




 广告
广告





















































苏治中:面向规模化量产的自动驾驶感知研发与实践

导读
4月27日,地平线智能驾驶感知研发部负责人苏治中就《面向规模化量产的自动驾驶感知研发与实践》这一主题进行了直播讲解。
本次课程内容分为4个部分:
1、地平线自动驾驶环境感知量产实践2、软硬协同的自动驾驶感知算法设计3、实现规模化量产的“最后一公里”4、感知技术的发展趋势
01 地平线自动驾驶环境感知量产实践

图1 首先,为大家简单介绍下自动驾驶分级,图1左边来自于SAE,是大家提到自动驾驶分级时最广泛看到或最广泛引用的权威来源。从定义上来看,L3级以上才算是自动驾驶。L3级自动驾驶功能里,汽车具备从A点开到B点的能力。L2级的自动驾驶汽车仅仅具备纵向或横向的控制能力,不具备同时控制的能力,因此无法进行变道、超车、上下匝道,所以不能从一个地点开到另外一个地点。L4相比于L3,不再需要人去接管。到了L5级,对自动驾驶场景的限制就不再有了。
目前,国内的量产乘用车还不具备L3级的能力和功能,所以上面刚刚提到研发的Horizon Matrix Mono和Horizon Matrix Pilot产品,实际上也是ADAS或辅助驾驶产品。现有的一些车型实际上已经具备了L3能力,稍后讲到Pilot时也会提到,所谓L3是能够在限定场景区域内从一个点开到另外一个点。
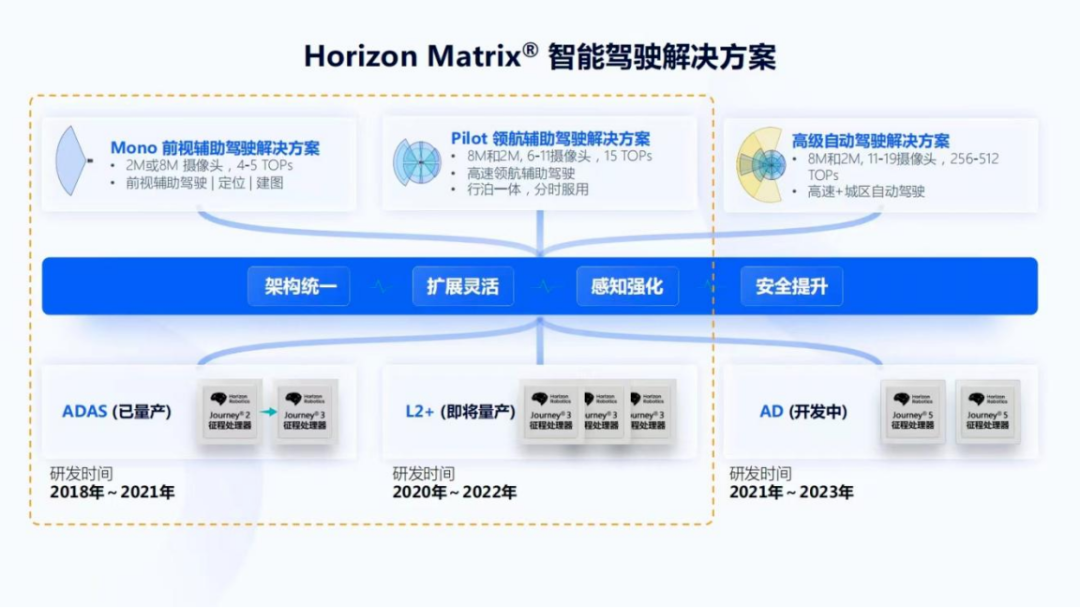
图2
图2是地平线Horizon Matrix智能驾驶解决方案的一个产品矩阵,包括Mono 前视辅助驾驶解决方案、Pilot 领航辅助驾驶解决方案和高级自动驾驶解决方案。它们分别是基于征程2,征程3和征程5开发的。由于今天聚焦于量产实践,所以会讲解在征程2和征程3上已经量产的Mono 和即将量产的Pilot 。从图2中可以看到,Mono的研发时间是从2018年到2021年,三年磨一剑;Pilot 也是用了近两年的研发时间,而SuperDrive,即更高级别基于征程5的解决方案将会在明年量产。

图3
先来看下Mono 的简介,Mono 是基于征程2或征程3的前视单目ADAS解决方案,征程2有4 TOPS的算力,征程3有5 TOPS的算力,它们分别支持C-NCAP跟E-NCAP的法规要求。
Mono 产品虽然看似简单,仅仅是一个单目前视解决方案,却是提升用户驾驶安全性,使得客户车型能够满足NCAP要求的重要产品。NCAP是指New Car Assessment Program,这也是欧洲、日本、北美和中国在法规层面,汽车进入市场之前一个逐步强制的要求。
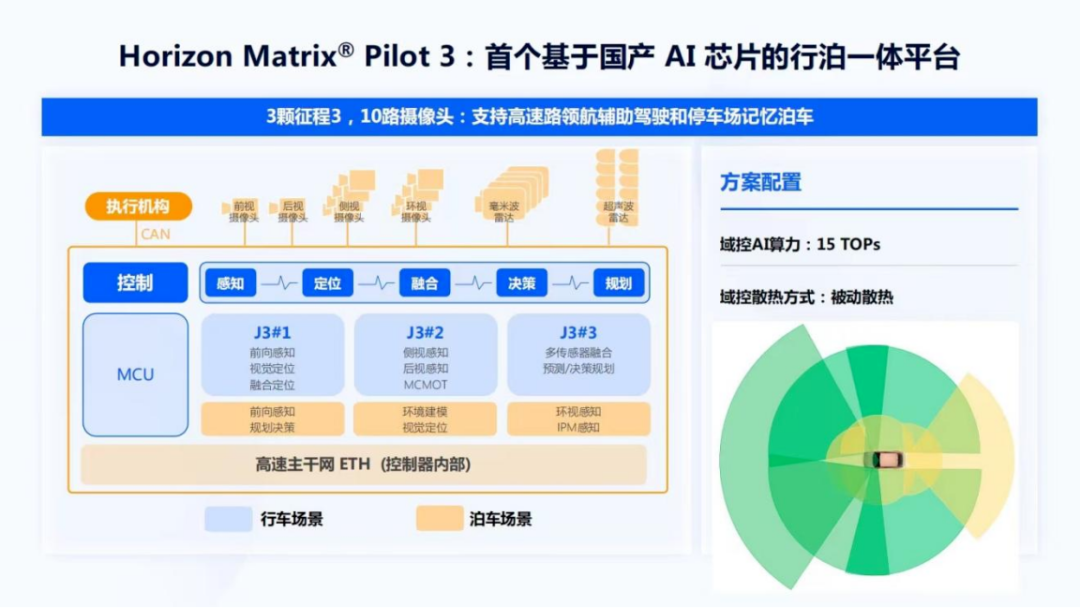
图4
Pilot 是基于3颗征程3,10路摄像头,支持高速路领航辅助驾驶和停车场记忆泊车的一款L2+产品,也是首个基于国产AI芯片的行泊一体的平台。从图4右下角可以看到Pilot 摄像头的布局,包括1个前视的8M相机,4个侧视的2M相机,后视的1颗相机和4路的环视鱼眼相机。
一些外部的调研也发现,消费者认为自动驾驶目前最需要解决的场景或最有需求的场景,是停车和高速路驾驶,Pilot 3恰好满足了这个要求,所以Pilot 3这款产品的功能正在逐步成为智能汽车的一个标配。我们也看到并预测,未来具备高速路领航辅助驾驶功能车型的量产会越来越多。
以上是已经量产和即将量产的两款主要产品,接下来会为大家讲解其中的感知算法设计,并且是如何结合征程2和征程3芯片实现高性能表现。
02 软硬协同的自动驾驶感知算法设计

