




 广告
广告





















































3D车道线单目检测方法ONCE-3DLanes

3D车道线检测论文”ONCE-3DLanes: Building Monocular 3D Lane Detection“,上传arXiv于2022年5月,是华为诺亚和复旦大学的工作。
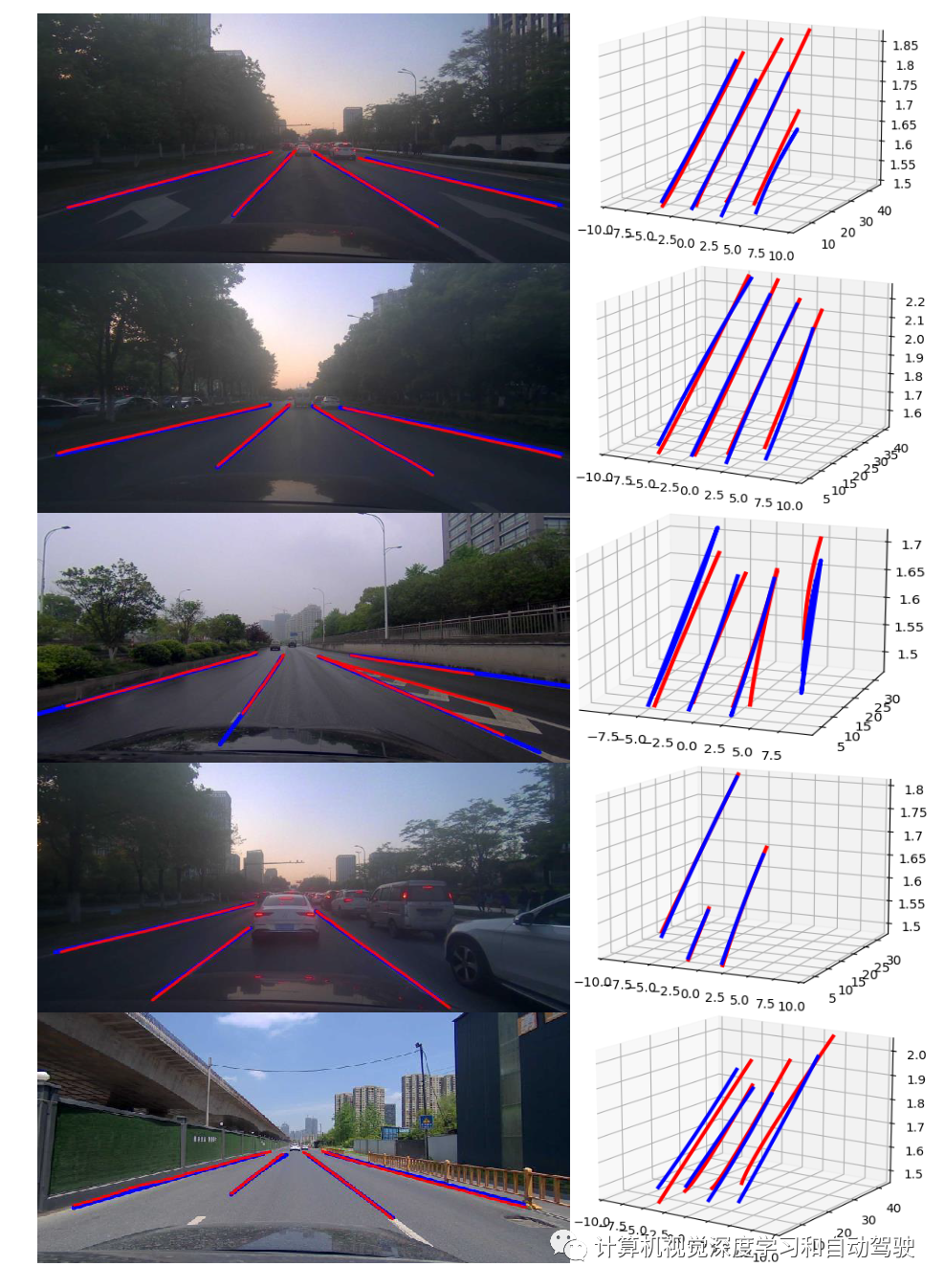
由于道路不平,传统的单目图像2D车道线检测在自动驾驶的跟踪规划和控制任务中性能较差。因此,预测3D车道线布局是必要的,可以实现有效和安全的驾驶。然而,现有的3D车道线检测数据集不多,一些还是模拟环境合成,严重阻碍了该领域的发展。
该文提出一个真实世界的自动驾驶数据集,ONCE-3DLanes,具有3-D空间的车道线布局标注。通过点云和图像像素之间的显式关系,文章设计了该数据集标注流水线,从211K个道路场景的2D车道线标注,自动生成高质量的3D车道线位置。此外,作者还提出一种无外参、无锚点的方法,称为SALAD,在图像视图中回归车道线的3D坐标,而无需将特征地图转换为BEV。为了促进未来对3D车道线检测的研究,文章对数据集提供基准测试,并提供一种新的评估指标,对现有方法和提出的方法进行了广泛的实验分析。
