




 广告
广告





















































一个语义引导的轨迹预测半监督对抗训练方法

arXiv上传于2022年5月27日论文“Semi-supervised Semantics-guided Adversarial Training for Trajectory Prediction“,作者是美国西北大学和加州尔湾分校。

对轨迹预测的对抗性攻击,即在历史轨迹中引入小的人为干扰,可能会严重误导未来轨迹的预测,导致不安全的规划。然而,很少有工作涉及增强重要安全-紧要任务的鲁棒性。
本文提出轨迹预测的对抗训练方法。与典型的对抗图像任务训练相比,这个工作面临着一些挑战,如更多具有丰富上下文的随机输入和类别标签的缺少等。为了应对这些挑战,提出一种基于半监督对抗自动编码器(autoencoder)的方法,利用领域知识对分离的语义特征进行建模,并为对抗训练提供附加的潜标签。
对不同类型的攻击进行大量实验表明,半监督语义引导的对抗训练方法可以有效地减轻对抗攻击的影响,并普遍提高系统对各种攻击(包括未见过的)的对抗性鲁棒性。
自动驾驶系统通常由感知、定位、预测、规划(路线、行为、轨迹和运动规划)和控制等几个模块组成。感知模块根据传感器输入(例如图像和3D点云)检测智体和障碍物。预测模块是根据感知模块和地图环境中观察的历史轨迹预测周围车辆的未来轨迹。
很少有研究对车辆轨迹预测的鲁棒性进行研究,这实际上至关重要,因为 1)自动驾驶本质上是一项安全-紧要任务,2)最近的工作表明,如果周围车辆沿着看似自然但精心设计的轨迹行驶,预测模块容易受到对抗攻击,3)当前的预测模型往往对数据集有限的模式过拟合,但驾驶场景和行为存在长尾分布。
如图所示:目标车辆可能在规划模块中进行不安全的紧急制动,因为其错误地预测不良车辆将切入其车道;精心设计的输入轨迹有可能故意误导目标车辆错误预测,并导致危险的规划决策。
为了防御车辆轨迹预测的对抗攻击,存在着与图像和音频不同的重要挑战。
-