图5
最简单的是一个固定的融合网络,这也是最早期的BEV方案。它的好处是所有的都见过,没有特别新的架构在里面,但是足够简单、鲁棒、好用,所以作为一个起点对应上面提到的几个不同层次内容。左边是上面提到的alignment、temporal fusion、 spatial fusion、最终的Task heads,图6以摄像头为例,激光雷达可能会有一些不同的变种,但基本的意思是一样的。首先,在征程2和征程3里,通过采用多任务模型来同时获得更好的感知性能和更低的系统延迟,所以可以认为我们的感知系统是由一个或多个多任务模型组成的。图5有一个简单的示例图,包括以全图输入的一些多任务模型,和若干以ROI作为输入,或是需要做细粒度识别的一些多任务模型。

图6
下面将从Backbone、Task设计以及Multi-task model三个方面为大家讲解算法的设计。首先是Backbone的设计,在Google提出MobileNet之后,MobileNet在对低延迟有非常高要求的场景中获得了巨大成功,并且它仅需要更小的算力。但MobileNet也有一定的缺陷,因为它的depthwise convolution与pointwise convolution的计算量分配不均,使得在硬件上会增加计算和访存读取的切换时间。
为了解决上面的问题,我们提出了VarGNet。它是指可变组的卷积,即variable group的CNN,通过可变组卷积升维,再通过pointwise convolution降维。MobileNet则是通过depthwise convolution升维。相比普通的 group convolution,我们的网络group数可变,但每个卷积里分组channel数是一致的,而一般的group convolution是channel数不一致,但group数保持一致。之所以要做到channel数一致,是因为可以组合跨层之间的部分 channel卷积,减少在SRAM与DDR之间的读取。
VarGNet有两个特性,一个是Block内计算更均衡,像刚刚提到的升维和降维分别使用variable group跟pointwise convolution计算,减少了内存切换和计算之间的平衡;另外一方面在block之间采用了一个更小的 channel或更小的feature map,通过这种方式达到更好的访存和计算平衡。
关于特征和参数的组合,以及硬件在计算过程中的流水线,大家可以参考凌坤在2月23日讲解的《好的自动驾驶AI芯片更是“好用”的芯片》,里面有更详细的介绍。这篇VarGNet的论文,也可以在arXiv上找到。

图7
之后是感知任务设计,大家最熟悉可能是2D感知。计算机视觉里一些经典的任务,比如检测、分割、分类和关键点检测,组成了自动驾驶里最基础的2D感知。图7有一些示例,像车辆检测、车型分类、针对一个行车场景和停车场景的分割,以及通过车轮接力点的关键点检测,在2D任务里判断车辆的朝向,和在停车场景中停车位的检测。但是2D感知都是在图像域的,所以要变为可以被路径规划和控制所使用的车辆坐标系或世界坐标系下的感知结果,因此需要结合一系列的先验才能得到所需要的信息。