网站地址在https://once-3dlanes.github.io。
大多数现有的基于图像的车道线检测方法都专注于对车道检测问题描述为2D任务,其中典型的流水线首先基于语义分割或坐标回归在图像平面中检测车道线,然后通过假设地面平坦在俯视图中投影检测车道线。利用标定良好的摄像头外参,逆透视映射(IPM)能够在平坦的地平面上获得可接受的3-D车道线近似值。然而,在真实的驾驶环境中,道路并不总是平坦的,并且由于车速变化或道路崎岖不平,摄像头外参对车身运动非常敏感,这将导致对3D道路结构的错误感知,从而可能会在自动驾驶车辆上发生意外行为。
为了克服与地平面假设相关的上述缺点,3D LaneNet以端到端方式直接预测3D车道线坐标,其中有监督的方式预测摄像头外参,以便获得图像视图到俯视图的投影。此外,提出一种基于锚点的车道线预测头,用于从虚拟俯视图生成最终的3D车道线坐标。尽管结果显示了这项任务的可行性,但如果没有难获得的外参信息,虚拟IPM投影很难学习,并且模型是在摄像头对地平面零度夹角的假设下训练的。一旦假设受到质疑,或者外参的需求得不到满足,这种方法几乎无法工作。
Gen LaneNet在虚拟顶视图中提出一种几何引导的新车道线锚点。通过图像分割学习与3D车道线预测的解耦,该算法实现了更高性能,并且更适用于未观察到场景。3D LaneNet+提出了一种无锚点半局部表征方法来表示车道线,而不是将每条车道线与预定义的锚点关联起来。虽然检测更多车道线拓扑结构的能力显示了无锚点(anchor- free)方法的威力,然而这些方法都需要以有监督方式学习投影矩阵,以便将图像视图特征与俯视特征对齐,这可能会导致高度信息丢失。
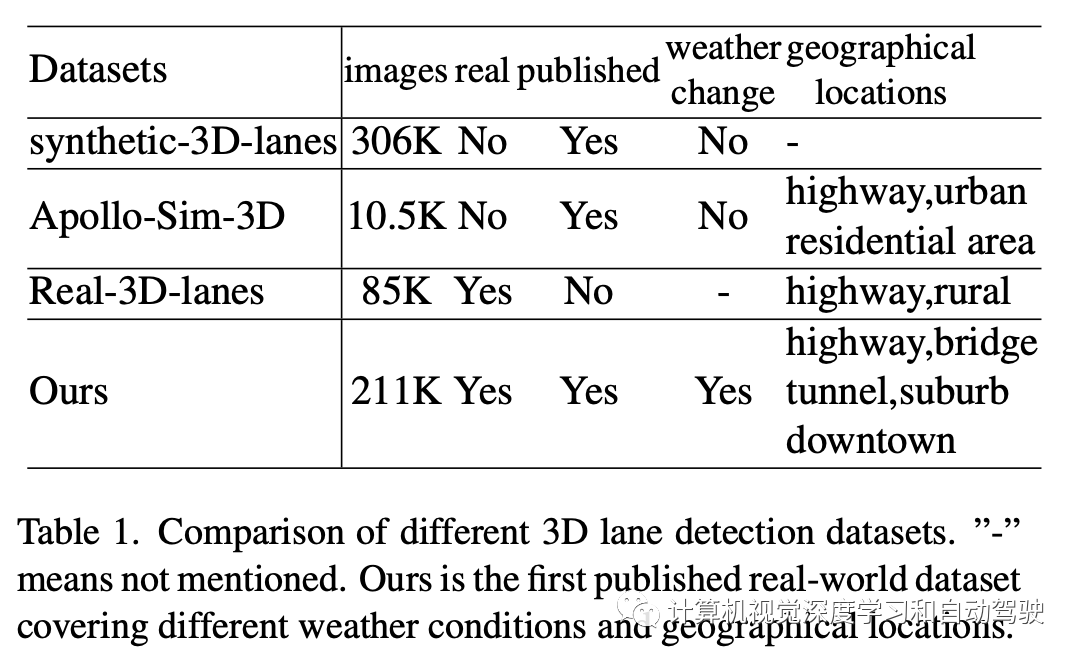
目前3-D车道线的数据集比较如表:
3D空间中的车道线L_k由一系列点{x_ki,y_ik,z_ik)}表示,这些点记录在3D摄像头坐标系中。摄像头坐标系位于摄像头的光学中心,X轴向右正,Y轴向下,Z轴向前。
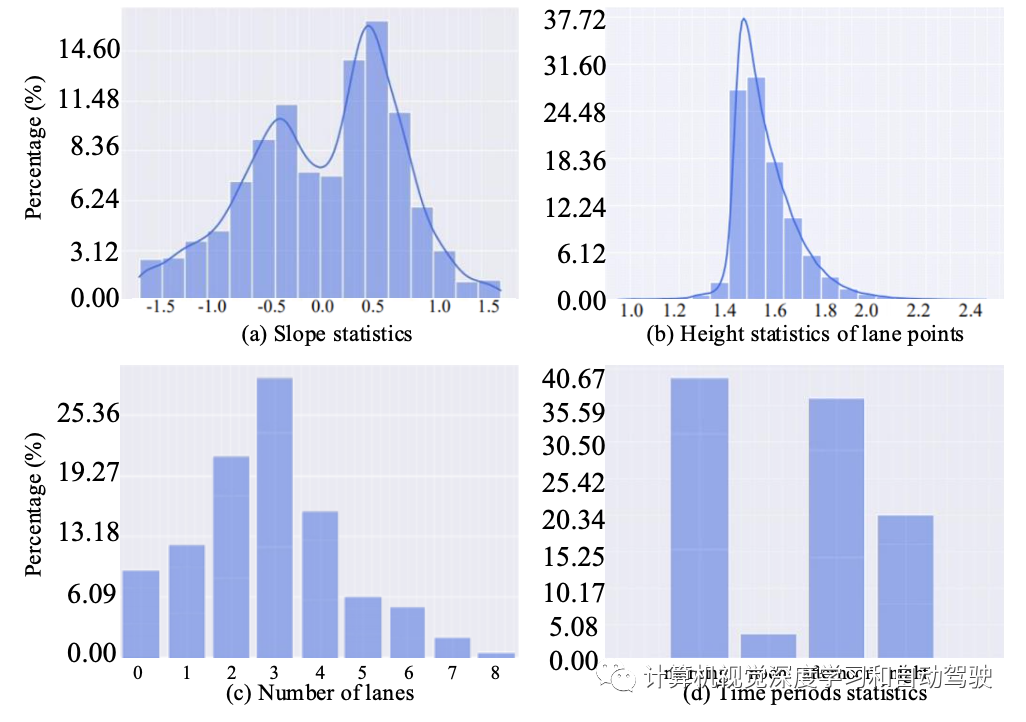
正视图到俯视图的投影误差主要发生在斜坡地面的情况下,因此重点分析ONCE- 3DLanes数据集的坡度统计。每个场景中车道线的平均坡度用于表示该场景的坡度。向前方向被认为最重要的特定车道线坡度计算如下:
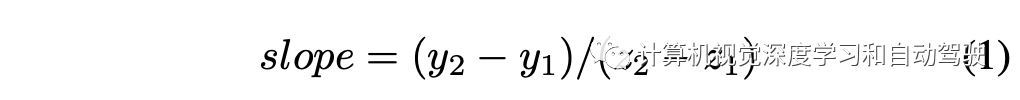
