




 广告
广告





















































SurroundDepth:自监督多摄像头环视深度估计

arXiv论文“SurroundDepth: Entangling Surrounding Views for Self-Supervised Multi-Camera Depth Estimation“,上传于2022年4月,来自清华、天大和鉴智机器人创业公司。
从图像中估计深度是自动驾驶3D感知的基本步骤,是昂贵深度传感器(如激光雷达)的经济替代品。时间光度学一致性(photometric consistency)可以实现无标注的自监督深度估计,进一步促进其广泛应用。然而,大多数现有方法仅基于每个单目图像预测深度,而忽略了多个周围摄像头之间的相关性,这通常适用于现代自动驾驶车辆。
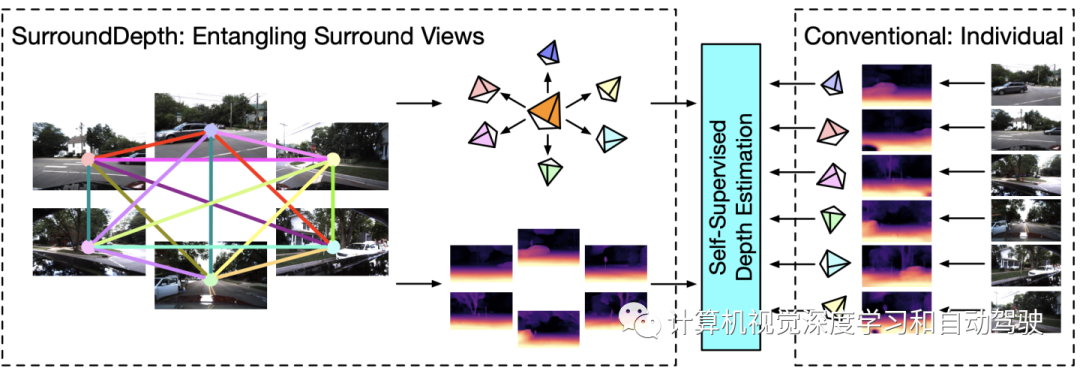
本文提出一种SurroundDepth方法,将来自多个周围视图的信息合并到一起,预测摄像头之间的深度图。具体地说用一个联合网络来处理所有周围的视图,并提出一个交叉视图transformer来有效地融合来自多个视图的信息。用交叉视图自注意来有效地实现多摄像机特征图之间的全局交互。与自监督单目深度估计不同,能够在给定多摄像机外参的情况下预测真实世界的尺度。为了实现这一目标,运动恢复结构(SfM)提取尺度-觉察的伪深度来预训练模型。此外,不预测每个单独摄像头的自运动,而是估计车辆的通用自运动,并将其传输到每个视图,以实现多视图一致性。在实验中,该方法在具有挑战性的多摄像头深度估计数据集DDAD和nuScenes上取得了最新的性能。
代码位于https://github.com/weiyithu/SurroundDepth
摄像头的3D感知由于其语义丰富和经济性,已成为一种很有前途潜在的替代方法。深度估计作为输入2D图像和真实3D环境之间的桥梁,对下游3D理解有着至关重要的影响,并受到越来越多的关注。
