




 广告
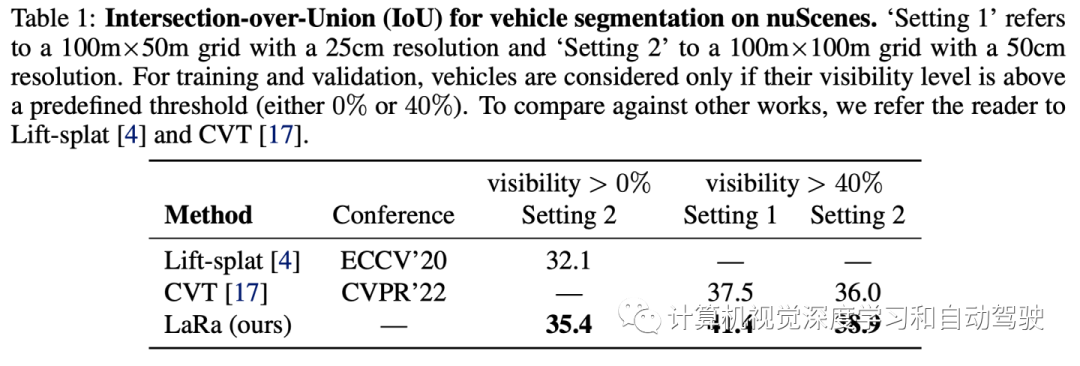
广告





















































LaRa:用于多摄像头BEV语义分割的潜表征和光线嵌入

arXiv上传于2022年6月27日的论文“LaRa: Latents and Rays for Multi-Camera Bird’s-Eye-View Semantic Segmentation“,作者来自法国的Valeo.ai 和Inria。

