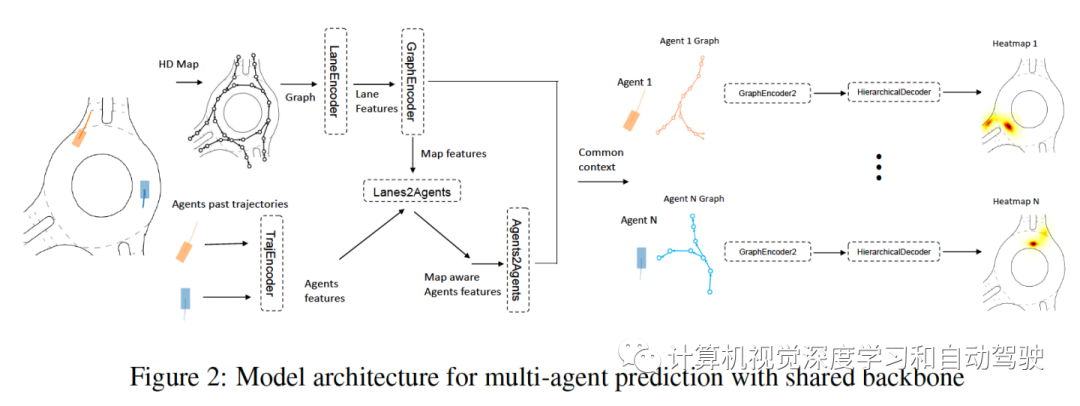
如下是GOHOME的模型架构图:LaneEncoder、TrajEncoder、GraphEncoder、Lanne2Agents、Agents2Agents、GraphEncoder2和Lanes2Rater等。
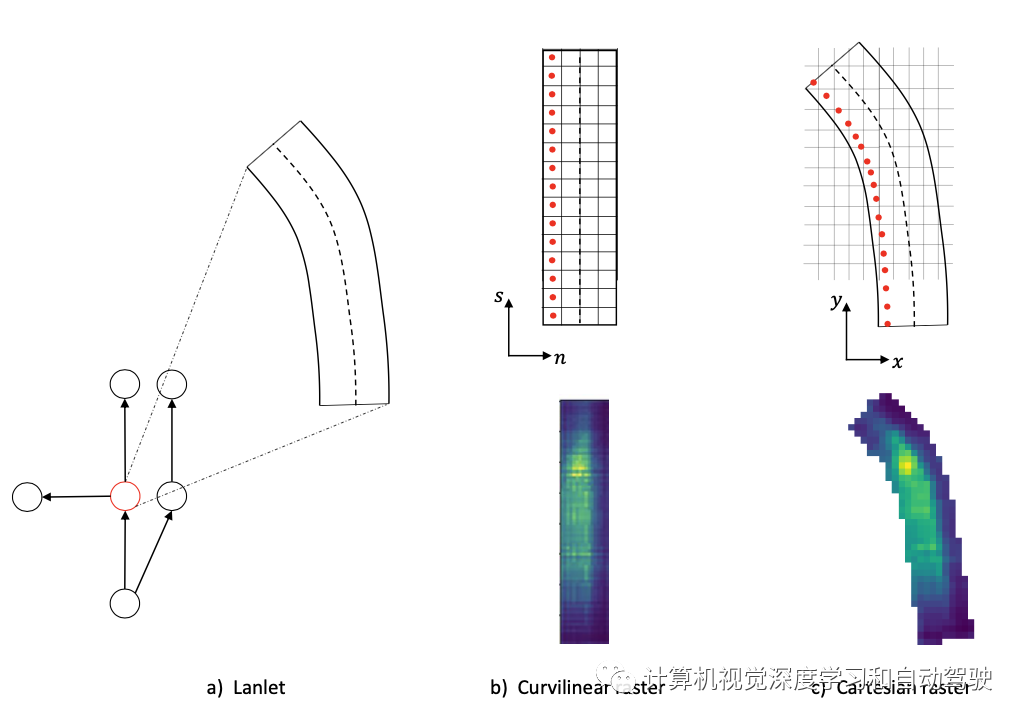
热图输出,在笛卡尔坐标中得到一个密集的图像,尺寸为 (H,W)。为此,在整个图像上不用任何卷积,为曲线坐标的每个lanenet创建一个栅格。车道排名,为前 k 个lanenet而不是全部,生成车道栅格。
如下所示:a) 图的单个节点是一个lanelet,描述了一个路段;b) 沿lanelet 的曲线坐标生成一个矩形栅格。c) 然后用lanelet 坐标将预测的栅格投影回笛卡尔坐标,完成最终的热图输出。

该论文也是来自法国华为研发和高校MINES ParisTech,THOMAS,是一种联合多智体轨迹预测框架,允许对多智体多模态轨迹进行有效且一致的预测。所提出的是一个同时估计智体未来预测热图的统一模型架构,其中用分层和稀疏的图像生成做快速和内存有效的推理。这是一个可学习的轨迹重组合模型,将每个智体的一组预测轨迹作为输入,输出其一致重排序的重组合。这个重组合模块,能够重新对齐最初独立的模态,这样不会发生冲突并且彼此保持一致。
目标是由 H 时间步长的过去历史和高清地图上下文预测 A 智体的未来 T 时间步长。将问题分为基于目标的预测和全轨迹重建。预测流水线如图所示:首先将每个智体轨迹和高清地图上下文图编码为一个通用表征。然后,场景中的每个智体解码未来概率热图,其中启发式采样最大化覆盖范围。最后,采样的端点重新组合成跨智体的场景一致模式,并为每个智体构建完整轨迹预测。
