




 广告
广告





















































SHAIL:带安全-觉察的城市环境自动驾驶分级对抗模仿学习

arXiv上2022年4月上传论文“SHAIL: Safety-Aware Hierarchical Adversarial Imitation Learning for Autonomous Driving in Urban Environments“,作者来自斯坦福大学和德国KIT。

生成模仿学习是通过现实世界和模拟决策来自动制定策略的一种方法。以前生成模仿学习应用于自动驾驶策略的工作,侧重于学习简单设置的低级控制器。然而,为扩展到复杂设置,许多自动驾驶系统,将固定、安全、基于优化的低级控制器与能选择适当任务和相关控制器的高级决策逻辑相结合。
本文试图用Safety-Aware Hierarchical Adversarial Imitation Learning(SHAIL)来弥合这种复杂性差距,SHAIL是一种学习高级策略的方法,以带策略(on-policy)模仿低级驾驶数据的方式从一组低级控制器实例中进行选择。该文引入一个城市环形交叉路口模拟器,该模拟器用来自在伯克利开源Interaction数据集的真实数据来控制非自车。
实现代码可见在 https://github.com/sisl/InteractionImitation。
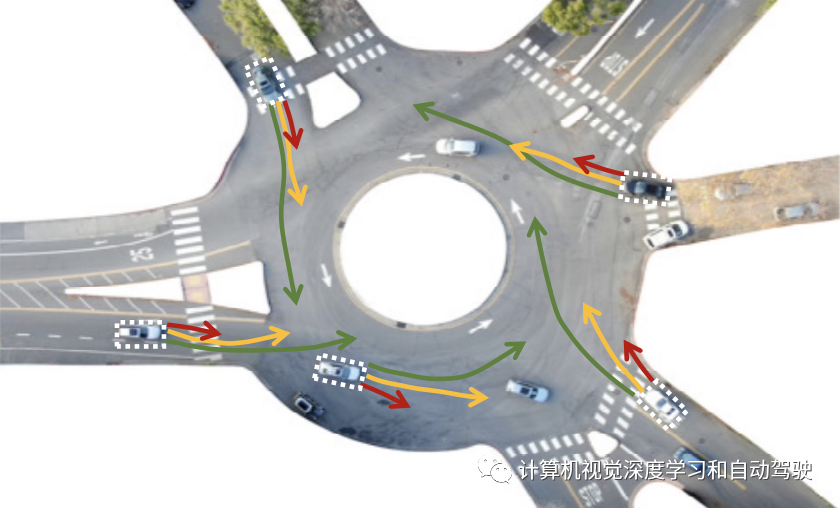
下图是示意图:通过SHAIL,自车学会从一组安全高级选项中进行选择,Interaction数据集所派生的复杂驾驶环境进行导航。这里可学习的只有低级专家状态和动作。
最优决策一般在MDP环境定义,包括状态空间、动作空间和状态转移函数,以及奖励函数、初始状态分布和discount系数γ。MDP的策略通过动作影射状态到一个分布,一个最优策略最大化累计discounted奖励。在强化学习设置中,确切的转换和奖励函数 T 和 R 是未知的,但可以与环境交互,接收下一状态和奖励生成的样本。
在模仿学习设置中,不接收奖励信号,而是依赖于与环境交互的专家以轨迹推出的形式提供数据。模仿学习问题可以看作是专家和学习者分布之间的时刻匹配(moment matching)问题,方法可以大致描述为以下几种:无策略(off-policy)的Q-价值时刻,带策略的Q-价值时刻或奖励时刻。
在模仿学习设置中学习策略的最直接方法是通过行为克隆 (BC),其中受监督的学习者将状态回归动作。这种方法在自动驾驶系统中有着悠久的历史。行为克隆在测试过程中会有错误的累积,因为智体最终会进入训练期间未见过的状态,这种现象通常被称为协变量移位(covariance shift)。
在某策略π下的状态-动作占用度量,是访问状态和动作的(非规范化)γ- discounted平稳分布。同样地,也可以定义专家策略的状态-行动占用度量。一种观点将模仿学习表述为专家和学习的占用度量之间的时刻匹配问题,其通过最小化相关分布之间的一些f-散度来实现。在带策略奖励时刻匹配设置中,这个目标(objective)可以写成带策略生成器和观测-动作鉴别器之间的双人博弈:
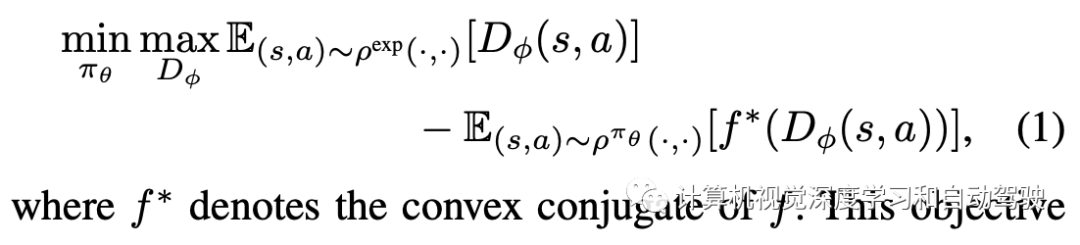
这个优化方法可以在优化鉴别器参数的discriminator gradient ascent 步和优化随机策略的policy gradient ascent 步之间切换,后者可以看成是带奖励信号的强化学习。而两个步骤都可以用蒙特卡洛方法(和一个replay buffer)估计其期望。
首先把前面目标函数定义为一个分层找到生成状态和动作的一个策略:将占用度量在选项扩展,这些选项在执行期间会引向状态 s 和动作 a,以及该选项开始执行的初始状态。扩展在时间 τ 开始执行选项 o 的初始状态 sτ = h,在该初始状态下,在时间 t 低级的状态s和动作 a可以被观察:

应用这个分层占用度量表征,可以把度量匹配目标函数定义为一种分层策略数据生成的形式:
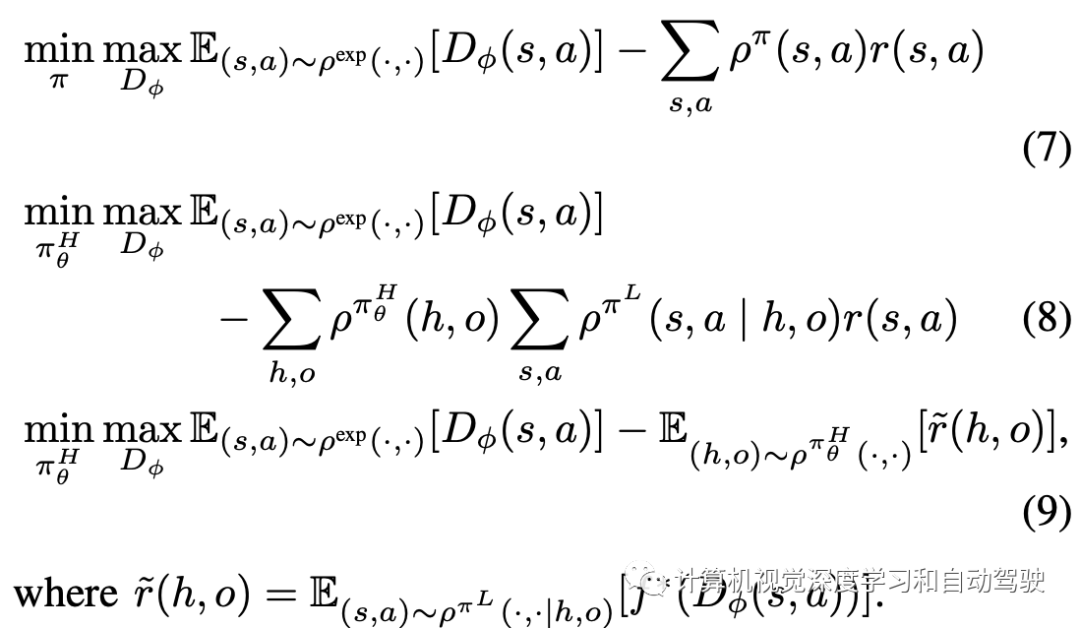
这里鉴别器更新保持不变,而生成器更新采用策略梯度算法,其中新的“想象”高级奖励累积执行该选项discounted低级“想象”鉴别器奖励。
许多实际策略梯度的实现,都依赖于固定大小的动作空间。基于此,这里仅限于一个选项集,其中任何选项都可以从每个状态做初始化。就安全性而言,这种假设可能非常有限。通常,有来自不同状态的受限选项信息(例如,Accelerate 选项不应从红灯中获取)。此外,也许能够对不同控制器的安全性进行预测。例如,通过控制器的可达性(reachability)公式严格去做,或者通过场景理解更宽松地完成(例如,“由于有车辆穿过十字路口,因此转弯可能不安全”)。SHAIL设计一个在选项安全性包含敏感性的高级“选项-选择(option-selection)”策略,改进了前面的分层对抗模仿学习(hierarchical adversarial imitation learning)公式。
假设智体可以推断来自不同状态不同选项的安全性或可用性,以此纳入安全意识。该文引入一个二进制随机变量 z,它预测低级控制器的安全性或可用性,表示选项 o 从高级状态 s 执行时是安全的概率。这样设计选项就可以根据此安全预测将控制传递回高级选项的选择器。
基于此控制器安全性,可以设计高级控制器:

此高级控制器根据选项的安全预测重新加权(或掩码)选项概率。此方案需要至少一个具有非零安全概率的选项(例如,永久的“安全”控制器),否则这个高级策略将不表示在控制器的有效分布。另外,要学习有用选项的选择器,其应该具有一些在不同初始化状态下成立的语义意思。
通过策略梯度学习具有此策略的选项选择器,需要将选项启动期间看到的安全概率存入replay buffer中。
Interaction仿真器在https://github.com/sisl/InteractionSimulator,是一个开源OpenAI Gym仿真器,取Interaction数据集的数据。仿真器本身根据Interaction数据集中记录的数据,即车辆路径和生成时间,并允许控制场景中一个或所有智体做加速。如果仅控制自车,则非自车的策略将从数据集中场景重放。
如图所示是SHAIL与环境交互时学到的策略在单个时间步长的情况:自车可以获得自己的运动状态和类似激光雷达、最多可以包括五辆周围车辆的相对状态信息。
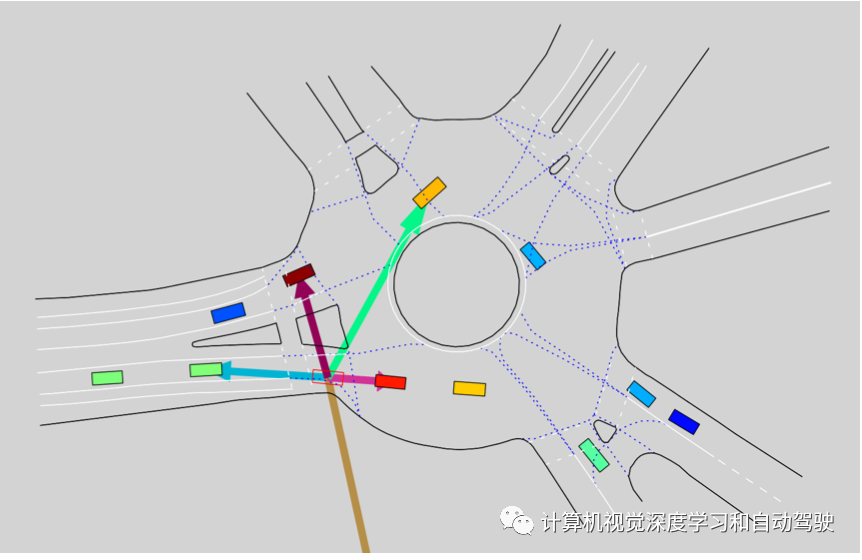
实验中专注于单一智体的控制,允许策略确定自车沿其轨道加速。当车辆离开现场时,模拟将终止。自车遵循一个双积分器转换模型(double integrator transition model)沿着其记录的路径移动,而非自车则遵循其记录的轨迹。
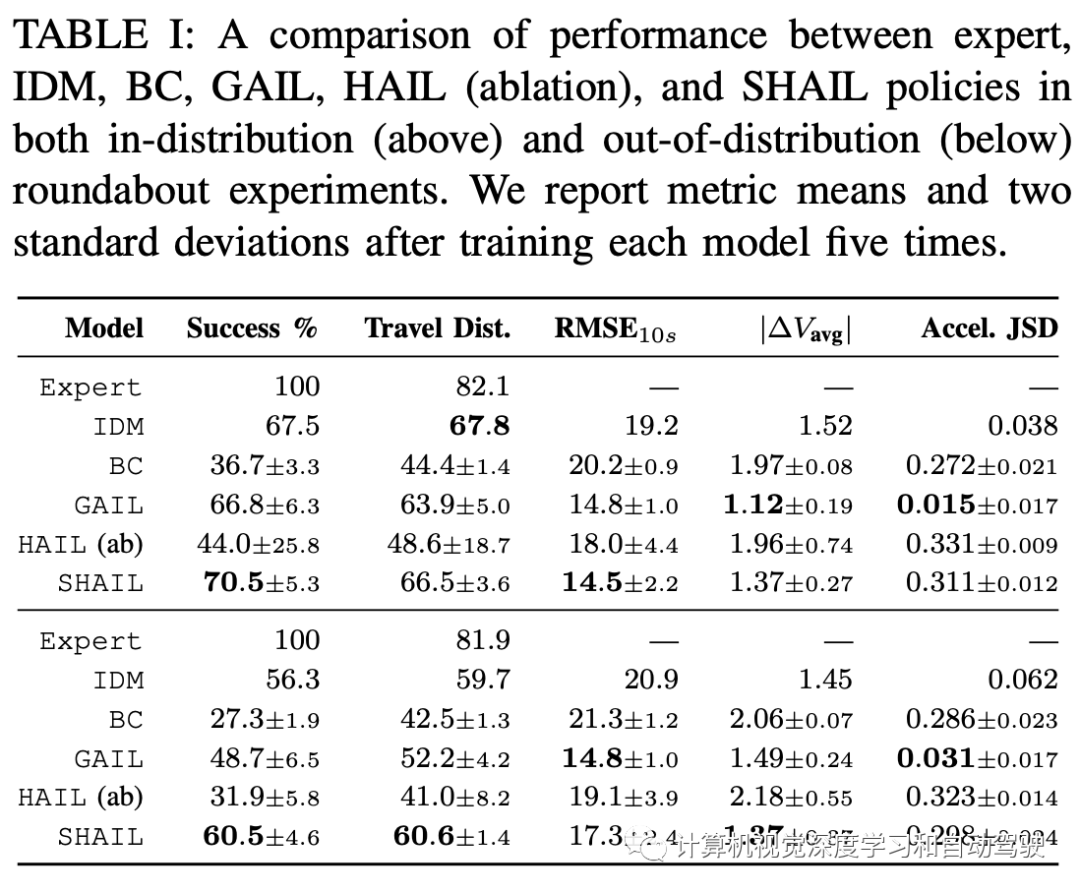
实验中和其他方法,即Generative Adversarial Imitation Learning (GAIL) ,还有行为克隆、IDM和专家模型(interaction数据集),进行比较。