图8
综上可知,2D感知实际上具有很大的局限性。它依赖人工逻辑设计,难以规模化的扩展,比如图8左边的例子,上面是一个车道线的分割,它能够帮我们拟合出来在图像坐标系下的二维车道线,然后再通过一系列外参的映射,把它反推到车辆坐标系下的车道线。图8右边的两张照片是2D检测不能很好应对的场景,右侧上图是一个横穿的车辆,可以看到车辆的检测效果并不好,这是因为自动驾驶汽车可能在大部分行驶过程中,都会看到车尾或者对向来车,这种横穿车辆相对来说是较少出现。
右侧下图是复杂遮挡的例子,车尾与全车检测都还有一个不错的效果,但在这样很多遮挡情况下,很难估计车辆的pose。如果没有办法估计车辆pose,也没有办法知道它行进的方向,以及对自动行驶的影响。因此为了使用深度学习,即通过数据和计算进行端到端的优化,是需要进行原生的3D环境感知。
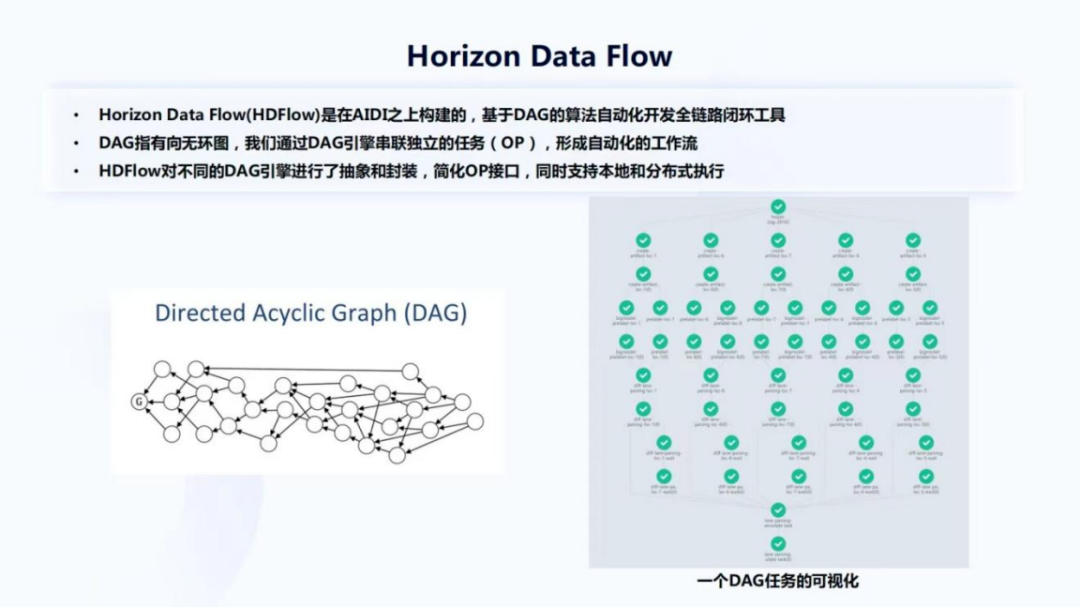
图9
讲到3D环境感知,首先会想到单目深度估计。当然,单目深度估计实际上是一个2.5D的任务,并不是一个严格的3D任务。现在最常见的单目深度估计的算法是通过激光雷达点云的监督,可以看到图9左下角是激光雷达提供的稀疏真值,图9左上角是原始输入的 RGB图像,然后通过激光雷达提供的稀疏监督,能够预测出稠密的深度值。通过深度值可以解决非常多的问题,比如图9右上角,如果使用车尾和全车检测,很难应对一辆拉了树木的大车,甚至车尾会发生漏检,但depth可以很好的应对,防止出现一些交通事故。
此外depth还可以改进 Freespace的效果,尤其是外参测距的情况。图9右边中间部分是单纯的外参测距产生的Freespace,而下面的是外参+depth产生的Freespace,可以看到在一个高速收费口有三个水马,实际上感知是找到了水马,但Freespace投影出来这几个水马的位置却比较靠后。而通过引入depth,可以更好的得到一个准更准确的Freespace,结果显示这三个点的位置跟水马检测到的位置是很接近的。
很多同学也会问到,基于激光雷达的任务,怎样更好的优化,因为量产车上是没有激光雷达的,所以现在也在尝试基于多摄像头和多帧的光度一致性,对深度预测模型做无监督或自监督的优化,这也是目前学术界广泛尝试的方案。
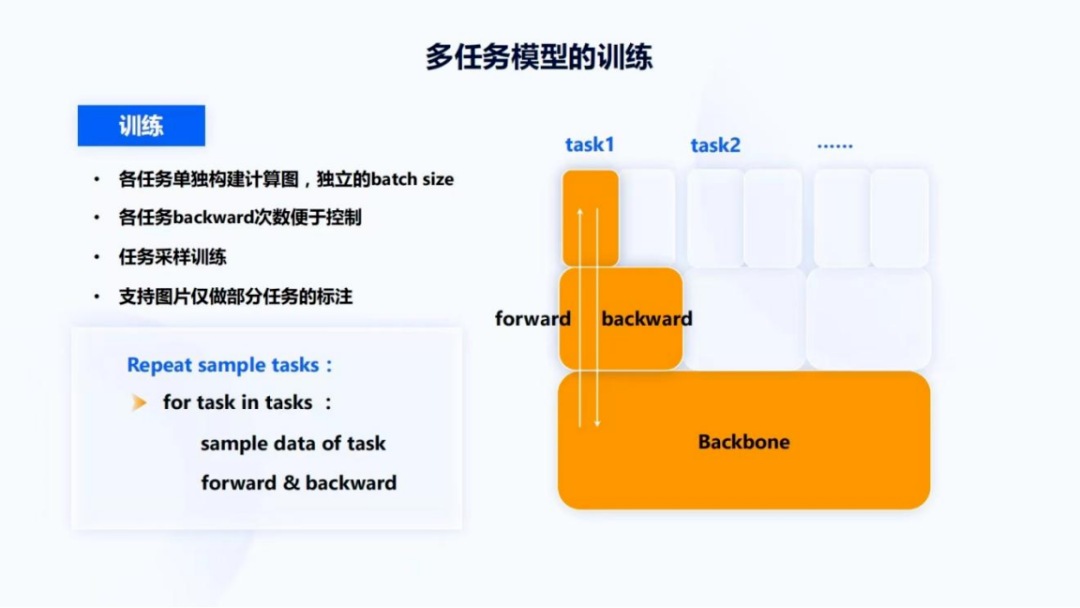
图10
接下来针对动态目标的3D检测,与depth任务类似,同样要用激光雷达得到场景中所有3D的动态目标,比如车辆、骑车人,然后再以图像为输入进行学习,并直接输出3D的bounding box offset,还有长、宽、高等。图10可以看到一些3D检测的示例图,包括一个多类目标的感知车辆,还有骑车人以及针对横穿马路场景的处理。刚刚前面也讲到,目前2D感知很难应对横穿车辆的场景。
其次,当没有办法准确估计pose时,实际上很难判断周围车辆是否会在近距离对本车安全产生影响,而3D感知可以对遮挡车辆有很好的 pose估计,因为 bounding box本身是带有pose的,这样可以产生更稳定的下游预测值,自车行驶也会更加平顺。