首先,车辆轨迹预测是一个具有丰富上下文的时间序列回归,而现有大多数的对抗性攻击和相应的防御方法都是针对分类任务。其攻击模式更加随机,并且没有定义良好的类标签,这意味着鲁棒的模型很难训练和泛化。
-
其次,车辆轨迹可以传递语义或行为信息。例如,人们可以根据车辆轨迹推断车辆行为,例如前行或变道。
最近研究表明,在同时白盒和黑盒设置中,自动驾驶的轨迹预测可以被周围车辆的对抗行为所愚弄,其中对抗行为分别通过PGD(Projected Gradient Decent)或PSO(Particle Swarm Optimization)进行优化。对航点的最大偏差加上硬约束,使对抗轨迹在物理上可行而不是表现为不切实际的行为。
与图像分类不同,轨迹预测没有类别标签,但它在上下文中具有方向信息,例如前移、转弯或右换道。因此,攻击者除了可以进行随机攻击外,还可以进行有方向性的攻击。
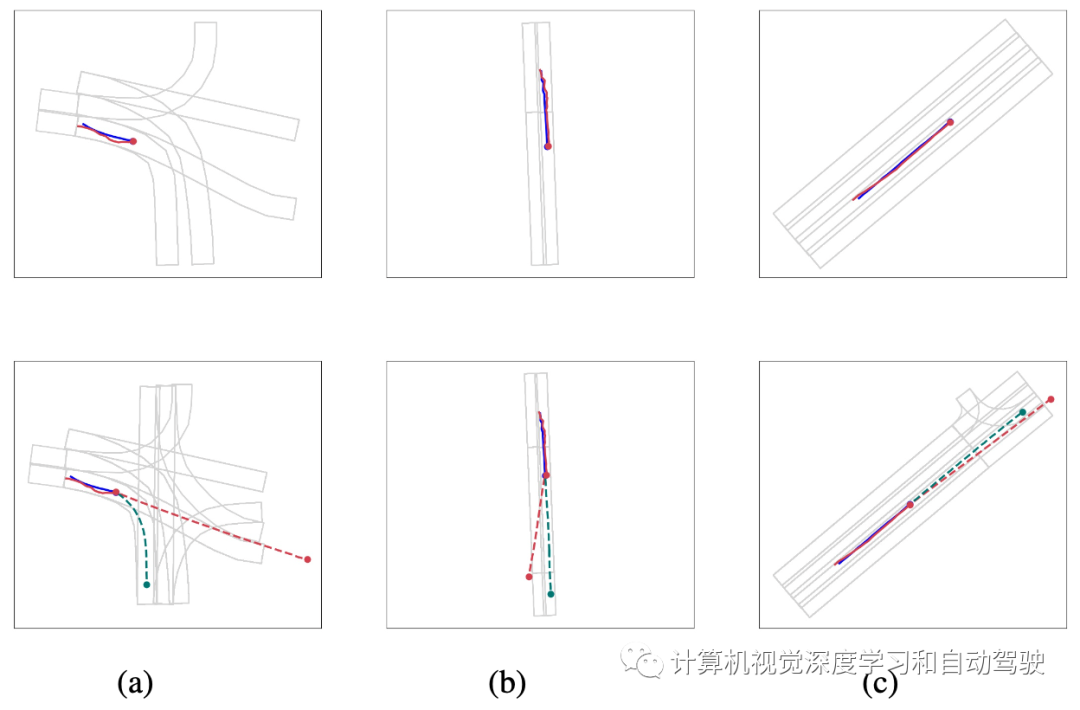
如图所示:三种类型的对抗性攻击,会导致重大的方向性错误;第一行是用于预测的敌对(红线)和良性(蓝线)输入历史轨迹,看起来与人眼非常相似;第二行是相应被攻击的未来轨迹预测(红虚线)和良性情况下的真实轨迹(绿虚线)。左图(a)是随机导致最大平均偏差的ADE攻击;中图(b)是横向攻击,主要导致车辆向左或向右偏离;右图(c)是主要导致纵向偏差的纵向攻击。
方向错误度量定义为
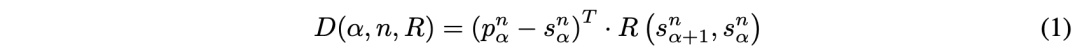
其中α表示时间帧ID,n表示目标车辆ID。p和s分别表示预测和真实车辆位置的二维向量。R是生成特定方向(横向或纵向)单位向量的函数。纵方近似为由真值头两个航点定义的向量。
除了方向性攻击外,还设计了一种随机攻击最大化平均位移误差(ADE),即预测轨迹和真实轨迹航点之间的均方根误差的平均值。
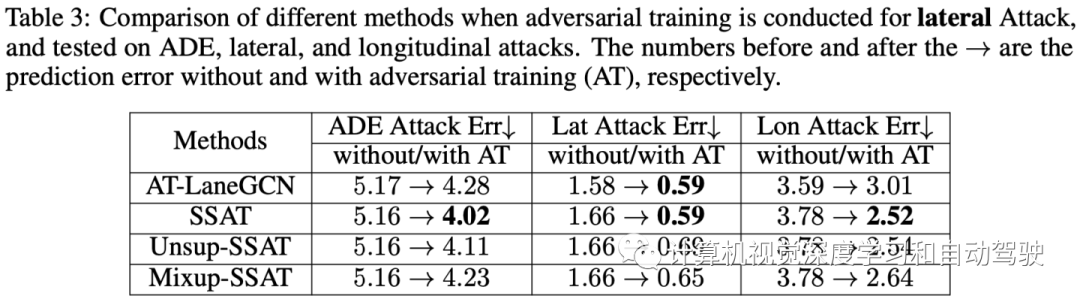
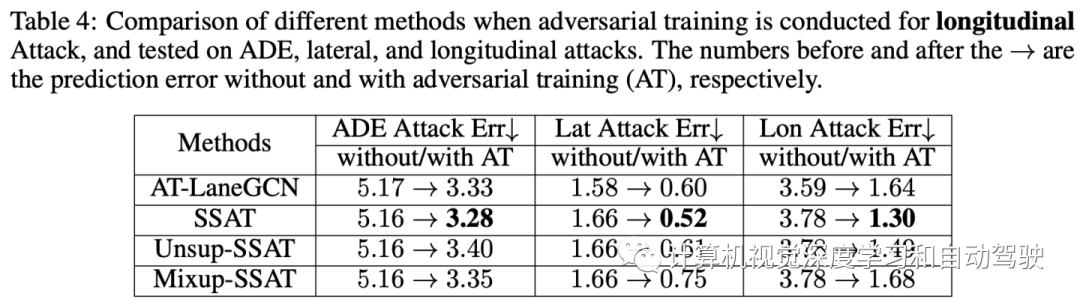
如表1的定量显示,任何攻击类型都可能严重偏离预测轨迹。因此,攻击者可以进行随机攻击或方向性攻击,这对防御方法,尤其是泛化性能提出了很大挑战。