由于密集标注深度图的昂贵成本,深度估计通常是以自监督的方式学习。通过同时预测深度图和摄像头的自运动,现有方法利用连续图像之间的时域光度一致性作为监督信号。尽管现代自动驾驶汽车通常配备多个摄像头来拍摄周围场景的360度全景,大多数现有方法仍然侧重于从单目图像预测深度图,而忽略了周围视图之间的相关性。由于只能通过时域光度一致性推断出相对尺度,这些自监督的单目深度估计方法无法产生尺度-觉察的深度。然而,由于多摄像机外参矩阵中的平移向量获得了真实世界的尺度,因此有可能获得尺度-觉察预测。
自监督单目深度估计方法同时探索学习深度和运动的路线。对于单目序列,几何约束通常建立在相邻帧上。最早就是将该问题构建为一个视图合成任务,并训练两个网络分别预测姿势和深度。也有提出ICP损失,其工作证明了使用整个3D结构一致性的有效性。Monodepth2采用最小重投影损失、全分辨率多尺度采样和auto-masking损失,进一步提高预测质量。还有一个尺度非一致性(scale consistency )损失项来解决深度图之间尺度不一致的问题。PackNet SfM通过引入3D卷积进一步提高了深度估计精度。最近,FSM通过引入空间和时间上下文来丰富监督信号,将自监督的单目深度估计扩展到全周围视图。
多视图特征交互是多视图立体视觉、目标检测和分割中的一个关键组件。MVSNet构建一个多视图特征的基于方差成本体(variance-based cost volume),并用3D CNN做成本正则化回归深度值。另外还有引入自适应聚合和LSTM来进一步提高性能。最近,CVP-MVSNet采用金字塔结构来迭代优化深度预测。STTR采用一种具有交替自注意和交叉注意的transformer来取代成本体。LoFTR在transformer中使用自注意和交叉注意层,获得两幅图像的特征描述子。Point MVSNet结合2D图像外观线索和几何先验知识,动态融合多视图图像的特征。此外,PVNet集成3D点特征和多视图特征,以更好地识别联合3D形状。
深度估计的附加监督信号,可以加强深度估计的准确性,如光流和目标运动。DispNet是第一个将合成立体视频数据集的信息传输到真实世界深度估计的工作。此外,有工作采用一种具有生成性对抗损失的双模块域自适应网络(two-module domain adaptive network),从合成域迁移知识。一些方法采用辅助深度传感器来捕获准确的深度,如激光雷达,以协助深度估计。