




 广告
广告





















































综述:自动驾驶应用中知识增强的机器学习方法(一)

arXiv2022年5月10日上传论文“Knowledge Augmented Machine Learning with Applications in Autonomous Driving: A Survey“,作者来自德国多个tier-1公司和一些研究所。
代表性数据集的存在是许多成功人工智能和机器学习模型的先决条件。然而,这些模型的后续应用通常涉及训练数据中表现不充分的场景。其中原因是多方面的,从时间成本限制到伦理考虑等。因此,这些模型的可靠性,尤其是在安全-紧要的应用情况,是一个巨大的挑战。要克服纯数据驱动方法的局限性,并最终提高这些模型的泛化能力,关键在于利用额外的、已经存在的知识来源。
此外,即使在表征性不足的场景,符合知识的预测对于做出可靠和安全的决策也至关重要。这项工作概述文献中基于数据的模型和现有知识结合的现有技术和方法。已经确定的方法按照类别集成、提取和整合进行内容编排。特别注意的是在自动驾驶领域的应用部分。
全文93页,其中参考资料占了30页,880个参考资料。
该文目录如下:
数据驱动学习,首先是深度学习,已经成为当前绝大多数人工智能(AI)和机器学习(ML)应用中的关键范例。许多监督学习的模型,其出色性能主要归功于大量标注数据的可用性。突出的例子是图像分类和目标检测、序列数据处理以及决策。不利的一面是,这种前所未有的性能是以缺乏可解释性和透明度为代价的,这也导致了所谓的黑盒模型,不允许简单直接的人工检验。
因此,将数据驱动的方法转移到安全-紧要的应用程序成为了一个重大挑战。通常,在这些情况下,由于高获取成本,或者至少出于伦理原因,标记数据比较稀缺。此外,开发人员和用户都假定需求能够理解所部署模型推理的决策。为了解决这两个问题,开发知识源的方式,如物理基本定律、逻辑数据库、某些场景的常见行为或简单地反例等,是发展纯数据驱动模型去增强抗干扰能力、更好地泛化未知样本、以及和安全可靠行为的现有原则保持一致的关键。
2.1 感知:作者是Rizvi, Munir, van Elst
计算机视觉方法和一般的机器学习(ML)方法在过去几年中有了显著的改进。各种不同的方法能够准确地解释图像或视频中呈现的情况。即使有了这样的进步,在某些情况下,ML方法的反应与人类不同。造成这种差距的主要原因是所学模型缺乏背景知识。
ML方法只考虑训练数据中存在的模式,而人类拥有可以帮助他们更有力地解释危急情况的隐性知识。在自动驾驶场景,也是一般情况下,不可能针对道路上可能发生的每种情况去训练模型。为了给行人和自动驾驶车辆提供更安全的环境,重要的是将知识并入负责做出重要决策的模块中。
2.2 环境理解:作者是Bogdoll, Vivekanandan, Qureishi, Schunk
配备4级或5级自动驾驶系统的车辆有望在其ODD内掌握各种情况。由于许多情况在现实生活中并不经常发生,基于ML的系统很难在已经训练过的领域进行推断。因此,将基于规则/知识的算法和领悟,集成到ML系统中,这样的混合方法有可能将两个世界的最佳特性结合起来——出色的总体性能和对罕见情况(如极端案例)的改进处理。
2.3 规划:作者是Bührle, Königshof, Vivekanandan, Nekolla
L5级自动驾驶车辆,预计将在各种ODD发挥作用。虽然安全舒适驾驶的基本原则保持不变,但交通法规、习惯行为和场景结构层面的具体实施可能会发生变化。将知识纳入运动规划系统将通过增加可追溯性(例如,在碰撞重建的情况下)和可靠性,更容易处理这些情况。此外,基于人类-机器共识的透明决策过程将提高可解释性和信任度。预计会出现大量模拟测试的替代方案,这是当前验证的概念核心。
强调一下知识整合的优势。一种方法扩展智体的奖励函数,以社会规范的形式整合规则,例如,以最小距离通过目标。违反这些规则,将导致奖惩。结果发现有这种限制的智体表现出与人类更相似的行为。因此,当将知识整合到机器学习流水线时,不仅对于专家而且对于普通人,模型变得更具解释性和可信,因为这些约束发生在日常生活中。
此外,对智体知识的扩展减少了学习努力,从而加速了训练,并在大多数情况下能够超越原基准算法。尽管有这些有希望的好处,但集成知识通常会缩小各种可能解决方案的范围,同时耗费人力进行手工劳动。这收缩了机器学习最初的、整体的方法。因此,需要仔细选择知识整合和自学习之间的权衡。
符号(symbolic)和亚符号(sub-symbolic)方法代表人工智能的两端。然而,在数据驱动的亚符号/统计世界中,符号空间中用于集成或扩充的知识表示仍然存在一个核心挑战。