如图是坡度场景的坡度和高度统计:
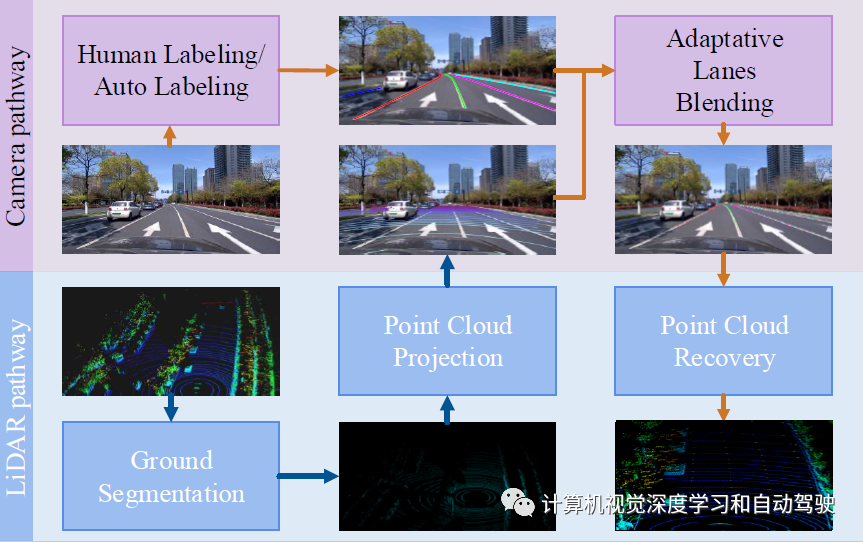
车道线是地面上的一系列点,在点云中很难识别。因此,获得3D车道线的高质量标注非常昂贵,而在2D图像中对车道线进行注释则便宜得多。对激光雷达点云和图像像素进行深入研究,用于构建3-D车道线数据集。数据集构建流水线的概述如图所示:该流水线包括五个步骤,即地面分割、点云投影、人为标注/自动标注、自适应车道线调和(blending)和点云恢复。
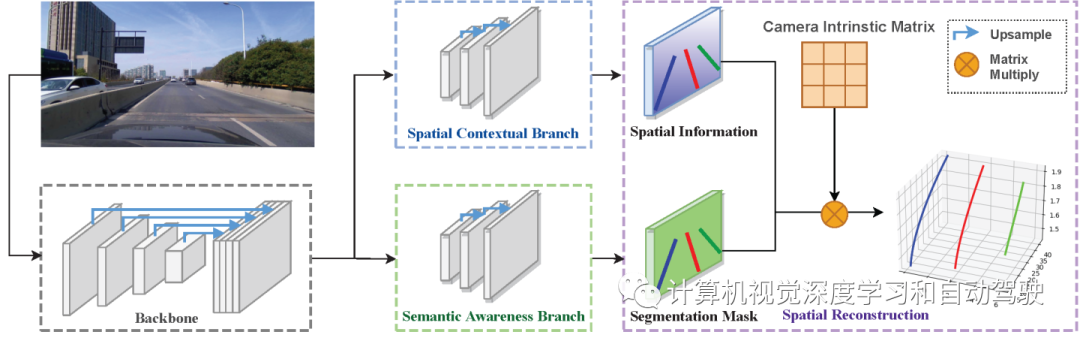
SALAD,一种空间感知的单目车道线检测方法,可直接在单目图像上执行3D车道线检测。与之前的3D车道线检测算法相比,该算法将图像投影到顶视图,并采用一组预定义的锚点回归3D坐标,不需要人工制作锚点和外参的监督。受SMOKE(单目3D检测)方法的启发,SALAD由两个分支组成:语义-觉察分支和空间上下文分支。
SALAD的模型总体结构如图所示:主干将输入图像编码为深度特征,两个分支即语义-觉察分支和空间上下文分支对特征进行解码,以获得车道线的空间信息和分割掩码;然后整合这些信息进行3D重建,最终获得真实场景的3D车道线位置;此外,一种改进的联合3D车道线扩展策略可提高泛化能力。