对抗性训练被证明是提高DNN模型鲁棒性的最有效方法之一。实践中PGD攻击通常用于评估,因为它在白盒子设置中具有强大的攻击能力。然而,最近研究表明,特定类型的对抗性攻击不足以表征对抗性示例的空间,对抗训练的模型仅对特定的攻击具有鲁棒性。这确实限制了对抗训练在实践中的应用,尤其是长尾分布的轨迹回归任务。
对抗自动编码器(AAE)是变分自动编码器(VAE)的一种变型,是一个采用随机梯度下降(SGD)联合学习深度潜变量模型和相应推理模型的原则性方法。VAE模型,首先使用KL散度对高斯分布潜变量的输入进行正则化,然后从潜空间重构输出结果。
AAE利用对抗学习而不是KL散度,对潜向量施加各种分布。由于对抗学习的灵活性,A在潜空间施加复杂分布这一点,AAE优于VAE。研究表明,解纠缠的潜表征,会生成VAE,在对抗攻击中更鲁棒。
基于AAE架构,作者引入领域知识,促进良性情况和对抗情况下语义信息的建模。该模型以半监督方式学习方向性语义潜向量,因为真值仅适用于有限的场景,但其分布可以从领域知识和统计数据中得出。因此,潜空间建模包括两个层次:无监督分布建模和有标签时的半监督学习。
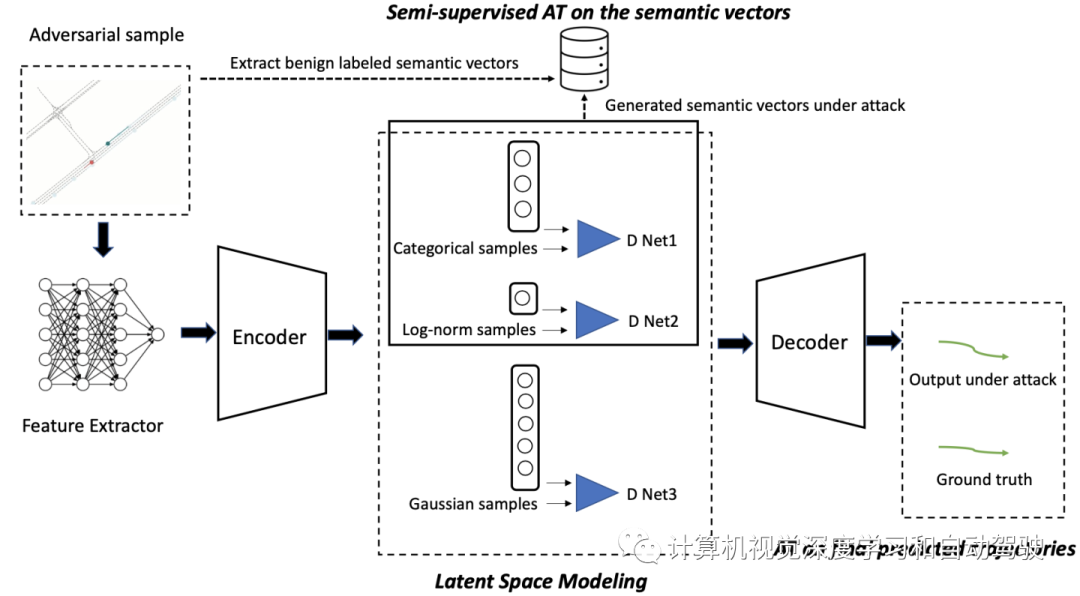
该模型架构如图所示:特征提取器利用一维膨胀(dilated)卷积神经网络获取时间序列轨迹嵌入,并用图神经网络(GNN)来建模车道线上下文和目标之间的交互。编码器采用分布正则化和半监督训练将高维特征映射到语义引导的潜空间。具体而言,潜空间分为三部分:纵向特征z-lon,遵循一维对数正态分布;横向特征z-lat,遵循三维类别分布;剩下其他特征,遵循高斯分布。最后,解码器将语义向量以及其他解纠缠的潜向量映射到未来轨迹。AAE代替传统VAE架构,可模拟这些不同且复杂的分布。
在攻击场景中,攻击的影响将被分解为不同的潜向量,攻击模式将通过语义特征显式建模。以横向向量为例,如果攻击不是针对横向维度,编码器将攻击结果分解为其他向量,横向的映射将保持稳定。否则,如果攻击导致横向向量的错误,则特征提取器和编码器将在方向标签进行对抗训练,并更新潜分布到最终轨迹的对应映射。