此外,一些方法引入曲面法线来帮助预测深度,因为深度受曲面法线决定的局部切平面约束。GeoNet提出了深度到法线(depth-to-normal)网络和法线到深度(normal-to-depth)网络,迫使最终预测遵循几何约束。此外,许多工作引入了传统方法(如SfM),产生一些稀疏但高质量的深度值,以协助模型训练。DepthHints使用一些现成的立体视觉算法来加强立体视觉匹配。
如图是传统单目深度估计方法和SurroundDepth的比较:
在自监督深度和自运动设置中,通过最小化像素光度重投影损失来优化深度网络F,其中包括SSIM度量和L1损失项:
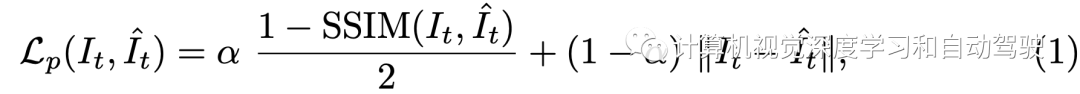
此过程需要一个姿态网络G来预测It-》Is的相对姿态。具体而言,给定摄像头固有矩阵K,基于预测深度图,可计算It中任何像素p1在Is的相应投影p2。这样,根据投影坐标p2可以在Is中使用双线性插值创建合成RGB图像。这种基于重建的自监督范式在单目深度估计方法上取得了巨大进展,并可以直接扩展到多摄像头全环视深度估计。I的预测深度图和姿势可以写成:
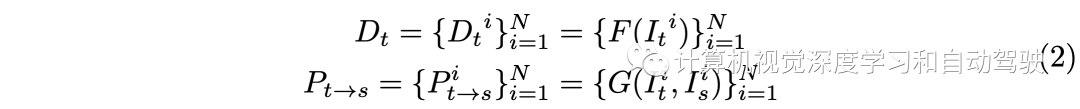
相邻视图之间重叠将所有视图连接成一个完整的360度环境视图,其中包含许多有益的知识和先验知识,有助于理解整个场景。基于这一事实,构建一个联合模型,首先提取并交换所有周围视图的表征。在交叉视图交互之后,将多视图表征同时映射到最终的深度。此外,视图相关的自运动可以从预测的共同姿态(universal pose)和已知的外部矩阵中迁移得到。总之,深度和姿态预测可以表示为:
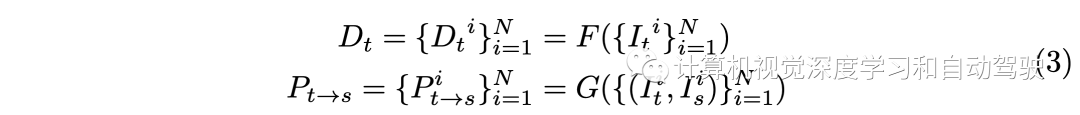
利用联合模型,不仅可以通过交叉视图信息交互提高所有视图的深度估计性能,还可以生成共同的自运动,从而使用相机外参矩阵生成尺度-觉察预测。
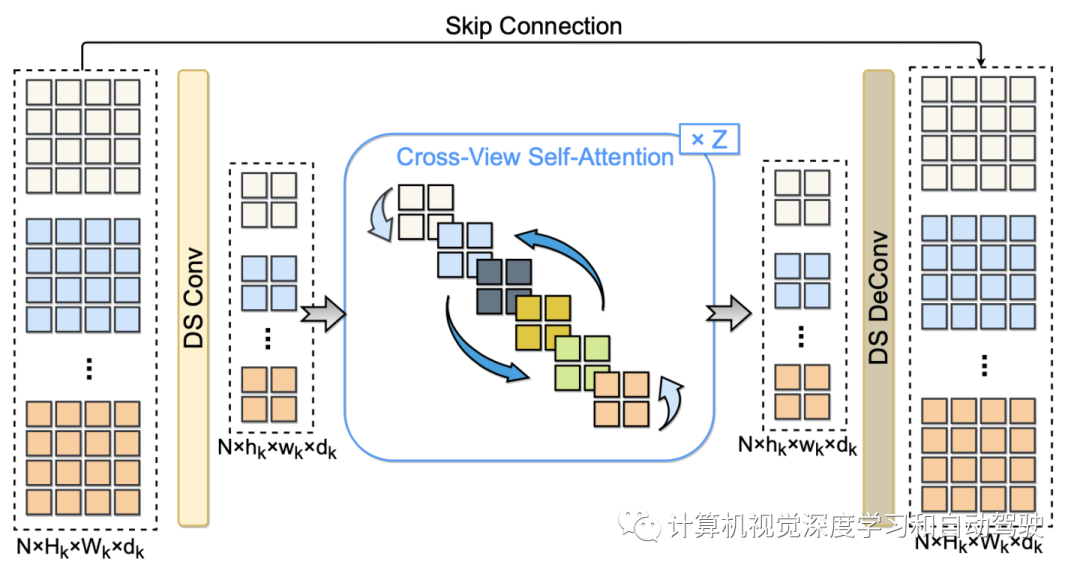