图11
再接下来是3D车道线,上面讲到2D感知局限性时,实际上也提到了2D车道线,如果先做分割,再做投影会很复杂。其次分割还需要一个相对复杂的连通域提取过程。车道线是环境里面最重要的一个静态目标,因为我们在大多数的城市道路和高速路上,车辆主要是沿着车道线行驶,因此研发原生的3D车道线感知很关键。上面右半部分的图片是对图11中的左半部分图片进行了IPM投影,然后将竖直的列作为anchor进行anchor-based detection,之后再在 instance基础上提取关键点。3D车道线的输入可以是单摄,也可以是跨摄感知融合的特征,跨摄感知融合的特征会在后面讲到。
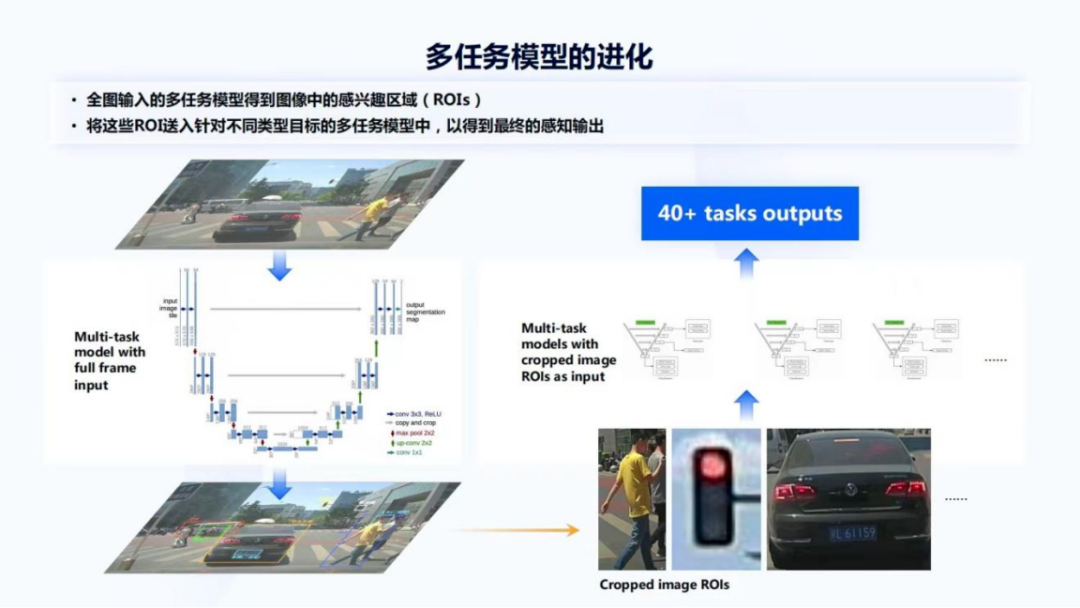
图12
接下来是多任务模型的设计和改进。图12是第一版多任务模型组成的视觉感知系统,是一个全图输入且相对比较大的多任务模型,采用了UNet结构,做所有关键目标的检测。之后会对这个图片感兴趣区域做截取,比如找到了行人、交通灯和车辆。因为基于行人或车辆的输入,还要做很多其他的任务,像朝向的判断、关键点检测以及分类等,所以还会针对不同的目标,再去使用一系列、更小的、以ROI作为输入的模型,做更细粒度的任务。
在这个系统中,实际上是有多个大小不一的多任务模型,最终至少产生了40多个task outputs。这个task output并不是tensor,因为每一个task可能会有非常多的tensor输出,比如3D车辆检测就有非常多的tensor输出,包括pose、长宽高以及中心点位置等。但是这个系统也存在一些问题,比如在系统中需要去截取这些图片,再去独立的过模型,可能没有办法复用或者共享之前大模型提取的一些特征,这实际上有一定的浪费,因此也希望采用特征ROI输入的多任务模型来改进系统。
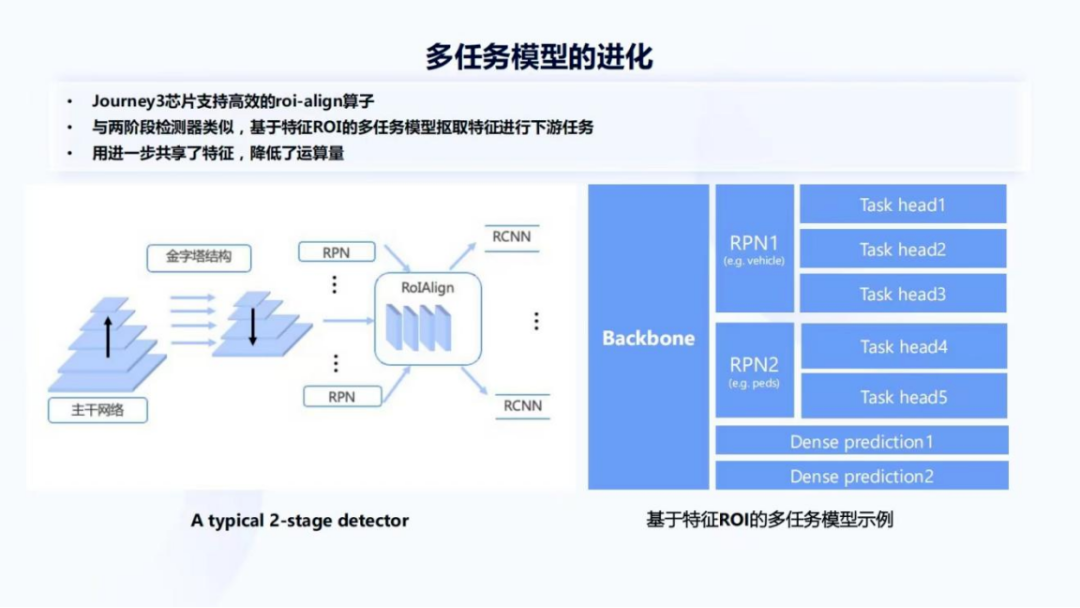
图13
征程3芯片支持非常高效的ROI-align算子,这也使得基于特征区域做多任务的方案成为了可能,与两阶段检测器很类似,基于特征ROI的多任务模型,通过ROI算子选取特征来进行下游任务。一个检测器的下游任务只有RCNN,但我们的多任务模型下游任务会复杂很多。图13右侧是基于特征ROI的多任务模型示例,它由 Backbone与若干个RPN,以及一系列Task head组成。因为模型会有一些 Dense prediction,比如前面讲到的depth,即每个像素都有输出的任务,所以会有一些不涉及这个RPN或Region proposal提取部分的任务。这里举了两个例子是车辆跟行人的RPN,实际上还会有更多其他的任务,包括骑车人、标志牌、交通灯等其他的关键任务。
针对基于特征ROI的多任务模型还有很多优化方法,下面为大家罗列了三种方法。首先将RPN替换成一个更好的 proposal generator,而征程3也支持一个更复杂的检测器,得到了ROI,然后再用ROI返回Backbone上取特征的方式,并且这个过程非常高效,它完全是在BPU里进行;其次是把一些没有必要的Dense prediction变成Sparse prediction,以及在Task head之间有一些share feature,进一步降低模型的延迟。
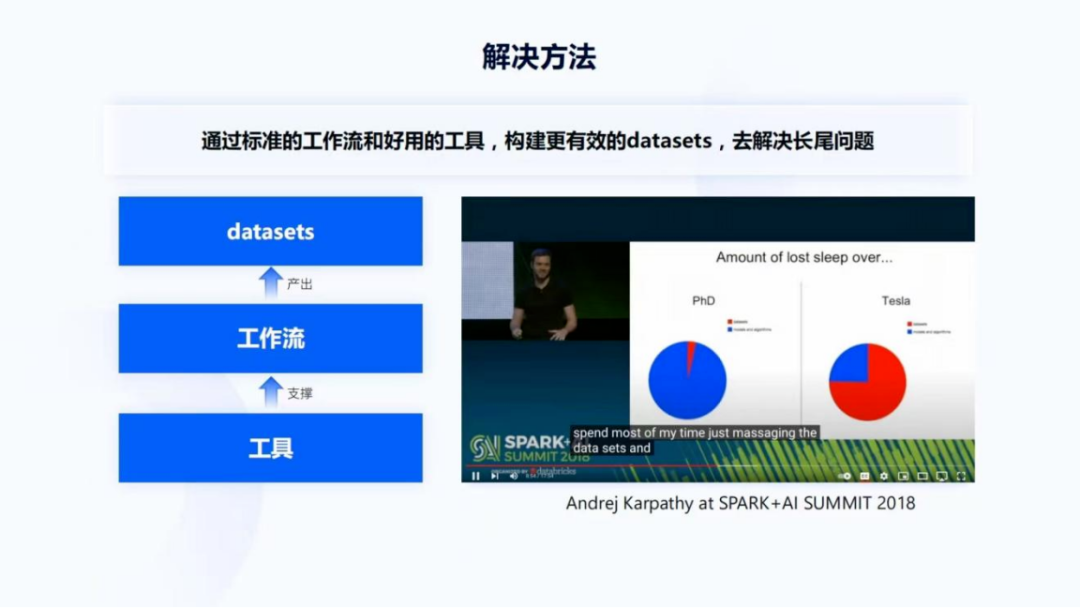
图14
下面详细介绍下这三种方法,首先是Better proposal generator,比如把RPN替换成FCOS,这也是现在相对比较新或者检测性能相对比较好的模型。上面有提到征程3是支持通过更复杂的检测器获取ROI,反过来再通过ROI来获取feature,然后进行下游任务。但是更复杂的 proposal generator有利也有弊,利在于首先是特征表达相对可能更浅层一些,所以通过引入浅层的特征,检测框可能是一个更精确的框;其次因为FCOS本身有很好的性能,所以它对 proposal 的提取会更精确,像可以更减少一些false positive proposal。但是它也有代价,因为FCOS会比RPN更复杂,所以计算量更高,可能会给模型带来一些延迟的增加,所以这里需要去做一些trade off。
接下来是dense prediction变成sparse prediction,和一个典型的例子:Vehicle 3D det变成Sparse vehicle 3D det。因为常见的基于 CenterNet的检测器,比如FCOS 3D是一个稠密的3D检测器,只需要把它连接在backbone上,就能够完成多任务模型,但是这个过程实际上是有一定浪费的,既然 region proposal已经给出了车辆的区域,那完全可以在proposal上预测3D bounding box。