在轨迹预测任务中,为了建模高级语义信息,很自然地将轨迹分解为两个维度——纵向和横向。通过代表性的度量和先验分布,期望利用领域知识指导建模。
纵向通常用速度和加速度来模拟车辆的动态,但总在变化,并且不包含足够的语义信息。在模型中,用时间推进(time headway)来有效地提取纵向特征,该特征测量两个连续车辆在通过给定点的时间差。时间推进代表了某个智体相对稳定的行为模式,并考虑与其他车辆的交互。
该模型将时间推进表示为潜空间的一维向量。在良性情况和对抗情况下,编码器都通过正则化损失函数做训练,强制纵向特征达到统计中时间推进所遵循的特定分布。
纵向特征遵循的分布定义为
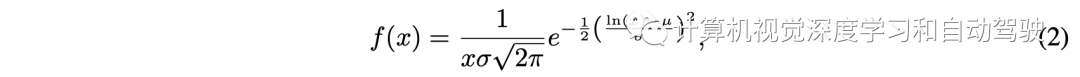
当被攻击目标和前方车辆之间存在可观测的交互时,可以明确地获得半监督训练的真实时间推进值。将半监督纵向特征编码视为一个回归问题,并通过最小化均方误差对其进行优化。
对于横向特征,用三个简单但有效的类别来表示:前进、左转/换道和右转/换道。这三个意图本质上是离散的,用类别分布对它们进行建模。在对抗训练过程中,只有在足够长时间内具有明确意图的车辆才会被标记,训练中用交叉熵来优化该分类任务。
对于所有语义和高斯潜变量,如下对抗性生成损失被正则化为目标分布。鉴别器的训练,最大化真潜样本的对数概率s和假潜样本的逆概率对数,公式为
对每个示例,仅为目标车辆,采用PGD攻击方法生成对抗轨迹,并保留周围其他车辆的原始轨迹,从而限制对抗攻击对整个场景的影响。如果攻击的预测与真值之间的误差大于阈值,攻击算是成功,对该样本进行对抗训练。
由于扰动很小,将真实的未来轨迹作为对抗训练的真值yi,并以L1平滑损失优化整个流水线
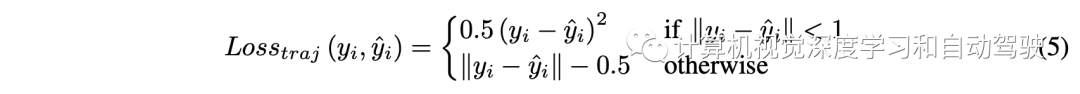
这是一个普遍但有点幼稚的对抗训练过程。在该体系结构中,进一步利用语义特征及其相应的标签来促进对抗性训练。对编码器进行优化,最小化纵向特征的均方误差和潜空间真值-预测横向特征的交叉熵。半监督损失函数如下所示:
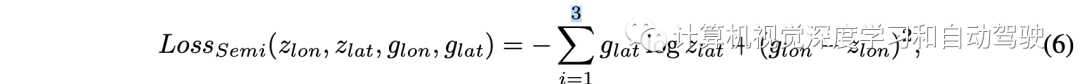
