




 广告
广告





















































BEVerse:自动驾驶视觉为中心的BEV统一感知和预测框架

arXiv论文“BEVerse: Unified Perception and Prediction in Birds-Eye-View for Vision-Centric Autonomous Driving”,上传于2022年5月19日。作者来自清华大学和创业公司鉴智机器人。

本文提出了基于多摄像机系统的3D感知和预测的统一框架BEVerse。与现有研究专注于改进单任务方法不同,BEVerse的特点是从多摄像头视频中生成BEV表征,并对多个任务进行联合推理,实现以视觉为中心的自动驾驶。具体来说,BEVerse首先执行共享特征提取和提升(lifting),从多时间戳和多视图图像生成4D BEV表征。在自运动补偿之后,利用时空编码器进一步提取BEV特征。
最后,加上多个任务解码器进行联合推理和预测。在解码器中,提出栅格采样器(grid sampler)来生成对不同任务支持不同范围和粒度的BEV特征。此外,还设计一个迭代流(iterative flow)方法,实现内存高效的未来预测。实验发现,时域信息可以提高3D目标检测和语义图的构建,而多任务学习以隐含方式有利于运动预测。
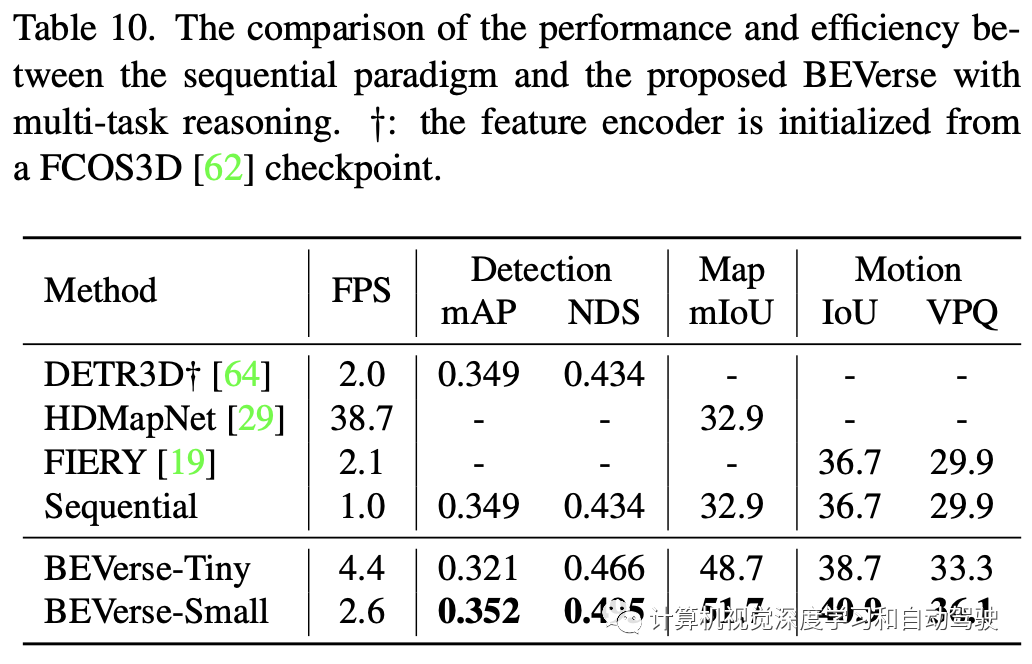
通过在nuScenes数据集上的大量实验,表明多任务BEVerse框架在3D目标检测、语义地图构建和运动预测方面优于现有单任务方法。与序列工作相比,BEVerse也有利于显著提高效率。