图15
图15可以看到Sparse 3D与Dense 3D的对比,在一些远距离的车辆上面, Sparse 3D获得更好的召回,同时还降低了计算量。这也是因为RPN会提取更多、更丰富的proposal,使得能够在第一个阶段保留更多的候选区域。
最后一个是Task head combination,比如针对vehicle task123可能是检测、关键点或者分类等其他任务,这三个head实际上是比较类似的,或者说是相关的任务,如果把这三个head再共享一部分特征,能够使得整个模型的计算量有一定下降,从而获得更低的模型延迟。
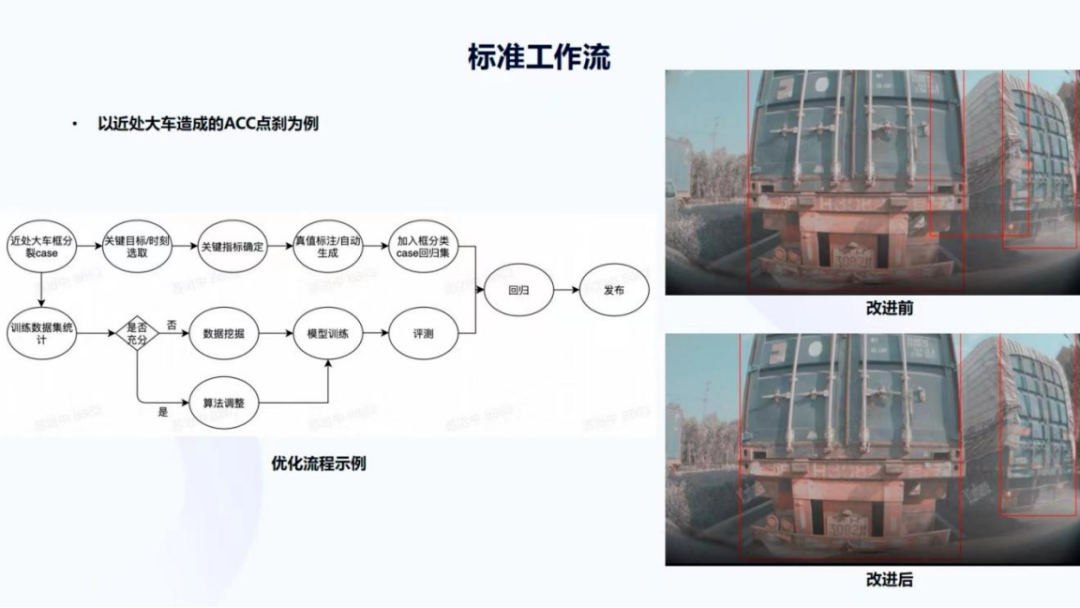
图16
以上是针对多任务模型进化做过的一些尝试或一部分工作,前面讲到了基于图片ROI跟特征ROI两种多任务模型的选择,但是基于特征ROI和图片ROI的模型并不简单是一个替代关系,即特征ROI模型做出来之后,它不可能完全替代图片ROI。
它们相互会有一些优势和缺点。比如基于图片ROI的多任务模型,它的研发工作是相对解耦的,像我在做车辆,我的伙伴在做行人,我们俩可以迭代两个模型,而不需要在同一个很大的模型里开展工作,这样研发的节奏或分工会更清晰简单些;其次,它可以针对单一任务快速、低成本迭代,比如我的版本发出去后,发现车辆的效果不太好,但是其他的都很好,实际上可以只迭代车辆的多任务模型,而不用迭代其他的,但是基于特征ROI模型也可以只迭代这个head,但是基于特征ROI总是要提取 Backbone的特征,所以会让过程变得稍微复杂;最后图片ROI可以调度skip非关键目标的计算,比如一些远距离车辆,可能现在不是特别关注,软件就不会调度图片ROI的车辆多任务模型。
针对特征ROI,因为在常规的一个两阶段检测器里,通常只能设置置信度和proposal的上限,很难做更复杂的策略来选择这个特征的ROI。虽然在软件层面上可以实现,但是会更复杂一些。
图片ROI的缺点刚刚也讲到,之所以要做特征共享就是为了节约计算量,所以它必然有更大的一个计算量;其次它的发版会更复杂,也更繁琐,维护也会更麻烦,因为一个版本里面可能要带很多个模型,而它们要被整理成一个相同的版本号。
特征ROI,首先它能完成特征共享,节约算力降低延迟;其次能够做端到端的联合优化,即proposal的提取与stream下游的一些任务能够做端到端的联合优化,做过深度学习的同学,应该都会非常期望我们的任务是可以被端到端联合优化的,有梯度回传一般来说总能带来更好的效果;最后特征ROI能够给下游任务提供更大的感受野,因为每个特征的像素对应到原图上一个很大的区域。但是特征ROI也不是完全完美,它会有一些训练难度大、耗时长的问题,以及Train from scratch代价高,所以在实际工作中这两种也会针对产品与任务,以及不同的项目做灵活选择。
图17
多任务模型的最后一部分是多任务模型的训练。多数模型如果没有一个很好的训练机制,需要把每张图片上所有的task都进行一个标注,并且有时很难控制不同task之间的数据量、更新频率以及迭代权重,所以也设计开发了一种每个task独立forward 和backward的训练模式,它可以每个任务单独构建计算图,使用独立的 batch size,比如task1是针对vehicle的某一个任务,而task2是针对pedestrian的某一个任务,它们俩可以有不同的batch size,这样独立的方式也可以比较容易的控制task1跟task2的迭代次数。像刚刚提到,如果车辆任务已经做得特别好,但行人任务不是特别好,只想迭代行人的task2。再次,它可以很方便去做任务采样训练。最后,它支持图片仅做一部分任务的标注,比如有一些图,过去可能只标注了pedestrian跟vehicle,但现在新增了一个task,是交通灯,通过这种方式就能够很好的把仅有部分标注的 data也可以做很好的应用。
图17的PPT动画也展示了这个过程,可以看到是在不同task之间,我们去simple一些data,然后forward 、backward结束之后,再进行到下一个task。
03 实现规模化量产的“最后一公里”
首先我想说“行百里者半九十”,在这个方案研发过程中,从研发的启动到车型量产会花掉比较久的时间。从最开始介绍Mono跟Pilot产品时,大家可以看到整个Mono产品是三年磨一剑,Pilot也是达到了两年的开发时间,所以在这样长的周期里,实际上算法方案大部分定型和数据覆盖大部分场景的情况下,距离量产可能仅仅才完成一半的工作。