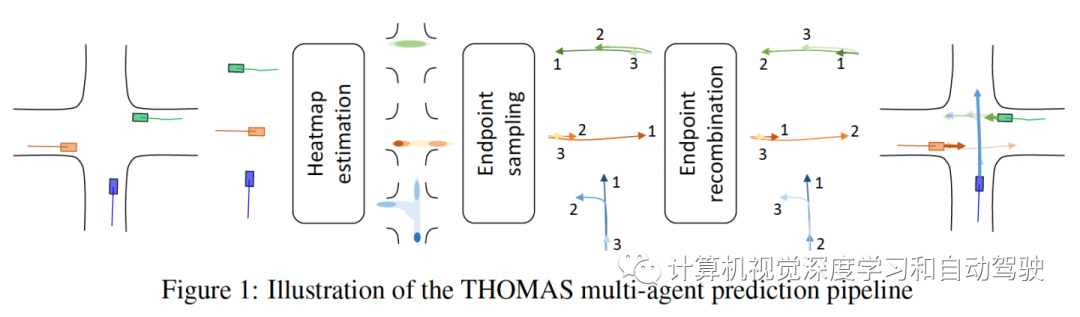
Thomas的流水线与 GOHOME共享相同的图编码器、采样算法和完整轨迹生成,但用了一种高效分层热图过程,可以扩展到同时进行多智体预测。此外,添加了一个场景一致性模块,将边际化预测输出重新组合成联合的预测。
如图就是这个共享主干网的多智体预测模型架构图:编码器和GOHOME模型是一样的
目标是将每个智体编码输出解码为一个热图,表征其在预测范围 T 的未来概率分布。由于为场景中的每个智体创建此热图,解码过程必须快速,以便并行应用于大量智体。用不同分辨率的分层预测,解码器有可能预测智体的整个环境,只在智体高概率存在的地方学习做更精确细化。
网格概率的分层迭代细化如图所示:首先,以非常低的分辨率评估整个网格,然后对概率最高的单元进行上采样并以更高的分辨率评估,直到达到最终分辨率。其中灰色突出显示在每个步骤中考虑细化的受限区域。
多模态多智体预测的困难在于每个智体之间的模态一致。由于模态被认为是按场景的,因此每个智体的最可能模态必须与其他智体的最可能预测相匹配,依此类推。此外,这些模态不能相互冲突,应该代表现实场景。
最初,模型的预测输出可以定义为边际化,因为所有 A 智体都已被独立预测和采样,分别获得 K 个可能的端点。目标是从边际化预测 M = (A, K) 中输出一组场景预测 J = (L, A),其中属于 J 的每个场景模态 l 是每个智体 a 的端点关联。为了实现这一点,主要假设在于,良好的轨迹提议已经存在于边际化预测中,但需要在智体之间连贯对齐,以实现一组整体一致的场景预测。对于给定的智体 a,为场景 l 选择的模态将是该智体可用边际化模态的组合。每个场景模态 l 将选择智体之间不同的关联。