代码和模型今后将开源在https://github.com/zhangyp15/BEVerse。
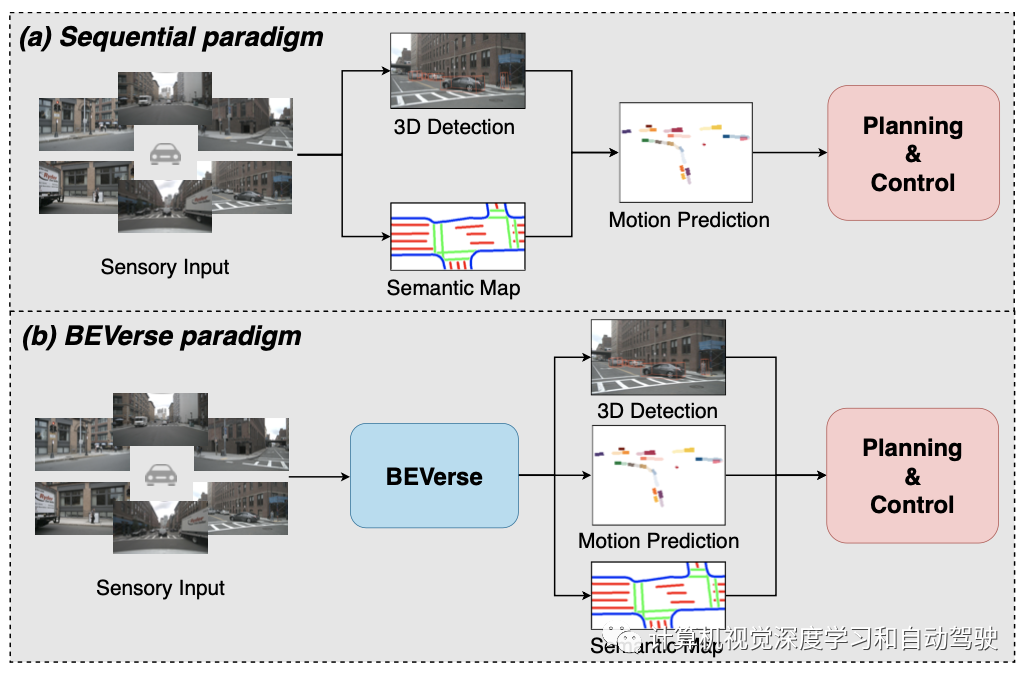
如上图所示,传统的范例是按序列堆叠这些子任务,其中一个子任务的输出作为输入馈送到下一个子任务。序列设计可以从整个系统中分割单个任务,为学术研究创造了独立和特定的问题。然而,错误的传播会显著影响下游任务。此外,由于重复的特征提取和传播,序列范式本身会带来额外的计算负担。而提出的BEVerse框架用于联合感知和预测,通过共享特征提取和并行多任务推理,在性能和效率之间实现了更好的权衡。
最近一些研究一直在探索以激光雷达为中心的自动驾驶系统感知和预测的联合推理。这些工作表明,由于共享计算的好处,多任务范式可以更有效,并且还可以实现最先进的性能,得益于时域融合和联合学习。考虑到激光雷达传感器的昂贵成本,大家研究的兴趣包括了以视觉为中心的方法,依赖于多个周围摄像头作为输入信息。
其他道路智体的未来行为对于自训练系统做出安全规划决策非常重要,已经提出了大量基于摄像头的运动预测方法。FIERY提出第一个直接从周围摄像头视频中进行BEV运动预测的框架。同时StretchBEV进一步提出在每个时间戳对潜变量进行采样,并预测残余变化产生未来状态。
FAF网络提出了一个整体模型,该模型将对检测、预测和跟踪进行联合推理。MotionNet提出了一种分层时-空金字塔网络,对激光雷达扫描序列中的BEV特征进行编码。然后,在不使用边框的情况下执行联合感知和运动预测。