最近在自动驾驶方面的工作广泛采用了BEV语义图作为世界的中间表征。这些BEV地图的在线预测涉及非同一般操作,例如多摄像头数据提取、融合和投影到一个共同顶视网格。这通常需要容易出错的几何操作(例如,单应性或来自单目深度估计的逆投影)或BEV图像像素和像素之间昂贵的直接密集映射(例如,MLP或注意机制)来实现。
这项工作提出“LaRa”,一种高效的编码器-解码器,基于transformer的模型,从多个摄像头进行车辆语义分割。该方法用一个交叉注意系统,将多个传感器的信息聚合成一个紧凑但丰富的潜表征集。这些潜表征经过一系列自注意块处理后,在BEV空间通过第二次交叉注意机制重投影。
为了安全规划和驾驶,自动驾驶汽车需要通过多个不同的传感器(例如摄像机、雷达和激光雷达)准确地360度感知和了解其周围环境。大多数方法缓慢地聚合来自每个传感器的独立预测。这种后融合策略在场景级全局推理方面存在局限性,并且没有利用连接传感器的可用先验几何知识。或者,BEV代表性空间,即顶视图占用网格,最近在社区内引起了极大的兴趣。
BEV是一个合适的自然空间,可以融合多个视图或传感器模态,并捕捉语义、几何和动态信息。此外,它是下游驾驶任务的广泛选择,包括运动预测和规划。本文重点研究多摄像机在BEV的感知。BEV表征的在线估计通常通过以下方式完成:(i)施加强大的几何先验,例如平面世界或像素列和BEV射线之间的对应关系,(ii)预测像素的深度概率分布,从2D提升到3D并投影到BEV,一个受到组合误差影响的系统,或(iii)学习多摄像机特征和BEV网格像素之间代价高昂的密集映射。
假设有多个摄像机观察场景,目标是对于自车周围的车辆估计二值占用网格。本文提出一种基于transformer的架构“LaRa”,在扩展回BEV空间之前,将多个摄像机收集的信息有效地聚合为紧凑的潜表征。由于摄像机之间的几何关系应该指导每个摄像机视图的融合,建议用覆盖每个像素光线的几何来增强每个像素。
LaRa架构如图所示:通过共享CNN从图像中提取语义特征(绿色),并与光线嵌入(多色)连接,后者提供几何信息,在摄像机内的像素和摄像机之间的像素建立空间关联。然后,通过1个交叉注意(CA)和 L个自注意(SA)层(黄色),将该表征融合为紧凑的潜表征。用交叉注意查询潜表征获得最终的BEV图,然后用BEV CNN(红色)进行细化。
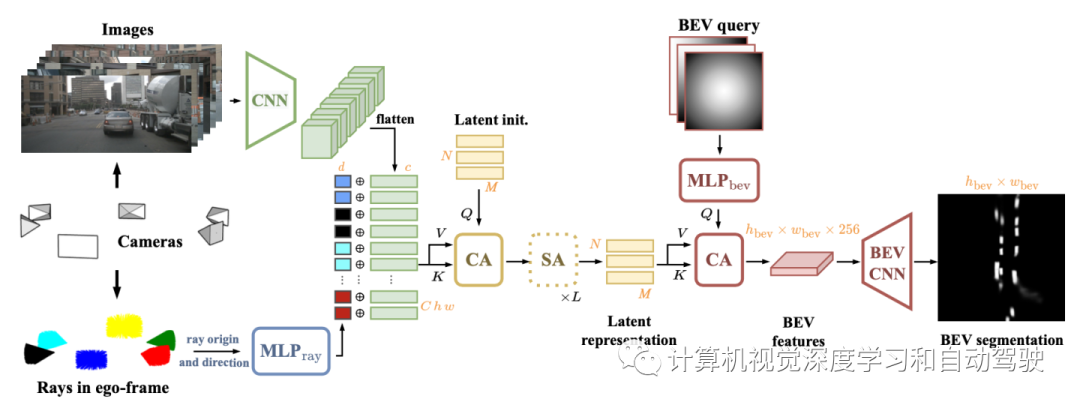
考虑C个摄像机,摄像机k产生的图像Ik,Rk和tk分别为其外参旋转和平移分量。从这些输入提取两种互补的信息:来自原始图像的语义信息和来自摄像机标定参数的几何线索。
-
来自原始图像的语义信息
共享图像编码器E为每个图像Ik提取特征图Fk = E(Ik),用预训练的EfficientNet主干实例化E,产生多摄像机特征。然后,这些空间特征图重新排列为一系列特征向量。
-
利用几何先验
为用几何先验丰富摄像机特征,常用的正弦和余弦空间嵌入在多个摄像机情况下是不明确的。一个简单的解决方案是,除了傅立叶嵌入之外,用依赖于摄像机的可学习嵌入来消除摄像机之间的歧义。然而,在设置中,摄像机之间的几何关系(由摄像机装备的结构定义)对于指导视图融合至关重要。这促使利用摄像机的内外参数来编码自车帧中每个像素的位置和方向。