图18
在大部分场景覆盖和算法方案定型之后,还有大量的细致打磨和解决长尾问题的工作量和时间。图18是一个长尾分布的图片,大家可能都非常熟悉,这个图片中横轴部分做了一个延长,因为长尾问题是永远解决不完的。
图19
针对长尾问题的解决方法,是通过标准的工作流和好用的工具,构建更有效的datasets,才能够更好地解决长尾问题。当然在这个阶段并不是没有算法方案改进的工作,一定还是有的,但在这部分,datasets的工作会更加重要。图19右侧这张图是Andrej Karpathy 在SPARK+AI SUMMIT 2018 talk里的截图,他讲了非常有意思的一句话:spend most of my time just massaging the datasets。他用了massaging这个词,实际上就是对datasets做一个非常细微的调整。
他还用了一张图讲 lost sleep over,实际上是讲他们在PhD阶段和在tesla工作时的时间分配。图中蓝色是指算法的开发,红色是指调整datasets所花的时间。地平线实际上也是类似的,在算法方案稳定之后会有大量的调整datasets的时间,而刚才也讲到一个好的datasets还需要工具支撑一个标准的工作流,才能更高效地产出一个好的datasets。

图20
那什么是一个好的工作流或我们的工作流是什么呢?首先收到长尾的问题或corner case,这些case可能来自于自己的测试,也可能来自于客户的测试。这些case会积攒得非常快,我们也会对它进行分类。当某一类型的case积攒得比较多时,会对它们进行 root cause分析,将大量的root cause扔进一个相对比较标准的优化流程里,我们有若干很标准的优化流程。尽管大部分优化流程都是很收敛的,但难免还是会发现新的根因,新的根因也会为它设计新的优化流程。
图20右侧是一个root cause分析的一个triage tree,但这只是部分,可以看到把这个根因分得非常细,这也是在三年量产过程中,针对场景或特定情况的一些分类的积累。root cause分析的过程一部分是自动的,也有一部分是手动的。如果是自动,它也会依赖云端更大的计算量,或者依赖后验分析,因为一般在得到这个case或问题触发之后,还有很长的一段时间。当你离线去处理它时,你可以用事后诸葛亮的方式来反推是否有问题,或者是有什么样的问题。也有一部分会依赖算法工程师或者标注人员进行手动的root cause分析。
图21
下面以近处大车造成的ACC点刹为例。首先对 ACC点刹进行root cause分析,发现是因为近处大车的检测框分裂造成,图21右侧是一个真实的场景,这种场景在测试过程中是非常多的,红色的框是车尾检测并不是全车,可以看到这两个框本身贴合是很好的,但中间却出现了一个很难被去除的框,这就是通过root cause发现的一类问题,就是近处大车框的分裂,那怎么样通过一个标准的工作流去解决这个问题呢?
有两个主要的分支,第一个分支是用很多这样的长尾问题去产生一个回归用的集合 regression dataset。首先会选取一个片段,我们称之为pack或clip的视频片段,然后在这里面选取关键的目标和时刻,关键目标是右上角图片里左边的车,因为它是我们的CIPV,即是本车道离自车最近的一辆车;关键时刻就是错误帧框跳出来,造成车辆产生点刹前后的一些时刻,然后会确定关键指标。针对这样的检测问题,关键指标实际上是AP或者 IoU error,因为IoU决定了框的检测是否足够贴合,之后会进行真值的标注或者自动生成,自动生成可能是一个预标注的过程,也可能是其他更复杂的4D标注生成的过程。针对2D更快或更常见的做法还是标注,之后把选好的corner case加入到框分裂case的回归集合里,这是回归case集合建立的链路。
另外一条链路是我们如何去解决它。首先会统计近处的大车是不是真的不充分,即是训练集合的一个统计,并分析训练集里打的一些tag,比如大车、离自车的距离、CIPV等看有多少这样的情况在训练集里是存在的。如果它非常丰富,但是还是出现了问题,会对它做算法调整,比如引入框的置信度,针对框边界的置信度,而不是针对框本身的置信度,因为现在的很多基于关键点的检测技术,实际上能够给我们带来框边界的置信度。但这种情况并不是特别多,大部分情况下会发现这种类型的数据并不充分,因此会做一些数据挖掘,然后将挖掘到的数据放到模型里做训练,然后评测,跟 case集合做回归,之后再做模型的发布。
以上是以近处大车造成的ACC点刹为例,实际上很多与某一个目标相关的,并且需要通过数据挖掘解决的标准工作流的方法都非常类似,这也就使得我们的工作能够相对比较收敛,以一种较少的工作流程来解决大部分在量产之前会遇到的问题。