与FIERY类似,本文方法也采用原始感知输入,在BEV坐标系下进行联合感知和预测。为了减少FIERY的内存消耗并支持多任务推理,提出一个用于未来状态高效生成的迭代流。
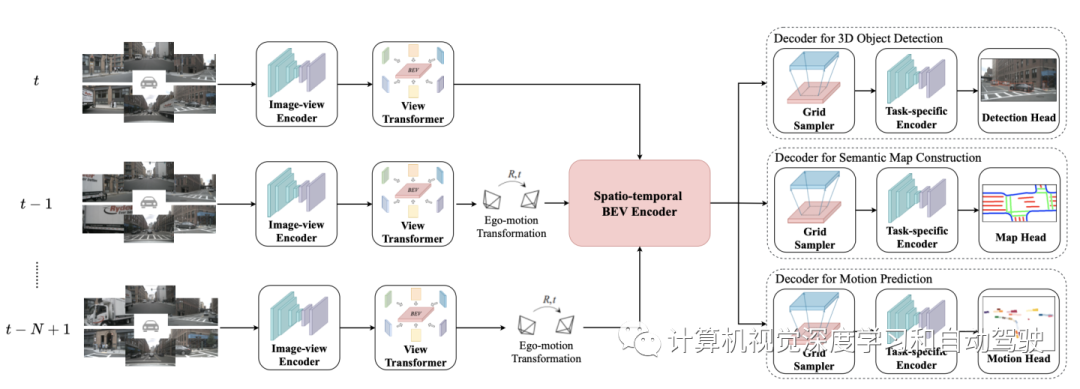
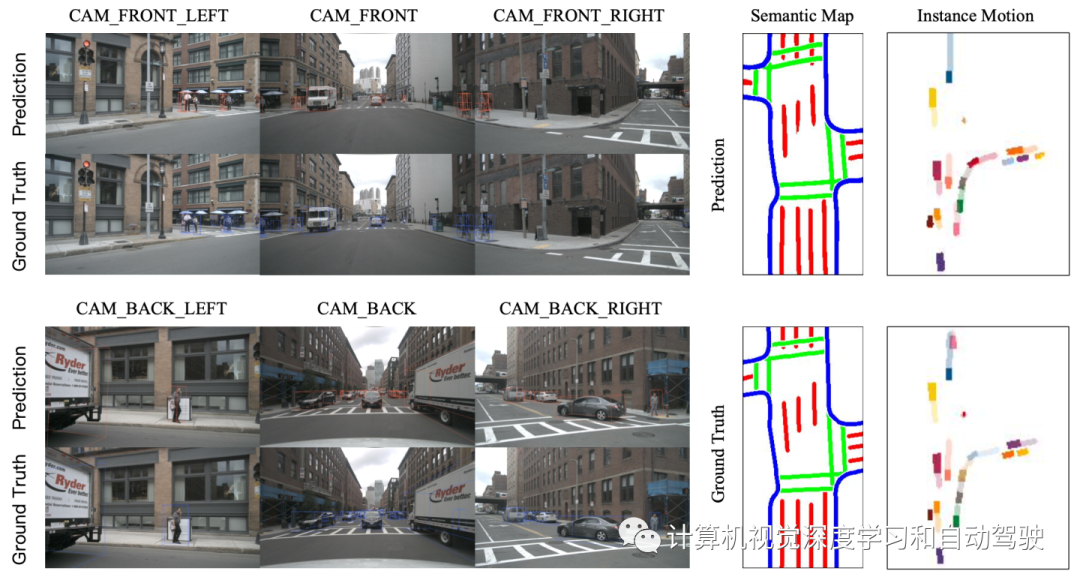
如图所示,BEVerse从N个时间戳中获取M个周围的摄像头图像,并将相应的自运动和摄像头参数作为输入。通过多任务推理,输出包括当前帧的3D边框和语义图,以及后续T帧的未来实例分割和移动。BEVerse由四个子模块组成,这些子模块依次为图像视图编码器、视图转换器、时空BEV编码器和多任务解码器。
图像视图编码器采用SwinTransformer做主干网,视图转换器采用Lift-Splat-Shoot(LSS)的方法,然后如FIERY时空BEV编码器由一组时域块组成。
多任务解码器是并行和独立的一组解码器组成,其中每个解码器包括栅格采样器、任务编码器和任务头。
由于不同任务可能需要特定的范围和粒度,输入BEV特征的空间范围和分辨率不能直接用于解码。例如,语义地图的学习需要细粒度特征,因为3-D空间的交通线很窄。因此,栅格采样器裁剪特定任务区域,并通过双线性插值转换为理想分辨率。实验中为提高效率,基本BEV栅格设置大而粗。
特征采样后,用轻量级任务编码器在相应的BEV栅格对特定任务特征进行编码。随BEVDet,作者用ResNet基本块构建主干,并结合图像视图编码器类似的多尺度特性。输出特征上采样到输入分辨率,并发送到任务头。