3.1 符号表征和知识制作:作者是Mattern, Gleißner
-
符号表征
与数字表征(例如矢量嵌入)不同,符号表征使用符号来表示事物(汽车、摩托车、交通标志)、人(行人、驾驶员、警察)、抽象概念(超车、刹车、减速)或非物理事物(网站、博客、上帝)及其关系。符号知识表征包括各种逻辑形式主义,以及用属性、类层次结构和关系表示实体的结构知识。
逻辑形式主义用来将知识(主要是事实和规则)表示为形式逻辑术语。逻辑形式主义或逻辑系统在表现力、复杂性和可判定性方面有所不同。正确形式主义的选择取决于要建模的具体问题。最简单的(可判定)逻辑形式主义是命题逻辑(propositional logic)。它由一组代表单个命题的符号和一组定义命题之间关系或修改命题数值的连接而组成。命题的值可以是true,也可以是false。
为了使逻辑陈述适用于许多目标,谓词逻辑(predicate logic),也称为一阶逻辑(FOL),用真值函数、谓词、常量、变量和数量词扩展命题逻辑。谓词逻辑比命题逻辑更具表现力,但并不总是可判定的,这意味着不能在每种情况下推断语句的真值。
法律规范的计算机可解释形式化是法律信息学领域的一个活跃研究课题。法律规则和规范的形式化有多种逻辑形式,例如标准道义逻辑(SDL,Standard Deontic Logic)、具体化输入输出逻辑(Reified Input-Output Logic)或(非道义的)时域逻辑(Temporal Logic)。然而,对于“最佳”逻辑形式主义仍然没有共识。为了使形式化的法律规则对可能的(道义的)逻辑系统不可知,要使用法律规范的中间形式表征。
-
知识制作
关于实体、概念、层次结构和属性以及与另一个实体的关系,这些知识可以自然地通过图结构表征。结构知识的图结构表征的突出例子是分类法(Taxonomies)、本体论(Ontologies)和知识图(Knowledge Graphs)。
“知识图获取信息并将其集成到本体中,并应用推理机来获取新知识。”在知识图中,来自异构数据源的数据通过上下文信息和元数据(例如,有关来源或版本信息)进行集成、链接和丰富,并用本体论进行语义描述。通过链接结构,知识图在语义搜索应用程序和推荐系统中得到了显著的应用,而且在以本体形式呈现规范元提要(meta-schema)时,也允许逻辑推理。
-
应用
符号表征,通过将检测目标映射到当前交通场景的正式语义表征(例如,场景图),改进了场景理解。为了将知识集成到机器学习算法中,这种知识的表示是必不可少的。虽然这种知识是以嵌入的形式存在的,但符号表征允许追溯,并使其为人类所理解。
给定交通规则的合理形式化,以及交通场景中实体、行为和法律概念的语义表征(类似于隐私概念中的法律本体建模),可以得出自动驾驶车辆的当前法律状态。
类似于将符号表征应用于形势理解,用交通规则和法律概念的形式表征以及符号场景描述,通过对可能的替代轨迹和动作进行排序,例如根据法律后果,来执行规划任务。
3.2 知识表征的学习:作者是Zwicklbauer
数据驱动和知识驱动的人工智能系统,二者优势和劣势互补,导致大量研究工作集中在符号(如知识图KG)和统计(如NNs)方法的结合。一种很有希望的方法是将符号知识转换为嵌入式表征,即先验知识的密集实向量,NNs可以去自然处理。符号知识的典型例子是文本描述、基于图的定义或命题逻辑规则。
知识表征学习(KRL)的研究领域旨在将先验知识(例如实体、关系或规则)表示到嵌入表征中,用于改进或解决推理(inference)或推想(reasoning)任务。大多数现有文献将KRL定义为仅从知识图转换成先验知识,从而缩小了问题的范围。这里讨论重点也在于基于图结构的知识建模。
-
规则注入的嵌入表征
知识图最近图神经网络(GNN)被引入,致力于显式地建模(知识)图的特性。特别是,多个关系图的图卷积网络(GCN)将非决定性神经网络推广到非欧几里德数据,并从实体的邻域收集信息,所有邻域在信息传递中的贡献相等。图卷积网络大多建立在节点聚合(node aggregation)的消息传递(message passing)神经网络框架之上。
图注意网络(graph attention networks)采用邻域注意操作可以增强图神经网络的表征能力。与自然语言模型类似,这些方法在聚合消息时应用了多头自注意机制,关注特定的邻域交互。最近有采用生成对抗网络(GANs)改变这种表征的质量,其中生成器经过训练生成负样本。
除此之外,特定的规则(软或硬规则)可以从知识图中派生出来,也称为规则学习(rule learning),或者在嵌入式学习过程中采用,也称为规则注入(rule injection)。