如图所示是THOMAS场景模态的生成过程:
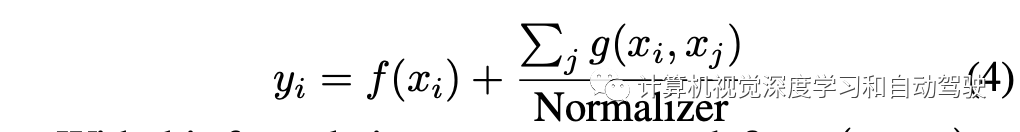
现在回到Motional这篇文章,LaneGCN中Agent-to-Agent的注意模块即
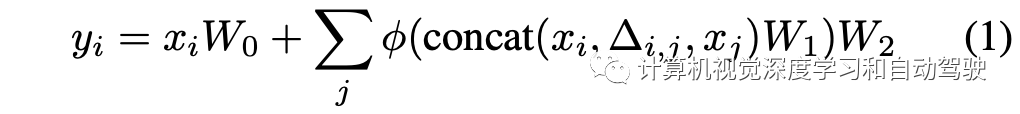
而Transformer的注意模块即
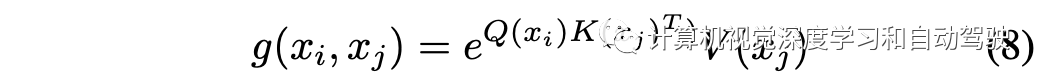
为其他智体和自车之间的交互进行建模,预测模型通常将自车包含在交互图(interaction graph)中,与其他智体相同的方式预测自车的未来轨迹。
在轨迹预测模型的agent-to-agent交互模块中,智体对自车的注意权重可计算智体的重要性得分。该模块的主要输入是场景中所有N个参与者的特征向量,表示为{xi}。该模块的输出是参与者交互建模的输出特征向量,表示为{yi}。
当交互模块只有一个注意层时,它通常具有这样一个特性,即每个智体j对另外一个智体i的贡献用函数g计算,然后相加到一起。
注意向量,并用L2-norm作为从agent j到agent i的重要性分数,这表示agent j对agent i未来轨迹预测的影响度。
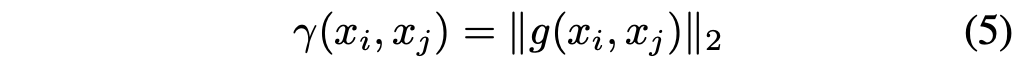
该公式概括了大多数最新轨迹预测工作所使用的注意模块,包括LaneGCN、GOHOME和THOMAS中使用的LaneGCN注意模块,以及VectorNet和Scene Transformer中使用的Transformer注意模块。