由于BEV的特征表征由多个摄像头视频构建,因此单目和激光雷达的方法之间的维度差距(dimension gap)已经消失。因此,为激光雷达设计的检测头可以直接采用,无需修改。本文使用两步法CenterPoint的第一步(stage)作为3D目标检测头部。
带有BatchNorm和ReLU的两个普通卷积层构建语义地图重建头,输出通道是语义地图中Cmap的类数。
还需要对未来状态进行预测。如上图(a)所示,FIERY首先预测未来高斯分布参数,并采样潜向量φt∈ RL,其中L是潜维度。采样的φt,在空域扩展为R (Xmotion × Ymotion × L)形状,并用于初始化未来状态。然后,重复应用ConvGRU(convolutional gated recurrent unit)网络块和瓶颈块,生成未来状态{st+1,st+2,···,st+T}。
影响FIERY预测模块有效性的两个重要因素:(1)每个BEV像素共享采样的全局潜向量φt,不能代表许多不同智体的不确定性。(2) 仅从采样潜向量初始化未来状态,这样会提高预测的难度。
为此,提出用于未来预测的迭代流,如上图(b)。与FIERY不同的是,这里直接预测和采样一个潜图R(Xmotion × Ymotion × L),这样可以分离不同目标的不确定性。
此外,通过预测流进行当前状态的warping,生成下一个时间戳的状态,这自然适应运动预测问题并简化了学习过程。生成未来状态后,用相同的输出头(如FIERY)预测未来实例分割和运动。
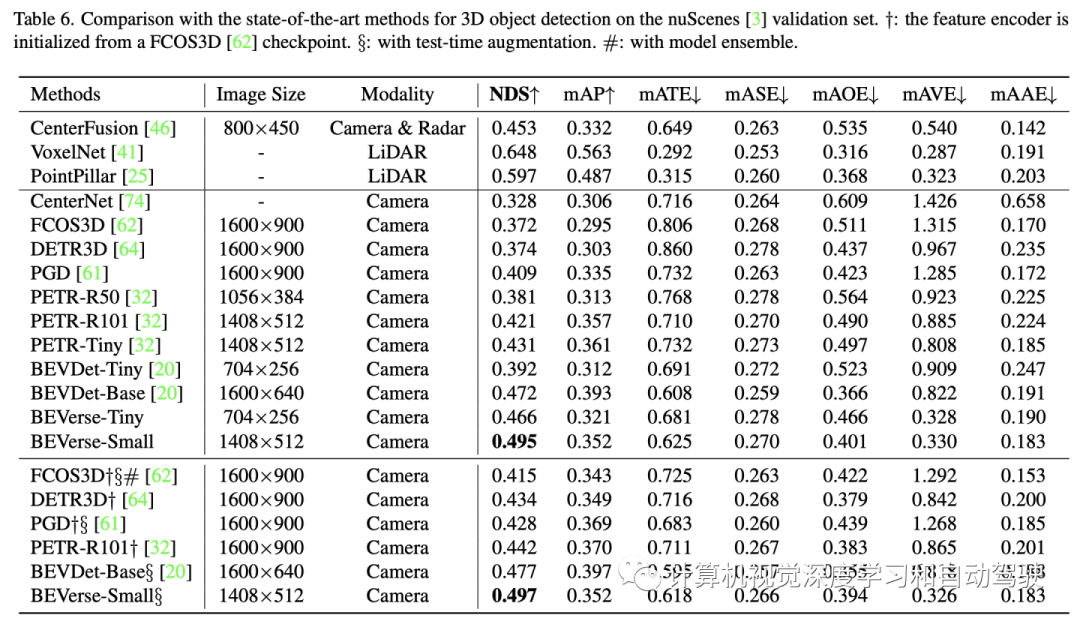
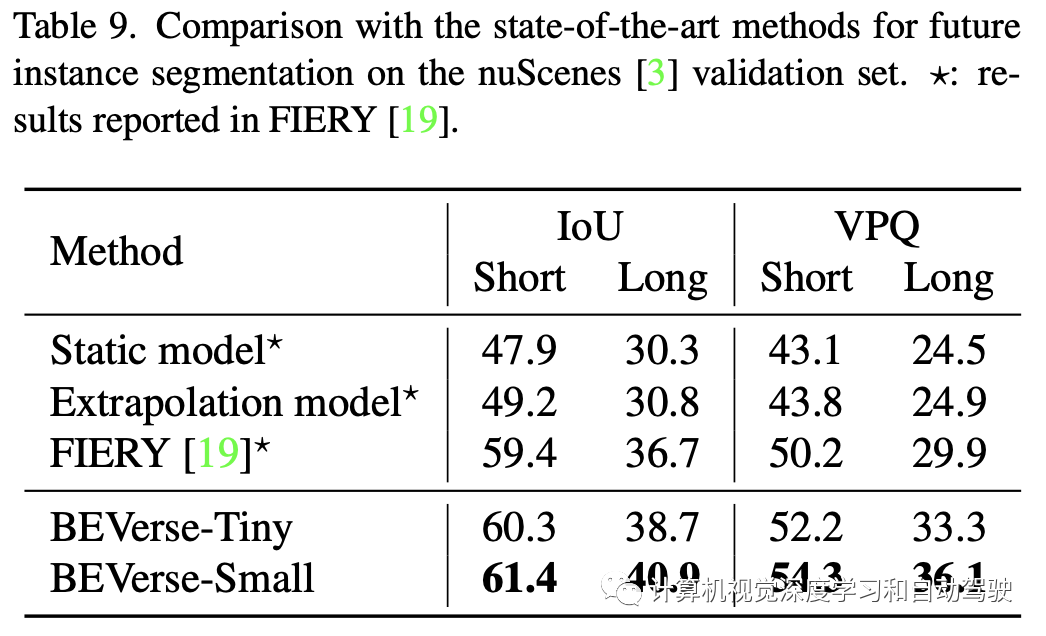