除了直接从底层知识图中挖掘规则外,还有其他方法试图应用更多外部规则。例如,通过使用非负性和近似蕴涵(entailment)约束来学习紧凑的实体表征,提高嵌入对规则建模的能力。前者自然地诱导稀疏性和嵌入可解释性,而后者可以在编码分布表征中关系之间的逻辑蕴涵规则。
也有将关系编码为凸区域,这是考虑不同关系之间依赖关系先验知识的自然方式。有一种方法Query2box,将实体(和查询)编码为超矩形(hyper-rectangles),也称为框嵌入(box embeddings),以克服点查询的问题,即一个复杂查询表示了其答案实体的一个潜在大集合,但不清楚如何将这样一个集合表示为单个点。框嵌入也被用于建模不确定性本体概念的分层特性。
目前,知识图在自动驾驶领域的应用还没有受到太多关注,尽管是一种帮助理解形势或场景的有效方法。
有大量的方法和途径侧重于额外的先验知识增强数据驱动的模型和算法。其中最突出的方法是通过定制成本函数修改训练目标函数,尤其是受知识影响的约束和惩罚项。这个通常伴随着特定问题的体系结构设计,导致混合模型以逻辑表达或知识图的形式应用符号知识。符号和亚符号方法的合并,称为神经符号集成(neural-symbolic integration)。
除了外部输入,最近的方法最好依赖于内部表征,以便将注意力集中在网络本身的确切特征和概念。最后但并非最不重要的一点是,数据增强(data augmentation)技术构成了将额外的领域知识集成到数据的主干,从而间接集成到模型之中。
除了这些流行的通用方法外,更适合自主驾驶领域的方法和范例,会考虑到多个与特定环境交互的智体。比如状态空间模型和强化学习去推断和预测智体的状态,还有信息融合方法中位置信息和语义信息的参与。
4.1 辅助损失和约束:作者是Werner, Pintz, von Rueden, Stehr
机器学习中常用的经验风险最小化(ERM),原则相当于用ERM来代替难以解决的风险最小化,即真实数据分布的预期损失。预期损失与其经验近似值之间的不匹配导致ERM产生的模型不能很好地推广到未见的数据。这表现为过拟合,即模型对训练数据的描述过于仔细,无法捕捉整体数据分布;或者表现为欠拟合,即模型无法捕捉数据的根本结构。正则化方案,可缓解过拟合的问题。结构风险最小化(SRM)原则扩展了ERM原则,即正则化。
SRM寻求在经验风险和模型复杂性之间最佳折衷的模型,通过Vapnik-Chervonenkis dimension(VC维度)或Rademacher复杂度来衡量。在实践中,通过增加正则化项来最小化经验风险。这项技术成功地进入了变量选择(variable selection)域,如开创性工作LASSO。正则化通常被证明在高维回归、分类、聚类、排名和稀疏方差或精度矩阵估计等应用中,是不可或缺的。
-
通过辅助损失的知识集成
至于知识注入到人工智能(AI),一种自然的策略是,类似地使用与形式化知识(formalized knowledge)相对应的正则化术语(所谓的辅助损失)。然而,约束也可能以硬约束的形式出现,例如,如果一定不能违反某些逻辑规则,那么通过辅助损失以软约束方式集成是不合适的,例如依赖性或正则化先验知识。
为了提高公众对自动驾驶车辆的接受度,深度模型的可解释性(interpretability)和解释性(explainability)改进相当有意义。知识集成,除了得到更好的泛化性能外,一个重要副作用是通过至少部分解释知识的预测,提高了模型的解释性和可解释性(explainability and interpretability)。
基于知识的正则化项,有可能通过鼓励机器学习模型尊重现有知识显著改进模型,这样在训练期间从零开始重新学习这些知识效率更高。要注意的是,如果数据中不存在知识(例如,如果与罕见情况相关),或者如果无法轻松从数据中导出知识,也可以通过损失和惩罚项进行知识整合。
-
其他约束的知识集成
损失函数中添加基于知识的正则化项通常以软方式强制约束。然而,在许多情况下,我们希望确保完全满足约束,即要强制执行硬约束,对应于带无限正则化参数的辅助正则化项情况。除了辅助损失外,通常还采用其他约束并入(constraint incorporation)方法,如结构改变,或不同优化方案,如projected gradient descent 或者 conditional gradients。
-
基于知识DNN的不确定性量化
一种不确定性量化方法,是物理引导的架构与蒙特卡罗(MC)dropout结合。物理引导的神经网络方法仍然产生黑盒模型,权重的随机下降再次导致物理上不一致的预测。