如图是SurroundDepth网络概览图:网络F可以分为三部分,即,共享编码器E、共享解码器D和多个交叉视图Transformer(CVT)。给定一组周视图像,编码器网络首先并行提取其多尺度表征。与现有的直接解码学习特征的方法不同,其将所有视图的特征在每个尺度上纠缠成一个完整的特征,并进一步利用多尺度特定CVT,在所有尺度上执行交叉视图自注意。
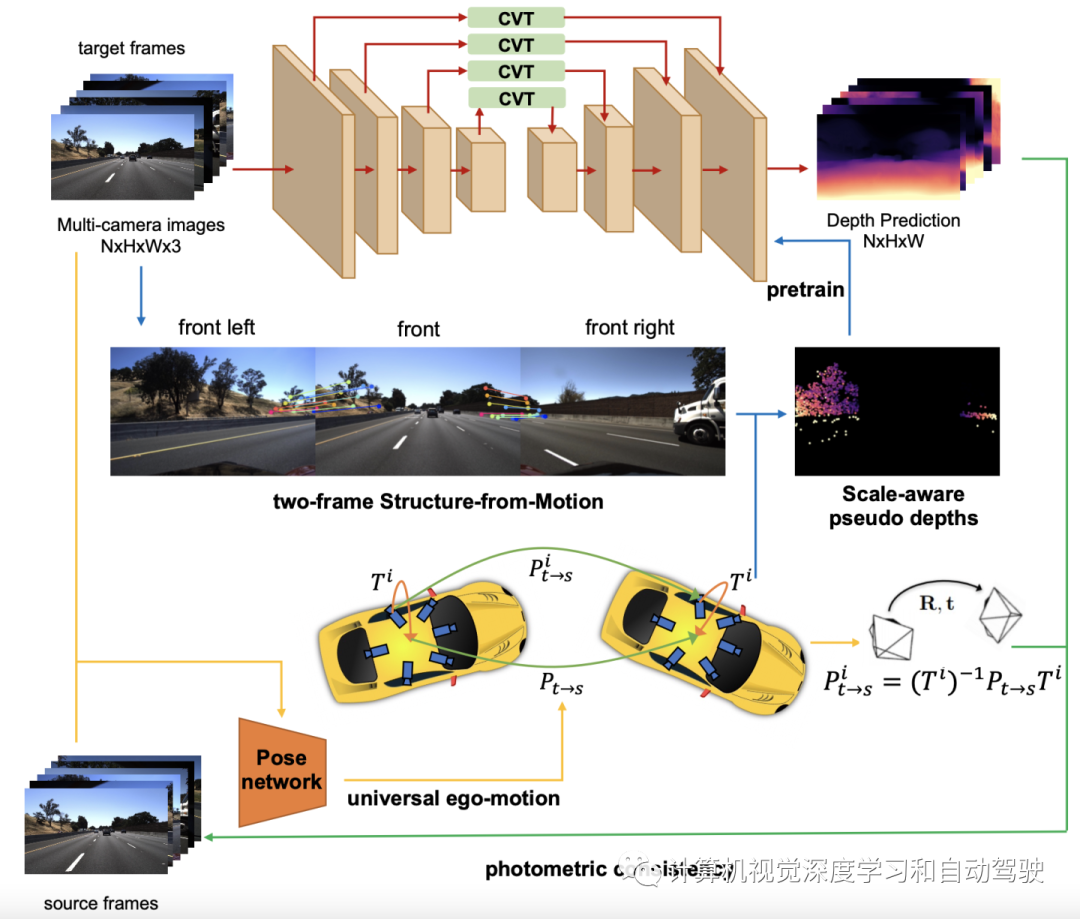
CVT利用强大的注意机制,使特征图的每个元素能够将其信息传播到其他位置,同时吸收其他位置的信息。最后,将交互后的特征分离给N个视图,并将其发送给解码器D。
与单目深度估计不同,这个能够从摄像头外参矩阵中恢复真实世界的尺度。利用这些摄像头外参矩阵的一种简单方法是,嵌入到两个相邻视图之间的空间光度损失中。然而,发现深度网络通过空间光度一致性的监督无法直接学习尺度。为了解决这个问题,作者提出尺度-觉察的SfM预训练和联合姿态估计。
具体来说,用两帧SfM生成伪深度来预训练模型。预训练深度网络能够学习真实世界的尺度。此外,N个摄像头的时域自运动具有明确的几何约束。这里没有使用一致性损失,而是估计车辆的共同姿态,并根据外参矩阵计算每个视图的自运动。
如图所示:该工作利用从所有周围视图中提取的多尺度特征,将编码器和解码器之间的跳连接替换为交叉视图transformer(CVT)
首先使用沿深度可分离卷积(DS Conv,depthwise separable convolution)层将多视图特征总结为紧凑表征。然后构建Z交叉视图自注意层,充分交换扁平的多视图特征。在交叉视图交互之后,用DS Deconv(depthwise separable deconvolution)层来恢复多视图特征的分辨率。最后,构造了一个跳连接,将输入和恢复的多视图特征相结合。
SfM预训练的目的是从相机外参矩阵中探索真实世界的尺度。利用外参矩阵的直接方法是在两个相邻视图之间使用空间光度损失,即:
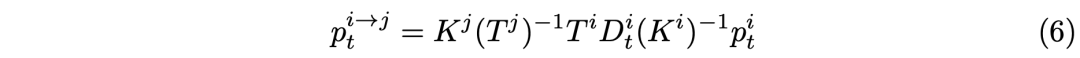
但实际上,这样做并不行。这个结论不同于FSM(“Full Surround Monodepth from Multiple Cameras“,arXiv 2104.00152,2021)得到的。实际上,在训练开始时,空间光度损失将无效,并且无法监督深度网络学习真实尺度。为了解决这个问题,采用SIFT描述子来提取对应关系。然后,用摄像头外参矩阵进行三角测量来计算尺度-觉察的伪深度。最后,用这些稀疏的伪深度以及时间光度损失来预训练深度网络和姿态网络。