图22
刚刚讲到了数据挖掘,下面会给大家展示一些数据挖掘的方法示例。首先,最常见到的Model Committee,会有多个大小不一的模型检测上图。比如图22中近处大车部分,某一个模型检测到了三个框,某一个检测到两个,还有检测到一个,多个性能很好的大模型,表现出了不一致的效果。我们认为这个时刻大概率是有问题的,因此就会获取它的标注,确认它是否有问题,然后加入到训练中。
第二个是用Scene tagging,通过这种感知结构化信息,因为在测试过程中都是一边测试一边在跑功能,所以会保留很多已有的感知结果,比如车道线的感知结果以及场景分类得到的天气、时间段的结果,这些感知结果会被结构化成一些场景的标签,比如夜晚高速路导流线的场景标签,这样可以在大的、全量的datasets里寻找相关的数据,并且将它们引入到训练当中。
第三个会用到的方法是similarity search。similarity search会对图片提取一个特征,提取特征的模型是什么,可以自行选择或自行去训练,现在有非常多性能非常好的、通过自监督学习得到的各类大模型,当提取出来这些特征之后,我们可以用希望得到的场景图片,比如一个隧道口,去底库里所有图片做特征的相似搜索,然后得到一系列高速路隧道口的图片,引入到训练里。
这只是一部分会用到的数据挖掘方法,因为数据挖掘在工作中非常重要,所以也会有一些其他更丰富的手段。

图23
接下来讲下工具部分,前面提到了一个高效的工作流是被很好用的工具和基础设施所支撑的。而地平线艾迪(Horizon AIDI)AI开发平台,就是我们所依赖的一个算法研发的平台和基础设施,它由AIDI-Issue,AIDI-eval、AIDI-Model、AIDI-Label等多个平台支撑算法研发服务。目前关于地平线AIDI的材料非常多,我的同事凌坤2月23日公开课课程《好的自动驾驶AI芯片更是“好用”的芯片》中,对这部分内容有更细致的介绍,大家如果感兴趣可以看下回放。
图24
算法工程师开发更多的是Horizon Data Flow(HDFlow)。它是依托于AIDI构建、基于DAG的算法自动化开发全链路闭环工具。DAG是指有向无环图,如图24左边的示例,把一些节点或者OP通过一些边连接在一起,让OP能够流转。现在业界有非常多不同的DAG引擎,我们也是通过对DAG引擎的封装来构建HDFlow,然后完成自动化的工作流。
HDFlow对业界一些比较普遍主流的一些DAG引擎都做了一个抽象跟封装,并且简化了OP操作的接口,同时它也是支持本地,即在自己的开发机上或者在集群上的分布式执行,灵活度高,也方便算法工程师调试。右边是一个DAG任务的可视化,每个小圈表示一个OP,之所以画了绿色的对号,是因为DAG已经顺利的完成了一个执行,这里面可能包含了一些数据挖掘和模型训练等等,都会作为HDFlow中的一些节点。

图25
图25展示了一些可以由HDFlow搭建的任务,包括训练前闭环:数据挖掘、标注质量检查、评测集构建、场景与Corner case数据集构建、数据分布统计,以及训练闭环:训练数据打包、模型训练、模型发版、模型评测和回归等等,这些都是通过HDFlow可以自动化构建的一些task。所有的小DAG可以被更大的DAG包含,所以这些任务之间也是可以被HDFlow自动化的串联在一起,通过这个工具,大幅的提升了在标准化工作流中做数据流转或算法开发任务。
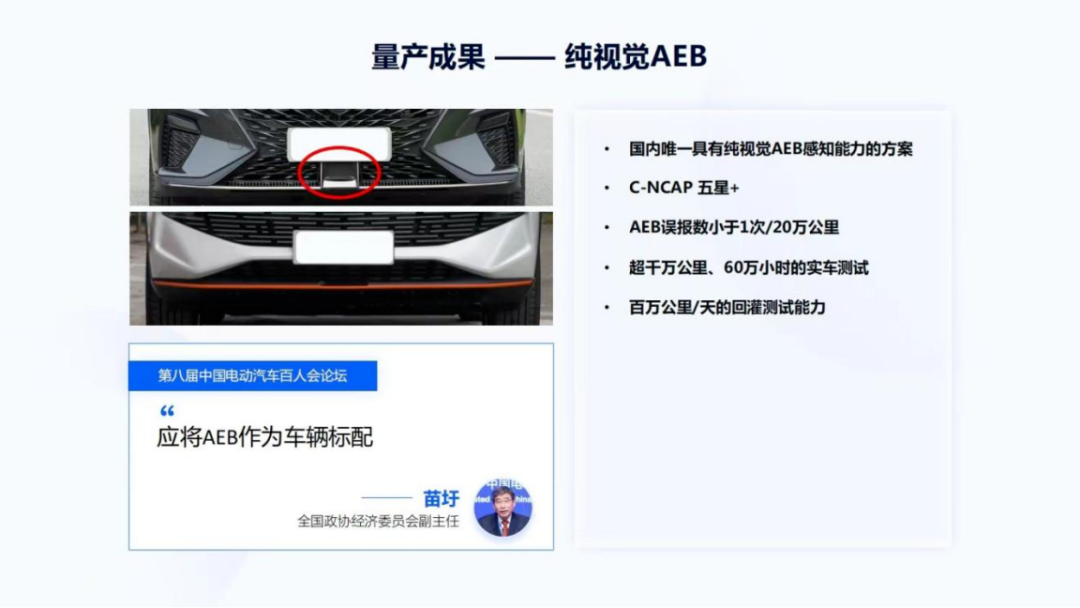
图26
既然已经讲了许多量产中的工作,也为大家展示一些成果,首先是纯视觉的AEB,如图26左上角所示。目前大部分汽车上都会在前保险杠上装一个黑色的毫米波雷达,而纯视觉AEB能够去掉这个器件,更节约成本,特斯拉目前也在Model 3跟Model Y中去掉了毫米波雷达,因为特斯拉认为会有一定噪声,引入毫米波雷达好坏与否,不是今天要讨论的话题。
目前,Horizon Matrix Mono前视单目解决方案,是国内唯一具有纯视觉AEB感知能力的方案,能够同时达到两项非常厉害的指标:C-NCAP 五星+和AEB误报数小于1次/20万公里。C-NCAP是中国的New Car Assessment Program,五星+是最高级别得分, C-NCAP要求车型需通过乘员保护、行人保护和主动安全三大项严苛评测,综合得分率≥90%才能获得5星+。与此同时,Matrix Mono也控制了AEB的误报数在非常低的水平——远小于20万公里一次,即大部分用户在开这个车的生命周期里面,像10万公里、 15万公里,很大概率都碰不到AEB误触发的情况,而且指标还在不断被优化。
AEB误触会带来很不安全的问题和很差的用户体验。大家过去可能听过一些车,由于AEB误触造成所谓幽灵刹车的情况,像正在路上开车,然后什么东西都没有,车突然自动刹车,然后把乘客吓了一跳,所以它也是一个很关键的指标。
我们之所以能够达到这样的指标,与前面讲到的算法方案、工具、标准化的工作流相关,也和测试能力有关。目前我们的产品是经过了超千万公里、超过60万小时的实车测试,并且具备百万公里每天的回灌测试能力,即如果有一个版本做了一定的改进,可以在一天之内完成100万公里的回灌测试。在前不久的中国电动汽车百人会的论坛上,苗圩主任也提出需要将AEB作为车辆标配的建议,这也说明了AEB作为主动安全重要的功能,被看重的程度或重要性。
接下来展示两个NOA领航辅助驾驶的 Demo视频。展示的是夜间车辆进入匝道的过程,可以看到整个驾驶过程非常平顺。在高速路行驶的期间,进入匝道的过程中,是完全没有驾驶员接管的。第二个视频同样是基于夜间领航辅助驾驶。这里是在跟着一辆车,车上载有货物,且货物跟车辆的车尾高度不相匹配的情况。可以看到,还是能够做到平稳跟车。