这里LaneGCN注意模块的注意向量是:
而Transformer的注意可扩展为:
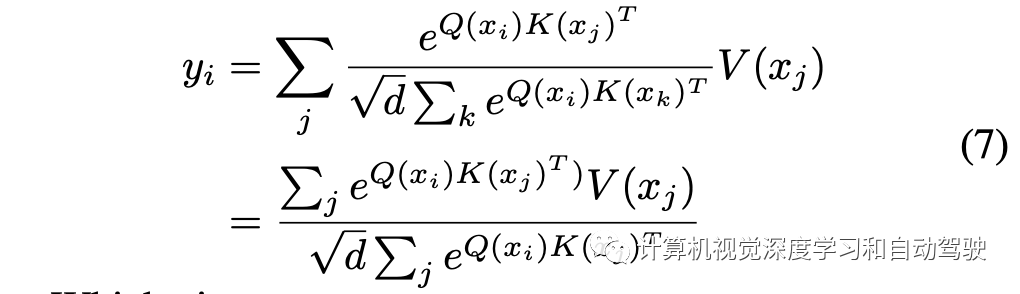
这样得到注意向量
当交互模块中有多个注意层时,可以计算每个注意层的智体重要性分并将其聚合。
Motional公司建立了一个基于ML闭环的运动规划器基准(“nuPlan: A closed-loop ML-based planning benchmark for autonomous vehicles“,February,2022),这里作者基于nuPlan训练集让模型学习,而运行模型选了验证集2000个样本。下表是nuPlan和其他数据集的比较:
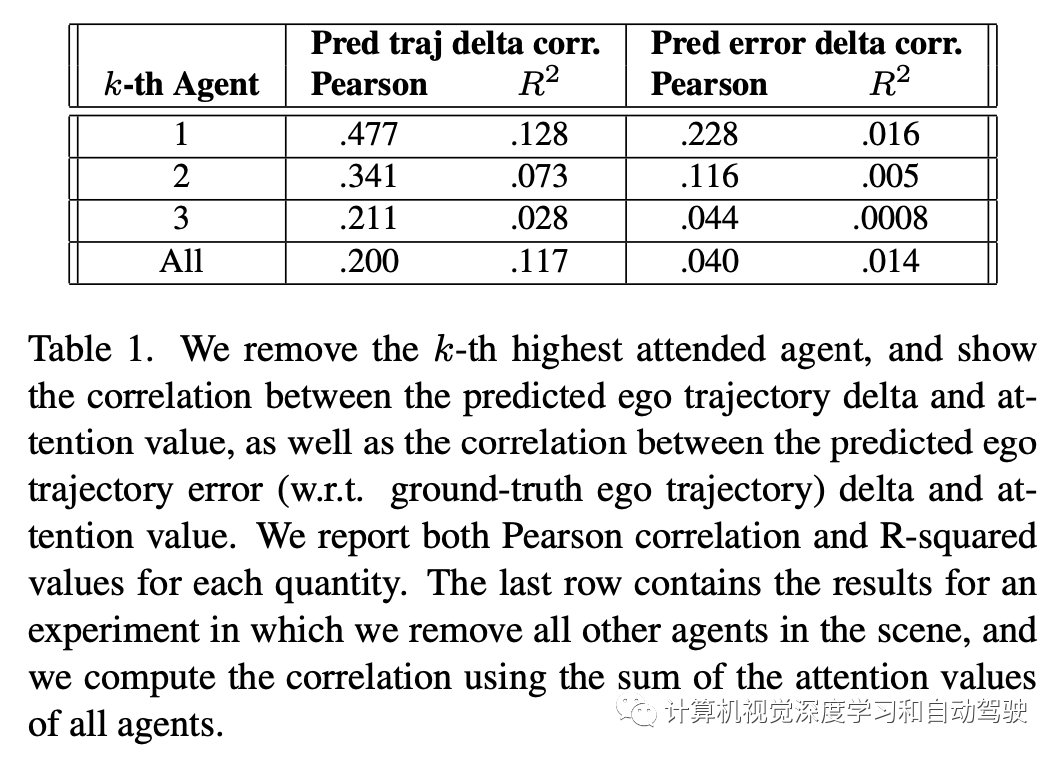
如下表是实验结果:分析三个方面
-
智体注意和自车行为变化的相关性
对被移除智体的归一化注意值(即重要性分数),和移除前后的自车轨迹预测逐点L2距离,计算一下这二者之间的相关性,以及在移除前后预测L2误差(相对真值自车轨迹)变化量的相关性。报告每个数量的Pearson相关性和R-平方值。R-平方值对应于线性模型中相关变量所解释的方差量。
表的最后一行删除了所有其他参与智体,尽管删除了大部分注意,其显示了与其他每行相关的Pearson相关性降低。Pearson相关性很小的事实表明,总体而言,移除的注意不如其他单一注意移除中相同数量的注意有效。考虑到Pearson相关性随等级降低,我们可以得出结论,我们的模型正确地将更多注意放在了最重要智体上。
-