如图所示即尺度-觉察SfM预训练:由于小重叠和大视角变化,传统的两帧运动恢复结构(SfM)会产生许多错误对应。通过引入region mask(定义图像Ii的左边1/3区域,图像Ii+1的右边1/3区域),缩小了对应关系的搜索范围,提高了检索质量。使用相机外参矩阵得到的极线几何可进一步过滤异常值。

这里一个点的外极线表示为:
在单目深度估计框架中,相对的摄像头姿态由PoseNet估计,PoseNet是一个编码器E-解码器D网络。因此,在多摄影头设置中,所有摄影头的姿态是为所有视图生成监督信号所必需的。一种直观的方法是分别估计每个姿态。然而,该策略忽略了不同视图之间的姿态一致性,这可能导致监督信号无效。为了保持多视点自运动的一致性,将摄像头姿态估计问题分解为两个子问题:共同姿态预测和universal-to-local变换。为了获得共同姿态P,我将N对目标和源图像一次馈入PoseNet G,并在解码器之前对提取特征进行平均。共同姿态可通过以下方式计算:
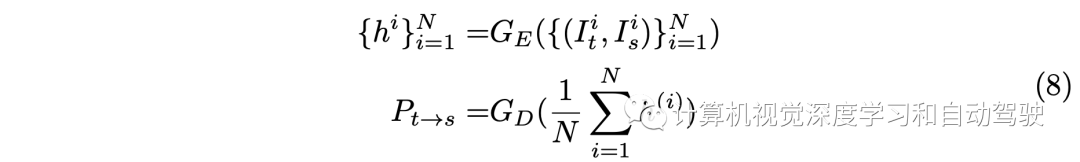
基于摄像头内参,由此计算各个摄像头姿态为:
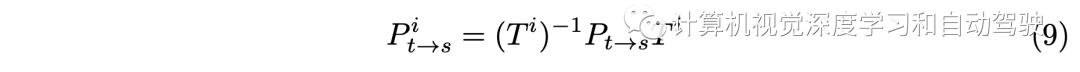
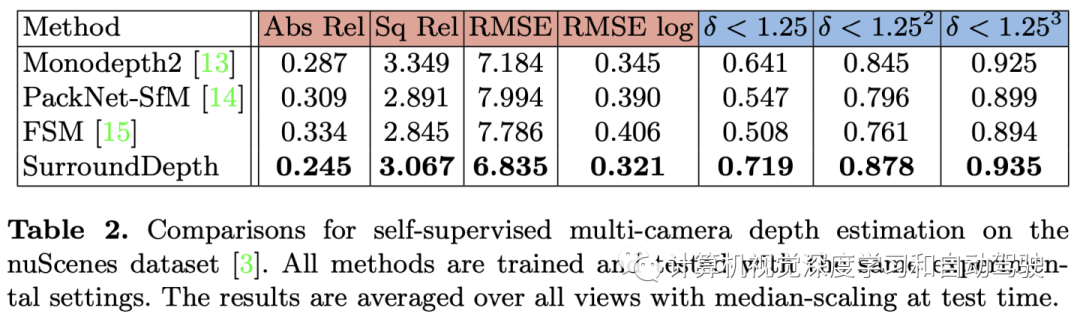
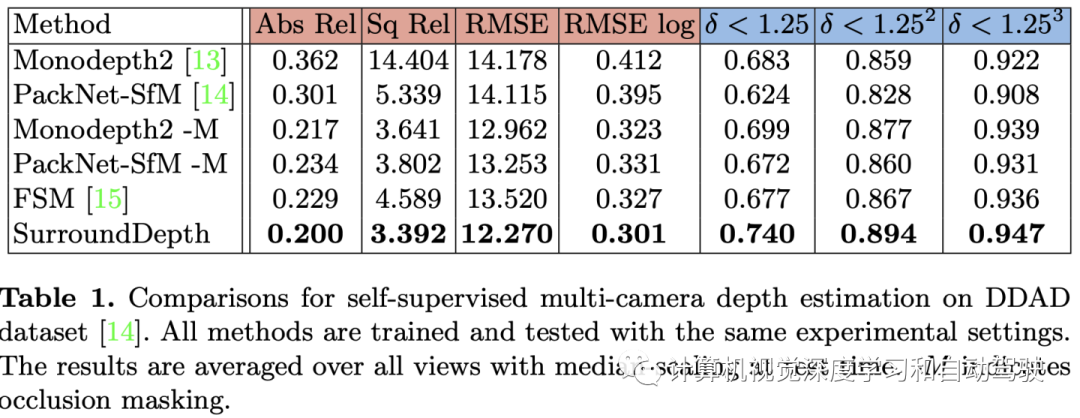
实验结果如下:


- 下一篇:某款混动车辆传动系统扭振设计及验证
- 上一篇:欧盟智能网联汽车中的无线电装置标准法规



编辑推荐




最新资讯
-
漫说信息智能 · 电动车防晕车大作战
2025-04-27 16:28
-
R171.01对DCAS的要求⑨
2025-04-27 15:29
-
智驾标准法规体系大全
2025-04-27 15:28
-
国内最大汽车创作者大会开幕,懂车帝投入5
2025-04-27 13:18
-
大卓智能端到端直播实测,16公里复杂路段挑
2025-04-25 17:16