通过引入物理通知的连接和物理中间变量,赋予某些神经元一种物理解释,可解决这个问题。一种保持单调性的LSTM(Long Short- Term Memory),提取时域特征并预测中间物理量(水密度),将其硬编码到体系结构,这样满足单调性。然后,多层感知器(MLP)将这些预测与输入结合起来,得到预测响应。MC dropout注入的扰动不会破坏与物理知识的一致性。针对前向和逆向随机问题,调用多项式杂乱(polynomial chaos)和MC-dropout,得到一种dropout方法的变型,用于物理引导NNs的不确定性估计(近似不确定性和参数不确定性)。
-
应用
知识整合涉及到几个感知任务,即目标检测、语义分割、人体姿势估计、跟踪、轨迹预测和规划等。
4.2 神经-符号集成:作者是 Gleißner, Gottschall, Hesels, Srinivas
机器学习和深度学习技术(所谓的亚符号AI技术)已被证明能够在多种类型的模式识别任务中取得优异的性能:图像识别、语言翻译、医疗诊断、语音识别和推荐系统等。
虽然那些需要处理大量噪声输入的任务准确性通常与人类的能力相当,甚至更高,但它们也有一些缺点:通常无法为输出提供任何理由,需要(太)多的数据和计算能力来进行训练,易受对抗攻击,经常被批评在训练分布之外(OOD)泛化能力较弱。另一方面,“经典”的所谓符号AI系统,如推理引擎(reasoning engines),可以提供可解释的输出,但在处理有噪声的输入表现不佳。
符号AI域和亚符号 AI域的融合方法是神经-符号集成的目的。其目标是通过集成这两个域的方法来弥补彼此的缺点,并结合彼此优点。AAAI 2020上给出第一个神经-符号集成的分类法:
-
通过符号输入(如机器翻译)创建符号输出的神经网络
-
符号问题求解器的神经模式识别子程序,例如AlphaGo核心神经网络中的蒙特卡罗搜索(MCTS)
-
将神经和符号连接在一起并利用其他系统输出的系统,例如神经-符号概念学习者(concept learner)或与符号规划器(symbolic planners)合作的强化智体
-
将知识编译到网络的神经网络,例如if-then规则
-
嵌入神经网络的符号逻辑规则,执行正则化
-
能够进行符号推理的神经网络,如定理证明
-
用于推理的神经符号方法
GNN在解决推理任务时有两个主要优势。通过架构直接应用归纳偏差(inductive bias),由于其更新和聚合功能而提供排列不变性(permutation invariance)。排列不变性简化了文字和子句的表征。因此,逻辑符号的顺序并不影响这些子句的学习和理解。GNN应用视觉场景理解和推理,优于卷积神经网络。
一阶逻辑的张量化(Tensorization)是另一种集成深度学习和神经符号解决推理任务的方法。实逻辑(Real Logic)是一种多值、端到端可微分的一阶逻辑,由一系列常量、函数、关系和变量符号组成。根据这些符号建立的公式可能部分正确,因此实逻辑包含模糊语义。
常量、函数和谓词也可以是由域符号表示的不同类型。逻辑还包括连接词和量词。语义上,实逻辑将每个常量、变量和术语解释为实数的张量,而每个函数和谓词解释为实函数或张量运算。
此外,还有多种相关方法将逻辑推理和深度学习结合,同时具有端到端的可微分性:
-
逻辑神经网络使用逻辑语言定义其架构。通过应用加权实逻辑,采用不同的激活函数表示不同的逻辑算子,建立树状结构的神经网络
-
DeepProbLog是一种概率逻辑程序语言,实现一个神经网络,通过应用逻辑推理来解决推理任务
-
用于上下文理解的神经-符号架构
这里讨论神经符号的两种应用。
第一个应用侧重于自动驾驶,用知识图嵌入(Knowledge Graph Embedding)算法将知识图转换为向量空间。知识图是从NuScenes数据集生成的,由给定有场景正式定义的场景本体(Scene Ontology)和分类系统定义的兴趣特征(Features-of- Interests)和事件的子集组成。通过创建知识图和知识图嵌入,可以计算场景的距离,并找到视觉上看上去不同的类似情况。提出的创建知识图嵌入方法有TransE、RESCAL和HoIE,其中TransE在定量知识图嵌入质量(Knowledge Graph Embeddings-quality)度量上表现出最一致的性能。
第二个应用是“神经问答(Neural Question-Answering)”,通过基于注意的注入(attention-based injection)进行知识整合。该方法利用来自ConceptNet 和 ATOMIC的知识,将常识知识融合到BERT的输出,这样注入选项比较网络(Option Comparison Network)。在CommonsenseQA数据集评估分析表明,基于注意的注入更适合于知识注入。