SHAIL的高级控制器从一组选项中进行选择,这些选项针对特定未来时间的特定速度。每个选项的低级控制器命令固定加速度,车辆在所需时间可达到所需的速度。安全预测器返回一个二进制指示器,用于指示如果该选项保持其速度,是否会与其他车辆碰撞。因此,该实验的安全层类似于确定性规划安全层(deterministic planning safety layer)。此外,重写最大减速选项,使其始终有效,成为默认的“安全”选项 HardBrake。同样,用PPO的目标来衡量策略梯度。这里额外学习了一个没有安全层或者选择早终止(early termination)的SHAIL版本,即HAIL。
实验集中在环形交叉路口的模型性能上,这是自动驾驶导航惯常的棘手场景。有两个实验:第一个实验(ID)在同一环境训练和测试模型,该环境仅从第一个轨道文件中选择车辆,此实验目的是比较绝对潜在模型性能;第二个实验(OOD)选择做训练和验证的环境,从场景记录1-4中随机选择车辆,并在场景5上报告指标。这种OOD测试评估模型在未见过车辆数据上的表现,尽管仍然在相同的驾驶环境中运行。在这两个实验中,超参(例如模型架构、选项集等)都是选择训练环境中产生最高成功率的进行优化。
- 下一篇:为什么算法这么难???
- 上一篇:基于余热利用的燃料电池汽车能量管理策略



编辑推荐




最新资讯
-
国内现货!GRAS 46AE/146AE 限时优惠直降 5
2025-04-22 16:22
-
仿真测试必要性及标准法规
2025-04-22 16:22
-
福特退出中国,进入倒计时!
2025-04-22 16:21
-
高效三通道双向电源:释放测试潜能
2025-04-22 09:23
-
R171.01对DCAS的要求⑦
2025-04-22 09:20