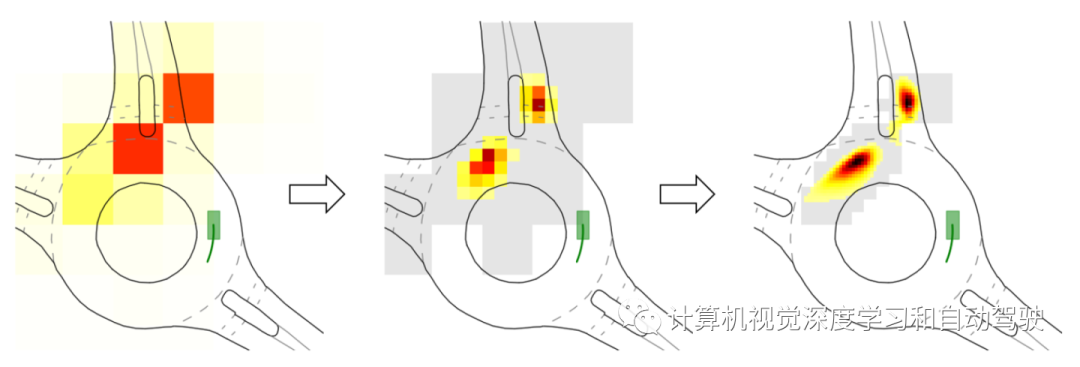
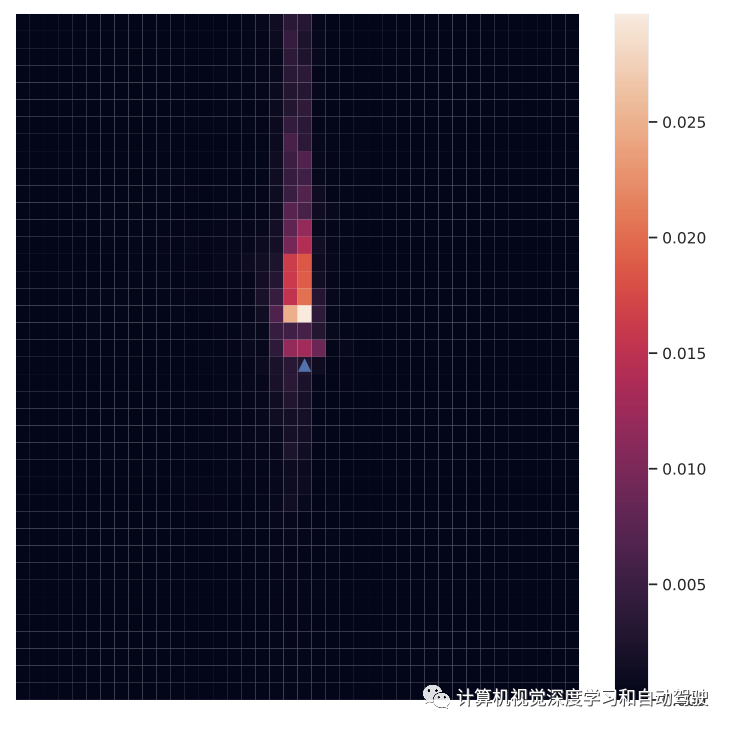
空间注意分布
如图所示,在以自车为中心的坐标系中绘制了每4×4m块的平均标准化注意值分(即重要性分数)。可以看到,大多数注意都集中在自车前面的智体身上,因为这些智体的未来行为很可能会导致自车的行为有所不同。相比之下,通常很少有人关注自车背后的人,因为他们的存在通常不会影响自车的行为,除非自车需要调整其路径以避免未来与背后的代理人发生碰撞。
-
多层注意
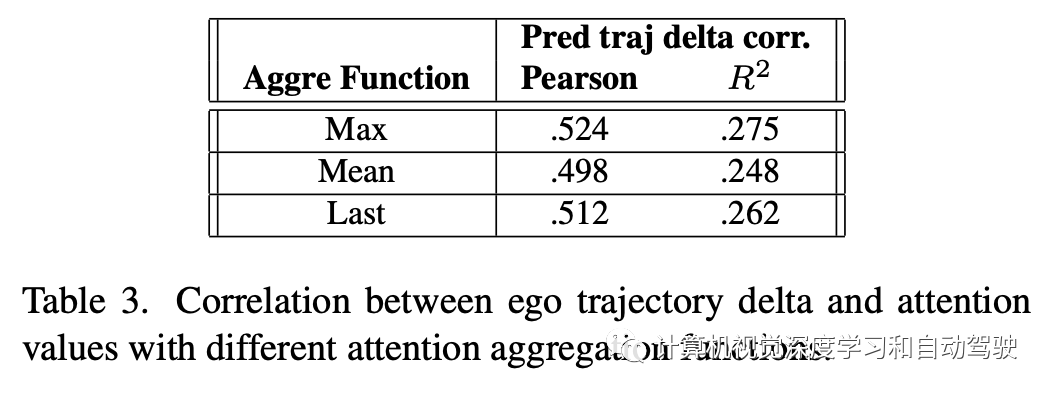
本实验中,比较不同的聚合函数,以聚集来自多个注意层的注意值分(即重要性分)。如表是三个聚合函数进行比较:1)所有层之间的最大注意,2)所有层之间的平均注意,以及3)仅使用最后一层的注意。比较自车轨迹增量和重要性得分之间的相关性,结果表明,这三个函数产生的结果相似,这意味着该方法对聚合函数的选择具有鲁棒性。
- 下一篇:基于声品质贡献因子的发动机悬置优化
- 上一篇:18届NVH控制大会:机遇、挑战和应对



编辑推荐




最新资讯
-
大卓智能端到端直播实测,16公里复杂路段挑
2025-04-25 17:16
-
《汽车轮胎耐撞击性能试验方法-车辆法》等
2025-04-25 11:45
-
“真实”而精确的能量流测试:电动汽车能效
2025-04-25 11:44
-
GRAS助力中国高校科研升级
2025-04-25 10:25
-
梅赛德斯-AMG使用VI-CarRealTime开发其控制
2025-04-25 10:21