-
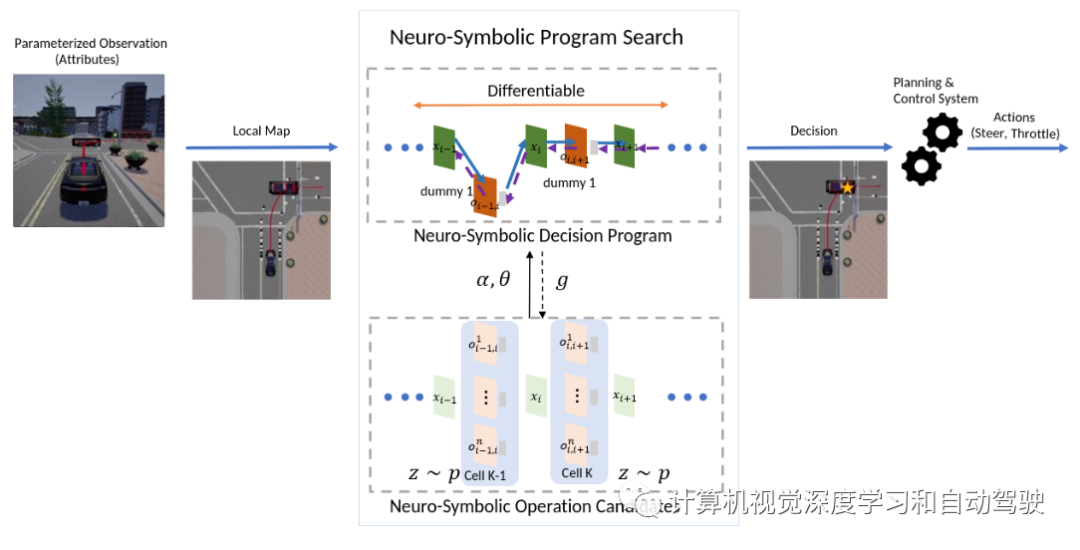
用于自主驾驶决策模块设计的神经符号程序搜索
采用神经结构搜索(NAS)框架,自动合成神经-符号决策程序(NSDP,Neuro-Symbolic Decision Program),可以改进自动驾驶系统的设计。神经-符号程序搜索(NSPS,Neuro-Symbolic Program Search)通过融合神经符号推理和表征学习,合成端到端可微分神经符号程序(NSPS,Neuro-Symbolic Programs)。
驾驶决策的符号表示用Domain-Specific Language(DSL)描述,用于自动驾驶。DSL包含用于驾驶部件的基本原语(basic primitives),以及用于强制执行更高级优先级的条件语句。DSL的设计允许在可微分神经符号行为范式指定自动驾驶的所有行为。
此外,NSPS被描述为一个随机优化问题,可以有效地搜索集成神经-符号操作的程序架构,确保端到端学习的可能性。如图所示:NSPS与生成对抗性模仿学习(GAIL)相结合,以端到端的方式学习生成神经符号决策程序,向运动规划器和控制器输出特定指令(例如,目标航路点索引和目标速度);其中NSPS搜索NSDP,通过反向传播g更新α和β。
-
应用
首先是感知。神经符号推理引擎可以利用世界知识或常识知识来理解感知模块或这些模块组合的场景。它可以作为一个正则化器(语义损失函数)在训练感知神经网络过程中发挥作用,该神经网络描述场景,并惩罚被识别实体及其属性或关系的不合理组合。第二,在推理过程中同样的原理也适用,在推理过程中,感知模块输出多个可能的场景描述,推理引擎检查场景中的矛盾元素,从而评估输出的合理性。
在某些情况下,基于注意的注入方法可以用于推理,例如通过将Straßenverkehrsordnung(StVO)注入QA网络,在BERT中编码新的句子。DSL可以设计为包含StVO逻辑规则以及基本属性(例如,速度、加速度、姿势、关联车道类型、车道属性和道路类型),强制执行更高级的机动优先级。
NSPS框架结合NAS的机制,可以用于为下游运动控制和规划任务生成决策策略。类似地,NSPS框架生成神经-符号行为程序(NSBP),对目标车辆的行为进行推理,支持场景中的协同规划(cooperative planning)。合成的NSBP应是涉及神经-符号运算(数值运算和逻辑运算)的操作,而不是普通的神经网络。NSPS框架和GAIL可用于端到端的方式学习NSBP。
其次是规划。形式化知识(formalized knowledge)的创建需要一种能够验证结果形式化的方法。其中一种方法是对测试用例查询形式化(querying the formalization),比如检查StVO目前形式化是否包含不需要的属性,例子是为救护车让路而危及行人是可以的。这些查询也是形式化的语句,并由形式化知识的神经符号推理引擎(neural-symbolic reasoning engine )来回答。
法律知识的形式化是检查特定交通状况采取或计划采取的行动是否符合StVO等法规的先决条件。神经符号推理机可以执行此类合规性检查,增强自动驾驶领域如下两个应用:首先,规划器用合规性检查评估多个行动方案;其次,在规划器的训练阶段,合规性检查可以被用作正则化,迫使模型更倾向于合规的、而不是不合规的解决方案。
4.3 注意机制:作者是Qiu
人类可以将注意力集中在视野或近期记忆中的特定区域,以避免过度消耗精力。受人类视觉注意的启发,算法的注意机制成为深度学习中的一个流行概念。与NLP的注意概念类似,许多机器学习任务也需要有效地关注特定的数据或信息。这种特定的关注点来自于对目标任务非常有帮助的先验知识或经验。
此外,这些注意力集中的信息通常对人类的理解是直观的,并且提供了有用的解释能力。例如,图像字幕任务在输入图像上查找热图,该热图指示字幕词所指的位置。如果将注意机制视为人类知识的一种形式,那么学习这种语义知识有望提高网络性能。
在计算机视觉(CV)任务中,注意机制分为三种不同的建模方法:空间注意、通道注意和自注意。
CV中的注意机制广泛应用于行人检测等自主驾驶感知任务中。注意机制不是直接用于规划,而是用于规划或决策的可解释性。Berkeley Deep Drive用注意热图来解释为什么车辆会采取某种控制器行为,并生成文本解释。注意机制在训练过程中不断更新,同时也最终影响训练结果。对于场景理解,它被认为不是一种可行的方法。