由于下采样和缺乏全局信息,预测车道点的位置不够准确。空间上下文分支,接受特征F并输出像素级偏移图,该偏移图预测图像平面上沿u轴和v轴的车道线点空间位置偏移δu和δv。通过像素位置偏移δu和δv的预测,车道线点的位置粗略估计将根据全球空间上下文进行修改:
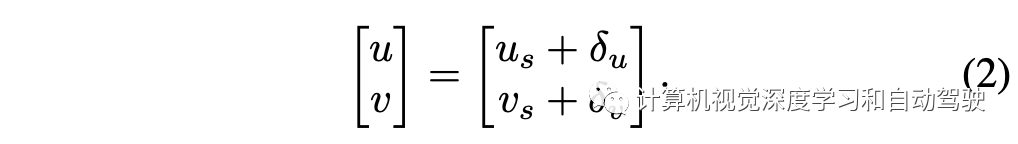
为了恢复3D车道线信息,空间上下文分支还生成一个密集的深度图,以回归车道线每个像素的深度偏移δz。考虑到图像平面的地面深度沿行增加,为深度图的每行指定一个预定义的偏移αr和比例βr,以残差方式进行回归。标准深度值z恢复如下:
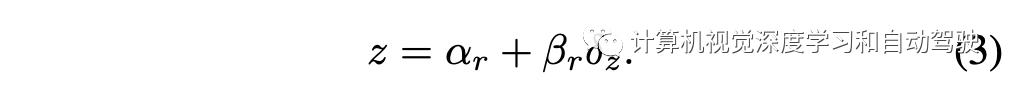
在稀疏深度图上应用深度补全,得到密集深度图Dgt,为空间上下文分支提供足够的训练信号。
具体而言,给定相机内参矩阵K3×3,相机坐标系的3D点(x、y、z)可以投影到2D图像像素(u、v),如下所示:

因此,给定图像像素坐标(u,v)及其深度信息d的2D车道线点,注意深度表示到摄像头平面的距离,因此深度d与相机坐标系中的z相同。因此,摄像机坐标系(x、y、z)中的3D车道线点可以恢复如下:
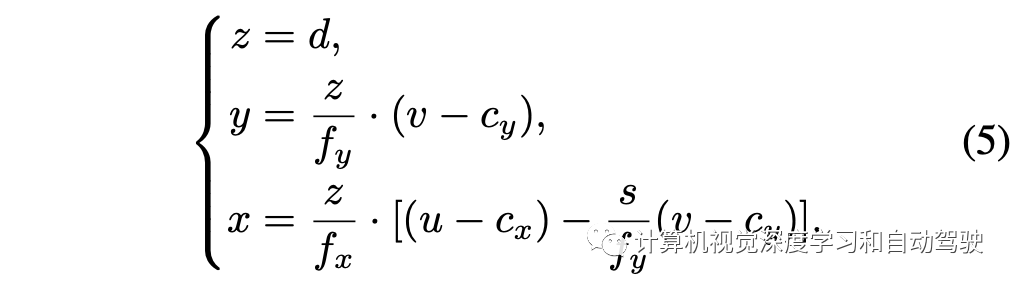
损失函数定义如下:
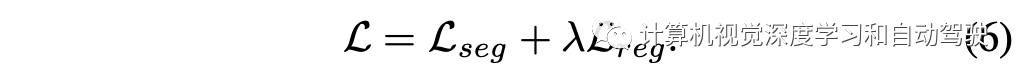
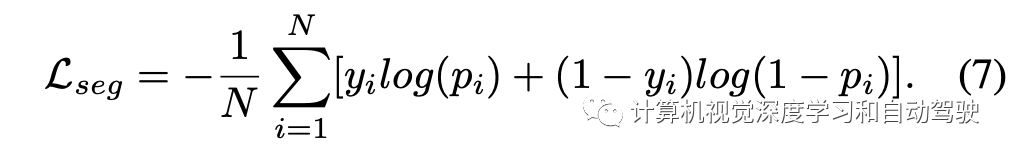
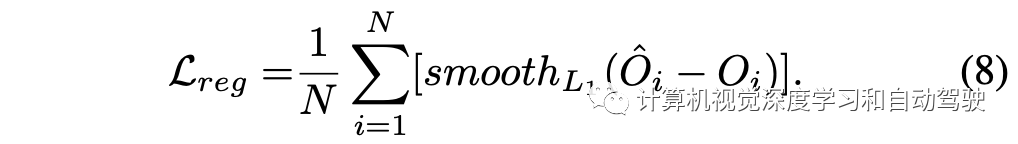
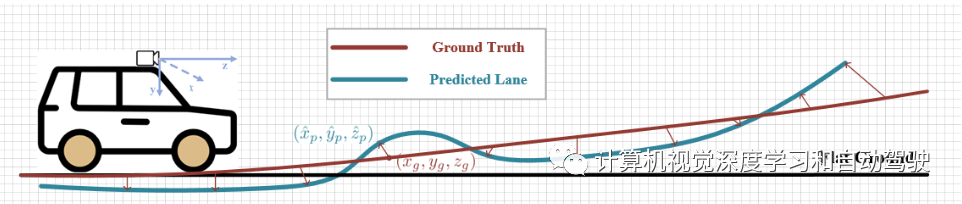
如图所示是单边Chamfer距离:给定路面真车道线上的一个点,在预测车道上找到最近的点以计算Chamfer距离。
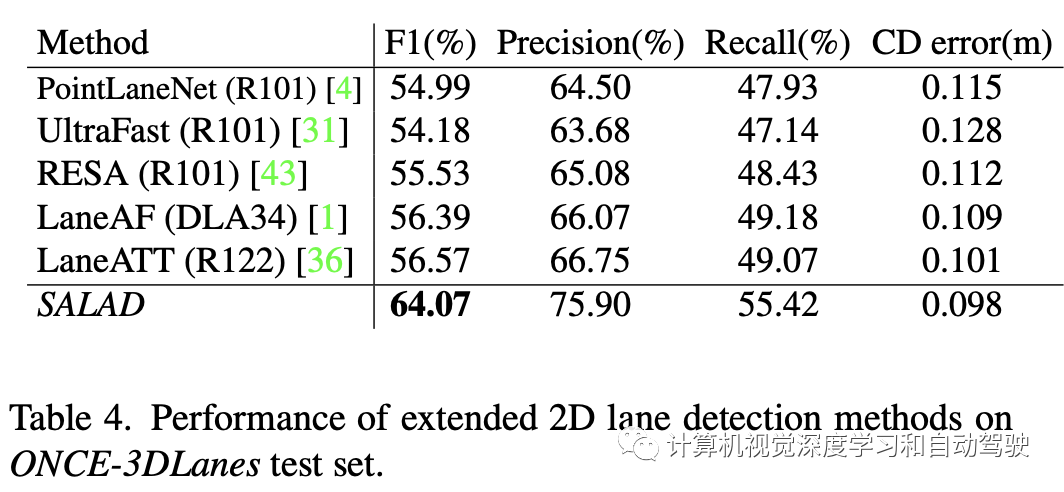
实验结果如下:




编辑推荐




最新资讯
-
大卓智能端到端直播实测,16公里复杂路段挑
2025-04-25 17:16
-
《汽车轮胎耐撞击性能试验方法-车辆法》等
2025-04-25 11:45
-
“真实”而精确的能量流测试:电动汽车能效
2025-04-25 11:44
-
GRAS助力中国高校科研升级
2025-04-25 10:25
-
梅赛德斯-AMG使用VI-CarRealTime开发其控制
2025-04-25 10:21