更准确地说,通过为摄像机的每个像素构建观察光线,编码摄像机标定参数。给定在摄像机图像Ik的像素坐标,捕获x的射线方向rk(x)用以下公式计算:
然后,为了充分描述捕获像素x的光线位置和方向,嵌入rayk(x)计算如下:
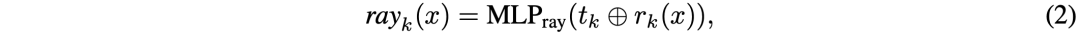
该计算在摄像机内和摄像机之间是一致的,并且显示了一个有趣的特性:具有相同光学中心的两个摄像机重叠区域具有相同的光线嵌入。请注意,内参根据Ik和Fk之间的分辨率差异进行缩放。最终输入向量序列通过串联每个特征向量Fk(x)及其几何嵌入rayk(x)。
作者基于通用架构的发现,用中等固定大小的潜空间,而不是学习多摄像机特征和BEV空间之间的二次“all-to-all”对应关系,去控制图像到BEV块的计算和内存开销。形式上,来自所有摄像机的视觉表征Fk及其相应的几何嵌入rayk,通过交叉注意压缩为N个可学习潜表征的集合。无论输入特征分辨率或摄像机数量如何,都能够有效地融合来自所有摄像机所处理的语义信息。基于潜查询,该公式将网络的深度多视图处理与输入和输出分辨率解耦。因此,该架构可以利用BEV网格的完整分辨率。
最后一步从潜空间解码二值分割预测。实际上,在最终预测分辨率下潜向量与BEV“查询”网格Q交叉参与(cross- attended)。查询网格的每个元素都是一个特征向量,用于编码BEV的空间位置,指定交叉注意将从潜表示中提取哪些信息。最后一个交叉注意在BEV空间中生成了一个特征图,用一个小型卷积编码器-解码器U-Net(BEV-CNN)进一步细化,最终预测二值BEV语义图。
具体来说,考虑两种查询的组合:BEV空间的归一化坐标和归一化径向距离。归一化坐标对BEV平面以自车为中心的归一化坐标进行编码。计算按照以下公式获得:
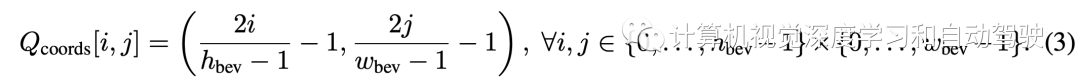
归一化径向距离就是图像像素相对中心的欧氏距离:
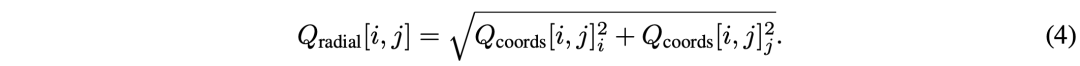
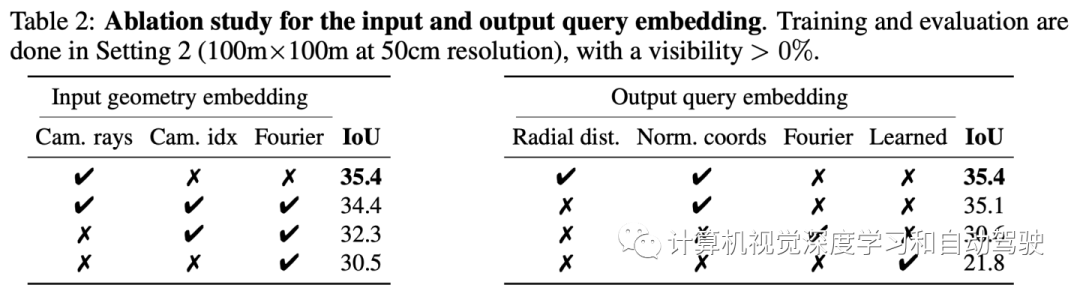
虽然该网络可以使用MLPbev从Qcoords生成类似的嵌入,但发现沿Qcoords引入这些径向嵌入改善了结果。此外,与更经典的傅立叶嵌入和学习的查询嵌入相比,这种查询解码选择更有利,如下表所示:
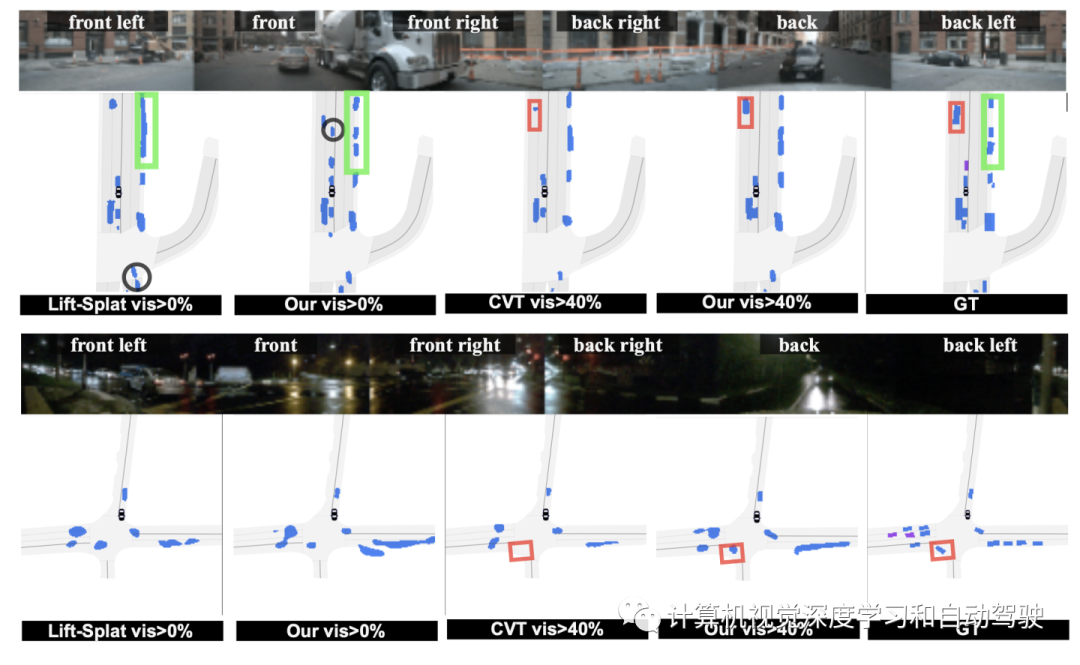
如图是uScenes 数据集的6个周视摄像头图像:

实验结果如下:
如图展示车辆周围的六个摄像头视图以及分割真值:在真值(GT)地图中,车辆显示为蓝色(可见性>40%)或紫色(可见性<40%)。



编辑推荐




最新资讯
-
大卓智能端到端直播实测,16公里复杂路段挑
2025-04-25 17:16
-
《汽车轮胎耐撞击性能试验方法-车辆法》等
2025-04-25 11:45
-
“真实”而精确的能量流测试:电动汽车能效
2025-04-25 11:44
-
GRAS助力中国高校科研升级
2025-04-25 10:25
-
梅赛德斯-AMG使用VI-CarRealTime开发其控制
2025-04-25 10:21