4.4 数据增强:作者是Matthes, Latka
数据增强(DA)包括一系列技术,以很少的额外成本增加数据量。DA提供了一种集成知识的方法,有关输入信号的具体变化如何影响模型目标输出,例如对小扰动的不变性。使用增强数据进行训练,通常可以提高模型的泛化能力,在数据稀缺或不平衡的情况下尤其有用。
可以使用哪种技术取决于输入数据的格式(例如,图像、音频、点云)和机器学习的任务。应用的算法必须保留与任务相关的信息。例如,颜色空间扭曲可能有助于基于图像的车牌识别(使模型对颜色变化更加鲁棒),但可能会降低鸟类物种分类的性能,因为颜色是许多物种的重要区别特征。对于某些任务,例如密度估计,定义适当的数据增强本身就很困难。另一方面,DA甚至是一些无监督模型的组成部分,例如在对比学习中。
结构因果模型(SCM,Structural Causal Models)对环境知识进行编码。这方面,可以被视为数据生成过程。从数学上讲,SCM无非是一个有向无循环图(DAG),同时具有一组函数和DAG根节点的分布。虽然DAG的节点对应于环境变量,但其有向边表示变量之间的独立因果机制。特别是,因果机制描述了变量如何以确定性的方式相互影响。
因此,每个SCM自然地定义了其变量的联合分布。所以,其形状由函数集和SCM根变量的分布决定。此外,分布飘移可以在SCM框架中建模为干预措施,例如,将一种功能转换为另一种功能。
SCM非常适合随意生成有效且一致的样本,因为它们与SCM中编码的因果关系一致。通过这种方式,SCMs可以作为一种轻量级的底层环境模拟器,根据具体的干预设置,产生不同的干预分布。更准确地说,任意的训练集可以被认为是由单个分布组成的。这些单独的分布既可以表示未修改SCM所定义的分布,也可以源于生成数据时应用于原始SCM的不同干预。
因此,干预措施有效地改变了环境,涵盖了环境的合理变化。通过这种方式,从不同的联合分布和干预分布(由原始SCM构建)中采样数据,自然会增加整体训练分布的多样性,可解释为某种数据增强方法。
作为自动驾驶环境下数据增强的另一个例子,例如,一个描述车辆轨迹的SCM(即,将车辆状态和动作连接到新状态的物理定律)。车辆运动的新轨迹可以通过车辆SCM根据后续步骤从现有轨迹生成。
首先,外部(通常是)未观察的随机变量是从现有轨迹(称为诱拐步骤)推断出来的,有效地重建了记录观察轨迹时车辆所处的情况。
其次,对车辆SCM应用一项干预或一系列干预(操作),同时从诱拐步骤维持更新的分布。
第三,(干预后的)SCM预测一条基于观察轨迹的新轨迹。刚才描述的过程返回了一个所谓的反事实(counterfactual)轨迹,如果采取了另一系列行动,该轨迹可能已经演变。从这个意义上说,这种技术将观察轨迹转换为反事实轨迹,同时遵守SCM中未被干预的其他部分(数据转换)。
因此,该技术允许以一种方式增强数据,即仍然固定在一个观察轨迹上,但同时生成更多数据,尤其是覆盖危险和代表性不足的场景。此外,该技术被证明有助于解释机器学习(ML)模型决策的原因。
4.5 状态模型:作者Reichardt
驾驶本身就是一种连续的动态活动。感官信息是通过一系列观察获得的,这些观察在很大范围的时间尺度上表现出因果依赖性和相关性。
作为一个被动观察者,理解任何动态现象的能力取决于预测未来观察结果的能力。概率上讲,动态过程可能固有的随机性,只能根据分布来理解和建模,而不是单个结果。一旦得到必要的分布,就能够优化/规划动作,增加预期未来结果和观察出现的机会。
牢固植根于概率论的状态空间模型(SSM),特别适合于研究源自交通现象的稳定信息流,已经渗透到驾驶的各个方面,从感知到形势理解和规划。
在知识集成的背景下SSMs代表了一个算法先验,提供了概率分布的框架及其相应的条件独立结构。然后可以使用数据驱动的方法来学习这些概率分布的参数化。理想情况下,优化和学习可以端到端地实现。
先说在感知的应用。
自动驾驶的感知阶段,通过生成观测模型或观测似然,可进入SSM。原则上,观测值可以是原始的感官输入,如相机图像或激光雷达点云,但如果不做强近似,目前这种思路在计算上是不可行的。一种替代方法是放弃观测模型的生成性,学习直接估计后验状态密度,这种方法被称为鉴别滤波器。然而,请注意,这种方法仅适用于固定历史长度,因此牺牲了在任意长度时间内标准公式表示相关性的能力。
第二种方法是通过检测算法对原始传感器数据进行预处理,产生与目标级数据相对应的观测值。这与“tracking- from-detection”的范式相对应。进一步区分的话,一个目标要么最多只能进行一次检测(“点检测算法”),要么进行多次检测。如果后者不是伪影(artifacts)而是多个传感器读取目标物理扩展的结果,则会产生所谓的“扩展目标跟踪(extended object tracking)”算法。如果可以从每个可用的传感器模态中进行检测,则观测似然是执行传感器融合的自然方法。或者,在原始传感器应用检测算法之前,先执行传感器融合。