在nuScenes数据集进行综合实验。nuScenes数据集包括1000个在波士顿和新加坡收集的驾驶视频段。每个视频段长度为20秒,并以2Hz频率用3D边框进行标注,生成多达40k个关键帧和1.4M个目标边框。所有视频段正式划分为700、150和150,分别用于训练、验证和测试。对于以视觉为中心的方法,提供的感知输入包括六个周围的摄像头、内/外参数和自运动。
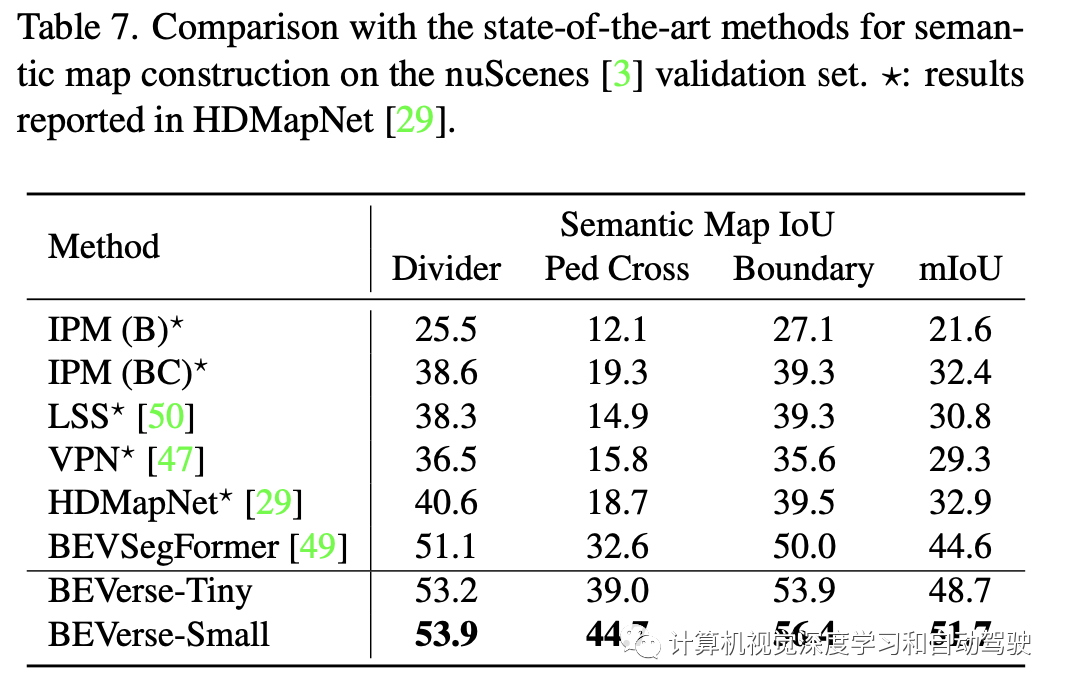
构建两个版本的BEVerse,即BEVerse-Tiny和BEVerse-Small,用于在性能和效率之间进行不同的权衡。BEVerse-Tiny使用Swin-T(33)作为主干,输入图像缩放至704×256,而BEVerse-Small使用更强Swin-S(59),图像缩放至1408×512。请注意,nuScenes数据集中的原始分辨率为1600×900。
按照FIERY设置,BEVerse获取过去三帧(包括现在)图像,感知当前环境,并预测未来四帧的实例运动(在nuScenes其时长2.0秒)。基于nuScenes的自车系统构建BEV坐标。
对于3-D目标检测,定义X-轴和Y-轴的BEV范围为[-51.2m,51.2m],间隔为0.8m。对于语义地图重建,X-轴范围为[-30.0m,30.0m],Y-轴范围为[-15.0m,15.0m],间距为0.15m。对于运动预测,X-轴和Y-轴的范围均为[-50.0m,50.0m],间隔为0.5m。
视图转换器的BEV栅格遵循检测设置。