此外,由于横向预测可以看作是一个分类问题,并且具有明确的行为含义,因此进一步利用横向语义向量调整对抗性训练过程。
当对抗性示例导致横向行为分类错误时,对抗性训练半监督损失的权重设置更高。这样,模型将首先保证高级语义预测的正确性,调整回归误差,从而避免显著的对抗性偏差,提高泛化性能。
整个对抗学习算法的伪代码如下:

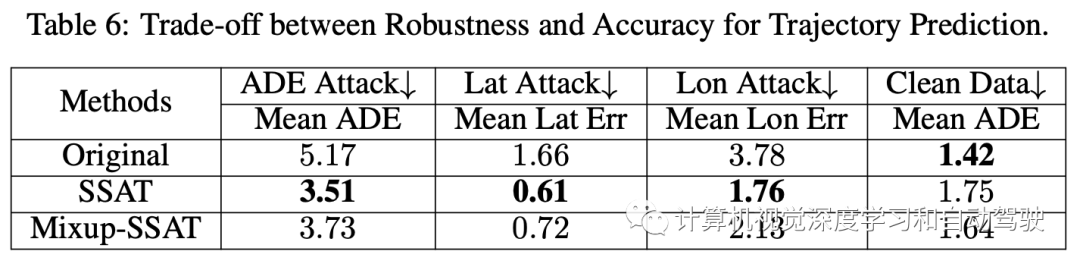
初步实验发现标准准确性和对抗性稳健性之间的一个权衡。首先尝试鲁棒的自训练和数据增强:添加一个额外的解码器,和带高斯噪声的真实输入相同的潜向量生成更多的输入,来增强数据。
然而,数据驱动增强引入了额外的误差,甚至可能会损害标准精度。部分原因是,在预测任务中,增强的输入需要非常精确地匹配未来轨迹(真值)和上下文,而分类任务更能容忍增强数据。因此,在对抗训练过程中进一步利用MixUp技术,混合对抗场景和良性场景,从而在轨迹预测的对抗鲁棒性和准确性之间平衡。
实验结果如下:
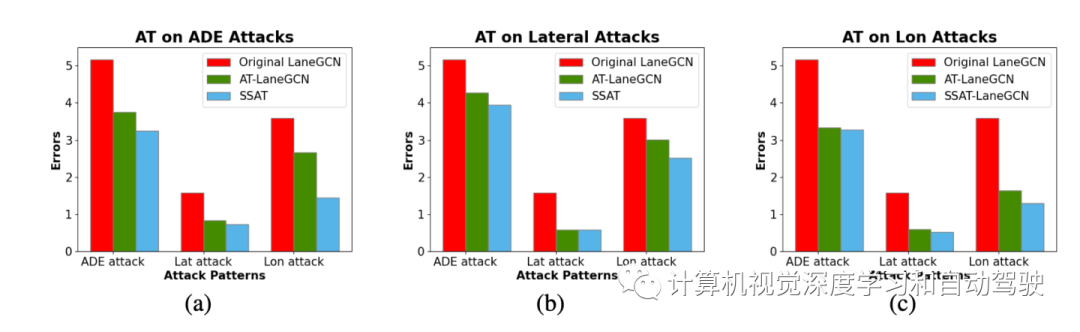
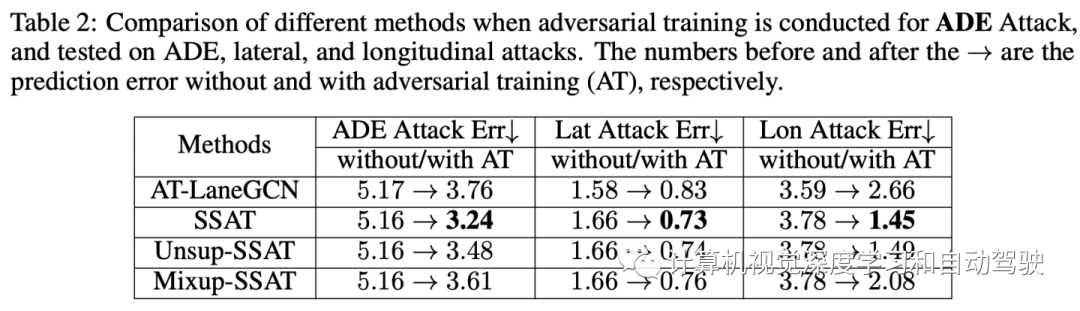
选择在LaneGCN模型进行对抗性训练作为比较基准。在此设置下,所有模型共享相同的特征提取器,然后结果主要反映对抗性训练造成的差异。
如图显示,轨迹预测任务的对抗性训练可以显著减少不同类型攻击下的错误。半监督语义引导(SSAT)方法将进一步增强对各种攻击的鲁棒性,与LaneGCN的简单对抗性训练相比,错误减少多达45%。




编辑推荐




最新资讯
-
每秒采集100万个数据 | 下一代USB DAQ产品-
2025-04-07 14:12
-
重型商用车辆和客车的动力学——振动环境
2025-04-07 14:11
-
2025年10大隐形车衣品牌排行榜
2025-04-07 10:40
-
沃尔沃卡车与Greenlane合作推动商业电动化
2025-04-07 08:42
-
江铃晶马:美标转欧标充电结构专利
2025-04-07 08:39