与在交通中观察到的一组目标相对应,检测算法将返回一组检测结果。然而,检测算法并不完美。可能存在所谓杂波(clutter)的错误检测,而这些杂波并非来自实际目标。也可能是由于检测算法的遮挡或故障当前时刻不被检测的目标。
此外,检测不一定被标注,即,跟踪目标与其检测之间不存在已知的对应关系。由此产生多目标跟踪的所谓数据关联问题:需要找到观测集元素与被跟踪目标集元素之间的这种对应关系。有标准算法可以解决这个问题。一旦建立了这种对应关系,并且更新了跟踪目标的后验状态估计,就无法恢复任何在更新错误检测目标的状态向量时发生的错误。
为了缓解这个问题,所谓的多假设跟踪(MHT)算法保留了几个看似合理的潜在数据关联假设,直到通过额外证据数据关联中可能存在的不确定性得到解决。
SSMs的另外两个方面与感知模块有关,可以知识集成。第一种是所谓的出生(birth)模型,可以表示传感器的灵敏度,以及物体将在何处以及如何进入自动驾驶车辆传感器范围的先验。第二个是可以进一步指定观测模型的探测概率、生存概率和杂波强度等。
SSM的一部分吸引力在于,它们可以用于对移动交通参与者以及从移动传感器看到的静态环境进行建模。
形势理解主要包括两个关键任务,即根据过去的观测值估计和跟踪系统的当前状态,即状态跟踪和滤波问题。具体而言,这涉及到地图和定位问题,即根据观察结果建模静态环境,并查找该环境中自车和其他交通参与者。
需要注意的是,状态更新方程的评估速度通常是新观测值可用的速度∆T≤ 50ms,因此运动模型用于非常短的预测范围。所以,人们通常使用简单的运动学模型,然后可以将模型不确定性充分建模为随机噪声,并使用数据来调整噪声分布。特别是,在多目标跟踪中,人们可能会假设单智体的运动是独立的,而忽略与环境和其他交通参与者的交互。这种简化会导致一种问题:随时间范围增长,当没有新的观察结果(例如由于遮挡)时候,错误会增加。
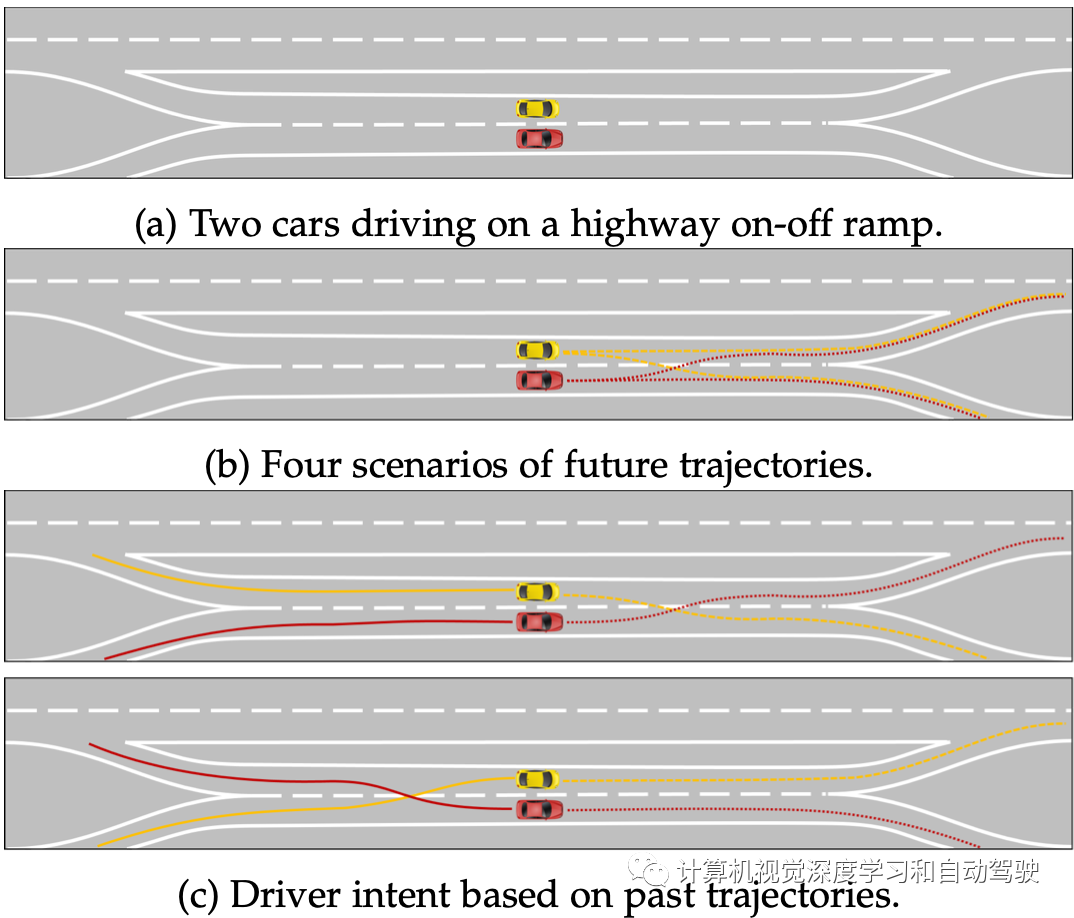
形势理解的第二项任务是将这种估计扩展到未来,并实现对安全舒适驾驶至关重要的预期规划。现在预测交通的状态在时间尺度上的演变∆t通常用于驾驶操作,即几秒钟,情况则变得明显不同。考虑如图所示的情况:其中描述了两辆车在高速公路入口匝道上行驶,出现潜在冲突的轨迹规划问题;现在,每辆车只有一条合理的未来轨迹,甚至场景未来演变的不确定性也降低了。这强调了对交通参与者的意图(intention)进行建模的必要性。
驾驶员意图通常被建模为一个不可观测的离散状态变量,表示几种可能的操作之一,如左变道、右转、跟车道。这些类别必须是相互排斥的,并且整体上是全面的,具体类别必须从观察中推断出来。通常,专门的运动模型与一个机动类别相关联,从而为此类机动目标提供所谓的多模型过滤器(multiple model filters)。
完全减少关于未来轨迹的不确定性,不总是可能的,所以必须为未来轨迹提供不止一种可能的选择。这意味着对单个交通参与者的运动以及场景中的整个交通参与者来说,预测都应该是多模态的。在分解(factorization)假设下,这可能会导致整个交通场景(包括许多具有冲突轨迹的未来场景)可能未来的组合爆炸(combinatorial explosion)。这个问题的解决可以通过相应的计算努力修剪这些冲突场景。更理想的是为整个交通场景建立一个运动模型,从一开始就产生无冲突的场景集。
4.6 强化学习:作者是Rudolph, Bogdoll, Josep
强化学习(RL)是一组技术,智体在一段时间内在给定奖励信号的情况下优化其行为。智体通过在每个时间步中执行操作与环境进行交互。根据当前状态及其过去经验估计的评估来决定选择哪种动作。这种从状态到动作的映射称为策略。随后,智体在每个时间步中都会收到奖励,这反映了智体行为局部评估的概念。
但是,通常情况下,仅凭这种即时奖励不足以判断一项动作有多好,因为只有在一系列有益的动作之后,才会给予更大的奖励,即智体面临一个连续决策问题。例如,智体在多个时间步中朝着正确的方向移动,以达到一个定义的目标。这就是为什么RL算法的目标通常是找到一个最大化预期累积奖励而不是即时奖励的策略。在过去的几年里,深度学习已经成为RL的主要形式,深度学习被用来实现RL智体。