图27
图27展示地平线的一些量产成果,已经有超过20个车企的定点合作,50多个车型的定点,以及超过百万的智能芯片出货和超过100家的生态合作伙伴。这张图中是已量产的部分车型示例,黄圈是我个人参与过的一些ADAS量产项目。
04 感知技术的发展趋势

图28
最后给大家介绍我个人对感知技术发展趋势的一些看法,我认为图28的这些技术会成为达成自动驾驶的重要途径。
首先是 Transformer。它有多种不同的应用,首先可以作为Backbone,比如 SwinTransformer,在相当长一段时间内是SOTA,但现在有一些新的模型产出;其次Transformer还是空间和时间特征融合很重要的组件,现在不管是做一些Tracking或BEV感知,很多时候都用到Transformer结构,才能够达到很好的效果,所以Transformer很重要。
其次是 BEV感知。关于BEV感知,刘景初博士在地平线自动驾驶技术专场第1讲上有一个课程叫《上帝视角与想象力--自动驾驶感知的新范式》,深入讲解了地平线针对BEV感知的一些实践。而BEV感知同时端到端地提供了特征融合和视角转换,所以是一个很好的新范式,目前很多人都在做,但是特征融合的方式有很多,不仅仅是BEV感知。然而视角转换也能够给下游的一些任务预测和planning提供一个更好的输入,这也是当前会比较倾向于使用BEV感知的一个原因。
之后是时序的端到端感知。这种结合时序特征的,比如通过Transformer做时序特征融合的一些端到端检测到跟踪再到预测,能够进一步降低系统不喜欢的人工逻辑参与。因为人工逻辑会使得我们总是需要很优秀的工程师不断优化系统,使得系统很难 scale up。
接下来是多传感器前(中)融合。现在有很多量产的车规级固态激光雷达,已经在很多车型上应用,像蔚来的ET7,理想的L9上都已经有一些装配。先不去论Lidar跟视觉之争,如果仅仅是有这些传感器,相比依赖人工逻辑的后融合,Lidar、Camera特征级的前融合,它能够通过数据和计算的驱动替代人工逻辑,带来更简单,或者更容易迭代的系统,同时算法也能够降低对传感器同步的要求。
下一个是(大模型的)自监督学习。目前业界有非常多大模型的自监督学习的工作,这些模型也显示出了一定的智能。比如最近特别火的DALL-E2,可以输入一段话来创作图片,创作的这些图片很难辨别是被机器或模型所创建的。我认为自监督学习的发展还是很好的,但自监督预训练在下游任务的表现还有待提高。我们会对这个领域保持关注。
最后一个是 Low Level Vision的应用。纯视觉的自动驾驶系统如果还是仅仅是依赖语义级的感知,比如detection、parsing会非常有局限性,因为这些语义级的感知往往是针对闭集,即一些定义好的类别,比如说车辆等。但是,它很难应对一些极端复杂的场景,或者一些没有定义过的障碍物类型。我个人认为纯视觉自动驾驶系统的发展,会依赖 Low Level Vision的成熟和大规模应用。
图29
地平线已经发布并即将量产的征程5正使得这些技术的量产落地成为可能。征程5有更大的算力,单颗芯片达到了128TOPS算力,也使得做一些更大的模型成为可能;其次它对Transformer有比较好的支持。在征程5上 SwinT可以跑到140FPS,同时征程5的功耗只有30瓦,而PC端常用的NV 3090,是在上百瓦功耗下达到230FPS,所以可以看到征程5有一个非常好的能效比,并且作为车规级的芯片,确实达到了很高的FPS,使得 SwinT系列在这个产品中使用成为可能。不过需要说明一下就是SwinT这里是一个batch size为1的情况,随着batch size增大,3090也会明显提升它的帧率。
其次,征程5支持图片和特征的remap变换,因为现在不少BEV或者其他技术会依赖高效的图片或特征的remap,包括要做虚拟相机之类的技术也是需要一些remap。
最后,征程5也硬核支持部分Low Level Vision feature的提取。
图29左下角是一个以EfficientNet作为Backbone的FCOS模型,在征程5上与Xavier和Orin-X的对比,蓝色的线是征程5,黄色的线是Orin-X,橙色的线是 Xavier,纵轴是mAP,横轴是FPS,可以看到征程5是有显著的优势。1283 FPS是在保持MS CoCo数据集上的精度 mAP=34.6%,输入分辨率为512*512的情况下,征程5所达到的计算性能。
最后,给大家展示下基于征程5的Matrix SuperDrive产品片段做个预热,后面还会有详细的课程做讲解。它是基于两个征程 5,256 TOPS算力支持下的一款自动驾驶产品。片段展示了一些BEV感知的结果和一个左转的过程,可以看到整个过程是没有接管并且非常平顺的。这也是通过纯视觉完成的。
以上是我今天跟大家分享的内容,谢谢大家。



编辑推荐



最新资讯
-
货车侧滑检测异常数据集群的成因分析 ——
2025-04-09 15:32
-
网络研讨会 | 4月16日HBK智能传感器
2025-04-09 12:21
-
褚教授课程笔记 | 工作变形分析(Operating
2025-04-09 12:19
-
深度讲解仰望U7水平对置发动机
2025-04-09 12:15
-
重磅!东风汽车重大突破
2025-04-09 12:15