对于模型架构实现,图像视图编码器的输出通道是512,并且在视图转换期间进一步减少到64。在时域模型和任务特定编码器之后,特征通道增加到256进行解码。对于每个任务的损失权重,遵循CenterPoint和FIERY的设置。为平衡多任务学习,将检测、地图和运动的权重设置为[1.0、10.0、1.0]。除非另有说明,否则所有报告的结果都是用多任务框架生成。
对于训练,使用AdamW优化器,初始学习率为2e-4,权重衰减为0.01,梯度剪辑为35。该模型使用CBGS进行了20 epochs的训练。对于学习安排,采用单周期(one-cylce)策略,峰值学习率为1e-3。在32个NVIDIA GeForce RTX 3090 GPU,为BEVerse Tiny/Small训练批量大小为64/32的模型。主干在ImageNet上进行预训练,其他参数随机初始化。对于推理,采用BEVDet提出的scale-NMS和加速技巧。
对于增强策略,严格按照BEVDet的设置来执行图像视图和BEV增强。图像视图操作包括输入图像的随机缩放、旋转和翻转。BEV增强包括类似的操作,但适用于BEV表征和相应的学习目标。为了保持一致性,对过去每一帧应用相同的增强操作。
实验结果:




编辑推荐




最新资讯
-
中汽中心工程院能量流测试设备上线全新专家
2025-04-03 08:46
-
上新|AutoHawk Extreme 横空出世-新一代实
2025-04-03 08:42
-
「智能座椅」东风日产N7为何敢称“百万级大
2025-04-03 08:31
-
基于加速度计补偿的俯仰角和路面坡度角估计
2025-04-03 08:30
-
《北京市自动驾驶汽车条例》正式实施 L3级
2025-04-02 20:23