RL大致可以分为两类,即无模型(model free)算法和基于模型(model-based)的算法。基于模型的算法利用预先给定或从经验中学习的环境显式模型。另一方面,无模型算法不使用这种模型,总是直接在环境中运行。另一个常见的分类是带策略(on-policy)和无策略(off-policy)算法之间的区别。前者只能改进智体当前执行策略的价值估计。相比之下,后者可以独立于智体采取的动作,提高对最佳策略价值的估计。
-
多智体强化学习
在多智体强化学习(Multi-Agent reinforction Learning,MARL)中,将智体与环境交互的基本思想扩展到多个智体同时与环境交互并彼此交互。
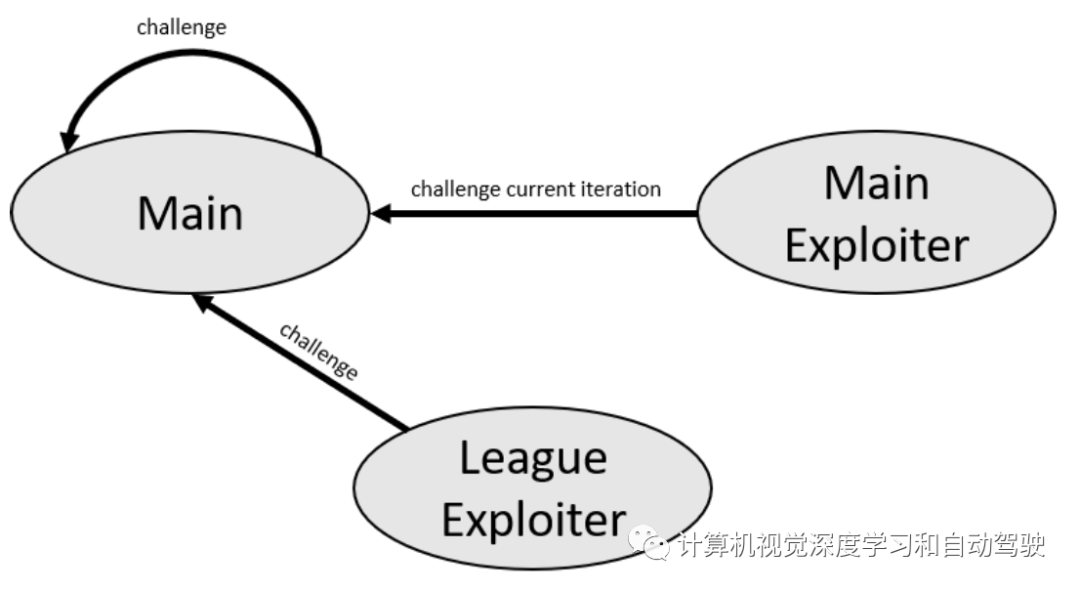
所谓联盟训练(league training ),其主要思想是与三种类型的智体展开虚拟的自游戏(参见如图):第一种类型被命名为主智体,使用优先虚拟游戏(fictitious play),这意味着根据对智体的获胜率选择对手。第二种类型是主剥削者(exploiter),与当前的主要智体竞争,只是为了发现其行为中的弱点。第三种类型是联盟剥削者(league exploiter agents),使用与主智体类似的策略,但不能成为主剥削者的目标。因此,他们有机会找到策略来利用整个联盟。
基于MCTS,有一个多智体的扩展已应用于简单的网格(grid)世界,其中每个智体必须学习移向到定义目标的一个,但每个格(tile)只能由一个智体使用。该方法用默认策略和随机策略的MCTS,并与奖励函数的差异评估(difference evaluation)相结合。
-
逆强化学习
当前另一种方法是逆强化学习(IRL)的思想,其中一个目标是学习与环境交互示例中的奖励函数,这个也可以和行为克隆一起属于模仿学习。
IRL解决了两个核心挑战:“找到一个能最好地解释观测结果的奖励函数基本上是不适定的”和“解决问题的计算成本往往会随着问题规模不成比例地增长”。这在复杂的自动驾驶领域尤其重要,因为现有的方法“不能合理地扩展到几十个状态或十多个可能的动作”。
根据四个类别对现有IRL方法进行分类。Max margin方法试图“最大化观察到的动作价值与假设之间的margin”,而max entropy方法则被设计为“最大化动作分布的熵”。Bayesian learning 方法“使用贝叶斯规则学习假设空间上的后验概率”,分类和回归方法“学习预测模型,其模仿观测行为”。此外,IRL还有许多扩展,可分为三类:“不完整和含噪的观测方法、多任务和不完整模型参数”。
-
强化学习和知识集成技术
-
奖励成型:知识集成最常见的形式是奖励成型。其思想是设计奖励函数,使智体更容易找到最优策略,同时仍在极限内优化原始目标。这在时间跨度较长且奖励信号稀疏的情况下尤其有用。
-
模型:在RL算法中集成先验知识的常用方法是利用某种环境模型。这种方法首先定义基于模型RL的区域。虽然这种趋势倾向于在运行时由智体学习的模型,但已经证明,人工设计的模型可以解决非常复杂的任务,并通过在学习系统中集成知识提高学习速度。
-
通过示范学习:通过示范学习(或学徒学习)的想法已经存在了一段时间。它定义了一个范例,人类展示学习系统的期望行为以加速学习过程。一种常见的方法是使用IRL。其他情况下,已经有了奖励信号也行。
-
辅助任务:将先验知识整合到神经网络的方法是辅助任务。其主要思想是在多个任务上共享一个网络,迫使其创建对主要任务有益的结构。
-
应用
有许多可以利用RL的任务,包括路径规划、控制器优化和基于场景的策略学习。大多是仿真环境的实验,因为数据收集和状态-动作空间维度的限制。
4.7 带先验知识图的深度学习:作者是Chuo, Chen, Stapelbroek
目标检测和识别问题通常通过深度学习方法来解决。然而,在模型精度方面,尤其在某些情况下,即物体被遮挡、距离传感器太远或光线条件差,仍然是一个巨大的挑战。
在提高数据效率方面,尤其是在数据容量较低的情况下,也存在挑战,找到一种提取和组合信息的方法变得很重要。
待续。。。
- 下一篇:综述:自动驾驶应用中知识增强的机器学习方法(二)
- 上一篇:一文梳理锂离子电池电解质



编辑推荐




最新资讯
-
全国汽车标准化技术委员会汽车节能分技术委
2025-04-18 17:34
-
我国联合牵头由DC/DC变换器供电的低压电气
2025-04-18 17:33
-
中国汽研牵头的首个ITU-T国际标准正式立项
2025-04-18 17:32
-
为什么要进行汽车以太网接收测试?汽车以太
2025-04-18 17:26
-
产品手册下载 | NI 全新USB数据采集-NI mio
2025-04-18 16:39
